当我们在浏览器的地址栏输入 www.cnblogs.com ,然后回车,回车到看到页面到底发生了什么呢?
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
一、域名解析
首先Chrome浏览器会解析www.cnblogs.com这个域名对应的IP地址。怎么解析到对应的IP地址?
- Chrome浏览器会首先搜索浏览器的DNS缓存(缓存时间比较短,TTL默认是1000,且只能容纳1000条缓存),看自身的缓存中是否有www.cnblogs.com对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
注:我们怎么查看浏览器的DNS缓存?可以使用 chrome://net-internals/#dns 来进行查看
- 如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统的DNS缓存,如果找到且没有过期则停止搜索解析到此结束。
注:怎么查看操作系统的DNS缓存,以Windows系统为例,可以在命令行下使用 ipconfig /displaydns 来进行查看
-
如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
- 如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找到根域的DNS地址,就会向其发起请求(请问www.cnblogs.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.cnblogs.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.cnblogs.com这个域名的IP地址,但是我知道www.cnblogs.com这个域的DNS地址,你去找它去,于是运营商的DNS又向www.cnblogs.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.cnblogs.com这个域名的IP地址是多少?),这个时候cnblogs.com域的DNS服务器一查,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.cnblogs.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.cnblogs.com对应的IP地址,该进行一步的动作了。
DNS递归解析图如下所示:
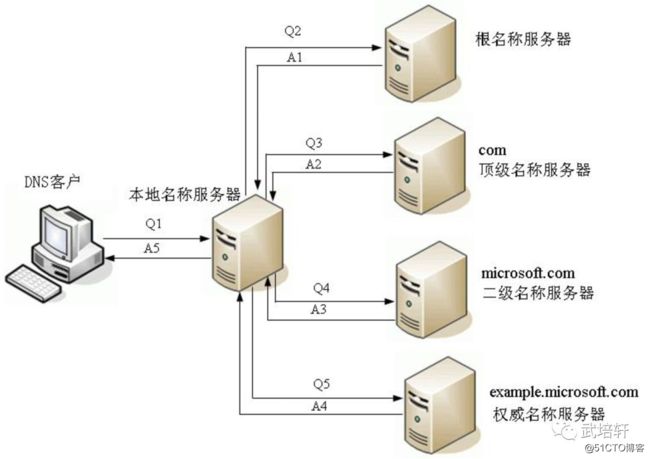
DNS迭代解析图如下所示:
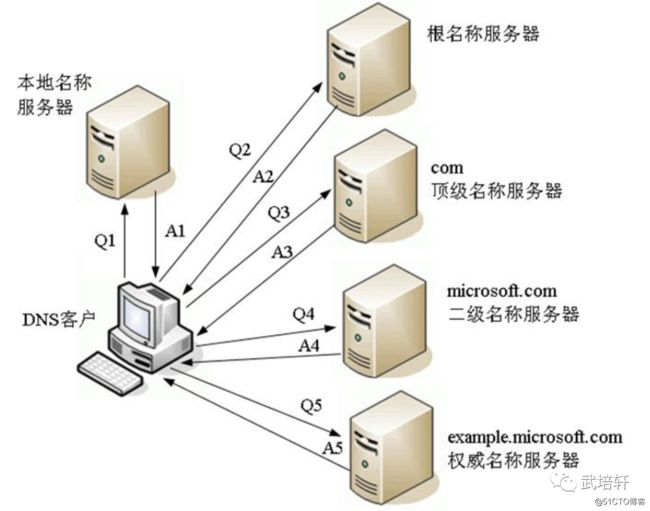
注:一般情况下是不会进行以下步骤的,如果经过以上的4个步骤,还没有解析成功,那么会进行如下步骤:
-
操作系统就会查找NetBIOS name Cache(NetBIOS名称缓存,就存在客户端电脑中的),那这个缓存有什么东西呢?凡是最近一段时间内和我成功通讯的计算机的计算机名和Ip地址,就都会存在这个缓存里面。什么情况下该步能解析成功呢?就是该名称正好是几分钟前和我成功通信过,那么这一步就可以成功解析。
-
如果第5步也没有成功,那会查询WINS 服务器(是NETBIOS名称和IP地址对应的服务器)
-
如果第6步也没有查询成功,那么客户端就要进行广播查找
- 如果第7步也没有成功,那么客户端就读取LMHOSTS文件(和HOSTS文件同一个目录下,写法也一样)
如果第八步还没有解析成功,那么这次解析失败,那就无法跟目标计算机进行通信。只要这八步中有一步可以解析成功,那就可以成功和目标计算机进行通信。
二、发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有tomcat,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。如下图:
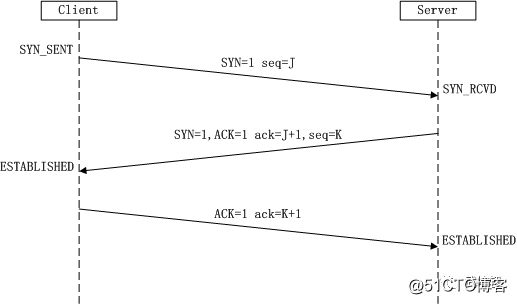
注:TCP三次握手详解
三、建立TCP连接后发起http请求
HTTP请求报文的方法是get方式,如果浏览器存储了该域名下的Cookies,那么会把Cookies放入HTTP请求头里发给服务器。
下面是Chrome发起的http请求报文头部信息:
GET / HTTP/1.1
Host: www.cnblogs.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://www.cnblogs.com/wupeixuan/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9四、服务器端响应http请求,浏览器得到html代码
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
用Chrome浏览器看到的响应头信息:
HTTP/1.1 200 OK
Date: Sun, 08 Apr 2018 10:51:00 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Encoding
Cache-Control: public, max-age=29
Expires: Sun, 08 Apr 2018 10:51:29 GMT
Last-Modified: Sun, 08 Apr 2018 10:50:59 GMT
X-UA-Compatible: IE=10
Content-Encoding: gzip五、浏览器解析html代码,并请求html代码中的资源
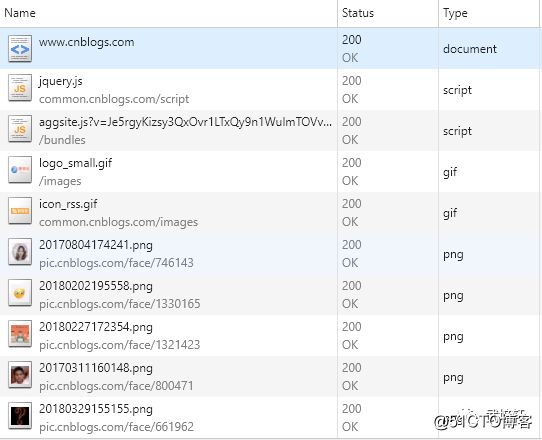
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
六、浏览器对页面进行渲染呈现给用户
最后,Chrome浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
武培轩
有帮助?在看,转发走一波
钟意作者