使用numpy完成item-cf算法
1. Item-cf实现的基本原理
下面以一个实例来展示使用perason相似度计算的item-cf算法
1.1:计算物品相似度(以《寻龙诀》和《小门神》两部电影为例)
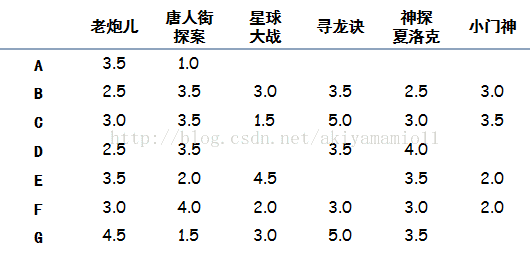
Index栏的A,B,C,D,E,F,G为用户,column栏为电影的评分。
距离:A/老炮儿 栏 评分为3.5,即代表A用户对老炮评分为3.5分。
1.2计算Pearson相似度
计算公式:
我们选《寻龙诀》(X)和《小门神》(Y)作为例子,来算一下相似度,则
X=(3.5,5.0,3.0)
Y=(3.0,3.5,2.0)
数字就是评分,因为只有三个人同时看了这两个电影,所以X,Y两个向量都只有三个元素。
求相关系数,这个可以直接通过numpy提供的corrcoef方法计算。
1.3得到相似度表:
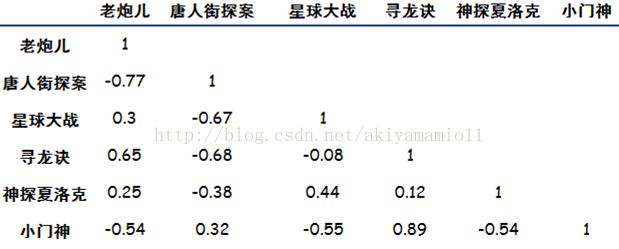
相关系数取值为【-1,1】,1表示完全相似,0表示没关系,-1表示完全相反。结合到电影偏好上,如果相关系数为负数,比如《老炮儿》和《唐人街探案》,意思是说,喜欢《老炮儿》的人,存在厌恶《唐人街探案》的倾向。
2. 数据导入MySQL
要实现item-cf,肯定先要将数据导入MySQL,这里使用Navicat for MySQL的导入数据功能(ps:由于实现的是item-cf算法,只需要评论的详细信息,因此仅导入了评论信息,书籍信息使用书籍的id号代替):
设置好格式和字段名后导入结果如下:
3. 利用python实现item-cf算法
3.1得到所需信息的查询
要计算两本书的pearson相似度,需要得到对这两本书都进行过评价的所有用户,以及这些用户对这两本书的评分。
在这里以《火鳳燎原 23》(书id号:3024737)和《火鳳燎原 4》(书id号3024796)为例
可以使用如下语句进行查询得到结果:
SELECT a.author,a.rating,b.rating fromsheet1 a,sheet1 b where a.bookID=3024737 and b.bookID=3024796 and a.uri=b.uriand a.rating <> 0 and b.rating <> 0;
得到的结果为:
(('MajorZiggy',5, 4), ('欧阳杼', 5, 4), ('小肚子✨', 5, 5), ('伽藍紙鳶', 5, 5), ('legolas', 5, 5), ('医遗以癔', 4, 4), ('小八千', 5, 5))
这个tuple中的数据,第一列为评论者,第二列为对《火鳳燎原 23》的评分,第三列为对《火鳳燎原 4》的评分。
整理一下格式后,可以得到两个向量:
[5, 5,5, 5, 5, 4, 5]
[4, 4, 5, 5, 5,4, 5]
分别是不同用户对《火鳳燎原 23》的评分向量和对《火鳳燎原 4》的评分向量
这里有两个注意点:
1. 使用a.uri=b.uri而不用a.name=b.name是因为防止有重名的评论者,所以使用每个评论者独一无二的uri。
2. a.rating<>0和b.rating<>0是因为库中0代表只有评论而没有评分,所以需要去掉。
之后就可以用numpy进行相似度计算了
3.2计算得到两个向量的pearson相似度
之后可以使用Numpy计算两个向量的pearson相似度。
代码如下:
import pymysql
import numpy as np
import codecs
db=pymysql.connect("localhost","root","","douban",charset='utf8') #连接数据库
#查询两本书的评分
cursor=db.cursor()
cursor.execute("SELECT a.author,a.rating,b.rating from sheet1 a,sheet1 b where a.bookID=3024737 and b.bookID=3024796 and a.uri=b.uri and a.rating <> 0 and b.rating <> 0; ")
data=cursor.fetchall()
print(data)
a=[]
b=[]
for dat in data: #得到两个向量
a.append(dat[1])
b.append(dat[2])
rel=np.corrcoef(a, b) #计算pearson相似度的方法
print(rel[0][1]) #pearson相似度
file=codecs.open('C:/Users/xuwei/Desktop/corr.txt',mode='a',encoding='utf-8')
file.write(str(data))
file.close()
db.close()得到这两本书的pearson相似度为0.471404520791
3.3 对所有书计算pearson相似度
运用上述方法,可以对所有书两两计算pearson相似度。
可以采用dict存储某本书与其他所有书的相似度,进行排序后,就可以得到与某本书最相似的书了。代码如下:
import pymysql
import numpy as np
import codecs
f=open("C:/Users/xuwei/Desktop/demo.txt",'r') #读取所有书的id号
line=f.readline()
list=[]
while line:
list.append(line.replace('\n',''))
line=f.readline()
db=pymysql.connect("localhost","root","","douban")
for i in list:
dict={}
for j in list:
if i != j:
cursor=db.cursor()
sql="SELECT a.author,a.rating,b.rating from sheet1 a,sheet1 b where a.bookID={0} and b.bookID={1} and a.uri=b.uri and a.rating <> 0 and b.rating <> 0; ".format(i,j)
cursor.execute(sql)
data=cursor.fetchall()
if len(data)>1: #判断共同评分数量,如果只有一个的话没有办法计算相似度
a=[]
b=[]
for dat in data:
a.append(dat[1])
b.append(dat[2])
rel=np.corrcoef(a, b) #计算相似度
if not np.isnan(rel[0][1]): #判断是否为nan,若不是就存到字典里
dict[j]=rel[0][1]
dic=sorted(dict.items(),key=lambda d:d[1],reverse=True) #按相似度由大到小排序
print(dic)
file=codecs.open('C:/Users/xuwei/Desktop/corr.txt',mode='a',encoding='utf-8')
file.write(i+'\t'+str(dic)+'\n') #写到文件中
file.close()
print(i,'write finished')
db.close()