1.历史
HBase Coprocessors是参照Google BigTable的coprocessor来实现的。


2.什么是Coprocessor
简单来说,Coprocessor是一个框架,这个框架可以让你很容易地在Region Server运行你的业务逻辑代码。
对于客户端查询数据:
Hbase,用Get/Scan查询数据,RDBMS用SQL查询数据
Hbase,用Filter查询特定数据,RDBMS用Where查询特定数据
但是以上情况只适合几千行数据以及不是很多的列的“小数据”。
当表扩展为亿万行及百万列时,在通过网络传递移动大量的数据导致网络拥堵,且客户端需要足够多内存来处理这么大量数据的计算操作,另外,客户端代码也会变的大而复杂。
对于这种情况,Coprocessor就可搞定,你可以把业务计算的代码放到在Region Server 运行着的Coprocessor里,和数据放到相同的位置,然后返回结果给客户端。
3.Coprocessor 分类、类比及实现步骤
Coprocessor 类比
Triggers and Stored Procedure
Observer Coprocessor –> RDBMS 中的触发器
EndPoint Coprocessor –> RDBMS中的存储过程
MapReduce
MapReduce 和 Coprocessor有一样的操作原则,计算向数据靠拢。
AOP
类似面向切面编程,Coprocessor就像应用Advice,在传递请求到最终的目的地之前,通过 拦截一个请求后运行相同的代码。
Coprocessor分类
1. Observer :它是一种类似于传统数据库的触发器,提供了钩子函数:Get、Put、Delete、Scan等。
2. Endpoint:是一个远程rpc调用,类似于webservice形式调用,但他不适用xml,而是使用的序列化框架是protobuf(序列化后数据更小).
关于两者的区别, Coprocessor的作用是将用户的代码运行在Region上,而Observer像是个触发器,到某个条件Region就去执行用户代码,用户从主观来说是无法控制的;EndPoint就是远程调用,用户可以在客户端远程调用执行自己的代码。
Coprocessor 实现步骤
1. 继承一个Coprocessor类,像BaseRegionObserver,或是实现Coprocessor,CoprocessorService接口。
2. 加载Coprocessor,有两种方法,一配置文件中静态加载,二使用Hbase Shell
3. 客户端调用Coprocessor
4. 接口
先说下三个最重要的抽象接口,一个是协处理器,一个是协处理器的环境,最后是管理前面两者的管理器,结构如下图所示。
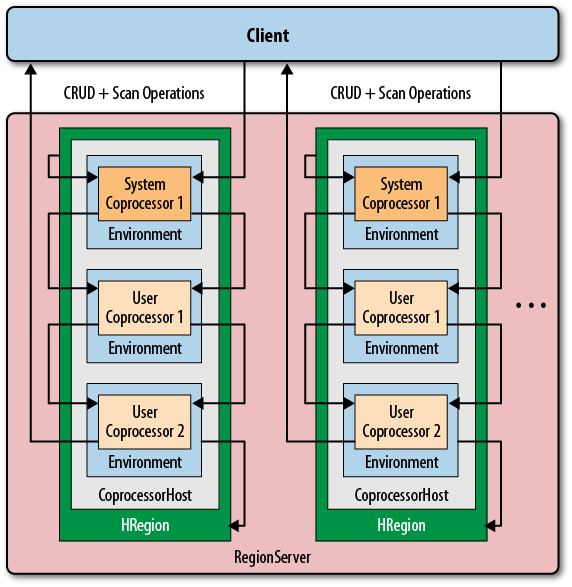
4.1 Coprocessor
所有的协处理器都继承Coprocessor接口,这个接口主要的是Priority成员,用于标示是系统级别的协处理器还是用户级别的,系统级别比用户级别先执行
org.apache.hadoop.hbase
-Coprocessor
4.2 CoprocessorEnvironment
这个接口主要是提供了协处理器的环境信息,提供版本信息,协处理器的优先信息,协处理器的对应表,协处理器的序号
这里的序号是按照最初加载时顺序指定的,在之后的执行过程中也会按照这个序号进行
需要注意的是一开始我以为CoprocessorEnvironment是一个全局唯一量,后来才发现是一个Coprocessor对应着一个环境
org.apache.hadoop.hbase
-CoprocessorEnvironment
4.3 CoprocessorHost
这个接口是用来管理Coprocessor和CoprocessorEnvironment,并且外部会调用该接口来执行Coprocessor。
org.apache.hadoop.hbase.coprocessor
-CoprocessorHost
5. 加载方法
加载方法有两种:
5.1. 从配置中加载
Hbase在启动时读取配置文件中的几条配置来加载,这个用于加载所有的协处理器
在hbase-site.xml中加入如下信息:
hbase.coprocessor.region.classes
地址,地址
注意在value中可以添加多个地址,也就是添加多个Coprocessor
name中的类型在官方0.98代码中有5种,分别是region上的系统协处理器、regionserver上的协处理器、region上的用户处理器、master服务器上的协处理器、在regionserver上的日志相关协处理器
也就是说一般的RS服务器上会加载2和5,当打开了一个region会加载1和3,在master服务器上会加载4
public static final String REGION_COPROCESSOR_CONF_KEY ="hbase.coprocessor.region.classes";
public static final String REGIONSERVER_COPROCESSOR_CONF_KEY ="hbase.coprocessor.regionserver.classes";
public static final String USER_REGION_COPROCESSOR_CONF_KEY ="hbase.coprocessor.user.region.classes";
public static final String MASTER_COPROCESSOR_CONF_KEY ="hbase.coprocessor.master.classes";
public static final String WAL_COPROCESSOR_CONF_KEY ="hbase.coprocessor.wal.classes";
5.2. 从表描述符中加载
Hbase会获取表的描述信息,其中的”COPROCESSOR$1=>’地址'”这样的格式来加载,这个只能加载对应一张表的协处理器
在创建表的时候需要添加COPROCESSOR信息,java代码:
HTableDescriptor htd = new HTableDescriptor("name");
htb.setValue("COPROCESSOR$1","地址");
其中COPROCESSOR后面的“美元符合”后的数子表示这是第几个Coprocessor,定义的时候需要依次
COPROCESSOR$1,COPROCESSOR$2……
注意:前面说的地址的意思是自己实现的协处理的包的地址,因为部署时需要将自己写的协处理器jar文件放到每一台服务器的java路径下,Coprocessor框架会根据这个路径来找到类。
最后看下在RegionCoprocessorHost的协处理器加载过程
- 首先加载系统的协处理器,加载实际上就是把协处理器的环境放入一个set中
- 如果部署系统表的话就加载用户协处理器
- 最后从表描述中加载协处理器
#在RegionCoprocessorHost的构造中从配置文件加载了两个协处理器,然后会从表的描述中加载所有的协处理器
RegionCoprocessorHost
#coprocessors是保存所有加载的coprocessor的排序带锁的set集合
-coprocessors = new SortedCopyOnWriteSet(new EnvironmentPriorityComparator());
-RegionCoprocessorHost
#加载Region的协处理器 hbase.coprocessor.region.classes
-loadSystemCoprocessors(conf, REGION_COPROCESSOR_CONF_KEY);
-如果不是系统表
#加载用户的协处理器 hbase.coprocessor.user.region.classes
-loadSystemCoprocessors(conf, USER_REGION_COPROCESSOR_CONF_KEY);
#最后从hdfs上加载,也就是获取表配置中的coprocessor
-loadTableCoprocessors(conf);
->loadTableCoprocessors
-如果coprocessor没有启动的话则return
#从region的描述中取出coprocessor
-for (attr: getTableCoprocessorAttrsFromSchema)
#从本地加载coprocessor的环境
-env = load
-configured.add(env);
-coprocessors.add()
6. Observer
Observer在Hbase中主要分为四类,均继承Coprocessor接口:
1. RegionObserver 针对于Region的观察者(Region打开、关闭、刷新、合并等工作)
2. RegionServerObserver 针对RegionServer的观察者(Region合并、分裂、日志回滚等)
3. MasterObserver 针对Master的观察者(表创建、删除、Region移动、拆分等工作)
4. WALObserver 针对WAL的观察者(日志写)
6.1 RegionObserver过程
下图示例了一个客户端get操作在Coprocessor框架的过程
- 在region打开时就会加载所有的协处理器,具体见前面加载过程
- 在get前调用CoprocessorHost的PreGet方法
- CoprocessorHost会循环调用所有的协处理器的PreGet方法
- 执行真正的get方法
- 调用CoprocessorHost的PostGet方法
- CoprocessorHost中循环调用所有的协处理器PostGet方法

在协处理器中的过程代码如下:
RegionCoprocessorHost
#coprocessors是保存所有加载的coprocessor的排序带锁的set集合
-coprocessors = new SortedCopyOnWriteSet(new EnvironmentPriorityComparator());
-preGet
-return execOperation(coprocessors.isEmpty() ? null : new RegionOperation() {
public void call(RegionObserver oserver, ObserverContext ctx)
throws IOException {
oserver.preGetOp(ctx, get, results);
}
})
->execOperation
-for (RegionEnvironment env: coprocessors)
-observer = env.getInstance();
#如果需要调用
-if (ctx.hasCall(observer))
-ctx.prepare(env);
#调用上面的call
-ctx.call(observer, ctx);
#是否调用失败
-bypass |= ctx.shouldBypass();
-ctx.postEnvCall(env);
-return bypass; 对于其他几个Observer的实现类似。
6.2 Hindex的使用示例
这里我们想通过一个示例来看下Observer。
如果使用Coprocessor的话首先需要知道继承的类,下图是整个Observer的继承图,最下面的四个类实现了各自的接口,如果需要监控master的一些操作,就直接继承BaseMasterObserver。

接下来我们来看下华为二重索引HIndex中对于Observer的使用,这里使用到了三个Observer
1. org.apache.hadoop.hbase.index.coprocessor.master.IndexMasterObserver
拦截DDL操作,在数据库表发生创建/删除/Enable/Disable/Drop操作时同步创建/更改/删除Index表。并且拦截region balance过程,在HFile发生合并和分裂时同步修改Index表,确保Index表的记录与统一Rowkey的数据记录永远在同一Region Server,加快查询效率。
2. org.apache.hadoop.hbase.index.coprocessor.regionserver.IndexRegionObserver
拦截数据库表的Put/Delete/Get/Scan/Flush等操作,同步更新Index表
3. org.apache.hadoop.hbase.index.coprocessor.wal.IndexWALObserver
同步WAL操作,在Region Server的预写区域发生操作时判断Index Table是否需要同步操作,将预写操作提交到Region Server。
这里我们主要看下IndexRegionObserver
首先也是需要加载,在配置文件hbase-site.xml中加入
hbase.coprocessor.master.classes
org.apache.hadoop.hbase.index.coprocessor.master.IndexMasterObserver
然后重新启动集群,这样就hbase的master就加载这个类了。
从下面方法中可以看到,IndexMasterObserver重新了PreCreateTable,主要实现了创建表的时候同时进行一些索引的创建工作;PreMove和PostMove都是防止系统Balancer的时候将索引和原表分开;最后两个Handler是会在BaseMasterObserver中的postModifyTbale方法和postCreateTable方法中被调用。
IndexMasterObserver
-preCreateTable
-preMove
-postMove
-postModifyTableHandler
-postCreateTableHandler
7. EndPoint
Endpoint允许定义自己的动态RPC协议,用于客户端与region servers通讯。Coprocessor 与region server在相同的进程空间中,因此您可以在region端定义自己的方法(endpoint),将计算放到region端,减少网络开销,常用于提升hbase的功能,如:count,sum等。
工作过程如下图所示过程:
- 不管是通过配置还是表描述加载了EndPoint协处理器
- 在Client执行CoprocessorExec()调用对应的RPC方法
- 在对应的每个region中都会执行该方法后返回结果

7.1 获取行数示例
HBase中AggregateImplementation是了一个EndPoint,实现了Coprocessor接口,该类主要用于实现聚合功能,提供了getMax、getMin、getSum等RPC调用。
org.apache.hadoop.hbase.coprocessor
-AggregateImplementation
我们可以通过客户端提供AggregationClient来远程调用AggregateImplementation来获取每一个region的数据,最后在这个类中再进行一次合并就可以输出了
org.apache.hadoop.hbase.client.coprocessor
-AggregationClient
步骤
首先在配置文件中加入AggregateImplementation,还需要重启集群,这样就可以让Coprocessor框架来加载这个EndPoint了
hbase.coprocessor.region.classes
org.apache.hadoop.hbase.coprocessor.AggregateImplementation
然后在客户端调用
Configuration customConf = new Configuration();
customConf.setStrings("hbase.zookeeper.quorum","node0,node1,node2"); //提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000); //设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(configuration);
Scan scan = new Scan(); //指定扫描列族,唯一值
scan.addFamily(CF);
long rowCount = aggregationClient.rowCount(TABLE_NAME, null, scan);
System.out.println("row count is " + rowCount);
参考:1.《Hbase权威指南》
2. http://www.zuiyuemuai.com/wordpress/?p=1856
3.http://www.3pillarglobal.com/insights/hbase-coprocessors
4.http://hbase.apache.org/book.html#cp