【一】实践中学习 awk
内置变量
awk 中预先定义好的,内置在 awk 内部的变量。
| 变量名 | 描述 |
|---|---|
| FS | 输入字段分隔符,默认是空格 |
| OFS | 输出字段分隔符,默认是空格 |
| RS | 输入记录分隔符,默认换行符 |
| ORS | 输出记录分隔符,默认换行符 |
| NF | number of fields,当前记录中域的个数,也就是每行有多少列 |
| NR | number of rows,已经读出的记录数,也就是行号。从1开始,有多个文件时,这个值会累加 |
| FNR | 各个文件分别计数的行号,和 NR 类似,这个是相对于当前文件的,当处理多个文件时很有作用,每当从新的文件读入时,FNR 都会被重置为 0 |
| FILENAME | 当前文件名 |
| AGRC | 命令行参数的个数 |
| ARGV | 数组,保存命令行所传的各个参数 |
记录
- awk 把每一个换行符结束的行称为一个记录,$0 变量:它指的是整条记录。
# 输出 test.txt 文件中的所有记录
awk '{print $0}' test.txt
- 变量 NR:一个计数器,每处理完一条记录,NR 的值就增加 1。
# 输出 test.txt 中的所有记录,并在记录前显示行号
awk '{print NR, $0}' test.txt
域
记录中的每个单词都称作「域」,默认情况下以空格分隔。awk 可跟踪域的个数,并在内建变量 NF 中保存该值。
# 打印第一和第三个以空格分开的列(域)
awk '{print $1, $3}' test.txt
awk 命令格式
有了上边域和记录的概念,来看看 awk 的命令格式:
awk [options] 'pattern{action}' file
eg1:
# $3 == 0:是 pattern
# print $0:是 action
awk '$3==0 {print $0}' employee # 如果第三个域等于 0,则将这行打印
eg2:
下面这个 awk 脚本没有指定 action,但结果和 eg1 一样,没有指定 action 时默认是 {print $0}(打印整行)。
awk '$3 == 0' employee
eg3:
#将结果重定向到文件
awk '$3 == 0' employee > other.txt
域分隔符
- 输入分隔符(field separator),就是 test.txt 中每个列是以什么进行分隔的,awk 默认以空格对每一行进行分隔,分隔符得值保存在内建变量 FS中,可以通过-F命令行选项修改FS的值。
# 指定 : 作为分隔符
awk -F: '{print $1, $3}' test.txt
# 显示指定空格作为分隔符
awk -F'[ ]' '{print $1, $3}' test.txt
# 指定空格、冒号、tab 作为分隔符
awk -F'[:\t ]' '{print $1, $3}' test.txt
# 指定以逗号(,)作为分隔符
awk -F, '{print $1, $2}' separator.txt
# 使用 -v 选项对内建变量设置分隔符,和 awk -F, 效果一样
awk -v FS=',' '{print $1, $2}' separator.txt
- 输出分隔符(out field separator), 大白话表示就是 awk 在处理完文本后以什么字符作为分隔符将每行输出,默认也是空格,保存在内建变量 OFS 中。
eg1:
# 对内建变量 OFS 赋值
awk -v OFS="->" '{print $1, $2, $3}' other.txt
输出如:
Beth->4.00->0
Dan->3.75->0
eg2:
# 同时指定输入和输出分隔符
awk -v FS=',' -v OFS='->' '{print $1, $2}' separator.txt
模式-Pattern
根据前面的一些例子,awk 的语法如下:
awk [options] 'Pattern {Action}' file1 file2
options(选项): 如前面使用过的 -v -F
Action(动作):如 print
Pattern:也就是条件,一个关系表达式,awk 会逐行处理文本,处理完当前行,然后再处理下一行。如果不指定任何的「条件」,awk 会一行一行的处理完文件的每一行,如果指定了「条件」,只处理满足条件的行。这即 awk 中的模式。
# 将有四列的行打印出来
awk 'NF == 4 {print $0}' column.txt
# 没有指定模式则是空模式,空模式会匹配文本中每一行,每一行都满足条件
awk '{print $0}' test.txt
- 正则模式
# 将包含 in 的记录行进行打印
awk '/in/ {print $0}' pattern.txt
- 行范围模式
eg1:
# 从第一行 到 正则匹配到的第一行 之间的所有行进行打印
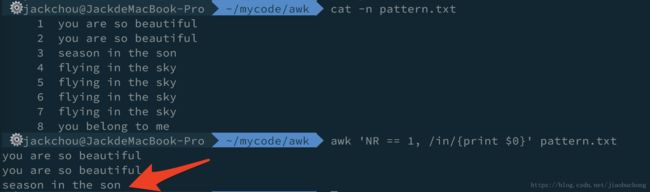
awk 'NR == 1, /in/{print $0}' pattern.txt
# /xx/ 没有匹配到第二个模式,打印第一个模式出现的行到文本末尾
awk 'NR == 1, /xx/{print NR, $0}' pattern.txt
看一下结果:
eg2:
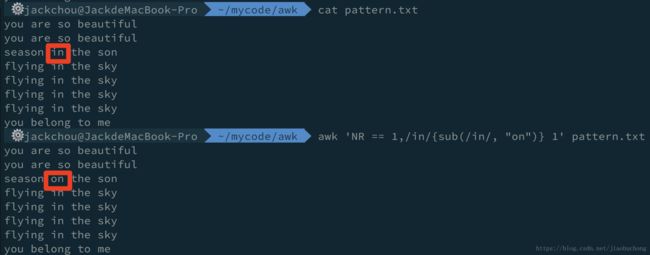
# 将第一行 到 正则匹配到的第一行中的 in 替换为 on(从记录行的左边开始,只替换一次)
# 怎么理解这个 1 呢?
# 这里有两个模式,awk 读出每行记录都会经过这两个模式的判断
# 1 表示这个模式为真,没有指定模式默认的 action 就是打印整行
awk 'NR == 1,/in/{sub(/in/, "on")} 1' pattern.txt
再来一波例子估计就懂 eg2 中的用法了:
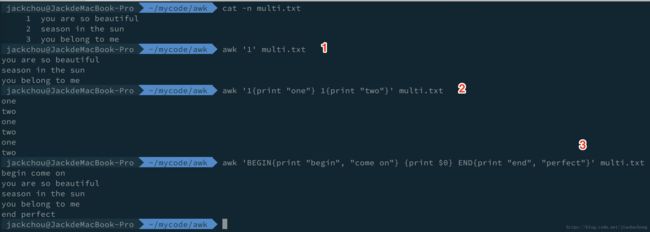
在 1 处,模式指定为 1 表示为真,走默认的 action 打印整行。
在 2 处,指定了两个模式,每行记录都会经过这两个模式的处理,然后分别执行模式自己的动作。
在 3 处,有 3 个模式:BEGIN 模式和 END 模式,中间的是空模式(没有指定模式)。BEGIN 模式:处理文本之前先执行的操作;END 模式:处理完所有行后需要执行的操作。
范围模式的第一个模式和第二个模式都以第一次匹配到的行为准。
awk 内建函数
字符串函数
- sub
sub (regular expression, substitution string):
sub (regular expression, substitution string, target string)
对每一个记录行从左到右第一个匹配到的域进行替换,每一行只会匹配替换一次。
# 将每行第一次出现的域 hello 替换为 hi,每行只会匹配替换一次
awk '{sub(/hello/, "hi"); print}' test.txt
# 对每行的第一个域进行替换
awk '{sub(/hello/, "hi", $1); print}' test.txt
- gsub
全局替换,会对每一行中每个符合正则表达式条件的域都会进行替换。
# 将每一行中出现的 m 替换为 M
awk '{gsub(/m/, "M");print}' poem.txt
更多awk实践例子可参考:
【二】实践中学习 awk
很好的 awk 入门教程:
AWK程序设计语言
awk 从放弃到入门
AWK 简明教程
https://www.jianshu.com/p/8c6a0d0d4f0d