基于1.1.5-alpha版本,具体源码笔记可以参考我的github:https://github.com/saigu/JavaKnowledgeGraph/tree/master/code_reading/canal
本文将对canal的binlog订阅模块parser进行分析。
parser模块(绿色部分)在整个系统中的角色如下图所示,用来订阅binlog事件,然后通过sink投递到store.
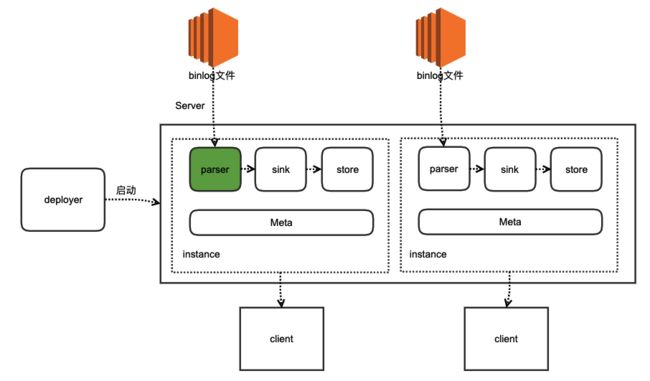
parser模块应该来说是整个项目里面比较复杂的模块,代码非常多。
因此,本文根据过程中的主线来进行展开分析,从 启动 开始,进行分析。
如果读者有其他相关内容不明白的,可以给我留言,我会进行解答或者根据情况再单独写相关内容。
模块内的类如下:
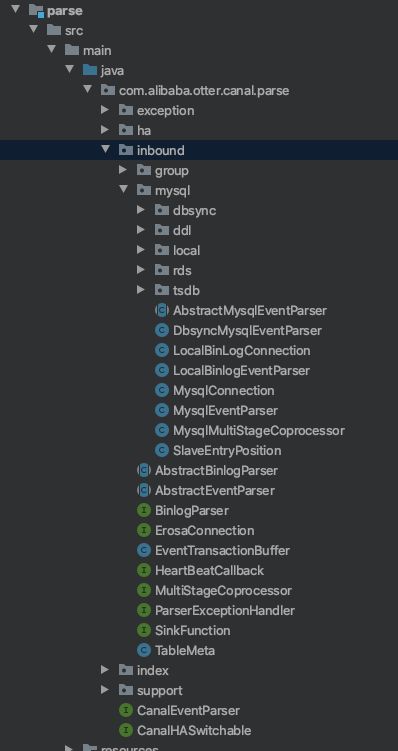
重点需要关注几个核心问题
- 如何抓取binlog
- 对binlog消息处理做了怎样的性能优化
- 如何控制位点信息
- 如何兼容阿里云RDS的高可用模式下的主备切换问题
1.从启动进入parser主流程
前面的文章我们已经提到了,instance启动的是,会按照顺序启动instance的各个模块

parser模块就是在这里开始的。
这里需要注意一下,在beforeStartEventParser方法中,启动了parser的两个相关组件CanalLogPositionManager 和 CanalHAController,这里先分别介绍一下。
- CanalLogPositionManager:管理位点信息
- CanalHAController:instance连接源数据库的心跳检测,并实现数据库的HA(如果配置了standby的数据库)
1.1 位点信息管理CanalLogPositionManager
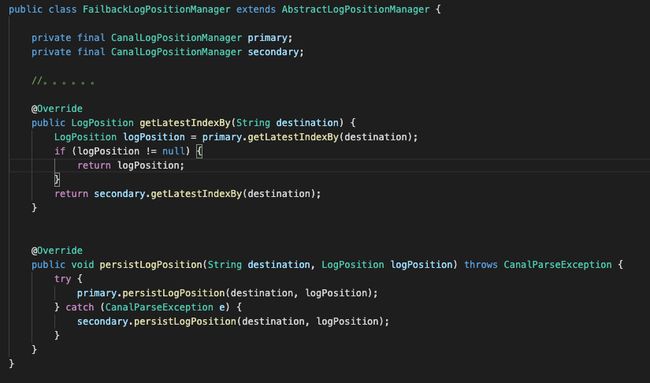
我们用的是default-instance.xml的配置,所以实际实现类是FailbackLogPositionManager
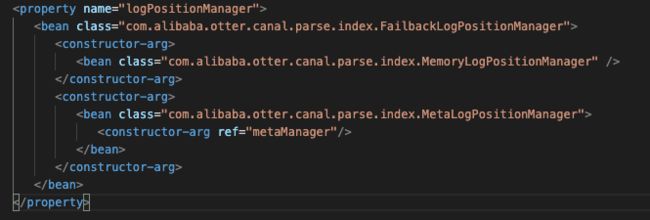
这里构造器有两个入参,一个是primary的MemoryLogPositionManager,一个是second的MetaLogPositionManager。
前者是内存的位点信息,后者我们我们看一下构造器的metaManager是基于zk的位点信息管理器。
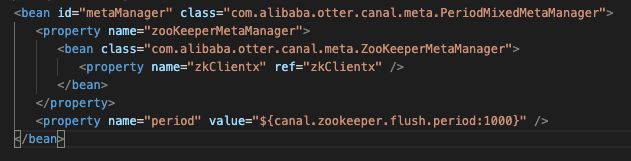
所以FailbackLogPositionManager逻辑也比较简单,获取位点信息时,先尝试从内存memory中找到lastest position,如果不存在才尝试找一下zookeeper里的位点信息。
1.2 心跳控制器CanalHAController
我们用的是default-instance.xml的配置,所以实际实现类是HeartBeatHAController

HeartBeatHAController里面没有特别复杂的逻辑,就是实现了心跳检测成功的onSuccess方法和onFail方法。另外维护了一个CanalHASwitchable对象,一旦心跳检测失败超过一定次数,就执行doSwitch()进行主备切换。

前提是我们要设置了主备数据库的连接信息。
这里的代码写的真的是有点混乱,居然是用MysqlEventParser实现了这个doSwitch()方法。
另外,在MysqlEventParser中,写了一个MysqlDetectingTimeTask内部类,集成了TimerTask来做定时心跳检测。
- 定时去连接数据库,可以通过select\desc\show\explain等方法做存活检测
- 如果检测成功,就调用HeartBeatHAController的onSuccess方法
- 如果失败,就HeartBeatHAController的onFail方法
- 如果失败超过一定次数,onFail方法中就会调用doSwitch方法进行主备切换
2.核心逻辑
从parser.start()进去后,我们就来到了parser的核心。
从default-instance.xml配置文件看,默认的parser实现是从base-instance.xml的baseEventParser来的,用的是RdsBinlogEventParserProxy类。

我们看下这个类图的结构。
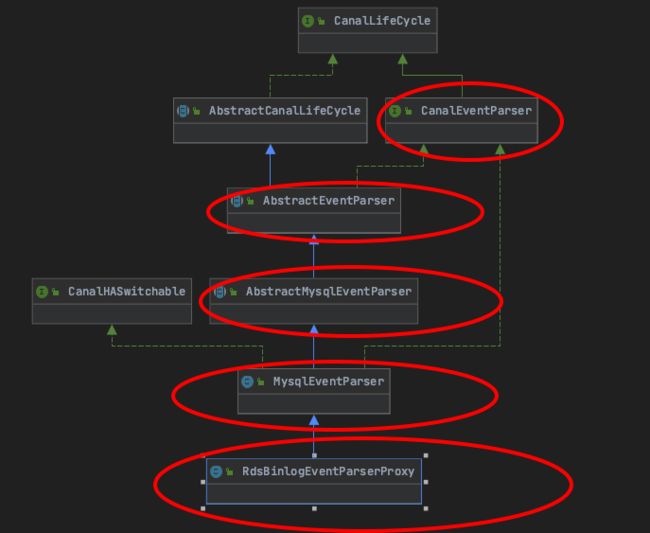
从这个结构来看,我们从上到下,就能对parser模块的主体逻辑进行抽丝剥茧了。
Let’s go!
2.1 CanalEventParser接口
定义了一个空的接口
2.2 AbstractEventParser抽象类
这个类里面代码非常多,我们重点关注核心流程。
2.2.1 构造器AbstractEventParser()
构造器里面就只做了一件事情,创建了一个EventTransactionBuffer。
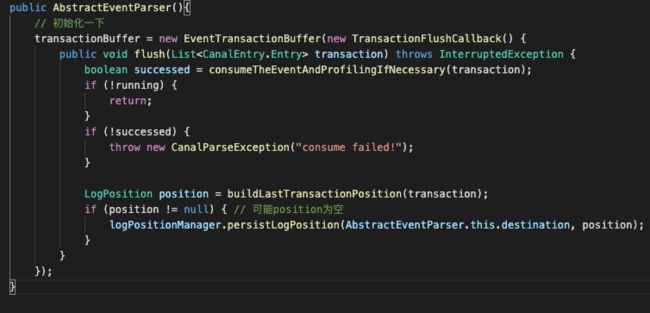
EventTransactionBuffer这个类顾名思义就是一个缓冲buffer,它的作用源码里的注释也很清楚,它是缓冲event队列,提供按事务刷新数据的机制。
那对于这里构造器中实现的TransactionFlushCallback的flush(List
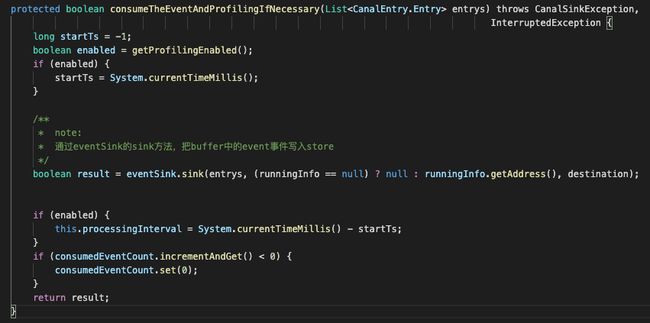
我们可以看下consumeTheEventAndProfilingIfNecessary(transaction)方法,跟我们想的一样,具体的sink方法放在后面的sink模块再展开分析。
2.2.2 主干的start()方法
主要做了这些事情:
- 初始化缓冲队列transactionBuffer
- 初始化binlogParser
- 启动一个新的线程进行核心工作
- 构造Erosa连接ErosaConnection
- 利用ErosaConnection启动一个心跳线程
- 执行dump前的准备工作,查看数据库的binlog_format和binlog_row_image,准备一下DatabaseTableMeta
- findStartPosition获取最后的位置信息(挺重要的,具体实现在MysqlEventParser)
- 构建一个sinkHandler,实现具体的sink逻辑(我们可以看到,里面就是把单个event事件写入到transactionBuffer中)
- 开始dump过程,默认是parallel处理的,需要构建一个MultiStageCoprocessor;如果不是parallel,就直接用sinkHandler处理。内部while不断循环,根据是否parallel,选择MultiStageCoprocessor或者sinkHandler进行投递。
- 如果有异常抛出,那么根据异常类型做相关处理,然后退出sink消费,释放一下状态,sleep一段时间后重新开始
代码很长,逻辑比较清晰,就不贴了。
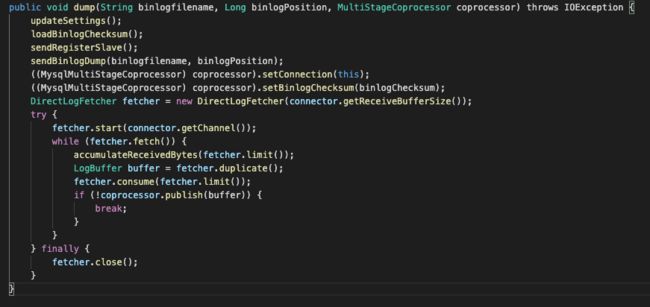
2.2.3 核心dump过程
dump过程默认是parallel处理的,需要构建一个MultiStageCoprocessor;如果不是parallel,就直接用sinkHandler处理。内部while不断循环,根据是否parallel,选择MultiStageCoprocessor或者sinkHandler进行投递。
注意multiStageCoprocessor在这里start启动。
代码如下

dump方法在MysqlConnection类中实现,主要就是把自己注册到数据库作为一个slave,然后获取binlog变更,具体到协议我们就不展开分析了。
通过fetcher抓取到event,然后调用sink投递到store。
注意,parallel为false的,是单线程交给sinkHandler处理,parallel为true的,交给MultiStageCoprocessor的coprocessor.publish(buffer)处理,后面展开分析下并行处理的逻辑。
注意multiStageCoprocessor在这里publish进行写入RingBuffer,下文会详细讲下这里的机制。
2.3 AbstractMysqlEventParser抽象类
这个类比较简单,就是做了根据配置做了一些对象创建和设置的工作,比如BinlogParser的构建、filter的设置等
2.4 MysqlEventParser实现类
总共有将近1000行代码,里面其实代码组织有点混乱。像前面提到的MysqlDetectingTimeTask内部类、HeartBeatHAController的部分方法实现,都是在这个类里面的。
那抛开这些来说,这个类的主要功能还是在处理根据journalName、position、timestamp等配置查找对应的binlog位点。
我们选取核心流程里面的关键逻辑 findStartPostion( ) 方法进行分析即可。
这个是AbstractEventParser类中start方法中调用的,获取dump起始位点。
我们默认是使用 非GTID mode记录位点信息的,所以直接看下来看下findStartPositionInternal( ) 具体逻辑,这里可以了解到如何正确配置位点信息:
- logPositionManager找历史记录
- 如果没有找到
- 如果instance没有配置canal.instance.master.journal.name
- 如果instance配置了canal.instance.master.timestamp,就按照时间戳去binlog查找
- 如果没有配置timestamp,就返回数据库binlog最新的位点
- 如果instance配置了canal.instance.master.journal.name
- 如果instance配置了canal.instance.master.position,那就根据journalName和position获取bingo位点信息
- 如果配置了timestamp,就用journalName + timestamp形式获取位点信息
- 如果找到了历史记录
- 如果历史记录的连接信息和当前连接信息一致,那么判断下是否有异常,没有异常就直接返回
- 如果历史记录的连接信息和当前连接信息不一致,说明可能发生主备切换,就把历史记录的时间戳回退一分钟,重新查询
这里是纯if else 流程代码,挺长的,就不贴了。
在这个过程中,调用了几个有意思的方法,可以了解一下
- findServerId( ):查询当前db的serverId信息,mysql命令为 show variables like 'server_id'
- findEndPosition():查询当前的binlog位置,mysql命令为 show master status
- findStartPosition():查询当前的binlog位置,mysql命令为 show binlog events limit 1
- findSlavePosition():查询当前的slave视图的binlog位置,mysql命令为 show slave status
2.5 RdsBinlogEventParserProxy实现类
这个类比较简单,就是canal为阿里云rds定制的一个代理实现类。
主要解决了云rds本身高可用架构下,服务端HA切换后导致的binlog位点信息切换。
所以对于抛出的异常做了一定的处理,兼容了这种服务端HA的情况。
同时,也能满足rds的备份文件指定位点开始增量消费的特性。
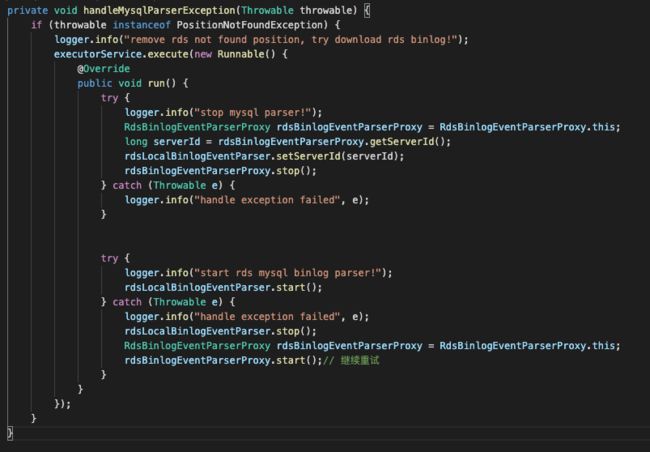
主要过程如下
- 如果抛出了PositionNotFoundException异常,就委托rdsLocalBinlogEventParser进行处理
- rdsLocalBinlogEventParser会通过下载binlog的oss备份,找到目标binlog文件和位置
3.事件处理优化 MultiStageCoprocessor
我们前面说过,parallel为false的,是单线程交给sinkHandler处理,parallel为true的,交给MultiStageCoprocessor处理。
这里展开看看并行处理是如何实现的。
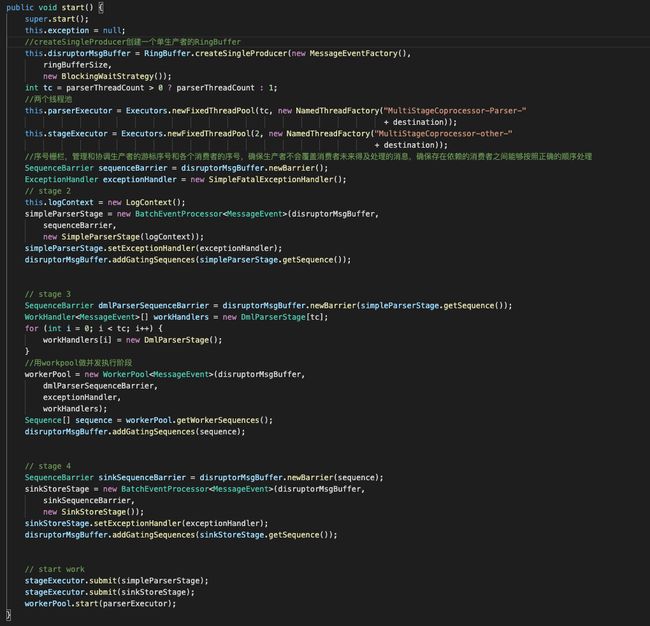
实现类是MysqlMultiStageCoprocessor, 看下基本结构,持有了EventTransactionBuffer(前文提到过的存储事务内多个evnet的buffer)、RingBuffer
这些属性类型基本是跟Disruptor框架相关。

start()方法里面对一系列属性做了初始化配置并进行启动,要理解这里的逻辑,其实主要是使用Disruptor框架做的任务队列。
如果了解了Disruptor框架的使用,就能明白这里所做的任务队列处理模型了。
start()源码如下:
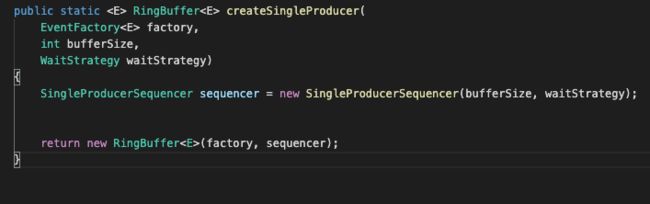
首先,这里用了Disruptor框架的典型单生产者-多消费者模型。
这里创建生产者的时候,就创建了RingBuffer和Sequencer,全局唯一。
上面在dump方法内,订阅到binlog事件后,通过multiStageCoprocessor的publish方法写入RingBuffer,作为单一的生产者。
多消费者主要通过Disruptor的Sequencer管理。
Sequencer 接口有两种实现,SingleProducerSequencer 和 MultiProducerSequencer,分别来处理单个生产者和多个生产者的情况,这里使用了SingleProducerSequencer。
在 Sequencer 中有一个 next() 方法,就是这个方法来产生 Sequence 中的 value。Sequence 本质上可以认为是一个 AtomicLong,消费者和生产者都会维护自己的 Sequence。
Sequencer 的核心就是解决了两个问题,第一个是对于所有的消费者,在 RingBuffer 为空时,就不能再从中取数据,对于生产者,新生产的内容不能把未消费的数据覆盖掉。
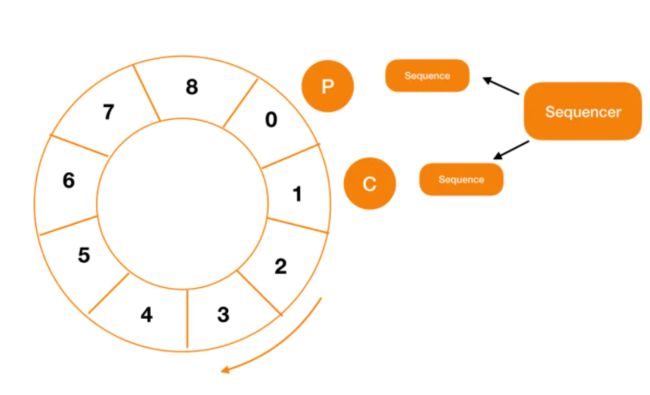
上图中 C 代表消费者,P 代表生产者。
当然,在多消费者模型中,一个关键的问题是控制消费者的消费顺序。
这里主要通过消费者之间控制依赖关系其实就是控制 sequence 的大小,如果说 C2 消费者 依赖 C1,那就表示 C2 中 Sequence 的值一定小于等于 C1 的 Sequence。
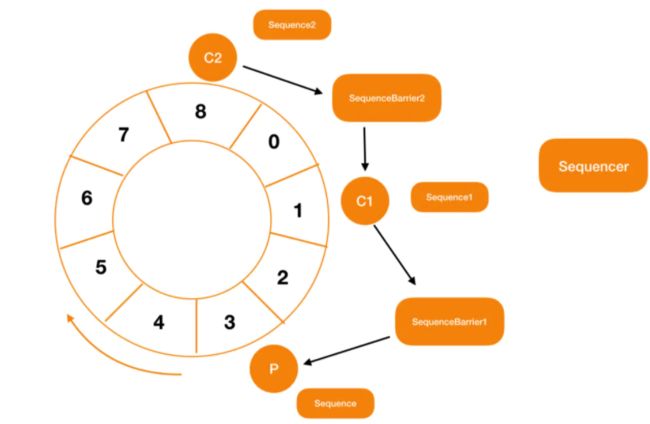
具体的方法是通过RingBuffer的addGatingSequences( )进行的。
具体Disruptor的原理和使用就不展开说明了,这里了解这些关键问题即可。
通过这样的编程模型,parser实现了解析器的多阶段顺序处理。
- Stage1: 网络接收 (单线程),publish投递到RingBuffer
- Stage2: 从RingBuffe获取事件,使用SimpleParserStage进行基本解析 (单线程,事件类型、DDL解析构造TableMeta、维护位点信息)
- Stage3: 事件深度解析 ,用workpool进行多线程, 使用DmlParserStage进行DML事件数据的完整解析
- Stage4: SinkStoreStage单线程投递到store
SimpleParserStage和SinkStoreStage使用了stageExecutor这个线程池进行管理,DmlParserStage使用了workpool进行管理。
这三个类都是MysqlMultiStageCoprocessor的内部类,通过实现OnEvent方法进行逻辑处理,具体处理逻辑就不展开了,大家有兴趣可以看下源码。
4.总结
这个模块是非常核心的,涉及到了对binlog事件的抓取和处理,以及相关位点信息的处理。
回头看开头几个问题,相信也都有了答案:
- 如何抓取binlog
dump方法在MysqlConnection类中实现,主要就是把自己注册到数据库作为一个slave,然后获取binlog变更(具体的协议我们就不展开分析了)。
- 对binlog消息处理做了怎样的性能优化
利用disruptor框架,基于RingBuffer实现了
单线程接受 -> 单线程解析事件 -> 多线程深度解析事件 -> 单线程投递store 这样的一个流程。
(这里有点疑惑,单线程接受事件后,为什么需要一个单线程先解析一下再多线程深度解析,而不是直接多线程深度解析?有了解的朋友可以给我留言指点一下,谢谢)
- 如何控制位点信息
有多种CanalLogPositionManager可以选择。
默认采用FailbackLogPositionManager,获取位点信息时,先尝试从内存memory中找到lastest position,如果不存在才尝试找一下zookeeper里的位点信息。
- 如何兼容阿里云RDS的高可用模式下的主备切换问题
RdsBinlogEventParserProxy如果发现了PositionNotFoundException异常,就委托rdsLocalBinlogEventParser通过下载binlog的oss备份,找到目标binlog文件和位置。
都看到最后了,原创不易,点个关注,点个赞吧~
文章持续更新,可以微信搜索「阿丸笔记 」第一时间阅读,回复关键字【学习】有我准备的一线大厂面试资料。
知识碎片重新梳理,构建Java知识图谱: github.com/saigu/JavaK…(历史文章查阅非常方便)