利用Oprofile对多核多线程进行性能分析
利用Oprofile对多核多线程进行性能分析
杨小华
工欲善其事,必先利其器
---墨子
性能分析工具简介
在对应用程序不断调优的过程中,除了制定完备的测试基准(Benchmark)外,还需要一把直中要害的利器——性能分析工具。
根据工具的复杂度和所提供的功能,可以将性能工具分为两个层次:
- 基本的计时工具
在普通生活中,秒表是最简单的计时工具。根据该思想,可以将计时函数放在代码的任意位置并多次调用,这样就可以测量出整个应用或者某一部分的运行时间。这种分析方法不够精细,误差大。
- 软件分析工具
目前,主要有两种不同类型的软件分析工具:采样和插桩。
Ø 采样型分析工具
主要通过周期性中断,来纪录相关的性能信息,如处理器指令指针、线程id、处理器id和事件计数器等。这种方法开销小,精确度高。在Linux系统中,比较常见的有Oprofile和Intel VTune性能分析器等。
Ø 插桩型分析工具
即可以使用直接的二进制插桩,也可以通过编译器在应用中插入分析代码。这种方式与自己在应用中增加计时函数类似,同时带来的开销大,但提供了更多的功能,如调用树,调用次数和函数开销等。在Linux系统中,比较常见的有gprof和Intel VTune性能分析器等。
本文将利用采样型工具Oprofile,对多核多线程程序进行性能分析,起一个抛砖引玉的作用。
衡量性能收益的方法
随着科学技术的不断发展,计算机系统结构朝着多核的方向发展,从而将并发编程推到了聚光灯下,但如何去衡量并行程序设计所带来的性能收益呢?
不得不想起1967年Gene Amdahl所做出的杰出贡献,他提出的Amdahl定律能够计算出并行程序相对于最优串行算法在性能提升上的理论最大值。
Amdahl定律
1
加速比=————————
S+(1-S)/n+H(n)
其中, S 表示执行程序中串行部分的比例, n 表示处理器核的数量, H(n)表示系统开销。
由于Amdahl定律本身做出了几个假设,但这些假设在现实世界中又不一定是正确的,因此使计算机界心灰意冷了很多年,认为根据Amdahl定律,开发更大的并行性所带来的性能收益可能是微不足道的,一直到Gustafson定律的出现,才改变了现状。
在Sandia实验室工作的基础上,E.Barsis提出了Gustafson定律:
扩展加速比=N+(1-N)*S
其中, S 表示执行程序中串行部分的比例,N 表示处理器核的数量。
幸运的是,Shi于1996年证明Gustafson定律和Amdahl定律是等效的。
Oprofile工作原理简介
根据CPU系统结构的不同, Oprofile支持两种采样方式:基于事件(Event Based)的采样和基于时间(Time Based)的采样。
如果CPU内部存在性能计数寄存器,则Oprofile基于事件采样,记录特定事件(如分支预测事件)发生的次数,当达到设定的定值时就采样一次。反之,则基于时间采样,主要是借助于操作系统的时钟中断机制,每当时钟中断发生时就采样一次。不难看出,基于时间的采样方式,要求被测程序不能屏蔽中断,其精度也低于事件采样。
对于x86体系结构,不同型号的CPU,采样方式也不同,具体细节如下表所示:
| 处理器 |
CPU_TYPE |
采样方式 |
| Athlon |
i386/athlon |
Event Based |
| Pentium Pro |
i386/ppro |
Event Based |
| Pentium II |
i386/pii |
Event Based |
| Pentium III |
i386/piii |
Event Based |
| Pentium M (P6 core) |
i386/p6_mobile |
Event Based |
| Pentium 4 (non-HT) |
i386/p4 |
Event Based |
| Pentium 4 (HT) |
i386/p4-ht |
Event Based |
| Dual Core |
timer |
Time Based |
| Core 2 Duo |
timer |
Time Based |
表一 x86各处理器采样方式
Oprofile主要分为两部分,其中一部分是内核模块(oprofile.ko),另外一部分是用户空间的守护进程(oprofiled)。前者主要负责访问性能计数寄存器或者注册基于时间采样的函数,并将采样结果置于内核的缓冲区中。后者在后台运行,负责从内核空间收集数据,并写入采样文件中,其交互流程如图1所示:
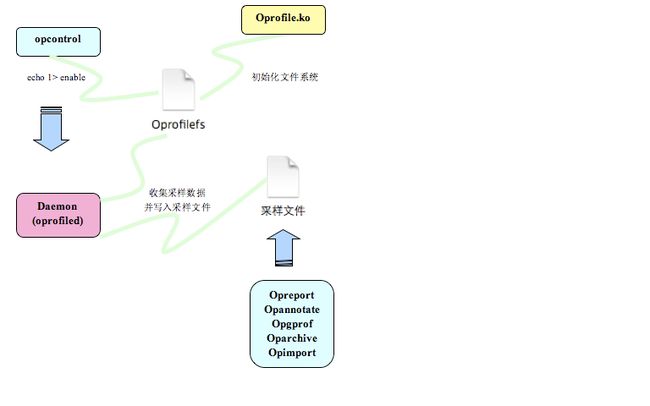
图1 oprofile交互流程图
安装Oprofile
oprofile.ko内核模块已经被集成到linux 2.6内核中,所以只需要安装前端工具,可以从oprofile官方网站下载源码来进行安装,当前最新版本为0.9.4。
该源码包是通过automake和autoconf生成的makefile,所以只需要以root用户进入oprofile目录,运行./configure、make及make install来完成所有的安装。 在目前大部分发行版中, 安装时可能缺少popt库,请另行下载安装。
Oprofile工具链提供了6大工具,供用户控制oprofile和分析样本。其中opcontrol是一个bash脚本程序,主要用来控制oprofile的启动、暂停及设置,其他工具主要是对采样数据进行分析。
样例程序
程序功能:求从1一直到 APPLE_MAX_VALUE (100000000) 相加累计的和,并赋值给apple的a和b ;求orange数据结构中的 a[i]+b[i]的和,循环 ORANGE_MAX_VALUE次。
| #define ORANGE_MAX_VALUE 1000000 #define APPLE_MAX_VALUE 100000000 #define MSECOND 1000000
struct apple { unsigned long long a; unsigned long long b; };
struct orange { int a[ORANGE_MAX_VALUE]; int b[ORANGE_MAX_VALUE];
};
int main (int argc, const char * argv[]) { // insert code here... struct apple test; struct orange test1;
for(sum=0;sum { test.a += sum; test.b += sum; }
for(index=0;index { sum += test1.a[index]+test1.b[index]; } return 0; } |
观察上述样例程序, S (串行部分的比例)所占比例非常小,基本为0, 根据Amdahl定律,在双核系统(n=2)上,则加速比为:加速比=1/(0+1/2+1%)=1.96,也就是说效率可以提高96%。
样例程序运行时间为:1.049046s,那么经过优化后,能不能达到理论值呢?请随着本文开始。
追踪热点
既然要充分利用双核的特性,则不得不对样例程序进行改造,进行并行程序设计。
可以将应用程序看成是众多相互依赖的任务的集合。将应用程序划分成多个独立的任务,并确定这些任务之间的相互依赖关系,这个过程称为分解(Decomosition)。分解问题的方式主要有三种:任务分解、数据分解和数据流分解。
运用任务分解的方法 ,不难发现计算apple的值和计算orange的值,属于完全不相关的两个操作,因此可以并行。
改造后的两线程程序:
| void* add(void* x) { for(sum=0;sum { ((struct apple *)x)->a += sum; ((struct apple *)x)->b += sum; }
return NULL; }
int main (int argc, const char * argv[]) { // insert code here... struct apple test; struct orange test1={{0},{0}}; pthread_t ThreadA;
pthread_create(&ThreadA,NULL,add,&test);
for(index=0;index { sum += test1.a[index]+test1.b[index]; }
pthread_join(ThreadA,NULL);
return 0; }
|
现在通过oprofile来对多线程程序进行性能分析,收集热点信息。oprofile的功能非常强大,可以对每个线程进行单独采样,也可以对每个CPU单独采样,这些都是通过opcontrol的--separate选项来完成的。separate选项值含义如下:
| separate选项值 |
含义 |
| none |
默认值 |
| lib |
对每个应用程序的所有lib进行采样 |
| kernel |
对每个应用程序的内核及内核模块采样 |
| thread |
对每个线程或任务采样 |
| cpu |
对每个CPU进行采样 |
| all |
以上所有选项的功能 |
表2 separate选项值含义
操作步骤如下:
| # opcontrol --init # opcontrol --separate=thread --no-vmlinux # opcontrol --start Using 2.6+ OProfile kernel interface. Using log file /var/lib/oprofile/samples/oprofiled.log Daemon started. Profiler running. # ./twothreadprocess add thread:b7dc7b90,Used Time:1.225483 main thread:b7dc8ad0,Used Time:1.230151 a = 4999999950000000,b = 4999999950000000,sum=0 # opcontrol --shutdown Stopping profiling. Killing daemon. |
识别出并行程序中的重载
运行opreporte,查看采样结果:
| # opreport -l ./twothreadprocess CPU: CPU with timer interrupt, speed 0 MHz (estimated) Profiling through timer interrupt Processes with a thread ID of 5237 Processes with a thread ID of 5238 samples % samples % symbol name 30 100.000 0 0 main 0 0 343 100.000 add |
运行时间为:1.230151s,与理论值相差甚远,反而运行时间越来越长,原因何在呢?
通过分析结果,不难看出add线程负载非常重,而main负载较轻,负载不均衡,因此重点分析对象为add线程。根据多线程数据分解的原理,将计算apple值的过程一分为二,main线程也参与部分计算。由于都是循环,为了使负载均衡,则add线程里面应该循环(ORANGE_MAX_VALUE+APPLE_MAX_VALUE)/2次。修改后的程序如下:
| #define ORANGE_MAX_VALUE 1000000 #define APPLE_MAX_VALUE 100000000 #define MSECOND 1000000 #define MIDLLE_VALUE 49500000
struct apple { unsigned long long a; unsigned long long b; };
struct orange { int a[ORANGE_MAX_VALUE]; int b[ORANGE_MAX_VALUE]; };
unsigned long long value[2][2];
void* add(void* x) { temp1 = ((struct apple *)x)->a; temp2 = ((struct apple *)x)->b;
for(sum=MIDLLE_VALUE;sum<APPLE_MAX_VALUE;sum++) { temp1 += sum; temp2 += sum; }
value[0][0]=temp1; value[1][0]=temp2;
return NULL; }
int main (int argc, const char * argv[]) { // insert code here... struct apple test; struct orange test1={{0},{0}}; pthread_t ThreadA;
test.a= 0; test.b= 0;
temp1 = test.a; temp2 = test.b;
pthread_create(&ThreadA,NULL,add,&test);
for(sum=0;sum<MIDLLE_VALUE;sum++) { temp1 += sum; temp2 += sum; }
value[0][1]=temp1; value[1][1]=temp2;
sum=0;
for(index=0;index<ORANGE_MAX_VALUE;index++) { sum=test1.a[index]+test1.b[index]; }
pthread_join(ThreadA,NULL);
test.a = value[0][0]+value[0][1]; test.b = value[1][0]+value[1][1];
return 0; }
|
重新运行oprofile,再次收集采样数据,改造后的程序是否达到了负载均衡呢?
| # opreport -l ./twothreadprofile CPU: CPU with timer interrupt, speed 0 MHz (estimated) Profiling through timer interrupt Processes with a thread ID of 5242 Processes with a thread ID of 5243 samples % samples % symbol name 135 100.000 0 0 main 0 0 156 100.000 add |
运行时间为:0.629821s,时间有了显著的提高,效率也提升了66%,已经逼近理论值,但还是有一点差距。
继续分析,不难看出,负载还是没有达到均衡,main线程还是有点轻。因此继续增大MIDLLE_VALUE的值到53500000,再次运行oprofile,看看效果如何:
| # opreport -l ./twothreadprofilebig CPU: CPU with timer interrupt, speed 0 MHz (estimated) Profiling through timer interrupt Processes with a thread ID of 5248 Processes with a thread ID of 5249 samples % samples % symbol name 145 100.000 0 0 main 0 0 146 100.000 add |
运行时间为:0.540942s,比样例程序时间大约减少了一半,效率提升了92%,已经非常接近于理论值。相信通过不断的微调,将会越来越接近理论值。同时在计算理论值时,所假设的系统开销比较低,仅仅为1%。
由于Linux 内核进程调度器天生具有CPU软亲和力(affinity) 的特性,这就意味着进程通常不会在处理器之间频繁的迁移。在实际应用中,如果不存在数据竞争的影响,应用的不同部分分布到不同的CPU上运行,可能会带来更高的收益。
将样例程序的多线程版本绑定到不同的CPU上运行,效率会有所提升吗?
修改后的程序如下:
| struct apple { unsigned long long a; unsigned long long b; };
struct orange { int a[ORANGE_MAX_VALUE]; int b[ORANGE_MAX_VALUE]; };
int cpu_nums = 0; unsigned long long value[2][2];
inline int set_cpu(int i) { CPU_ZERO(&mask);
if(2 <= cpu_nums) { CPU_SET(i,&mask);
if(-1 == sched_setaffinity(gettid(),sizeof(&mask),&mask)) { return -1; } } return 0; }
void* add(void* x) { if(-1 == set_cpu(1)) { return NULL; }
temp1=((struct apple *)x)->a; temp2=((struct apple *)x)->b;
for(sum=MIDDLE_VALUE;sum { temp1 += sum; temp2 += sum; }
value[0][0]=temp1; value[1][0]=temp2;
return NULL; }
int main (int argc, const char * argv[]) { // insert code here... struct apple test; struct orange test1={{0},{0}}; pthread_t ThreadA;
test.a= 0; test.b= 0;
cpu_nums = sysconf(_SC_NPROCESSORS_CONF);
if(-1 == set_cpu(0)) { return -1; }
temp1=test.a; temp2=test.b;
pthread_create(&ThreadA,NULL,add,&test);
for(sum=0;sum { temp1 += sum; temp2 += sum; }
value[0][1]=temp1; value[1][1]=temp2;
sum=0;
for(index=0;index { sum+=test1.a[index]+test1.b[index]; }
pthread_join(ThreadA,NULL);
test.a=value[0][0]+value[0][1]; test.b=value[1][0]+value[1][1];
return 0; }
|
修改opcontrol的--separate参数为cpu,然后开始采样:
| # opcontrol --separate=cpu --no-vmlinux # opcontrol --reset # opcontrol --start Using 2.6+ OProfile kernel interface. Using log file /var/lib/oprofile/samples/oprofiled.log Daemon started. Profiler running. # ./affinitytwoprofile …… # opcontrol --shutdown Stopping profiling. |
采样结果如下:
| # opreport -l ./affinitytwoprofile CPU: CPU with timer interrupt, speed 0 MHz (estimated) Profiling through timer interrupt Samples on CPU 0 Samples on CPU 1 Samples on CPU all samples % samples % samples % symbol name 147 100.000 0 0 147 50.9559 main 0 0 143 100.000 143 49.0441 add |
程序运行时间为:0.575131s,与没有绑定之前的效果接近,但不代表CPU绑定没有用处,只是本样例程序运行时间较短,工作量不大,不适合使用CPU绑定而已。
oprofile分析多核程序与分析多线程程序类似,通过采样数目来识别重载,然后开始一步一步的优化。
总结
根据以上分析及实验,对所有改进方案的测试时间做一个综合对比,如下图所示:
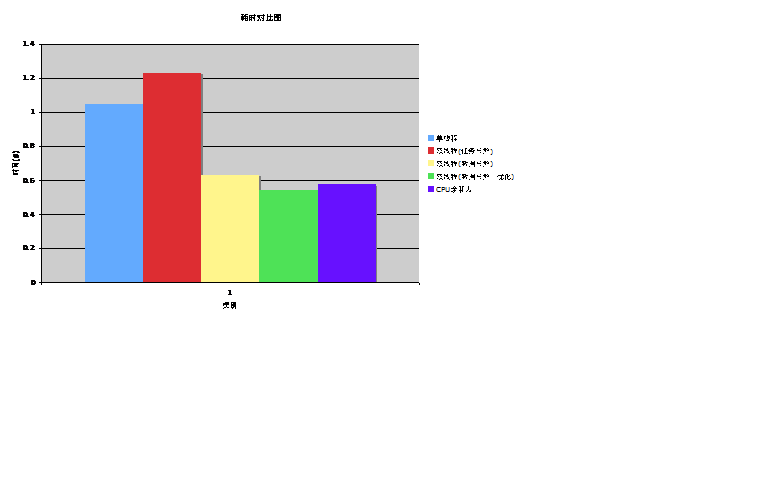
图2 各优化时间对比图
利用Oprofile,一步一步的不断调优,最终使优化后的结果接近于理论值,让我们见证了优化工具所具有的魅力。但Oprofile不仅仅只有这些功能,关于更多的其他功能,请参看官方网站介绍或者本文参考资料所列出的资料2和3。
参考资料
[1] Oprofile官方网站
[2] PrPrasanna S. Panchamukhi,《用 OProfile 彻底了解性能》, IBM Developerworks
[3] John Engel,《 使用 OProfile for Linux on POWER 识别性能瓶颈》, IBM Developerworks
[4] 杨小华,《 利用多核多线程进行程序优化》, IBM Developerworks