中文是熵, /shāng/。下面是个简单科普:
是一种测量在动力学方面不能做功的能量总数,也就是当总体的熵增加,其做功能力也下降,熵的量度正是能量退化的指标。熵亦被用于计算一个系统中的失序现象,也就是计算该系统混乱的程度。熵是一个描述系统状态的函数,但是经常用熵的参考值和变化量进行分析比较,它在控制论、概率论、数论、天体物理、生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。
在信息论中,熵是接收的每条消息中包含的信息的平均量,又被称为信息熵、信源熵、平均自信息量。这里,“消息”代表来自分布或数据流中的事件、样本或特征。
这句话我暂时没有理解:
(熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。)
来自信源的另一个特征是样本的概率分布。这里的想法是,比较不可能发生的事情,当它发生了,会提供更多的信息。
由于一些其他的原因,把信息(熵)定义为 概率分布的对数的相反数 是有道理的。事件的概率分布和每个事件的信息量构成了一个随机变量,这个随机变量的均值(即期望)就是这个分布产生的信息量的平均值(即熵)。熵的单位通常为比特,但也用Sh、nat、Hart计量,取决于定义用到对数的底。
采用概率分布的对数作为信息的量度的原因是其可加性。
例如,投掷一次硬币提供了1 Sh的信息,而掷m次就为m位。更一般地,你需要用log2(n)位来表示一个可以取n个值的变量。
在1948年,克劳德·艾尔伍德·香农将热力学的熵,引入到信息论,因此它又被称为香农熵。
Model for Information
观察发生概率为p 的事件,得到的信息为i(p)
- i(p) ≥ 0 : information never decrease,得到的信息永远增加
- i(1) = 0 : observing a certain event adds no information 必然发生的时间,是得不到信息的
- i(p1p2) = i(p1)+i(p2): information from observing independent events are additive 信息可以相加
信息论之父克劳德·香农,总结出了信息熵的三条性质:
- 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
- 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。
能满足上面的模型,最简单就是 i(p) = −log(p)

Shannon's Information Entropy

上面是离散的和连续的 变量 x浪的 Entropy 函数
直觉上,信息量等于传输该信息所用的代价,这个也是通信中考虑最多的问题。比如说:赌马比赛里,有4匹马{A, B, C, D} ,获胜概率分别为 1/2, 1/4,1/8, 1/8
如果 A ,那么需要问1次(问题1:是不是A?),概率为1/2;
如果 B ,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为 1/4 ;
如果 C ,那么需要问3次(问题1,问题2,问题3),概率为 1/8 ;
如果 D ,那么同样需要问3次(问题1,问题2,问题3),概率为 1/8
为了确定 赢的马,在这种问法下, 取值的二元问题数量为:
那么我们回到信息熵的定义,会发现通过之前的信息熵公式,神奇地得到了:

这样就很好理解信息熵的概念,
这部分去看 知乎 - 信息熵是什么?
- 这句话我也没有太理解,信息熵 Information entropy 是 分布的 disorder
- why this is not a good model for knowledge? For Shannon's Information Entropy
下面是抛硬币的entropy情况

%pylab inline
import warnings
warnings.filterwarnings('ignore')
p = np.array([.5, .25, .01])
print(-p*np.log2(p) - (1-p)*np.log2(1-p))
>>>
Populating the interactive namespace from numpy and matplotlib
[ 1. 0.81127812 0.08079314]
Underdetermined problem
An optimization problem with more variables than constraints:
关于变量比 约束多的 优化问题:
- has infinite number of solutions 有无数的解决方案
- requires an objective function for a unique solution 需要一个独特解决方案的目标函数
- common problem in quant finance
- finding implied distribution from few liquid market prices 从流动性差的市场价格中找到隐含分布
- curve building
In (early) literature, various ad hoc objective functions are used: 目标函数
- e.g.: sum of squares of first and second order derivatives 例一阶和二阶导数的平方和
Ignorance is strength
Disorder (or the lack of information) in a distribution is highly desirable:
分布中的无序,信息缺失是非常需要的
- more uncertainty in outcome, leaves open more possibilities 结果中更多的不确定性,留下更多的可能性
- free from the contamination of irrelevant and artificial restrictions 不受无关和人为限制的干扰
- the distribution is smooth and well behaved 分布光滑且表现良好
- more difficult to arbitrage against 更难以套利
Max entropy is the ideal objective for finding implied distributions:
最大熵是寻找隐含分布的理想目标
- much better than ad hoc smoothness constraints 比特设光滑度限制好
- invokes the higher principles of the information theory 引用信息论的更高原则
Maximum Entropy Method

离散分布的信息熵最大值
- exp(p), log(p) 都是列向量
- 对p 求导 d/dp (p^T * log(p)) = log(p^T) + 1^T
- 我们只考虑线性约束,在实践中易于处理和充分
- 连续分布可以用积分来表示。
在后面的操作中,其实都是:为了把原带约束的极值问题转换为无约束的极值问题,一般引入拉格朗日乘子,建立拉格朗日函数,然后对拉格朗日函数求导,令求导结果等于0,得到极值。
Maximum Entropy Method 问题:
- 1^T p = 1 的1 是什么意思
- Ap = b b是什么意思
- 这个我也不完全懂:对p 求导 d/dp (p^T * log(p)) = log(p^T) + 1^T
Uniform distribution
均匀分布在所有分布中,具有最大熵

使得log(p)在 = -(1+ λ) 1 时有最大值
Uniform distribution问题:
- 1 究竟是什么?
- 应用拉格朗日乘数,后面λ部分应该是约束条件。究竟是个什么约束条件?
Normal distribution
Normal distribution has the maximum entropy with given mean and variance
正态分布给定均值和方差时有最大熵
- This explains the ubiquity of the normal distribution 解释了正态分布的普遍性
- Knowing only mean and variance, we have to assume the distribution is normal 只知道均值和方差,我们必须假设分布是正常的
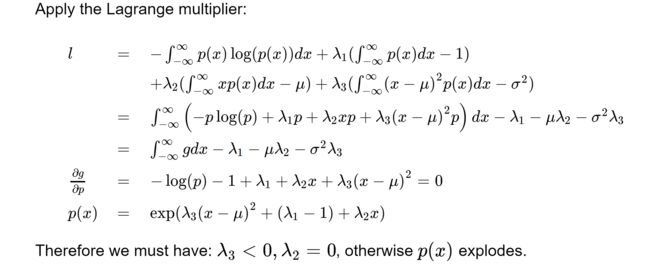
有三个约束条件
Normal distribution问题:
- 三个约束条件都是怎么得出来的?
Exponential distribution
Exponential distribution has the maximum entropy for a positive random variable with a given expectation 指数分布在给定期望的正随机变量时,有最大熵
-
Without addtional information, we have to assume all survival times are exponetially distributed. 没有附加信息,我们必须假设所有survival times 都是指数分布的。
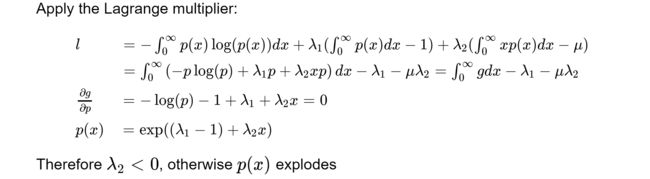
比较一下正太分布,约束条件都有:
- p(x)dx - 1
- xp(x)dx - μ
写个例子
%pylab inline
import me
from scipy.optimize import minimize
import pandas as pd
lecture = 10
matplotlib.rcParams.update({'font.size': 14})
x = np.arange(0, 10, .05)
a = np.array([x])
u = np.array([1.])
e = np.array([0])
q = np.ones(np.size(x))
dual = me.MaxEntDual(q, a, u, e)
res = minimize(dual.dual, np.zeros(len(u)), jac=dual.grad, method="BFGS")
figure(figsize=[12, 8])
subplot(2, 2, 1)
plot(x, dual.dist(res.x));
title('$x>0, \mathbb{E}[x]=1$');
subplot(2, 2, 3)
x = np.arange(-13., 13., .01)
a = np.array([x, x*x])
u = np.array([0., 1.])
e = np.array([0., 0.])
q = np.ones(np.size(x))/len(q)
dual = me.MaxEntDual(q, a, u, e)
res = minimize(dual.dual, np.zeros(len(u)), jac=dual.grad, method="BFGS")
semilogy(x, dual.dist(res.x))
xlim(-8, 8)
ylim(1e-16, 1e-2)
title('$\mathbb{E}[x] = 0, \mathbb{E}[x^2] = 1$');
subplot(2, 2, 4)
a = np.vstack([a, x*x*x*x])
u = np.append(u, 20)
e = np.append(e, 0)
dual = me.MaxEntDual(q, a, u, e)
res = minimize(dual.dual, np.zeros(len(u)), jac=dual.grad, method="BFGS")
semilogy(x, dual.dist(res.x))
xlim(-8, 8)
title('$\mathbb{E}[x] = 0, \mathbb{E}[x^2] = 1, \mathbb{E}[x^4] = 20$');
subplot(2, 2, 2)
a = np.vstack([a, x*x*x])
u = np.append(u, -4)
e = np.append(e, 0)
dual = me.MaxEntDual(q, a, u, e)
res = minimize(dual.dual, np.zeros(len(u)), jac=dual.grad, method="BFGS")
plot(x, dual.dist(res.x))
xlim(-8, 4)
title('$\mathbb{E}[x] = 0, \mathbb{E}[x^2] = 1, \mathbb{E}[x^3] = -4, \mathbb{E}[x^4] = 20$');

这一块老师用了他自己的 import me
同时我也不太理解他的 MaxEntDual 是什么?先跳过,之后要回来再找找。
Shannon's Information Entropy问题:
- 这句话我也没有太理解,信息熵 Information entropy 是 分布的 disorder
- why this is not a good model for knowledge? For Shannon's Information Entropy
Maximum Entropy Method 问题:
- 1^T p = 1 的1 是什么意思
- Ap = b b是什么意思
- 这个我也不完全懂:对p 求导 d/dp (p^T * log(p)) = log(p^T) + 1^T
Uniform distribution问题:
- 1 究竟是什么?
- 应用拉格朗日乘数,后面λ部分应该是约束条件。究竟是个什么约束条件?
Normal distribution问题:
- 三个约束条件都是怎么得出来的?
相关链接
维基 - 熵 (信息论)
知乎 - 信息熵是什么?
CSDN - 最大熵模型中的数学推导