Redis数据库数据结构
Redis核心数据结构
一、什么是Redis
1、Rdies是一种非关系型的键值对数据库,取出或者插入关联值的时间复杂度为O(1);
2、Redis的数据存放在内存中;
3、键(key)的类型可以是字符串、整型、浮点型等,且键是唯一的;
4、值(val)的类型可以是string、hash、list、set、sorted set等;
5、Redis内置了复制,磁盘持久化,LUA脚本,事务,SSL,客户端代理等功能。
6、通过Redis烧饼和自动分区提高可用性。
二、应用场景
1、缓存
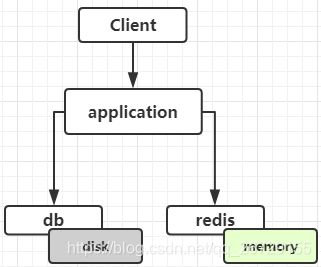
普通的数据库数据存放在硬盘文件上,IO速度慢。
而redis数据库的数据存放在内存中,所以可以当做缓存来使用。
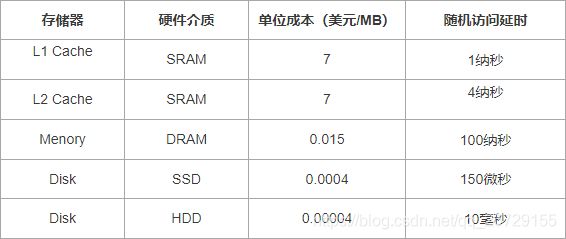
下图是一张16年左右的各种内存介质的成本和速度的统计表
2、计数器
可以对String进行自增自减运算,从而实现计数器功能。Redis这种内存型数据科的读写性能非常高,很适合存储频繁读写的计数量。
3、分布式ID生成
利用自增特性,一次请求一个大一点的步长如 incr 2000,缓存在本地使用,用完再请求。
4、海量数据统计
位图(bitmap):存储是否参加过某次活动,是否已读谋篇文章,用户是否为会员,日活跃统计。
5、会话缓存
可以使用Redis来统一存储多台应用服务器的会话信息。当应用服务器不在存储用户的会话信息,也就不在具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性和伸缩性
6、分布式队列\阻塞队列
LIst是一个双向链表,可以通过Ipush/rpushg和Ipop/rpop写入和读取消息。可以通过使用brpop/bIpop来实现阻塞队列。
7、分布式锁实现
在分布式场景下,无法使用基于进程的锁来对应多个节点上的进程进行同步。可以使用Redis自带的SETNX命令实现分布式锁。
8、热点数据存储
最新评论、最新文章列表,使用List存储, Itrim去除热点数据,删除老数据
9、社交类需求
Set可以实现交集,从而实现共同好友功能。Set通过求差集,可以进行好友推荐,文章推荐。
10、排行榜
ZSet可以实现有序性操作,可以非常简单的实现排行榜类型的功能
11、延迟队列
使用sorted_set,使用【当前时间戳+需要延迟的时长】做score,消息内容作为元素,调用zadd来生产消息,消费者使用zrangbyscore获取当前时间之前的数据做轮询处理,消费完再删除任务 rem key member。
三、数据结构
1、String
redis底层使用c来实现,但是基于c的string类型进行了优化,定义了一个sds(simple dynamic string)的数据类型。
为了字符串中有字符 '\0' ,定义了一个len,用来指示字符串的长度。
这么做的好处:
1、二进制安全的数据结构
2、为了避免重复内存的分配,进行了动态的扩容
3、字符数组以‘\0’结尾,兼容string字符串函数
/**
*redis 3.2以前的定义方式
*/
Struct sdshdr {
int len;
int free;
char buf[];
}
/**
*在3.2以前的定义方式中,每个sds都包含两个int,每个int占4个byte。如果字符串长度比较短,就会造成内存空间的浪费
*redis 3.2以后的定义方式
*/
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
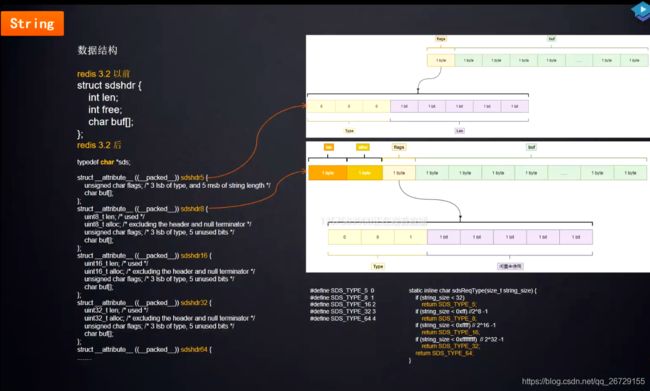
PS:上图中flags的高低位好像弄反了。
扩容机制——每次原长度和新加长度翻倍,大于1024*1024则每次添加1024*1024;
2、数据库整体结构
在没有修改配置的情况下,Redis数据库默认有16个子库DB,定义如下:
//默认16个dbs
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set 过期时间字典 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for NULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active axpire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one by one , gradually. */
} redisDb;
/**
*dict 定义如下
*/
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; /* 2个hashtable 扩容的时候用到第二个,渐进式扩容;头插法*/
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
typedef struct dicType{
uint64_t (*hashFunction) (const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*keyDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dicType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key; /* sds */
union {
void *val; /* redisObject */
uint64_t u64;
int64_t s64;
double d;
}
struct dictEntry *next;
} dictEntry;
typedef struct redisObject {
unsigned type:4; //4bit
unsigned encoding:4; //4bit
unsigned lru:LRU_BITS; // LRU time (relative to global lru_clock) or
// LFU data (least significant 8 bits frequency
// and most signifitant 16 bits aecess time).
int refcount; // 4byte
void *ptr; // 8byte
//总空间 4bit + 4bit + 24bit + 4byte + 8byte = 16byte;
} robj;在这里我们可以看到,每一个redisObject中都有一个ptr指针,指向真正的数据char[];
所以在redis的set command命令实现中又做了一次判断
if(len <= 20 && string2l(s, len, &value)){...//省略}从robj的定义可以看出,*ptr占8byte, 在基本数据类型中long同样占8byte;
如果string可以转换成long类型,那么就可以直接存放到*ptr的位置。可以减少查询char[]的次数,也可以减少没存占用。
完整的结构示意图

PS:
1、 同样的,根据robj的定义,robj占4bit + 4bit + 24bit + 4byte + 8byte = 16byte;sdshdr8 占4字节;而cpu每一次读取的缓存行cache line(64byte)
如果val< (64-16-8 = 44)字节,开辟一块内存空间64Byte,将robj、sdshdr8、val放到一起,减少一次cpuIO;
2、 mset 批量操作
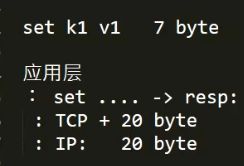
如图, 如果单次插入的key val过小,那么一次交互就浪费 33byte ;
mset k1 v1 k2 v2 k3 v3 批量操作 减少网络开销
实例:如何实现亿级用户日活统计
场景:现在一个系统,拥有亿级的活跃用户,为了增强用户粘性,要上线一个连续打卡发放积分的功能,请设计实现连续打卡的用户统计。
我们可以把userid定义为自增的unsigned int类型。(mysql 一般就是这么做的)。
每天建立一个bitmap,用来表示当天的用户登录情况,1表示当日签到,0表示当日未签到。用户id(userid)作为下标索引。
如图

那么,当日活跃用户的数量就可以用bitcount命令直接得到(2.6.0版本以后)。
月连续活跃用户可以通过将本月所有日活跃位图进行相与(&)操作来得到。