hadoop-2.6.0-cdh5.9.3分布式高可用部署
大家好,我是Linux运维工程师 Linke 。技术过硬,从不挖坑~
此文只说各组件的作用,部署搭建,不谈原理。知道这些基础组件的作用后,自个儿心中大概就对这玩意儿的工作方式有个差不多的了解了。好吧,其实我就这两下子,下面进入正题。(下面我是用root用户启动的,生产不用用root用户)
hdfs的一些专用词汇说明
NameNode: 负责管理文件系统的 namespace 以及客户端对文件的访问;
DataNode: 用于管理它所在节点上的存储;
FailoverController: 故障切换控制器,负责监控与切换 Namenode 服务;
JournalNode: 用于存储 EditLog;
Balancer: 用于平衡集群之间各节点的磁盘利用率;
HttpFS: 提供 HTTP 方式访问 HDFS 的功能;
EditLogs: 它包含最近对文件系统进行的与最新 FsImage 相关的所有修改;
FsImage: 它包含自 Namenode 开始以来文件的 namespace 的完整状态;
block : 是硬盘上存储数据的最不连续的位置,在 hadoop 集群中,每个 block 的默认大小为 128M;
checkpoint: 当 NameNode 启动时,它会从硬盘中读取 EditLog 和 FsImage,将所有 EditLog 中的事务作用在内存中的 FsImage 上,并将这个新版本的 FsImage 从内存中保存到本地磁盘上,然后删除旧的 EditLog,这个过程也被称为一个 checkpoint。
yarn以及MapReduce的一些专用词汇说明
yarn: hadoop的分布式资源管理框架,mapreduce作为计算引擎,运行在yarn里;
MapReduce: hadoop2.x 版本,MapReduce 进程是由 yarn 集群提供,在Hadoop内部用“作业”(Job)表示MapReduce程序。一个MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task);
Task Scheduler: 调度器,会在资源出现空闲时,选择合适的任务使用这些资源;
ResourceManager: 接收来自对yarn集群提交的请求,并指定NM分配Container。
NodeManager: 启动Container运行来自ResourceManager分配过来的任务。负责运行 所有TaskTracker 和 JobTracker,发送心跳给ResourceManager;
JobTracker: 主要负责所有TaskTracker与作业的健康状况资源监控和作业调度,一旦发现失败情况后,其会将相应的任务转移到其他节点;
TaskTracker: 周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker ,同时接收JobTracker发送过来的命令并执行相应操作(如启动新任务、杀手任务等);
slot: 等量划分本节点上的资源量(表现在cpu、mem上),一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用;
task: Task分为Map Task和Reduce Task两种,均由TaskTracker启动;
Map Task: 先将任务解析成一个个key/value对,然后依次进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分为若干个partition,每个partition将被一个Reduce Task处理;
Reduce Task: 执行过程分为三个阶段,1、从远程节点上读取Map Task的中间结果(称为“Shuffle阶段”);2、按照key对key/value键值对进行排序(称为“Sort阶段”);3、依次读取,调用用户自定义的reduce()函数处理,并将最终结果存放到HDFS上(称为“Reduce阶段”)。
首先从cdh官网下载 hadoop-2.6.0-cdh5.9.3.tar.gz 包。
http://archive.cloudera.com/cdh5/cdh/5/
一、服务器5台:
| 主机名 | ip | 部署方案 |
|---|---|---|
| namenode181 | 192.168.10.181 | ResourceManager、NameNode、DFSZKFailoverController |
| namenode182 | 192.168.10.182 | ResourceManager、NameNode、DFSZKFailoverController |
| datanode183 | 192.168.10.183 | QuorumPeerMain(zk进程名)、JournalNode、DataNode、NodeManager |
| datanode184 | 192.168.10.184 | QuorumPeerMain(zk进程名)、JournalNode、DataNode、NodeManager |
| datanode185 | 192.168.10.185 | QuorumPeerMain(zk进程名)、JournalNode、DataNode、NodeManager |
二、配置jdk环境变量;每台服务器添加 hosts ,并且免密登录,namenode用来远程启动使用
[root@namenode181 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.185 datanode185
192.168.10.184 datanode184
192.168.10.183 datanode183
192.168.10.182 namenode182
192.168.10.181 namenode181
[root@datanode181 ~]# java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
namenode181 namenode182 互相 ssh 免密码登录, namenode181 namenode182 到 datanode183 datanode184 datanode185 免密码登录。
从namenode181 和 namenode182 执行
[root@namenode181 ~]# ssh-keygen
[root@namenode181 ~]# ssh-copy-id namenode181
[root@namenode181 ~]# ssh-copy-id namenode182
[root@namenode181 ~]# ssh-copy-id datanode183
[root@namenode181 ~]# ssh-copy-id datanode184
[root@namenode181 ~]# ssh-copy-id datanode185
三、启动一个独立的 zookeeper 集群
推荐独立安装一个 zk 集群、随便挑一个版本,只要版本高的不是太离谱,应该都没问题。Linke 用的是 zookeeper-3.4.6 版本。怎么安装zk ,我直接跳过了,撸到此文的兄弟们应该都会自己安装。
jps命令查看,可以看到进程 QuorumPeerMain
[root@datanode184 zookeeper-3.4.6]# jps
20364 QuorumPeerMain
[root@datanode184 zookeeper-3.4.6]# /data/zookeeper-3.4.6/bin/zkServer.sh status
JMX enabled by default
Using config: /data/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
四、解压hadoop-2.6.0-cdh5.9.3压缩包到安装路径 /data 下,然后开始写我们的配置文件
1、解压文件到 /data 目录下
[root@namenode181 ~]# tar xvf hadoop-2.6.0-cdh5.9.3.tar.gz -C /data/
[root@namenode181 ~]# chown -R root. /data/hadoop-2.6.0-cdh5.9.3
[root@namenode181 ~]# cd /data/hadoop-2.6.0-cdh5.9.3
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# ls
bin bin-mapreduce1 cloudera etc examples examples-mapreduce1 include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share src
2、修改 etc/hadoop/core-site.xml 文件,此文件针对的是hdfs的全局配置
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://flinkhdfs/
hadoop.tmp.dir
/data/hadoop-2.6.0-cdh5.9.3/tmp
ha.zookeeper.quorum
datanode183:2181,datanode184:2181,datanode185:2181
fs.checkpoint.period
3600
fs.checkpoint.size
67108864
fs.checkpoint.dir
/data/hadoop-2.6.0-cdh5.9.3/namesecondary
3、修改 etc/hadoop/hdfs-site.xml 文件,此文件针对的是 hdfs 细节的配置。注意:dfs.ha.fencing.ssh.private-key-files 行配置,使用什么用户,填什么用户的id_rsa 路径
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# vim etc/hadoop/hdfs-site.xml
dfs.nameservices
flinkhdfs
dfs.ha.namenodes.flinkhdfs
namenode181,namenode182
dfs.namenode.rpc-address.flinkhdfs.namenode181
namenode181:9000
dfs.namenode.http-address.flinkhdfs.namenode181
namenode181:50070
dfs.namenode.rpc-address.flinkhdfs.namenode182
namenode182:9000
dfs.namenode.http-address.flinkhdfs.namenode182
namenode182:50070
dfs.namenode.shared.edits.dir
qjournal://datanode183:8485;datanode184:8485;datanode185:8485/flinkhdfs
dfs.journalnode.edits.dir
/data/hadoop-2.6.0-cdh5.9.3/journaldata
dfs.datanode.data.dir
file:///data/hadoop-2.6.0-cdh5.9.3/datanode
dfs.namenode.name.dir
file:///data/hadoop-2.6.0-cdh5.9.3/namenode
dfs.replication
2
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.flinkhdfs
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
4、修改 etc/hadoop/yarn-site.xml , yarn集群的详细配置
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# vim etc/hadoop/yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
flinkyarn
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
namenode181
yarn.resourcemanager.hostname.rm2
namenode182
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-address
datanode183:2181,datanode184:2181,datanode185:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
5、修改 etc/hadoop/mapred-site.xml
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
dfs.replication
2
6、修改 etc/hadoop/slaves ,此文件用来告诉NameNode在哪里起DataNode;告诉ResourceManager在哪里起NodeManager
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# vim etc/hadoop/slaves
datanode183
datanode184
datanode185
7、创建上诉配置文件中涉及到的目录
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# mkdir namenode namesecondary journaldata datanode
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# ls
bin cloudera etc examples-mapreduce1 journaldata libexec namenode NOTICE.txt sbin src
bin-mapreduce1 datanode examples include lib LICENSE.txt namesecondary README.txt share
8、将目录分发到每台服务器
是的,你没看错,所有节点全部使用相同的配置文件
五、启动hdfs高可用集群
这里Linke要用最简单粗暴的方式启动集群。
1、在datanode183 、datanode184、datanode185 启动journalnode ; 注意一下,是用 hadoop-daemons.sh 脚本启动,而不是 hadoop-daemon.sh ,前者是启动JournalNode集群的,不知道是不是读的etc/hadoop/slaves 这个文件中节点信息,后者是启动单个节点的。启动后,分别在三台 JournalNode 节点可以看到 JournalNode 进程,它是干嘛用的,请看一开始的介绍。根据etc/hadoop/hdfs-site.xml配置文件中所写,他的数据目录我放在了/data/hadoop-2.6.0-cdh5.9.3/journaldata ,此时此目录中不会有文件存在(此处画重点)。
[root@datanode183 hadoop-2.6.0-cdh5.9.3]# sbin/hadoop-daemons.sh start journalnode
datanode184: starting journalnode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-journalnode-datanode184.out
datanode183: starting journalnode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-journalnode-datanode183.out
datanode185: starting journalnode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-journalnode-datanode185.out
[root@datanode183 hadoop-2.6.0-cdh5.9.3]# jps
25144 JournalNode
22332 QuorumPeerMain
2、在 namenode181 格式化HDFS,跑完没有报错说明格式化完毕,然后会再namenode目录下生成初始的namenode集群文件
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs namenode -format
19/09/06 18:16:11 INFO namenode.FSNamesystem: ACLs enabled? false
19/09/06 18:16:11 INFO namenode.FSNamesystem: XAttrs enabled? true
19/09/06 18:16:11 INFO namenode.FSNamesystem: Maximum size of an xattr: 16384
19/09/06 18:16:12 INFO namenode.FSImage: Allocated new BlockPoolId: BP-76872703-192.168.10.181-1567764972634
19/09/06 18:16:12 INFO common.Storage: Storage directory /data/hadoop-2.6.0-cdh5.9.3/namenode has been successfully formatted.
19/09/06 18:16:12 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop-2.6.0-cdh5.9.3/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
19/09/06 18:16:12 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop-2.6.0-cdh5.9.3/namenode/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
19/09/06 18:16:12 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/09/06 18:16:12 INFO util.ExitUtil: Exiting with status 0
19/09/06 18:16:12 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at namenode181/192.168.10.181
************************************************************/
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# ls namenode/
current
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# ls namenode/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
3、将namenode直接传到 namenode182 上
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# scp -r namenode/ namenode182:/data/hadoop-2.6.0-cdh5.9.3/
VERSION 100% 205 184.0KB/s 00:00
seen_txid 100% 2 1.8KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 60.5KB/s 00:00
fsimage_0000000000000000000
4、在 namenode181 格式化ZKFC,如下没有报错说明格式化没问题
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs zkfc -formatZK
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-957.21.3.el7.x86_64
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Client environment:user.name=root
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Client environment:user.home=/root
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Client environment:user.dir=/data/hadoop-2.6.0-cdh5.9.3
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=datanode184:2181,datanode185:2181,datanode183:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@239e2011
19/09/06 18:22:38 INFO zookeeper.ClientCnxn: Opening socket connection to server datanode184/192.168.10.184:2181. Will not attempt to authenticate using SASL (unknown error)
19/09/06 18:22:38 INFO zookeeper.ClientCnxn: Socket connection established, initiating session, client: /192.168.10.181:52048, server: datanode184/192.168.10.184:2181
19/09/06 18:22:38 INFO zookeeper.ClientCnxn: Session establishment complete on server datanode184/192.168.10.184:2181, sessionid = 0x26d0609934a0000, negotiated timeout = 5000
19/09/06 18:22:38 INFO ha.ActiveStandbyElector: Session connected.
19/09/06 18:22:38 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/datahdfs in ZK.
19/09/06 18:22:38 INFO zookeeper.ZooKeeper: Session: 0x26d0609934a0000 closed
19/09/06 18:22:38 INFO zookeeper.ClientCnxn: EventThread shut down
5、在 namenode181 启动HDFS,并查看进程, NameNode和DFSZKFailoverController已经启动
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# sbin/start-dfs.sh
Starting namenodes on [namenode181 namenode182]
namenode181: starting namenode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-namenode-namenode181.out
namenode182: starting namenode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-namenode-namenode182.out
datanode184: starting datanode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-datanode-datanode184.out
datanode185: starting datanode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-datanode-datanode185.out
datanode183: starting datanode, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-datanode-datanode183.out
Starting journal nodes [datanode183 datanode184 datanode185]
datanode184: journalnode running as process 835. Stop it first.
datanode185: journalnode running as process 3972. Stop it first.
datanode183: journalnode running as process 2703. Stop it first.
Starting ZK Failover Controllers on NN hosts [namenode181 namenode182]
namenode181: starting zkfc, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-zkfc-namenode181.out
namenode182: starting zkfc, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/hadoop-root-zkfc-namenode182.out
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# jps
21151 DFSZKFailoverController
20872 NameNode
21207 Jps
6、在 namenode182 上查看进程,NameNode和DFSZKFailoverController已经启动
[root@namenode182 hadoop-2.6.0-cdh5.9.3]# jps
22480 NameNode
22572 DFSZKFailoverController
22638 Jps
7、在 datanode183 、datanode184、datanode185 上查看进程,新增了DataNode
[root@datanode183 hadoop-2.6.0-cdh5.9.3]# jps
2593 QuorumPeerMain
2823 DataNode
2923 Jps
2703 JournalNode
8、在 namenode181 启动启动YARN,并查看进程,ResourceManager已经启动,此时各nodemanager节点进程也已经启动
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/yarn-root-resourcemanager-namenode181.out
datanode184: starting nodemanager, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/yarn-root-nodemanager-datanode184.out
datanode183: starting nodemanager, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/yarn-root-nodemanager-datanode183.out
datanode185: starting nodemanager, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/yarn-root-nodemanager-datanode185.out
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# jps
21151 DFSZKFailoverController
20872 NameNode
21558 Jps
21293 ResourceManager
9、在datanode183 、datanode184、datanode185 上查看进程,新增了 NodeManager 进程
[root@datanode184 hadoop-2.6.0-cdh5.9.3]# jps
736 QuorumPeerMain
1169 Jps
835 JournalNode
1060 NodeManager
934 DataNode
10、在namenode182上启动ResourceManager备用节点(yarn备用节点需要单独启动,hdfs的备用节点会随着主namenode节点启动)。
[root@namenode182 hadoop-2.6.0-cdh5.9.3]# jps
22480 NameNode
22675 Jps
22572 DFSZKFailoverController
[root@namenode182 hadoop-2.6.0-cdh5.9.3]#
[root@namenode182 hadoop-2.6.0-cdh5.9.3]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /data/hadoop-2.6.0-cdh5.9.3/logs/yarn-root-resourcemanager-namenode182.out
[root@namenode182 hadoop-2.6.0-cdh5.9.3]# jps
22480 NameNode
22759 Jps
22572 DFSZKFailoverController
22703 ResourceManager
11、检查主备节点 namenode 的状态
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs haadmin -getServiceState namenode181
standby
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs haadmin -getServiceState namenode182
active
12、检查 resourcemanager 的状态
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# yarn rmadmin -getServiceState rm1
19/09/06 18:41:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# yarn rmadmin -getServiceState rm2
19/09/06 18:41:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
经过这么多步骤,终于启动完毕了,Linke已经感觉到达了高潮。下面让我们来测试一下hdfs写入文件。
六、测试hdfs写入文件,和读取文件
hdfs命令自己去百度几把,这里Linke不介绍
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -ls /
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -mkdir /test
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2019-09-06 18:43 /test
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -put /etc/passwd /test/
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -ls /test
Found 1 items
-rw-r--r-- 3 root supergroup 1035 2019-09-06 18:43 /test/passwd
[root@namenode181 hadoop-2.6.0-cdh5.9.3]# hdfs dfs -cat /test/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-bus-proxy:x:999:998:systemd Bus Proxy:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:998:997:User for polkitd:/:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
test:x:1000:1000::/home/test:/bin/bash
七、查看hdfs和yarn的web页面
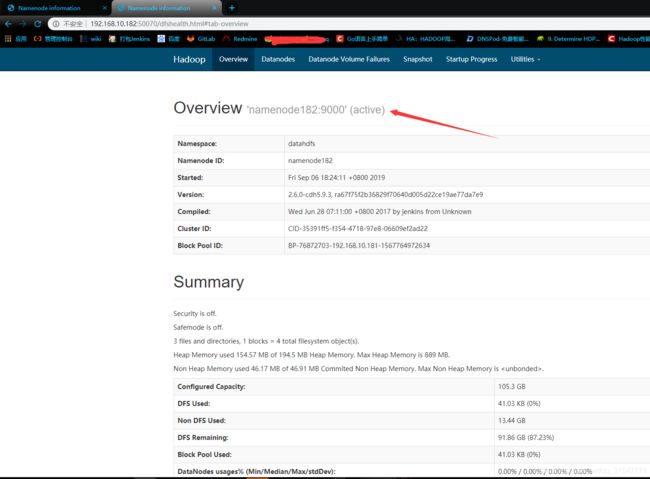
浏览器输入namenode主节点ip加端口,我的namenode主节点是namenode182
192.168.10.182:50070
查看hdfs中的文件
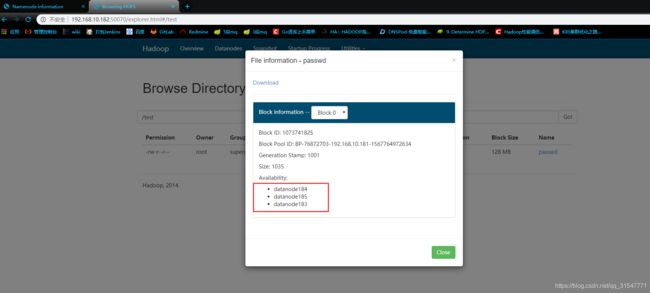
红框中为所有副本所在的节点,并且只有Block0 一个块儿,你们可以上传一个大的文件,比如500M的,然后就会有多个块儿了。为 500/128 个块儿。
浏览器输入ResourceManager 主节点ip加端口,我的ResourceManager 主节点是namenode181
192.168.10.181:8088
yarn集群提交任务后在这里可以看到任务成功或者失败的状态
由于时间关系,就不测yarn集群提交任务了,不过可以提供一个测试命令,注意,提交的目标目录 testyarn1 必须要没有,提交了以后会自动生成 testyarn1 目录
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.9.3.jar wordcount /test/passwd /testyarn1
八、单独重启某个节点的方式
1、datanode节点重启
单独重启某个 datanode ,到对应节点下
sbin/hadoop-daemon.sh start datanode
2、 journalnode 单个节点故障,到对应节点下
sbin/hadoop-daemon.sh start journalnode
3、namenode单个节点故障,到对应节点下
sbin/hadoop-daemon.sh start namenode
4、yarn集群 ResourceManager 单个节点故障,到对应节点下
sbin/yarn-daemon.sh start resourcemanager
5、yarn集群 NodeManager 如果挂掉,在 yarn 主节点启动
sbin/start-yarn.sh