【caffe学习】caffe第二个比较典型的识别例子CIFAR_10的运行详解
版权声明:
本文为博主原创文章,未经博主允许不得转载
文件说明:
1=== 这是caffe的第二个比较典型的例子Cifar10
2 === 详细分析了Cifar10的数据集和模型结构
3 === 给出了Cifar10的运行步骤
运行环境:
Ubantu14.04 +caffe+python可视化接口
时间地点:
陕西师范大学-------2017.1.16
参考资料:
http://blog.csdn.net/maweifei/article/details/52981425
http://www.cs.toronto.edu/~kriz/cifar.html
(一)CIFAR10简介
Cifar10是是由Hinton的两大弟子Alex Krizhevsky,ilya Sutskever收集的一个用于普适物体识别的数据集。Cifar是加拿大政府牵头投资的一个先进科学项目研究所。Hinton,Bengio以及他的学生在2004年拿到了Cifar投资的少量资金,建立了神经计算和自适应感知项目。这个项目集结了不少的计算机科学家,生物学家,电气工程师,神经科学家,心理学家,加速推动了DL的进程。从这个阵容来看,DL已经和ML系的数据挖掘分的很远了。
DL强调的是自适应感知和人工智能,是计算机与神经科学的交叉。DM强调的是告诉,大数据,统计数学分析,是计算机与数学的交叉。
(二)Cifar-10数据集简介
1 === Cifar-10由60000张32*32的RGB(三通道)彩色图构成,共10个分类
2 === 其中50000张为训练样本(训练集),10000为测试样本(测试集)
3 === 注意
(1) --- 这个数据集做大的特点在于将识别迁移到普适物体
(2) --- 可以将10分类问题扩展至100类物体的分类,甚至1000类和更多类的物体分类
(3) --- 该示例 中的数据集存放在一个10000*3072数组中----10000张图片×每张图片的像素数组
(4) --- 3072存储了一个32*32的彩色图片(3*32*32=3*1024=3072)
(5) --- numply的前1024位是RGB图像中的R分量像素值,中间的1024位是G分量的像素值,最后的1024是B分量的像素值
(6) --- Cifar10这个例子只能用于[小图片]的分类,类似于前面所讲的Mnist示例,主要用于【手写数字的识别一样】
(三)Cifar-10数据集的示例图

(四)Cifar10所使用的卷积神经CNN的网络模型
1 === DL的的两大核心:数据+模型,数据集在上面已经详细给出,下面是Caffe10中所使用的网络(net)模型
2 === 该模型在caffe安装目录下,文件名为:cifar10_quick_train_test.prototxt。具体路径为/home/wei/caffe/examples/cifar10/cifar10_quick_train_test.prototxt
3 === 该CNN-NET主要由:卷基层,POOLing层,非线性变换层,局部对比归一化线性分类器等组成
4 === 如下所示
(五)Cifar-10示例的具体训练操作过程
1 === 下载数据集
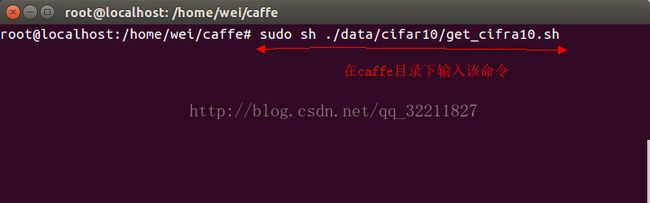
执行下面的命令:sudo sh ./data/cifar10/get_cifra10.sh (注:该命令是在linux操作系统终端的Caffe目录下运行的),如下图所示
下载完成后 在/home/wei/caffe/data/cifar10 文件目录下看到以下的二进制文件数据 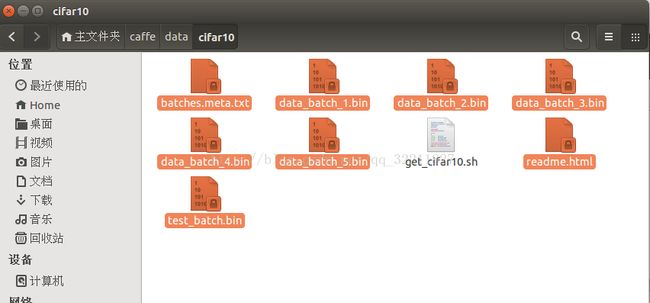
2 === 将刚下载进来的【二进制数据文件】转换成【caffe所识别的LMDB格式的数据库形式】,并且计算数据集的均值文件
1 === 数据格式的转化和计算均值所要使用的所有shell命令都被写在了一个shell脚本中,所以我们只需要运行这个shell脚本就可以了,
这个shell脚本在/home/wei/caffe/examples/cifar10目录下,名称为create_cifar10.sh
3 === 下载成功之后,会在/home/wei/caffe/examples/cifar10目录下生成三个文件--------如下图所示: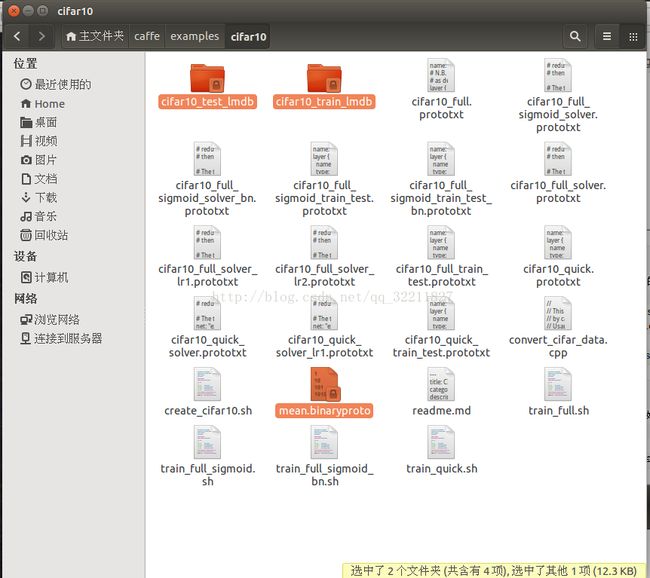
(六)训练和测试网络模型
在这个阶段,要准备三个文件,当然caffe已经为我们准备好了
1 === 网络模型配置文件:cifar10_quick_train_test.prototxt --------所在目录------/home/wei/caffe/examples/cifar10
2 === 超参数配置文件solver:cifar10_quick_solver.prototxt --------所在目录------/home/wei/caffe/examples/cifar10/
3 === 训练脚本文件:train_quick.sh --------所在目录--------/home/wei/caffe/examples/cifar10
4 === 编写训练模型的shell脚本文件train_quick.sh ,但是由于我使用的CPU没有GPU,所以在编写该文件之前,还应该修改cifar10_quick_solver.prototxt文件的
最后一项:将GPU改为CPU
准备好数据+模型+solver文件之后,执行下面的命令:
sudo ./examples/cifar10/train_quick.sh -----如下图所示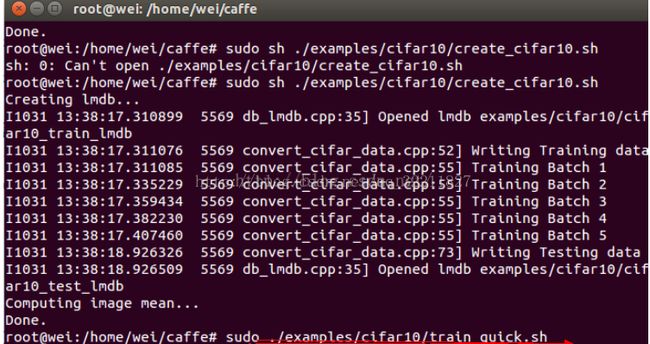
训练过程如下图所示:
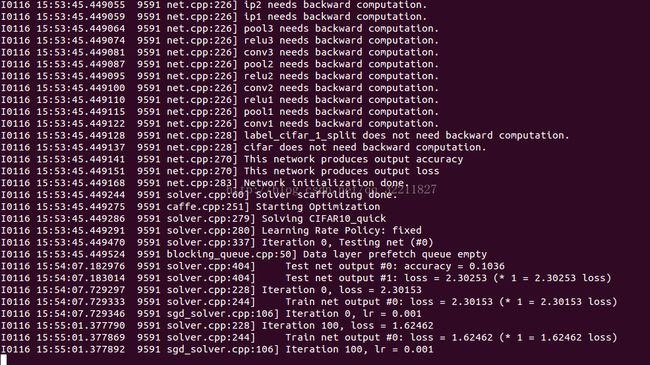
其中,每迭代100次,显示一次训练时的lr(学习率)和loss(训练损失)。
注:
训练完成之后,训练好的模型参数存储在protobuf格式的文件中,Cifar-10训练好的模型存储在/home/wei/caffe/examples/cifar10/文件夹下
(最后)总结一下一个网络用到的相关文件
- cifar10_quick_solver.prototxt:方案配置,用于配置迭代次数等信息,训练时直接调用caffe train指定这个文件,就会开始训练
- cifar10_quick_train_test.prototxt:训练网络配置,用来设置训练用的网络,这个文件的名字会在solver.prototxt里指定
- cifar10_quick_iter_4000.caffemodel.h5:训练出来的模型,后面就用这个模型来做分类
- cifar10_quick_iter_4000.solverstate.h5:也是训练出来的,应该是用来中断后继续训练用的文件
- cifar10_quick.prototxt:分类用的网络