Kafka详解(二):主题与分区、日志存储(KafkaAdminClient、优先副本的选举、分区重分配、日志清理、页缓存、零拷贝)
四、主题与分区
1、主题的管理
可以通过kafka-topics.sh脚本来执行创建主题、查看主题信息、修改主题和删除主题等操作,这个脚本位于$KAFKA_HOME/bin/目录下
1)、创建主题
如果broker端配置参数auto.create.topics.enable设置为true(默认值为true),那么当生产者向一个尚未创建的主题发送消息时,会自动创建一个分区数为num.partitions(默认值为1)、副本因子为default.replication.factor(默认值为1)的主题。除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会按照配置参数num.partitions和default.replication.factor的值来创建一个相应的主题。不建议将auto.create.topics.enable设置为true
创建一个分区数为4、副本因子为2的主题
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create --partitions 4 --replication-factor 2
在执行完脚本之后,Kafka会在log.dir或log.dirs参数所配置的目录下创建相应的主题分区
[root@localhost bin]# ls -al /tmp/kafka01-logs/ |grep topic-create
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-1
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-2
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-3
[root@localhost bin]# ls -al /tmp/kafka02-logs/ |grep topic-create
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-0
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-2
[root@localhost bin]# ls -al /tmp/kafka03-logs/ |grep topic-create
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-0
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-1
drwxr-xr-x. 2 root root 141 5月 22 06:23 topic-create-3
三个broker节点一共创建了8个文件夹,这个数字实际上是分区数4与副本因子2的乘积。每个副本(或者说日志,副本与日志一一对应)对应了一个命名形式如
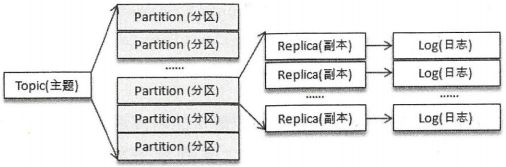
主题和分区都是提供给上层用户的抽象,而在副本层面或更加确切地说是Log层面才有实际物理上的存在。同一个分区中的多个副本必须分布在不同的broker中,才能提供有效的数据冗余
使用describe指令类型来查看分区副本的分配细节
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create
Topic:topic-create PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-create Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: topic-create Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-create Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: topic-create Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic和Partition分别代表主题名称和分区号。PartitionCount表示主题中分区的个数,ReplicationFactor表示副本因子,而Configs表示创建或修改主题时指定的参数配置。Leader表示分区的leader副本所对应的brokerId,Isr表示分区的ISR集合,Replicas表示分区的所有的副本分配情况,即AR集合,其中的数字都表示的是brokerId
kafka-topics.sh脚本中还提供了一个replica-assignment参数来手动指定分区副本的分配方案:
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create-same --replica-assignment 2:0,0:1,1:2,2:1
这种方式根据分区号的数值大小按照从小到大的顺序进行排序,分区与分区之间用逗号,隔开,分区内多个副本用冒号:隔开。并且在使用–replica-assignment参数创建主题时不需要原本必备的partitions和replication-factor这两个参数。创建时注意同一分区内的副本不能有重复
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create-same
Topic:topic-create-same PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-create-same Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: topic-create-same Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: topic-create-same Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: topic-create-same Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1
使用config参数创建一个主题
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-config --replication-factor 1 --partitions 1 --config cleanup.policy=compact --config max.message.bytes=10000
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-config
Topic:topic-config PartitionCount:1 ReplicationFactor:1 Configs:cleanup.policy=compact,max.message.bytes=10000
Topic: topic-config Partition: 0 Leader: 0 Replicas: 0 Isr: 0
创建主题时发生命名冲突会报出TopicExistsException的异常信息。kafka-topics.sh脚本中提供了一个if-not-exists参数,如果在创建主题时带上了这个参数,那么在发生命名冲突时将不做任何处理(既不创建主题,也不报错)。如果没有发生命名冲突,那么和不带if-not-exists参数的行为一样正常创建主题
Kafka的内部做埋点时会根据主题的名称来命名metrics的名称,并且会将点号.改成下划线_
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic_1.2 --replication-factor 1 --partitions 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to us
e either, but not both.
Created topic "topic_1.2".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic.1_2 --replication-factor 1 --partitions 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to us
e either, but not both.
Error while executing topic command : Topic 'topic.1_2' collides with existing topics: topic_1.2
[2019-05-22 07:00:05,489] ERROR org.apache.kafka.common.errors.InvalidTopicException: Topic 'topic.1_2' collides with existing topics: topi
c_1.2
(kafka.admin.TopicCommand$)
Kafka支持指定broker的机架信息。如果指定了机架信息,则在分区副本分配时会尽可能地让分区副本分配到不同的机架上。指定机架信息是通过broker端参数broker.rack来配置的,比如配置当前broker所在的机架为RACK1
broker.rack=RACK1
如果一个集群中有部分broker指定了机架信息,并且其余的broker没有指定机架信息,那么在执行kafka-topics.sh脚本创建主题时会报出AdminOperationException异常。此时若要成功创建主题,要么将集群中的所有broker都加上机架信息或都去掉机架细腻,要么使用disable-rack-aware参数来忽略机架信息
2)、查看主题
通过list指令可以查看当前所有可用的主题
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 -list
__consumer_offsets
topic-config
topic-create
topic-create-same
topic-demo
topic_1.2
通过describe指令来查看指定主题的信息
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-create,topic-create-same
Topic:topic-create PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-create Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: topic-create Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-create Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: topic-create Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic:topic-create-same PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-create-same Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: topic-create-same Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: topic-create-same Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: topic-create-same Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1
topics-with-overrides参数可以找出所有包含覆盖配置的主题
under-replicated-partitions参数可以找出所有包含失效副本的分区。此时分区的ISR集合小于AR集合
unabailable-partitions参数可以查看主题中没有leader副本的分区,这些分区已经处于离线状态
3)、修改主题
修改topic-config主题的分区数为3
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --partitions 3
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-config
Topic:topic-config PartitionCount:3 ReplicationFactor:1 Configs:cleanup.policy=compact,max.message.bytes=10000
Topic: topic-config Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: topic-config Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: topic-config Partition: 2 Leader: 2 Replicas: 2 Isr: 2
上面提示的告警信息:当主题中的消息包含key时,根据key计算分区的行为就会受到影响。当topic-config的分区数为1时,不管消息的key为何值,消息都会发往这一个分区;当分区数增加到3时,就会根据消息的key来计算分区号,原本发往分区0的消息现在有可能会发往分区1或分区2,而且还会影响既定消息的顺序
Kafka只支持增加分区数而不支持减少分区数
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --partitions 1
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can only be increased. Topic topic-config currently has 3 partit
ions, 1 would not be an increase.
[2019-05-22 07:22:13,176] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: The number of partitions for a topic can only be
increased. Topic topic-config currently has 3 partitions, 1 would not be an increase.
(kafka.admin.TopicCommand$)
所修改的主题不存在,可以通过if-exists参数来忽略异常
可以通过alter指令配合config参数增加或修改一些配置以覆盖它们配置原有的值
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --config max.message.bytes=20000
WARNING: Altering topic configuration from this script has been deprecated and may be removed in future releases.
Going forward, please use kafka-configs.sh for this functionality
Updated config for topic "topic-config".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-config
Topic:topic-config PartitionCount:3 ReplicationFactor:1 Configs:max.message.bytes=20000,cleanup.policy=compact
Topic: topic-config Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: topic-config Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: topic-config Partition: 2 Leader: 2 Replicas: 2 Isr: 2
可以通过delete-config参数来删除之前覆盖的配置,使其恢复原有的默认值
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --delete-config max.message.bytes
WARNING: Altering topic configuration from this script has been deprecated and may be removed in future releases.
Going forward, please use kafka-configs.sh for this functionality
Updated config for topic "topic-config".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-config
Topic:topic-config PartitionCount:3 ReplicationFactor:1 Configs:cleanup.policy=compact
Topic: topic-config Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: topic-config Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: topic-config Partition: 2 Leader: 2 Replicas: 2 Isr: 2
4)、配置管理
kafka-configs.sh脚本使用–describe指定了查看配置的指令动作,–entity-type指定了查看配置的实体类型,–entity-name指定了查看配置的实体名称

[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name topic-config
Configs for topic 'topic-config' are cleanup.policy=compact
add-config参数用来实现配置的赠、改
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name topic-config --add-config max.message.bytes=10000
Completed Updating config for entity: topic 'topic-config'.
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name topic-config
Configs for topic 'topic-config' are cleanup.policy=compact,max.message.bytes=10000
使用kafka-configs.sh脚本来变更配置时,会在ZooKeeper中创建一个命名形式为/config/的节点,并将变更的配置写入这个节点中
[zk: localhost:2181(CONNECTED) 2] get /config/topics/topic-config
{"version":1,"config":{"cleanup.policy":"compact","max.message.bytes":"10000"}}
变更配置时还会在ZooKeeper中的/config/changes/节点下创建一个以config_change_为前缀的持久顺序节点,节点命名形式可以归纳为config_change_(seqNo是一个单调递增的10位数字的字符串,不足位则用0补齐)
delete-config参数用来实现配置的删
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name topic-config --delete-config max.message.bytes,cleanup.policy
Completed Updating config for entity: topic 'topic-config'.
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name topic-config
Configs for topic 'topic-config' are
使用kafka-configs.sh查看entity-type所对应的所有配置信息
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics
Configs for topic '__consumer_offsets' are segment.bytes=104857600,cleanup.policy=compact,compression.type=producer
Configs for topic 'topic-create-same' are
Configs for topic 'topic-demo' are
Configs for topic 'topic-create' are
Configs for topic 'topic_1.2' are
Configs for topic 'topic-config' are
5)、删除主题
kafka-topics.sh脚本中的delete指令用来删除主题
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic-config
Topic topic-config is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
必须将delete.topic.enable参数配置为true才能够删除主题,这个参数的默认值就是true,如果配置为false,那么删除主题的操作将会被忽略
也可以使用if-exists参数忽略删除不存在的主题报出的异常
使用kafka-topics.sh脚本删除主题的行为本质上只是在ZooKeeper中的/admin/delete_topics路径下创建一个与待删除主题同名的节点,以此标记该主题为待删除的状态。与创建主题相同的是,真正删除主题的动作是由Kafka的控制器负责完成的
2、初识KafkaAdminClient
1)、基本使用
KafkaAdminClient继承了org.apache.kafka.clients.admin.AdminClient抽象类,主要方法如下:
- 创建主题:
CreateTopicsResult createTopics(CollectionnewTopics) - 删除主题:
DeleteTopicsResult deleteTopics(Collectiontopics) - 列出所有可用的主题:
ListTopicsResult listTopics() - 查看主题的信息:
DescribeTopicsResult describeTopics(CollectiontopicNames) - 查询配置信息:
DescribeConfigsResult describeConfigs(Collectionresources) - 修改配置信息:
AlterConfigsResult alterConfigs(Map - 增加分区:
CreatePartitionsResult createPartitions(Map
1)创建主题topic-admin
@RunWith(SpringRunner.class)
@SpringBootTest
public class KafkaAdminTest {
@Test
public void createTopic() {
String brokerList = "192.168.126.158:9092";
String topic = "topic-admin";
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
AdminClient client = AdminClient.create(props);
NewTopic newTopic = new NewTopic(topic, 4, (short) 1);
CreateTopicsResult result = client.createTopics(Collections.singleton(newTopic));
try {
result.all().get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
client.close();
}
}
}
AdminClient.create()方法实际上调用的就是KafkaAdminClient中的createInternal方法构建的KafkaAdminClient实例
public static AdminClient create(Properties props) {
return KafkaAdminClient.createInternal(new AdminClientConfig(props), null);
}
NewTopic用来设定所要创建主题的具体信息
public class NewTopic {
private final String name;//主题名称
private final int numPartitions;//分区数
private final short replicationFactor;//副本因子
private final Map<Integer, List<Integer>> replicasAssignments;//分配方案
private Map<String, String> configs = null;//配置
可以通过指定分区数和副本因子来创建一个主题
Map<Integer, List<Integer>> replicasAssignments = new HashMap<>();
replicasAssignments.put(0, Arrays.asList(0));
replicasAssignments.put(1, Arrays.asList(0));
replicasAssignments.put(2, Arrays.asList(0));
replicasAssignments.put(3, Arrays.asList(0));
NewTopic newTopic = new NewTopic(topic, replicasAssignments);
也可以在创建主题时指定需要覆盖的配置
Map<String, String> configs=new HashMap<>();
configs.put("cleanup.policy","compact");
newTopic.configs(configs);
public class CreateTopicsResult {
private final Map<String, KafkaFuture<Void>> futures;
CreateTopicsResult(Map<String, KafkaFuture<Void>> futures) {
this.futures = futures;
}
public Map<String, KafkaFuture<Void>> values() {
return futures;
}
public KafkaFuture<Void> all() {
return KafkaFuture.allOf(futures.values().toArray(new KafkaFuture[0]));
}
}
CreateTopicsResult中的方法主要是针对成员变量futures的操作,futures的类型Map中的key代表主题名称,而KafkaFuture代表创建后的返回值类型。KafkaAdminClient中的createTopics()方法可以一次性创建多个主题。KafkaFuture实现了Future接口,可以通过Future.get()方法来等待服务端的返回
KafkaAdminClient中的listTopics()方法的返回值为ListTopicsResult类型,这个ListTopicsResult类型内部的成员变量future的类型为KafkaFuture,这里包含了具体的返回信息
使用close()方法释放资源
2)查看刚刚创建的主题topic-admin的具体配置信息
String brokerList = "192.168.126.158:9092";
String topic = "topic-admin";
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
AdminClient client = AdminClient.create(props);
ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC, topic);
DescribeConfigsResult result = client.describeConfigs(Collections.singleton(resource));
Config config = result.all().get().get(resource);
System.out.println(config);
client.close();
3)将主题topic-admin的cleanup.policy参数修改为compact
ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC, topic);
ConfigEntry entry = new ConfigEntry("cleanup.policy", "compact");
Config config = new Config(Collections.singleton(entry));
Map<ConfigResource, Config> configs = new HashMap<>();
configs.put(resource, config);
AlterConfigsResult result = client.alterConfigs(configs);
result.all().get();
4)将主题topic-admin的分区增加到5
NewPartitions newPartitions = NewPartitions.increaseTo(5);
Map<String, NewPartitions> newPartitionsMap = new HashMap<>();
newPartitionsMap.put(topic, newPartitions);
CreatePartitionsResult result = client.createPartitions(newPartitionsMap);
result.all().get();
2)、主题合法性验证
Kafka broker端create.topic.policy.class.name参数,默认值为null,它提供了一个入口用来验证主题创建的合法性,需要自定义实现org.apache.kafka.server.policy.CreateTopicPolicy接口,然后在broker端的配置文件config/server.properties中配置参数create.topic.policy.class.name的值
主要实现接口的configure()、close()和validate()方法,configure()方法会在Kafka服务启动的时候执行,validate()方法用来鉴定主题参数的合法性,在创建主题时执行,close()方法在关闭Kafka服务时执行
3、分区管理
1)、优先副本的选举
在创建主题的时候,该主题的分区及副本会尽可能均匀地分布到Kafka集群的各个broker节点上,对应的leader副本的分配也比较均匀
创建一个分区数为3、副本因子为3的主题topic-partitions
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-partitions --partitions 3 --replication-factor 3
Created topic "topic-partitions".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-partitions
Topic:topic-partitions PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic-partitions Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: topic-partitions Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: topic-partitions Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
可以看到leader副本均匀分布在brokerId为0、1、2的broker节点之中。针对同一个分区而言,同一个broker节点中不可能出现它的多个副本,即Kafka集群的一个broker中最多只能有它的一个副本,可以将leader副本所在的broker节点叫作分区的leader节点,而follower副本所在的broker节点叫作分区的follower节点
当分区的leader节点发生故障时,其中一个follower节点就会成为新的leader节点,这样就会导致集群的负载不均衡。当原来的leader节点恢复之后重新加入集群时,它只能成为一个新的follower节点而不再对外提供服务。比如将brokerId为2的节点重启,那么主题topic-partitions新的分布信息如下:
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-partitions
Topic:topic-partitions PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic-partitions Partition: 0 Leader: 2 Replicas: 0,2,1 Isr: 2,1,0
Topic: topic-partitions Partition: 1 Leader: 2 Replicas: 1,0,2 Isr: 2,1,0
Topic: topic-partitions Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
优先副本是指在AR集合列表中的第一个副本,比如上面主题的topic-partitions中分区0的AR集合[1,0,2],那么分区0的优先副本就是1。理想情况下,优先副本就是该分区的leader副本。Kafka要确保所有主题的优先副本在Kafka集群中均匀分布,这样就保证了所有分区的leader均衡分布。如果leader分布过于集中,就会造成集群负载不均衡
优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也可以称为分区平衡
Kafka提供分区自动平衡的功能,与此对应的broker参数是auto.leader.rebalance.enable,此参数的默认值为true,默认情况下此功能是开启的。如果开启分区自动平衡的功能,则Kafka的控制器会启动一个定时任务,这个定时任务会轮询所有的broker节点,计算每个broker节点的分区不平衡率(broker中的不平衡率=非优先副本的leader个数/分区总数)是否超过leader.imbalance.per.broker.percentage参数配置的比值,默认值为10%,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。执行周期由参数leader.imbalance.check.interval.seconds控制,默认值为300秒,即5分钟
Kafka中kafka-preferred-replica-election.sh脚本提供了对分区leader副本进行重新平衡的功能。优先副本的选举过程是一个安全的过程,Kafka客户端可以自动感知分区leader副本的变更
[root@localhost bin]# ./kafka-preferred-replica-election.sh --zookeeper localhost:2181
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-partitions
Topic:topic-partitions PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic-partitions Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 2,1,0
Topic: topic-partitions Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 2,1,0
Topic: topic-partitions Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
上面这种方式会将集群上所有的分区都执行一遍优先副本的选举操作,分区数越多打印出来的信息也就越多。leader副本的转移是一项高成本的工作,如果要执行的分区数很多,那么必然会对客户端造成一定的影响。在优先副本的选举过程中,具体的元数据信息会被存入ZooKeeper的/admin/preferred_replica_election节点,如果这些数据超过了ZooKeeper节点所允许的大小,那么选举就会失败。默认情况下ZooKeeper所允许的节点数据大小为1MB
kafka-preferred-replica-election.sh脚本还提供了path-to-json-file参数来小批量地对部分分区执行优先副本的选举操作。通过path-to-json-file参数来指定一个JSON文件,这个JSON文件里保存需要执行优先副本选举的分区清单
只想对主题topic-partitions执行优先副本的选举操作,先创建一个JSON文件,文件名为election.json,内容如下:
{
"partitions": [{
"partition": 0,
"topic": "topic-partitions"
},
{
"partition": 1,
"topic": "topic-partitions"
},
{
"partition": 2,
"topic": "topic-partitions"
}
]
}
[root@localhost bin]# ./kafka-preferred-replica-election.sh --zookeeper localhost:2181 --path-to-json-file election.json
2)、分区重分配
Kafka提供了kafka-reassign-partitions.sh脚本来执行分区重分配的工作,它可以在集群扩容、broker节点失效的场景下对分区进行迁移。kafka-reassign-partitions.sh脚本的使用分为3个步骤:首先创建需要一个包含主题清单的JSON文件,其次根据主题清单和broker节点清单生成一份重分配方案,最后根据这份方案执行具体的重分配动作
在一个3个节点组成的集群中创建一个主题topic-reassign,主题中包含4个分区和2个副本:
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-reassign --replication-factor 2 --partitions 4
Created topic "topic-reassign".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign
Topic:topic-reassign PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-reassign Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: topic-reassign Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-reassign Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: topic-reassign Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0
如果现在要下线brokerId为1的broker节点,在此之前,我们要做的就是将其上的分区副本迁移出去。创建一个JSON文件,文件名为reassign.json,文件内容为要进行分区重分配的主题清单
{
"topics": [{
"topic": "topic-reassign"
}],
"version": 1
}
根据这个JSON文件和指定所要分配的broker节点列表来生成一份候选的重分配方案
[root@localhost bin]# ./kafka-reassign-partitions.sh --zookeeper localhost:2181 --generate --topics-to-move-json-file reassign.json --broker-list 0,2
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic-reassign","partition":2,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":0,"replicas":[2,1],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topic-reassign","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":3,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"topic-reassign","partition":0,"replicas":[0,2],"log_dirs":["any","any"]}]}
执行后打印出了两个JSON格式的内容。Current partition replica assignment所对应的JSON内容为当前的分区副本分配情况,在执行分区重分配的时候最好将这个内容保存起来,以备后续的回滚操作。Proposed partition reassignment configuration所对应的JSON内容为重分配的候选方案,这里只是生成一份可行性的方案,并没有真正执行重分配的工作。生成的可行性方案的具体算法和创建主题时的一样,这里也包含了机架信息
将第二个JSON内容保存在一个JSON文件中,命名为project.json,然后执行具体的重分配动作
[root@localhost bin]# ./kafka-reassign-partitions.sh --zookeeper localhost:2181 --execute --reassignment-json-file project.json
再次查看主题topic-reassign的具体信息:
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-reassign
Topic:topic-reassign PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-reassign Partition: 0 Leader: 2 Replicas: 0,2 Isr: 2,0
Topic: topic-reassign Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2
Topic: topic-reassign Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-reassign Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0
主题中所有分区副本都只在0和2的broker节点上分布
分区重分配的基本原理是先通过控制器为每个分区添加新副本(增加副本因子),新的副本将从分区的leader副本那里复制所有的数据。根据分区的大小不同,复制过程可能需要花一些时间,因为数据是通过网络复制到新副本上的。在复制完成之后,控制器将旧副本从副本清单里移除(恢复为原先的副本因子)。在重分配的过程中要确保有足够的空间
3)、复制限流
对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响
kafka-configs.sh脚本主要以动态配置的方式来达到限流的目的,在broker级别有两个与复制限流相关的配置参数:follower.replication.throttled.rate和leader.replication.throttled.rate,前者用于设置follower副本复制的速度,后者用于设置leader副本传输的速度,它们的单位都是B/s。通过情况下,两者的配置值是相同的。下面将broker1中的leader副本和follower副本的复制速度限制在1024B/s之内
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --entity-type brokers --entity-name 1 --alter --add-config follower.replication.throttled.rate=1024,leader.replication.throttled.rate=1024
Completed Updating config for entity: brokers '1'.
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --entity-type brokers --entity-name 1 --describe
Configs for brokers '1' are leader.replication.throttled.rate=1024,follower.replication.throttled.rate=1024
变更配置时会在ZooKeeper中创建一个命名形式为/config/的节点
[zk: localhost:2181(CONNECTED) 2] get /config/brokers/1
{"version":1,"config":{"leader.replication.throttled.rate":"1024","follower.replication.throttled.rate":"1024"}}
在主题级别也有两个相关的参数来限制复制的速度:leader.replication.throttled.replicas和follower.replication.throttled.replicas,它们分别用来配置被限制速度的主题所对应的leader副本列表和follower副本列表
创建一个分区数为3、副本数为2的主题topic-throttle
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-throttle --replication-factor 2 --partitions 3
Created topic "topic-throttle".
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-throttle
Topic:topic-throttle PartitionCount:3 ReplicationFactor:2 Configs:
Topic: topic-throttle Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: topic-throttle Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: topic-throttle Partition: 2 Leader: 0 Replicas: 0,1 Isr: 0,1
主题topic-throttle的三个分区所对应的leader节点分别为1、2、0,即分区与代理的影射关系为0:1、1:2、2:0,而对应的follower节点分别为1、2、0,相关的分区与代理的映射关系为0:2、1:0、2:1,此主题限流副本列表及具体操作如下:
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name topic-throttle --alter -add-config leader.replication.throttled.replicas=[0:1,1:2,2:0],follower.replication.throttled.replicas=[0:2,1:0,2:1]
Completed Updating config for entity: topic 'topic-throttle'.
对应ZooKeeper中的/config/topics/topic-throttle节点信息如下:
[zk: localhost:2181(CONNECTED) 3] get /config/topics/topic-throttle
{"version":1,"config":{"leader.replication.throttled.replicas":"0:1,1:2,2:0","follower.replication.throttled.replicas":"0:2,1:0,2:1"}}
五、日志存储
1、文件目录布局
Kafka中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。每个主题又可以分为一个或多个分区,分区的数量可以在主题创建的时候指定,也可以在之后修改。每个消息在发送的时候会根据分区规则被追加到指定的分区中,分区中的每条消息都会被分配一个唯一的序列号,也就是偏移量
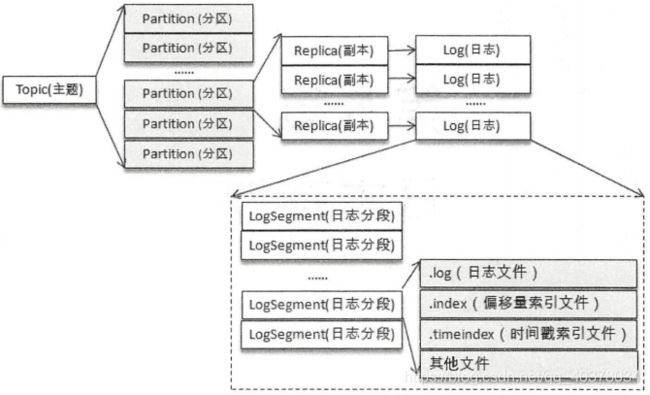
为了防止Log过大,Kafka引入了日志分段的概念,将Log切分为多个LogSegment。Log和LogSegment不是纯粹物理意义上的概念,Log在物理上只以文件夹的形式存储,而每个LogSegment对应于磁盘上的一个日志文件和两个索引文件,以及可能的其他文件
Log对应了一个命名形式为
为了便于消息的检索,每个LogSegment中的日志文件都有对应的两个索引文件:偏移量索引文件(以.index为文件后缀)和时间戳索引文件(以.timeindex为文件后缀)。每个LogSegment都有一个基准偏移量baseOffset,用来表示当前LogSegment中第一条消息的offset。偏移量是一个64位的长整型数,日志文件和两个索引文件都是根据基准偏移量命名的,名称固定为20位数字,没有达到的位数则用0填充。比如第一个LogSegment的基准偏移量为0,对应的日志文件为00000000000000000000.log
当Kafka服务第一次启动的时候,默认的根目录下就会创建以下5个文件:
[root@localhost kafka-logs]# ls
cleaner-offset-checkpoint log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint
消费者提交的位移是保存在Kafka内部的主题__consumer_offsets中的,初始情况下这个主题并不存在,当第一次有消费者消费信息时会自动创建这个主题
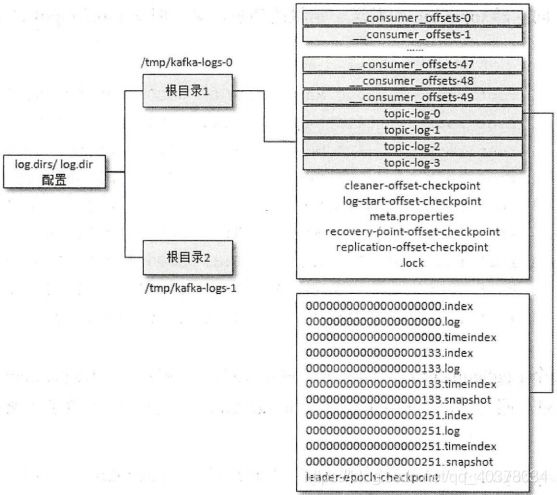
每一个根目录都会包含最基本的4个检查点文件(xxx-checkpoint)和meta.properties。在创建主题的时候,如果当前broker中不止配置了一个根目录,那么会挑选分区数最少的那个根目录来完成本次创建任务
2、日志格式
1)、v0版本

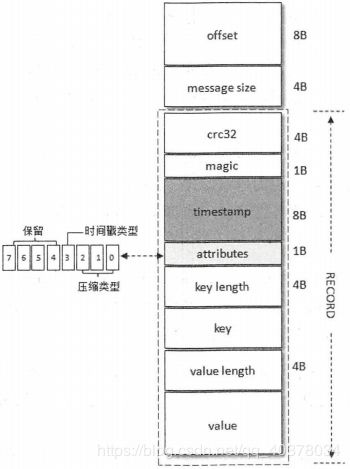
每个Record(v0和v1版本)必定对应一个offset和message size。每条消息都有一个offset用来标志它在分区中的偏移量,这个offset是逻辑值,message size表示消息的大小,这两者在一起被称为日志头部(LOG_OVERHEAD),固定为12B。LOG_OVERHEAD和RECORD一起用来描述一条消息。消息集中包含一条或多条消息,消息集不仅是存储于磁盘及在网络上传输的基本形式,而且是Kafka中压缩的基本单位
- crc32(4B):crc32校验值。校验范围为magic至value之间
- magic(1B):消息格式版本号,此版本的magic值为0
- attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:0表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4,其余位保留
- key length(4B):表示消息的长度。如果为-1,则表示没有设置key
- key:可选,如果没有key则无此字段
- value length(4B):实际消息体的长度。如果为-1,则表示消息为空
- value:消息体。可以为空,比如墓碑消息
v0版本中一个消息的最小长度为crc32+magic+attributes+key length+value length=14B。也就是说,v0版本中一条消息的最小长度为14B,如果小于这个值,那么就是一条破损的消息而不被接收
2)、v1版本
v1版本比v0版本就多了一个timestamp字段,表示消息的时间戳
v1版本的magic字段的值为1。v1版本的attributes字段中的低3位和v0版本的一样,还是表示压缩类型,而第4个为也被利用起来:0表示timestamp类型为CreateTime,而1表示timestamp类型为LogAppendTime,其他位保留。timestamp类型由broker端参数log.message.timestamp.type来配置,默认值为CreateTime,即采用生产者创建消息时的时间戳。如果在创建ProducerRecord时没有显示指定消息的时间戳,那么KafkaProducer也会在发送这条消息前自动添加上
3)、消息压缩
Kafka实现的压缩方式是将多条消息一起进行压缩。生产者发送到压缩数据在broker中也是保持压缩状态进行存储的,消费者从服务端获取的也是压缩的消息,消费者在处理消息之前才会解压消息,这样保持了端到端的压缩
Kafka日志中使用哪种压缩方式是通过参数compression.type来配置的,默认值为producer,表示保留生产者使用的压缩方式。这个参数还可以设置为gzip、snappy、lz4.如果参数compression.type配置为uncompressed,则表示不压缩
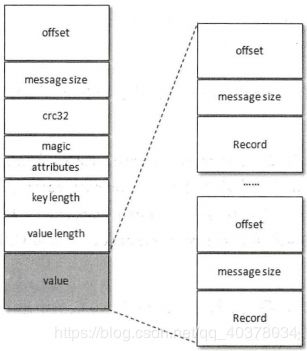
当消息压缩时是将整个消息集进行压缩作为内层消息,内层消息整体作为外层消息的value
压缩后的外层消息中的key为null,value字段中保存的是多条压缩消息,其中Record表示的是从crc32到value的消息格式
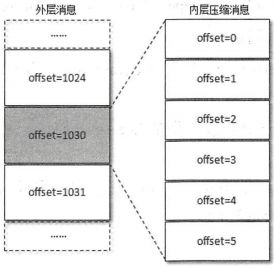
当生产者创建压缩消息的时候,对内部压缩消息设置的offset从0开始为每个内部消息分配offset
其实每个从生产者发出的消息集中的消息offset都是从0开始的,当然这个offset不能直接存储在日志文件中,对offset的转换是在服务端进行的,客户端不需要做这个工作。外层消息保存了内层消息中最后一条消息的绝对位移,绝对位移是相对于整个分区而言的。上图中内层消息中最后一条的offset理应是1030,但被压缩之后就变成了5,而这个1030被赋予给了外层的offset。当消费者消费这个消息集的时候,首先解压缩整个消息集,然后找到内层消息中最后一条消息的inner offset
对于压缩的情形,外层消息的timestamp设置为:
- 如果timestamp类型是CreateTime,那么设置的是内层消息中最大的时间戳
- 如果timestamp类型是LogAppendTime,那么设置的是Kafka服务器当前的时间戳
内层消息的timestamp设置为:
- 如果timestamp类型是CreateTime,那么设置的是生产者创建消息时的时间戳
- 如果timestamp类型是LogAppendTime,那么所有内层消息的时间戳都会被忽略
4)、v2版本

v2版本中消息集称为Record Batch,而不是先前的Message Set,其内部也包含了一条或多条消息。在消息压缩的情形下,Record Batch Header部分(从first offset到records count字段)是不被压缩的,而被压缩的是records字段中的所有内容。生产者客户端中的ProducerBatch对应这里的RecordBatch,而ProducerRecord对应这里的Record
Record的内部字段大量采用了Varints(变长整型),这样Kafka可以根据具体的值来确定需要几个字节来保存
- length:消息总长度
- attributes:弃用,但还是在消息格式中占据1B的大小
- timestamp delta:时间戳增量。通常一个timestamp需要占用8个字节,如果向这里一样保存与RecordBatch的起始时间戳的差值,则可以进一步节省占有的字节数
- offset delta:位移增量。保存与RecordBatch起始位移的差值
- headers:Header包含key和value,一个Record里面可以包含0至多个Header
v2版本对RecordBatch做了彻底的修改
- first offset:表示当前RecordBatch的起始位置
- length:计算从partition leader epoch字段开始到末尾的长度
- partition leader epoch:分区leader纪元,可以看作分区leader的版本号或更新次数
- magic:消息格式的版本号,v2版本值为2
- attributes:消息属性,这里占用了两个字节。低3位表示压缩格式,同v0和v1;第4位表示时间戳类型;第5位表示此RecordBatch是否处于事务中,0表示非事务,1表示事务。第6位表示是否是控制消息,0表示非控制消息,而1表示是控制消息,控制消息用来支持事务功能
- last offset delta:RecordBatch中最后一个Record的offset与first offset的差值
- first timestamp:RecordBatch中第一条Record的时间戳
- max timestamp:RecordBatch中最大的时间戳
- producer id:PID,用来支持幂等和事务
- producer epoch:用来支持幂等和事务
- first sequence:用来支持幂等和事务
- records count:RecordBatch中Record的个数
3、日志索引
偏移量索引文件用来建立消息偏移量到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置;时间戳索引文件则根据指定的时间戳来查找对应的偏移量信息
Kafka中的索引文件以稀疏索引的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由broker端参数log.index.interval.bytes指定,默认值为4096,即4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小log.index.interval.bytes的值对应地可以增加或缩小索引项的密度
稀疏索引通过MappedByteBuffer将索引文件映射到内存中,以加快索引的查询速度。偏移量索引文件中的偏移量是单调递增的,查询指定偏移量时,使用二分查找法来快速定位偏移量的位置,如果指定的偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量。时间戳索引文件中的时间戳也保持严格的单调递增,查询指定时间戳,也根据二分查找法来查找不大于该时间戳的最大偏移量,至于要找到对应的物理文件位置还需要根据偏移量索引文件来进行再次定位。稀疏索引的方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中
日志分段文件切分包含以下几个条件,满足其一即可:
- 当前日志分段文件的大小超过了broker端参数log.segment.bytes配置的值,log.segment.bytes参数的默认值为1073741824,即1GB
- 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值大于log.roll.ms或log.roll.hours参数配置的值。如果同时配置了log.roll.ms和log.roll.hours参数,那么log.roll.ms的优先级高。默认情况下,只配置了log.roll.hours参数,其值为168,即7天
- 偏移量索引文件或时间戳索引文件的大小达到broker端参数log.index.size.max.bytes配置的值。默认值为10485760,即10MB
- 追加的消息的偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE(offset-baseOffset>Integer.MAX_VALUE)
对非当前活跃的日志分段而言,其对应的索引文件内容已经固定而不需要再写入索引项,所以会被设定为只读。而对当前活跃的日志分段而言,索引文件还会追加更多的索引项,所以被设定为可读写。在索引文件切分的时候,Kafka会关闭当前正在写入的索引文件并置为只读模式,同时以可读写的模式创建新的索引文件,索引文件的大小由broker端参数log.index.size.max.bytes配置。Kafka在创建索引文件的时候会为其预分配log.index.size.max.bytes大小的空间,只有当索引文件进行切分的时候,Kafka才会把该索引文件裁剪到实际的数据大小。也即是说,与当前活跃的日志分段对应的索引文件的大小固定位log.index.size.max.bytes,而其余日志分段对应的索引文件的大小为实际的占用空间
1)、偏移量索引

- relativeOffset:相对偏移量,表示消息相对于baseOffset的偏移量,占用4个字节,当前索引文件的文件名即为baseOffset的值
- position:物理地址,也就是消息在日志分段文件中对应的物理位置,占用4个字节
消息的偏移量占用8个字节,也可以称为绝对偏移量。索引项中没有直接使用绝对偏移量而改为只占用4个字节的相对偏移量(relativeOffset=offset-baseOffset),这样可以减少索引文件占用的空间
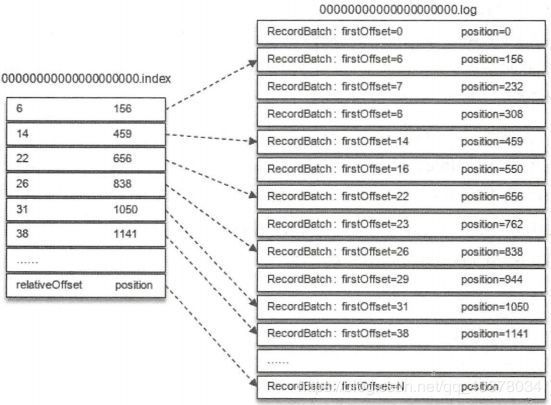
如果要查找偏移量为23的消息,首先通过二分法在偏移量索引文件中找到不大于23的最大索引,即[22,656],然后从日志分段文件中的物理位置656开始顺序查找偏移量为23的消息
如果要找到偏移量为268的消息,先定位到baseOffset为251的日志分段,然后计算相对偏移量relativeOffset=268-251=17,之后再在对应的索引文件中找到不大于17的索引项,最后根据索引项中的position定位到具体的日志分段文件位置开始查找目标消息。查找baseOffset为251的日志分段用了跳跃表的结构,Kafka的每个日志对象中使用了ConcurrentSkipListMap来保存各个日志分段,每个日志分段的baseOffset作为key,这样可以根据指定偏移量来快速定位到消息所在的日志分段
Kafka强制要求索引文件大小必须是索引项大小的整数倍,对偏移量索引文件而言,必须为8的整数。如果broker端参数log.index.size.max.bytes配置为67,那么Kafka在内部会将其转换为64,即不大于67,并且满足为8的整数倍的条件
2)、时间戳索引

每个索引项占用12个字节,分为两个部分
- timestamp:当前日志分段最大的时间戳
- relativeOffset:时间戳所对应的消息的相对偏移量
时间戳索引文件中包含若干个时间戳索引项,每个住家的时间戳索引项中的timestamp必须大于之前追加的索引项的timestamp,否则不予追加。如果broker端参数log.message.timestamp.type设置为LogAppendTime,那么消息的时间戳必定能够保持单调递增;相反,如果是CreateTime类型则无法保证。生产者可以使用类似ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)的方法指定时间戳的值。即使生产者客户端采用自动插入的时间戳也无法保证时间戳能够单调递增,如果两个不同时钟的生产者同时往一个分区中插入消息,那么也会造成当前分区的时间戳乱序
时间戳索引文件大小是索引项大小(12B)的整数倍,如果不满足条件也会进行裁剪。同样假设broker端参数log.index.size.max.bytes配置为67,那么对应于时间戳索引文件,Kafka在内部会将其转换为60
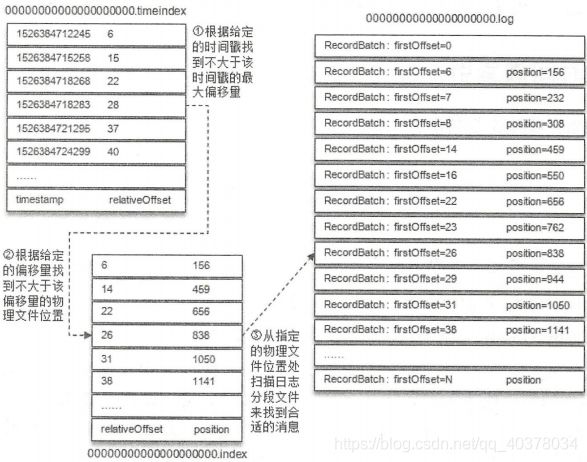
如果要查找指定时间戳targetTimeStamp=1526384718288开始的消息,首先是找到不小于指定时间戳的日志分段。这里就无法使用跳跃表来快速定位到乡音感到日志分段了
1)将targetTimeStamp和每个日志分段中的最大时间戳largestTimeStamp逐一对比,直到找到不小于targetTimeStamp的largestTimeStamp所对应的日志分段。日志分段中的largestTimeStamp的计算是先查询该日志分段所对应的时间戳索引文件,找到最后一条索引项,若最后一条索引项的时间戳字段值大于0,则取其值,否则取该日志分段的最近修改时间
2)找到相应的日志分段之后,在时间戳索引文件中使用二分法查找算法查找到不大于targetTimeStamp的最大索引项,即[1526384718283,28],如此便找到了相对偏移量28
3)在偏移量索引文件中使用二分法查找到不大于28的最大索引项,即[26,838]
4)从步骤1中找到日志分段文件中的838的物理位置开始查找不小于targetTimeStamp的消息
4、日志清理
Kafka提供了两种日志清理策略:
- 日志删除:按照一定的保留策略直接删除不符合条件的日志分段
- 日志压缩:针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本
可以通过broker端参数log.cleanup.policy来设置日志清理策略,此参数的默认值为delete,即采用日志删除的清理策略。如果要采用日志压缩的清理策略,就需要将log.cleanup.policy设置为compact,并且还需要将log.cleaner.enable(默认值为true)设定为true。通过将log.cleanup.policy设置为"delete,compact",还可以同时支持日志删除和日志压缩两种策略。日志清理的粒度可以控制到主题级别
1)、日志删除
在Kafka的日志管理器中会有一个专门的日志删除任务来周期性地检测和删除不符合保留条件的日志分段文件,这个周期可以通过broker参数log.retention.check.interval.ms来配置,默认值为300000,即5分钟。当前日志分段的保留策略有3种:基于时间的保留策略、基于日志大小的保留策略和基于日志起始偏移量的保留策略
1)基于时间
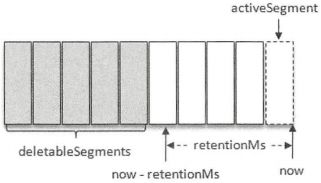
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值(retentionMs)来寻找可删除的日志分段文件集合(deletableSegments)。retentionMs可以通过broker端参数log.retention.hours、log.retention.minutes和log.retention.ms来配置,其中log.retention.ms优先级最高,默认情况下只配置了log.retention.hours参数,其值为168,默认情况下日志分段文件的保留时间为7天
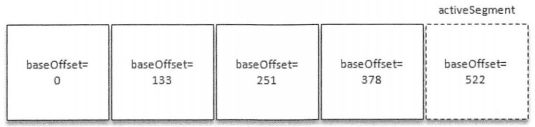
若待删除的日志分段的总数等于该日志文件中所有的日志分段的数量,那么说明所有的日志分段都已过期,但该日志文件中还要有一个日志分段用于接收消息的写入,即必须要保证有一个活跃的日志分段activeSegment,在此种情况下,会先切出一个新的日志分段作为activeSegment,然后执行删除操作
删除日志分段时,首先会从Log对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作。然后将日志分段所对应的所有文件添加上".deleted"的后缀。最后交由一个以"delete-file"命名的延迟任务来删除这些以".deleted"为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来调配,此参数的默认值为60000,即1分钟
2)基于日志大小
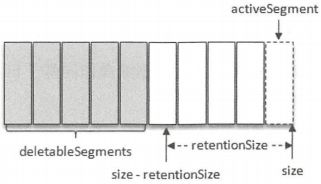
日志删除任务会检查当前日志的大小是否超过设定的阈值(retentionSize)来寻找可删除的日志分段的文件集合(deletableSegments),retentionSize可以通过broker端参数log.retention.bytes来配置,默认值为-1,表示无穷大。log.retention.bytes配置的是Log中所有日志文件的总大小,而不是单个日志分段的大小。单个日志分段的大小由broker端参数log.segment.bytes来限制,默认值为1073741824,即1GB
基于日志大小的保留策略与基于时间的保留策略类似,首先计算日志文件的总大小size和retentionSize的差值diff,即计算需要删除的日志总大小,然后从日志文件中的第一个日志分段开始进行查找可删除的日志分段的文件集合deletableSegments。查找出deletableSegments之后就执行删除操作,这个删除操作和基于时间的保留策略的删除操作相同
3)基于日志起始偏移量
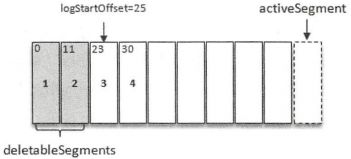
一般情况下,日志文件的起始偏移量logStartOffset等于第一个日志分段的baseOffset,但并不是绝对的,logStartOffset的值可以通过DeleteRecordsRequest请求(KafkaAdminClient的deleteRecords()方法、使用kafka-delete-records脚本)、日志的清理和阶段等操作进行修改
基于日志起始偏移量的保留策略的判断依据是某日志分段的下一个日志分段的起始偏移量baseOffset是否小于等于logStartOffset,若是,则可以删除日志分段。上图中,假设logStartOffset等于25,日志分段1的起始偏移量为0,日志分段2的起始偏移量为11,日志分段3的起始偏移量为23,通过如下动作收集可删除的日志分段的文件集合deletableSegments:
A.从头开始遍历每个日志分段,日志分段1的下一个日志分段的起始偏移量为11,小于logStartOffset的大小,将日志分段1加入deletableSegments
B.日志分段2的下一个日志偏移量的起始偏移量为23,也小于logStartOffset的大小,将日志分段2加入deletableSegments
C.日志分段3的下一个日志偏移量在logStartOffset的右侧,故从日志分段3开始的所有日志分段都不会加入deletableSegments
收集完可删除的日志分段的文件集合之后的删除操作同基于日志大小的保留策略和基于时间的保留策略相同
2)、日志压缩
Kafka中的Log Compaction是指在默认的日志删除规则之外提供的一种清理过时数据的方式,会定期将相同key的消息进行合并,只保留最新的value值
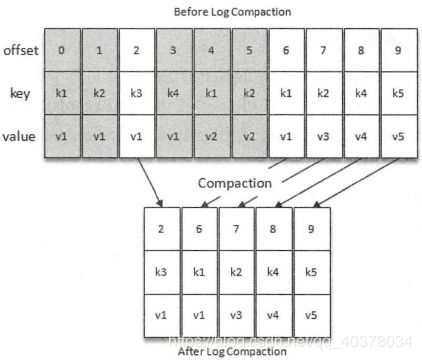
Log Compaction执行前后,日志分段中的每条消息的偏移量和写入时的偏移量保持一致,Log Compaction会生成新的日志分段文件,日志分段中每条消息的物理地址会重新按照新文件来组织。Log Compaction执行过后的偏移量不再是连续的,不过不会影响日志的查询
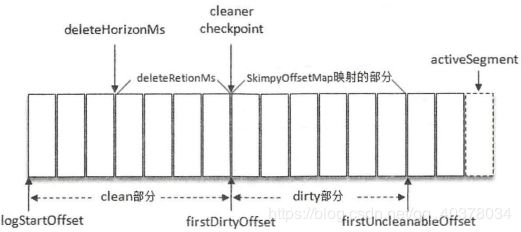
每一个日志目录下都有一个名为"cleaner-offset-checkpoint"的文件,这个文件就是清理检查点文件,用来记录每个主题的每个分区中已清理的偏移量。通过清理检查点文件可以将Log分成两个部分。如上图所示,通过检查点cleaner checkpoint来划分出一个已经清理过的clean部分和一个还没清理的dirty部分。在日志清理的同时,客户端也可以读取日志中的消息。dirty部分的消息偏移量是逐一递增的,而clean部分的消息偏移量是断续的
firstDirtyOffset表示dirty部分的起始偏移量,而firstUncleanableOffset为dirty部分的截止偏移量,整个dirty部分的偏移量分为为[firstDirtyOffset,firstUncleanableOffset)。为了避免当前活跃的日志分段activeSegment成为热点文件,activeSegment不会参与Log Compaction
Log Compaction是针对key的,所以在使用时应注意每个消息的key值不为null。每个broker会启动log.cleaner.thread(默认值为1)个日志清理线程负责执行清理任务,这些线程会选择污浊率最高的日志文件进行清理。用cleanBytes表示clean部分的日志占用大小,dirtyBytes表示dirty部分的日志占用大小,那么这个日志的污浊率为: d i r t y R a t i o = d i r t y B y t e s / ( c l e a n B y t e s + d i r t y B y t e s ) dirtyRatio=dirtyBytes/(cleanBytes+dirtyBytes) dirtyRatio=dirtyBytes/(cleanBytes+dirtyBytes)
为了防止日志比较的频繁清理操作,Kafka还使用了参数log.cleaner.min。cleanable.ratio(默认值为0.5)来限定可进行清理操作的最小污浊率。Kafka中用于保留消费者位移的主题__consumer_offsets使用的就是Log Compaction策略
5、磁盘存储
Kafka依赖于磁盘来存储和缓存消息。Kafka在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并且也不允许修改已写入的消息,这种方式属于典型的顺序写盘的操作
1)、页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘I/O的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变成对内存的访问
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页是否在页缓存中,如果存在则直接返回数据,从而避免了对物理磁盘的I/O操作;如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性
Kafka中大量使用了页缓存,这是Kafka实现高吞吐的重要因素之一。虽然消息都是先被写入页缓存,然后由操作系统负责具体的刷盘任务的,但在Kafka中同样提供了同步刷盘及间断性强制刷盘的功能,这些功能可以通过log.flush.interval.message、log.flush.interval.ms等参数来控制。同步刷盘可以提高消息的可靠性,防止由于机器掉电等异常造成处于页缓存而没有及时写入磁盘的消息丢失。消息的可靠性应该由多副本机制来保障,而不是由同步刷盘这种严重影响性能的行为来保障
2)、零拷贝
除了消息顺序追加、页缓存等技术,Kafka还使用零拷贝技术来进一步提升性能。零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。对于Linux操作系统而言,零拷贝技术依赖于底层的sendfile()方法实现。对应于Java语言,FileChannal.transferTo()方法的底层实现就是sendfile()方法
将静态内容展示给用户这个情形就意味着需要先将静态内容从磁盘中复制出来放到一个内存buf中,然后将这个buf通过套接字传输给用户,进而用户获得静态内容
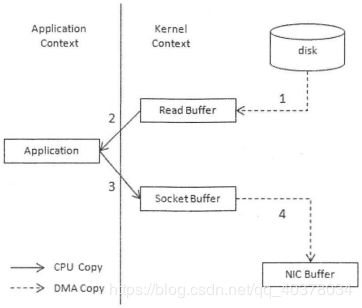
A.调用read()时,文件A中的内容被复制到了内核模式下的Read Buffer中
B.CPU控制将内核模式数据复制到用户模式下
C.调用write()时,将用户模式下的内容复制到内核模式下的Socket Buffer中
D.将内核模式下的Socket Buffer的数据复制到网卡设备中传送
采用零拷贝技术,应用程序可以直接请求内核把磁盘中的数据传输给Socket
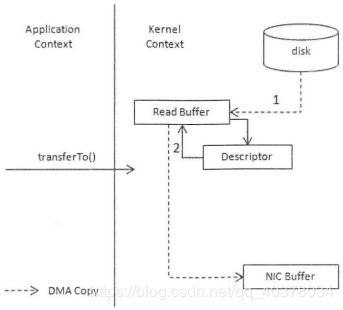
零拷贝技术通过DMA(Direct Memory Access)技术将文件内容复制到内核模式下的Read Buffer中。不过没有数据被复制到Socket Buffer,相反只有包含数据的位置和长度的信息的文件描述符被加到Socket Buffer中。DMA引擎直接将数据从内核模式中传递到网卡设备。零拷贝是针对内核模式而言的,数据在内核模式下实现了零拷贝