文件系统功能 os模块 子模块os.path pickle
os 模块
在os模块中,方法很多,有些是跟目录相关的,有些是跟系统文件相关的等等。是将linux操作系统系统上C语言所写的API如创建文件,创建目录API封装成了python的API。

os.mkdir()
 os.mkdir("")创建一个一级目录
os.mkdir("")创建一个一级目录
os.makedirs() 创建一个多级目录
os.chdir() 实现跳转到指定目录
os.getcwd() 获取当前目录

os.stat(path) 方法用于在给定的路径上执行一个系统 stat 的调用.
path – 指定路径。
返回值:
st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)
os.chdir(“G://”)
os.getcwd()
‘G:\’os.stat(“G:\neo4j操作指南\neo4j.txt”)
os.stat_result(st_mode=33206, st_ino=1407374883579497, st_dev=3530800496, st_nlink=1, st_uid=0, st_g
id=0, st_size=96, st_atime=1561629787, st_mtime=1565789195, st_ctime=1561629787)
os 常见的方法
1.目录相关的:
os.chdir() #改变工作目录
os.chroot() #设定当前进程的根目录
os.listdir() #列出指定目录下的所有文件名
os.mkdir() #创建一级目录文件
os.makedirs() #创建多级目录
os.getcwd()#获取当前目录
rmdir() #删除目录
removedirs() #删除多级目录
2.文件相关:
os.mkfifo() #创建命名管道
os.mknod() #创建设备文件 Python2
os.remove() #删除文件
os.unlink() #删除文件
os.rename() #文件重命名
os.stat() #返回文件状态信息
os.symlink() #方法用于创建一个软链接
os.utime() #更新文件的时间戳
os.tmpfile() #创建并打开一个新的临时文件 返回一个打开的模式为(w+b)的临时文件对象,这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 python2
3.访问权限相关:
os.access(path, mode) 判定指定用户对某文件是否具有访问权限
方法使用当前的uid/gid尝试访问路径。大部分操作使用有效的 uid/gid, 因此运行环境可以在 suid/sgid 环境尝试。
path – 要用来检测是否有访问权限的路径。
mode – mode为F_OK,测试存在的路径,或者它可以是包含R_OK,
W_OK和X_OK或者R_OK, W_OK和X_OK其中之一或者更多。
os.F_OK: 作为access()的mode参数,测试path是否存在。
os.R_OK: 包含在access()的mode参数中 , 测试path是否可读。
os.W_OK 包含在access()的mode参数中 , 测试path是否可写。
os.X_OK 包含在access()的mode参数中 ,测试path是否可执行。
os.chmod() 修改权限
os.chown() 修改属主,属组 Python2
os.umask() 设置默认权限模式
4.文件描述符:
os.open(file, flags[, mode]) #相当于打开一个文件方法用于打开一个文件,并且设置需要的打开选项,模式参数mode参数是可选的,默认为 0777。
file – 要打开的文件
flags – 该参数可以是以下选项,多个使用 “|” 隔开:
os.O_RDONLY: 以只读的方式打开
os.O_WRONLY: 以只写的方式打开
os.O_RDWR : 以读写的方式打开
os.O_NONBLOCK: 打开时不阻塞
os.O_APPEND: 以追加的方式打开
os.O_CREAT: 创建并打开一个新文件
os.O_TRUNC: 打开一个文件并截断它的长度为零(必须有写权限)
os.O_EXCL: 如果指定的文件存在,返回错误
os.O_SHLOCK: 自动获取共享锁
os.O_EXLOCK: 自动获取独立锁
os.O_DIRECT: 消除或减少缓存效果
os.O_FSYNC : 同步写入
os.O_NOFOLLOW: 不追踪软链接
mode – 类似 chmod()。
os.write(fd, str)方法用于写入字符串到文件描述符 fd 中. 返回实际写入的字符串长度。
在Unix中有效
fd – 文件描述符。
n – 写入的字节
os.read()方法用于从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。
在Unix,Windows中有效
fd – 文件描述符。
n – 读取的字节
5.设备文件:
os.mkdev() #根据指定的设备号创建设备文件的
os.major() # python2
os.minor()
os中 的方法图示
os.symlink()

os.access()判定指定用户是否对某一文件具有访问权限。

os.chmod()修改权限

#修改的代码

修改结果:红色部分为修改的文件
C:\Users\Administrator>I:
I:>ls -l
total 130468
drw-rw-rw- 10 Administrator 0 4096 2017-11-10 22:17 $RECYCLE.BIN
drw-rw-rw- 5 Administrator 0 4096 2019-08-07 23:31 ainlp
drw-rw-rw- 8 Administrator 0 28672 2019-05-26 22:32 book
drw-rw-rw- 4 Administrator 0 0 2019-04-28 05:57 CaijiData
drw-rw-rw- 3 Administrator 0 49152 2019-05-28 21:48 Downloads
drw-rw-rw- 7 Administrator 0 4096 2019-05-26 15:09 DPSCompany
drw-rw-rw- 3 Administrator 0 16384 2019-03-20 21:17 jieshou
drw-rw-rw- 5 Administrator 0 0 2018-11-26 19:28 JinRongFengKong
-rwxrwxrwx 1 Administrator 0 17134488 2019-08-03 14:50 KuaiZip_Setup_kzgw_001.exe
-rw-rw-rw- 1 Administrator 0 1556737 2019-04-02 21:44 lianyiqun.csv
-rw-rw-rw- 1 Administrator 0 20361216 2019-08-05 17:21 python-2.7.16.amd64.msi
drw-rw-rw- 2 Administrator 0 40960 2019-08-04 23:23 python???60??
drw-rw-rw- 5 Administrator 0 4096 2018-09-29 09:36 sphinAndrasabaster_Zip
drw-rw-rw- 2 Administrator 0 4096 2016-06-17 22:16 System Volume Information
drw-rw-rw- 2 Administrator 0 4096 2019-04-30 10:01 TaoBaoAndTianMaoUTF8
drw-rw-rw- 3 Administrator 0 12288 2019-05-03 16:50 taobaotianmao
drw-rw-rw- 2 Administrator 0 0 2019-03-20 18:00 tensorflow??
-rw-rw-rw- 1 Administrator 0 28 2019-04-28 16:00 test.csv
-rw-rw-rw- 1 Administrator 0 4500 2019-06-07 11:07 test2.csv
drw-rw-rw- 2 Administrator 0 0 2019-03-25 11:15 wordVectorModel
-rwxrwxrwx 1 Administrator 0 19345784 2019-08-04 20:15 xfplay9.9998.exe
drw-rw-rw- 3 Administrator 0 0 2019-08-15 07:29 xiaopang
drw-rw-rw- 2 Administrator 0 0 2019-08-15 09:12 xiaopang.txt
drw-rw-rw- 3 Administrator 0 0 2018-10-18 19:39 XLNetAccSetup
-rwxrwxrwx 1 Administrator 0 73690576 2019-07-27 21:41 YNote.exe
drw-rw-rw- 2 Administrator 0 4096 2019-05-03 16:50 YOHO
drw-rw-rw- 3 Administrator 0 0 2019-07-27 21:56 youdaoCatch
drw-rw-rw- 6 Administrator 0 16384 2019-08-05 21:14 YoudaoNote
drw-rw-rw- 2 Administrator 0 0 2019-07-27 21:54 YoudaoNoteAddin
drw-rw-rw- 4 Administrator 0 131072 2019-03-25 11:16 ??
drw-rw-rw- 12 Administrator 0 4096 2019-08-03 02:26 ??????(???)
drw-rw-rw- 2 Administrator 0 65536 2019-08-11 20:25 ?????v1
drw-rw-rw- 2 Administrator 0 65536 2019-08-11 19:54 ???_??v2
drw-rw-rw- 2 Administrator 0 4096 2019-08-03 02:32 ???,???
drw-rw-rw- 17 Administrator 0 4096 2019-03-24 13:32 ??
-rw-rw-rw- 1 Administrator 0 0 2019-04-27 21:22 ???.txt
drw-rw-rw- 2 Administrator 0 4096 2019-08-02 18:11 ???-???24?-04-Hadoop Hive Hbase Flume Sqoo
p-12?
drw-rw-rw- 4 Administrator 0 4096 2019-08-02 20:10 ???-???24?-05-ElasticSearch-2?
drw-rw-rw- 2 Administrator 0 4096 2019-08-02 17:59 ???-???24?-06-Spark???-10?
-rw-rw-rw- 1 Administrator 0 1003154 2019-04-21 21:28 ???.txt
drw-rw-rw- 3 Administrator 0 0 2018-09-12 14:54 ???
drw-rw-rw- 9 Administrator 0 4096 2019-03-24 15:20 ??
os.chown() #修改属主,属组。python2
#修改代码:

#修改结果:

os.open()

>> help(os.walk)
Help on function walk in module os:
walk(top, topdown=True, οnerrοr=None, followlinks=False)
Directory tree generator.
For each directory in the directory tree rooted at top (including top
itself, but excluding '.' and '..'), yields a 3-tuple
dirpath, dirnames, filenames
dirpath is a string, the path to the directory. dirnames is a list of
the names of the subdirectories in dirpath (excluding '.' and '..').
filenames is a list of the names of the non-directory files in dirpath.
Note that the names in the lists are just names, with no path components.
To get a full path (which begins with top) to a file or directory in
dirpath, do os.path.join(dirpath, name).
If optional arg 'topdown' is true or not specified, the triple for a
directory is generated before the triples for any of its subdirectories
(directories are generated top down). If topdown is false, the triple
for a directory is generated after the triples for all of its
subdirectories (directories are generated bottom up).
When topdown is true, the caller can modify the dirnames list in-place
(e.g., via del or slice assignment), and walk will only recurse into the
subdirectories whose names remain in dirnames; this can be used to prune the
search, or to impose a specific order of visiting. Modifying dirnames when
topdown is false is ineffective, since the directories in dirnames have
already been generated by the time dirnames itself is generated. No matter
the value of topdown, the list of subdirectories is retrieved before the
tuples for the directory and its subdirectories are generated.
By default errors from the os.scandir() call are ignored. If
optional arg 'onerror' is specified, it should be a function; it
will be called with one argument, an OSError instance. It can
report the error to continue with the walk, or raise the exception
to abort the walk. Note that the filename is available as the
filename attribute of the exception object.
By default, os.walk does not follow symbolic links to subdirectories on
systems that support them. In order to get this functionality, set the
optional argument 'followlinks' to true.
Caution: if you pass a relative pathname for top, don't change the
current working directory between resumptions of walk. walk never
changes the current directory, and assumes that the client doesn't
either.
import os
from os.path import join, getsize
for root, dirs, files in os.walk('python/Lib/email'):
print(root, "consumes", end="")
print(sum([getsize(join(root, name)) for name in files]), end="")
print("bytes in", len(files), "non-directory files")
if 'CVS' in dirs:
dirs.remove('CVS') # don't visit CVS directories
os.walk() 返回某个目录下的所有一级文件和一级目录,返回的是迭代器。

os.major() python2

os的子模块 path
os.path 跟文件路径相关
os.path.basename(): 路径基名
os.path.dirname() 路径目录名
os.path.join() 拼接路径
os.path.split() 返回dirname(),basename()元组
os.path.splitext() 返回(filename,extensionname)
信息:
getatime()
getctime()
getmtime()
getsize() 返回文件的大小
查询:
exists():判断指定文件是否存在
isabs()判断指定的路径是否为绝对路径
isdir() 是否为目录
isfile()是否是文件
islink()是否符号链接
ismount() 是否为挂载点
samefile()两个路径是否指向了同一个路径
#练习:判断文件是否存在,存在则打开,让用户通过键盘反复输入多行数据,追加保存至此文件中。
原始的test.txt文档内容如下:

代码如图:

运行代码输入文字图:

test.txt文件中的结果如下图:


os.path.split() 返回os.path.basename()根基目录和os.path.dirname()目录名所组成的元组。

os.path.join()
os.path.join()简单实例代码应用如下:
>>> os.listdir("i://")
['$RECYCLE.BIN', 'ainlp', 'book', 'CaijiData', 'Downloads', 'DPSCompany', 'jieshou', 'JinRongFengKon
g', 'KuaiZip_Setup_kzgw_001.exe', 'lianyiqun.csv', 'python-2.7.16.amd64.msi', 'python从入门到精通视
频(全60集)', 'sphinAndrasabaster_Zip', 'System Volume Information', 'TaoBaoAndTianMaoUTF8', 'taoba
otianmao', 'tensorflow实战', 'test.csv', 'test2.csv', 'wordVectorModel', 'xfplay9.9998.exe', 'xiaopa
ng', 'xiaopang.txt', 'XLNetAccSetup', 'YNote.exe', 'YOHO', 'youdaoCatch', 'YoudaoNote', 'YoudaoNoteA
ddin', '三个月教你从零入门人工智能,深度学习精华实践课程', '书屋', '壁纸', '大数据算法_哈工大(王宏志)
', '小牛学堂-大数据24期-04-Hadoop Hive Hbase Flume Sqoop-12天', '小牛学堂-大数据24期-05-ElasticSearc
h-2天', '小牛学堂-大数据24期-06-Spark安装部署到高级-10天', '总结', '新建文本文档.txt', '淘宝账号与密
码.txt', 'xxx', '马哥视频_修复v1', '马哥视频_修复v2']
>>> for filename in os.listdir("i://"):
... print(os.path.join("i://",filename))
...
i://$RECYCLE.BIN
i://ainlp
i://book
i://CaijiData
i://Downloads
i://DPSCompany
i://jieshou
i://JinRongFengKong
i://KuaiZip_Setup_kzgw_001.exe
i://lianyiqun.csv
i://python-2.7.16.amd64.msi
i://python从入门到精通视频(全60集)
i://sphinAndrasabaster_Zip
i://System Volume Information
i://TaoBaoAndTianMaoUTF8
i://taobaotianmao
i://tensorflow实战
i://test.csv
i://test2.csv
i://wordVectorModel
i://xfplay9.9998.exe
i://xiaopang
i://xiaopang.txt
i://XLNetAccSetup
i://YNote.exe
i://YOHO
i://youdaoCatch
i://YoudaoNote
i://YoudaoNoteAddin
i://三个月教你从零入门人工智能,深度学习精华实践课程
i://书屋
i://壁纸
i://大数据算法_哈工大(王宏志)
i://小牛学堂-大数据24期-04-Hadoop Hive Hbase Flume Sqoop-12天
i://小牛学堂-大数据24期-05-ElasticSearch-2天
i://小牛学堂-大数据24期-06-Spark安装部署到高级-10天
i://总结
i://新建文本文档.txt
i://淘宝账号与密码.txt
i://xxx
i://马哥视频_修复v1
i://马哥视频_修复v2
文件对象的持久存储(简单介绍)
pickle :能够将内存中的对象持久存到文件中。
marshal (后期专门介绍)
DBM接口: 仅仅是写到dbm数据库中去,但没有办法实现扁平化(流式化)(后期专门介绍)
shelve :既能实现流式化,又可以存到数据库中去(后期专门介绍)
pickle.dump()

字典的内容为: dict1={“a”:“xiaopang”,“b”:“like”,“c”:“xioahe”,}
将字典写入文件:

第一次写入: 文件打开方式 wb

第二次写入:文件打开方式 wb

第3次写入: 文件打开方式为 a+b

python2中的使用如下图:

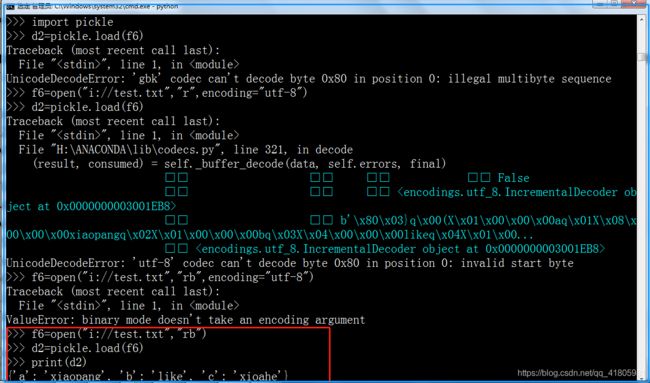
help(pickle.load)

#pickle.load()
os源码
import os
help(os)
Help on module os:
NAME
os - OS routines for NT or Posix depending on what system we’re on.
DESCRIPTION
This exports:
- all functions from posix or nt, e.g. unlink, stat, etc.
- os.path is either posixpath or ntpath
- os.name is either ‘posix’ or ‘nt’
- os.curdir is a string representing the current directory (always ‘.’)
- os.pardir is a string representing the parent directory (always ‘…’)
- os.sep is the (or a most common) pathname separator (’/’ or ‘\’)
- os.extsep is the extension separator (always ‘.’)
- os.altsep is the alternate pathname separator (None or ‘/’)
- os.pathsep is the component separator used in $PATH etc
- os.linesep is the line separator in text files (’\r’ or ‘\n’ or ‘\r\n’)
- os.defpath is the default search path for executables
- os.devnull is the file path of the null device (’/dev/null’, etc.)
Programs that import and use 'os' stand a better chance of being
portable between different platforms. Of course, they must then
only use functions that are defined by all platforms (e.g., unlink
and opendir), and leave all pathname manipulation to os.path
(e.g., split and join).
CLASSES
builtins.Exception(builtins.BaseException)
builtins.OSError
builtins.object
nt.DirEntry
builtins.tuple(builtins.object)
nt.times_result
nt.uname_result
stat_result
statvfs_result
terminal_size
class DirEntry(builtins.object)
| Methods defined here:
|
| __fspath__(...)
| returns the path for the entry
|
| __repr__(self, /)
| Return repr(self).
|
| inode(...)
| return inode of the entry; cached per entry
|
| is_dir(...)
| return True if the entry is a directory; cached per entry
|
| is_file(...)
| return True if the entry is a file; cached per entry
|
| is_symlink(...)
| return True if the entry is a symbolic link; cached per entry
|
| stat(...)
| return stat_result object for the entry; cached per entry
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| name
| the entry's base filename, relative to scandir() "path" argument
|
| path
| the entry's full path name; equivalent to os.path.join(scandir_path, entry.name)
error = class OSError(Exception)
| Base class for I/O related errors.
|
| Method resolution order:
| OSError
| Exception
| BaseException
| object
|
| Methods defined here:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __str__(self, /)
| Return str(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| characters_written
|
| errno
| POSIX exception code
|
| filename
| exception filename
|
| filename2
| second exception filename
|
| strerror
| exception strerror
|
| winerror
| Win32 exception code
|
| ----------------------------------------------------------------------
| Methods inherited from BaseException:
|
| __delattr__(self, name, /)
| Implement delattr(self, name).
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __repr__(self, /)
| Return repr(self).
|
| __setattr__(self, name, value, /)
| Implement setattr(self, name, value).
|
| __setstate__(...)
|
| with_traceback(...)
| Exception.with_traceback(tb) --
| set self.__traceback__ to tb and return self.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from BaseException:
|
| __cause__
| exception cause
|
| __context__
| exception context
|
| __dict__
|
| __suppress_context__
|
| __traceback__
|
| args
class stat_result(builtins.tuple)
| stat_result: Result from stat, fstat, or lstat.
|
| This object may be accessed either as a tuple of
| (mode, ino, dev, nlink, uid, gid, size, atime, mtime, ctime)
| or via the attributes st_mode, st_ino, st_dev, st_nlink, st_uid, and so on.
|
| Posix/windows: If your platform supports st_blksize, st_blocks, st_rdev,
| or st_flags, they are available as attributes only.
|
| See os.stat for more information.
|
| Method resolution order:
| stat_result
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| st_atime
| time of last access
|
| st_atime_ns
| time of last access in nanoseconds
|
| st_ctime
| time of last change
|
| st_ctime_ns
| time of last change in nanoseconds
|
| st_dev
| device
|
| st_file_attributes
| Windows file attribute bits
|
| st_gid
| group ID of owner
|
| st_ino
| inode
|
| st_mode
| protection bits
|
| st_mtime
| time of last modification
|
| st_mtime_ns
| time of last modification in nanoseconds
|
| st_nlink
| number of hard links
|
| st_size
| total size, in bytes
|
| st_uid
| user ID of owner
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| n_fields = 17
|
| n_sequence_fields = 10
|
| n_unnamed_fields = 3
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
class statvfs_result(builtins.tuple)
| statvfs_result: Result from statvfs or fstatvfs.
|
| This object may be accessed either as a tuple of
| (bsize, frsize, blocks, bfree, bavail, files, ffree, favail, flag, namemax),
| or via the attributes f_bsize, f_frsize, f_blocks, f_bfree, and so on.
|
| See os.statvfs for more information.
|
| Method resolution order:
| statvfs_result
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| f_bavail
|
| f_bfree
|
| f_blocks
|
| f_bsize
|
| f_favail
|
| f_ffree
|
| f_files
|
| f_flag
|
| f_frsize
|
| f_namemax
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| n_fields = 10
|
| n_sequence_fields = 10
|
| n_unnamed_fields = 0
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
class terminal_size(builtins.tuple)
| A tuple of (columns, lines) for holding terminal window size
|
| Method resolution order:
| terminal_size
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| columns
| width of the terminal window in characters
|
| lines
| height of the terminal window in characters
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| n_fields = 2
|
| n_sequence_fields = 2
|
| n_unnamed_fields = 0
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
class times_result(builtins.tuple)
| times_result: Result from os.times().
|
| This object may be accessed either as a tuple of
| (user, system, children_user, children_system, elapsed),
| or via the attributes user, system, children_user, children_system,
| and elapsed.
|
| See os.times for more information.
|
| Method resolution order:
| times_result
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| children_system
| system time of children
|
| children_user
| user time of children
|
| elapsed
| elapsed time since an arbitrary point in the past
|
| system
| system time
|
| user
| user time
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| n_fields = 5
|
| n_sequence_fields = 5
|
| n_unnamed_fields = 0
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
class uname_result(builtins.tuple)
| uname_result: Result from os.uname().
|
| This object may be accessed either as a tuple of
| (sysname, nodename, release, version, machine),
| or via the attributes sysname, nodename, release, version, and machine.
|
| See os.uname for more information.
|
| Method resolution order:
| uname_result
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| machine
| hardware identifier
|
| nodename
| name of machine on network (implementation-defined)
|
| release
| operating system release
|
| sysname
| operating system name
|
| version
| operating system version
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| n_fields = 5
|
| n_sequence_fields = 5
|
| n_unnamed_fields = 0
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
FUNCTIONS
_exit(status)
Exit to the system with specified status, without normal exit processing.
abort()
Abort the interpreter immediately.
This function 'dumps core' or otherwise fails in the hardest way possible
on the hosting operating system. This function never returns.
access(path, mode, *, dir_fd=None, effective_ids=False, follow_symlinks=True)
Use the real uid/gid to test for access to a path.
path
Path to be tested; can be string or bytes
mode
Operating-system mode bitfield. Can be F_OK to test existence,
or the inclusive-OR of R_OK, W_OK, and X_OK.
dir_fd
If not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that
directory.
effective_ids
If True, access will use the effective uid/gid instead of
the real uid/gid.
follow_symlinks
If False, and the last element of the path is a symbolic link,
access will examine the symbolic link itself instead of the file
the link points to.
dir_fd, effective_ids, and follow_symlinks may not be implemented
on your platform. If they are unavailable, using them will raise a
NotImplementedError.
Note that most operations will use the effective uid/gid, therefore this
routine can be used in a suid/sgid environment to test if the invoking user
has the specified access to the path.
chdir(path)
Change the current working directory to the specified path.
path may always be specified as a string.
On some platforms, path may also be specified as an open file descriptor.
If this functionality is unavailable, using it raises an exception.
chmod(path, mode, *, dir_fd=None, follow_symlinks=True)
Change the access permissions of a file.
path
Path to be modified. May always be specified as a str or bytes.
On some platforms, path may also be specified as an open file descriptor.
If this functionality is unavailable, using it raises an exception.
mode
Operating-system mode bitfield.
dir_fd
If not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that
directory.
follow_symlinks
If False, and the last element of the path is a symbolic link,
chmod will modify the symbolic link itself instead of the file
the link points to.
It is an error to use dir_fd or follow_symlinks when specifying path as
an open file descriptor.
dir_fd and follow_symlinks may not be implemented on your platform.
If they are unavailable, using them will raise a NotImplementedError.
close(fd)
Close a file descriptor.
closerange(fd_low, fd_high, /)
Closes all file descriptors in [fd_low, fd_high), ignoring errors.
cpu_count()
Return the number of CPUs in the system; return None if indeterminable.
This number is not equivalent to the number of CPUs the current process can
use. The number of usable CPUs can be obtained with
``len(os.sched_getaffinity(0))``
device_encoding(fd)
Return a string describing the encoding of a terminal's file descriptor.
The file descriptor must be attached to a terminal.
If the device is not a terminal, return None.
dup(fd, /)
Return a duplicate of a file descriptor.
dup2(fd, fd2, inheritable=True)
Duplicate file descriptor.
execl(file, *args)
execl(file, *args)
Execute the executable file with argument list args, replacing the
current process.
execle(file, *args)
execle(file, *args, env)
Execute the executable file with argument list args and
environment env, replacing the current process.
execlp(file, *args)
execlp(file, *args)
Execute the executable file (which is searched for along $PATH)
with argument list args, replacing the current process.
execlpe(file, *args)
execlpe(file, *args, env)
Execute the executable file (which is searched for along $PATH)
with argument list args and environment env, replacing the current
process.
execv(path, argv, /)
Execute an executable path with arguments, replacing current process.
path
Path of executable file.
argv
Tuple or list of strings.
execve(path, argv, env)
Execute an executable path with arguments, replacing current process.
path
Path of executable file.
argv
Tuple or list of strings.
env
Dictionary of strings mapping to strings.
execvp(file, args)
execvp(file, args)
Execute the executable file (which is searched for along $PATH)
with argument list args, replacing the current process.
args may be a list or tuple of strings.
execvpe(file, args, env)
execvpe(file, args, env)
Execute the executable file (which is searched for along $PATH)
with argument list args and environment env , replacing the
current process.
args may be a list or tuple of strings.
fdopen(fd, *args, **kwargs)
# Supply os.fdopen()
fsdecode(filename)
Decode filename (an os.PathLike, bytes, or str) from the filesystem
encoding with 'surrogateescape' error handler, return str unchanged. On
Windows, use 'strict' error handler if the file system encoding is
'mbcs' (which is the default encoding).
fsencode(filename)
Encode filename (an os.PathLike, bytes, or str) to the filesystem
encoding with 'surrogateescape' error handler, return bytes unchanged.
On Windows, use 'strict' error handler if the file system encoding is
'mbcs' (which is the default encoding).
fspath(path)
Return the file system path representation of the object.
If the object is str or bytes, then allow it to pass through as-is. If the
object defines __fspath__(), then return the result of that method. All other
types raise a TypeError.
fstat(fd)
Perform a stat system call on the given file descriptor.
Like stat(), but for an open file descriptor.
Equivalent to os.stat(fd).
fsync(fd)
Force write of fd to disk.
ftruncate(fd, length, /)
Truncate a file, specified by file descriptor, to a specific length.
get_exec_path(env=None)
Returns the sequence of directories that will be searched for the
named executable (similar to a shell) when launching a process.
*env* must be an environment variable dict or None. If *env* is None,
os.environ will be used.
get_handle_inheritable(handle, /)
Get the close-on-exe flag of the specified file descriptor.
get_inheritable(fd, /)
Get the close-on-exe flag of the specified file descriptor.
get_terminal_size(...)
Return the size of the terminal window as (columns, lines).
The optional argument fd (default standard output) specifies
which file descriptor should be queried.
If the file descriptor is not connected to a terminal, an OSError
is thrown.
This function will only be defined if an implementation is
available for this system.
shutil.get_terminal_size is the high-level function which should
normally be used, os.get_terminal_size is the low-level implementation.
getcwd()
Return a unicode string representing the current working directory.
getcwdb()
Return a bytes string representing the current working directory.
getenv(key, default=None)
Get an environment variable, return None if it doesn't exist.
The optional second argument can specify an alternate default.
key, default and the result are str.
getlogin()
Return the actual login name.
getpid()
Return the current process id.
getppid()
Return the parent's process id.
If the parent process has already exited, Windows machines will still
return its id; others systems will return the id of the 'init' process (1).
isatty(fd, /)
Return True if the fd is connected to a terminal.
Return True if the file descriptor is an open file descriptor
connected to the slave end of a terminal.
kill(pid, signal, /)
Kill a process with a signal.
link(src, dst, *, src_dir_fd=None, dst_dir_fd=None, follow_symlinks=True)
Create a hard link to a file.
If either src_dir_fd or dst_dir_fd is not None, it should be a file
descriptor open to a directory, and the respective path string (src or dst)
should be relative; the path will then be relative to that directory.
If follow_symlinks is False, and the last element of src is a symbolic
link, link will create a link to the symbolic link itself instead of the
file the link points to.
src_dir_fd, dst_dir_fd, and follow_symlinks may not be implemented on your
platform. If they are unavailable, using them will raise a
NotImplementedError.
listdir(path=None)
Return a list containing the names of the files in the directory.
path can be specified as either str or bytes. If path is bytes,
the filenames returned will also be bytes; in all other circumstances
the filenames returned will be str.
If path is None, uses the path='.'.
On some platforms, path may also be specified as an open file descriptor;\
the file descriptor must refer to a directory.
If this functionality is unavailable, using it raises NotImplementedError.
The list is in arbitrary order. It does not include the special
entries '.' and '..' even if they are present in the directory.
lseek(fd, position, how, /)
Set the position of a file descriptor. Return the new position.
Return the new cursor position in number of bytes
relative to the beginning of the file.
lstat(path, *, dir_fd=None)
Perform a stat system call on the given path, without following symbolic links.
Like stat(), but do not follow symbolic links.
Equivalent to stat(path, follow_symlinks=False).
makedirs(name, mode=511, exist_ok=False)
makedirs(name [, mode=0o777][, exist_ok=False])
Super-mkdir; create a leaf directory and all intermediate ones. Works like
mkdir, except that any intermediate path segment (not just the rightmost)
will be created if it does not exist. If the target directory already
exists, raise an OSError if exist_ok is False. Otherwise no exception is
raised. This is recursive.
mkdir(path, mode=511, *, dir_fd=None)
Create a directory.
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
The mode argument is ignored on Windows.
open(path, flags, mode=511, *, dir_fd=None)
Open a file for low level IO. Returns a file descriptor (integer).
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
pipe()
Create a pipe.
Returns a tuple of two file descriptors:
(read_fd, write_fd)
popen(cmd, mode='r', buffering=-1)
# Supply os.popen()
putenv(name, value, /)
Change or add an environment variable.
read(fd, length, /)
Read from a file descriptor. Returns a bytes object.
readlink(...)
readlink(path, *, dir_fd=None) -> path
Return a string representing the path to which the symbolic link points.
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
remove(path, *, dir_fd=None)
Remove a file (same as unlink()).
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
removedirs(name)
removedirs(name)
Super-rmdir; remove a leaf directory and all empty intermediate
ones. Works like rmdir except that, if the leaf directory is
successfully removed, directories corresponding to rightmost path
segments will be pruned away until either the whole path is
consumed or an error occurs. Errors during this latter phase are
ignored -- they generally mean that a directory was not empty.
rename(src, dst, *, src_dir_fd=None, dst_dir_fd=None)
Rename a file or directory.
If either src_dir_fd or dst_dir_fd is not None, it should be a file
descriptor open to a directory, and the respective path string (src or dst)
should be relative; the path will then be relative to that directory.
src_dir_fd and dst_dir_fd, may not be implemented on your platform.
If they are unavailable, using them will raise a NotImplementedError.
renames(old, new)
renames(old, new)
Super-rename; create directories as necessary and delete any left
empty. Works like rename, except creation of any intermediate
directories needed to make the new pathname good is attempted
first. After the rename, directories corresponding to rightmost
path segments of the old name will be pruned until either the
whole path is consumed or a nonempty directory is found.
Note: this function can fail with the new directory structure made
if you lack permissions needed to unlink the leaf directory or
file.
replace(src, dst, *, src_dir_fd=None, dst_dir_fd=None)
Rename a file or directory, overwriting the destination.
If either src_dir_fd or dst_dir_fd is not None, it should be a file
descriptor open to a directory, and the respective path string (src or dst)
should be relative; the path will then be relative to that directory.
src_dir_fd and dst_dir_fd, may not be implemented on your platform.
If they are unavailable, using them will raise a NotImplementedError."
rmdir(path, *, dir_fd=None)
Remove a directory.
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
scandir(...)
scandir(path='.') -> iterator of DirEntry objects for given path
set_handle_inheritable(handle, inheritable, /)
Set the inheritable flag of the specified handle.
set_inheritable(fd, inheritable, /)
Set the inheritable flag of the specified file descriptor.
spawnl(mode, file, *args)
spawnl(mode, file, *args) -> integer
Execute file with arguments from args in a subprocess.
If mode == P_NOWAIT return the pid of the process.
If mode == P_WAIT return the process's exit code if it exits normally;
otherwise return -SIG, where SIG is the signal that killed it.
spawnle(mode, file, *args)
spawnle(mode, file, *args, env) -> integer
Execute file with arguments from args in a subprocess with the
supplied environment.
If mode == P_NOWAIT return the pid of the process.
If mode == P_WAIT return the process's exit code if it exits normally;
otherwise return -SIG, where SIG is the signal that killed it.
spawnv(mode, path, argv, /)
Execute the program specified by path in a new process.
mode
Mode of process creation.
path
Path of executable file.
argv
Tuple or list of strings.
spawnve(mode, path, argv, env, /)
Execute the program specified by path in a new process.
mode
Mode of process creation.
path
Path of executable file.
argv
Tuple or list of strings.
env
Dictionary of strings mapping to strings.
startfile(filepath, operation=None)
startfile(filepath [, operation])
Start a file with its associated application.
When "operation" is not specified or "open", this acts like
double-clicking the file in Explorer, or giving the file name as an
argument to the DOS "start" command: the file is opened with whatever
application (if any) its extension is associated.
When another "operation" is given, it specifies what should be done with
the file. A typical operation is "print".
startfile returns as soon as the associated application is launched.
There is no option to wait for the application to close, and no way
to retrieve the application's exit status.
The filepath is relative to the current directory. If you want to use
an absolute path, make sure the first character is not a slash ("/");
the underlying Win32 ShellExecute function doesn't work if it is.
stat(path, *, dir_fd=None, follow_symlinks=True)
Perform a stat system call on the given path.
path
Path to be examined; can be string, bytes, path-like object or
open-file-descriptor int.
dir_fd
If not None, it should be a file descriptor open to a directory,
and path should be a relative string; path will then be relative to
that directory.
follow_symlinks
If False, and the last element of the path is a symbolic link,
stat will examine the symbolic link itself instead of the file
the link points to.
dir_fd and follow_symlinks may not be implemented
on your platform. If they are unavailable, using them will raise a
NotImplementedError.
It's an error to use dir_fd or follow_symlinks when specifying path as
an open file descriptor.
stat_float_times(...)
stat_float_times([newval]) -> oldval
Determine whether os.[lf]stat represents time stamps as float objects.
If value is True, future calls to stat() return floats; if it is False,
future calls return ints.
If value is omitted, return the current setting.
strerror(code, /)
Translate an error code to a message string.
symlink(src, dst, target_is_directory=False, *, dir_fd=None)
Create a symbolic link pointing to src named dst.
target_is_directory is required on Windows if the target is to be
interpreted as a directory. (On Windows, symlink requires
Windows 6.0 or greater, and raises a NotImplementedError otherwise.)
target_is_directory is ignored on non-Windows platforms.
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
system(command)
Execute the command in a subshell.
times()
Return a collection containing process timing information.
The object returned behaves like a named tuple with these fields:
(utime, stime, cutime, cstime, elapsed_time)
All fields are floating point numbers.
truncate(path, length)
Truncate a file, specified by path, to a specific length.
On some platforms, path may also be specified as an open file descriptor.
If this functionality is unavailable, using it raises an exception.
umask(mask, /)
Set the current numeric umask and return the previous umask.
unlink(path, *, dir_fd=None)
Remove a file (same as remove()).
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
dir_fd may not be implemented on your platform.
If it is unavailable, using it will raise a NotImplementedError.
urandom(size, /)
Return a bytes object containing random bytes suitable for cryptographic use.
utime(path, times=None, *, ns=None, dir_fd=None, follow_symlinks=True)
Set the access and modified time of path.
path may always be specified as a string.
On some platforms, path may also be specified as an open file descriptor.
If this functionality is unavailable, using it raises an exception.
If times is not None, it must be a tuple (atime, mtime);
atime and mtime should be expressed as float seconds since the epoch.
If ns is specified, it must be a tuple (atime_ns, mtime_ns);
atime_ns and mtime_ns should be expressed as integer nanoseconds
since the epoch.
If times is None and ns is unspecified, utime uses the current time.
Specifying tuples for both times and ns is an error.
If dir_fd is not None, it should be a file descriptor open to a directory,
and path should be relative; path will then be relative to that directory.
If follow_symlinks is False, and the last element of the path is a symbolic
link, utime will modify the symbolic link itself instead of the file the
link points to.
It is an error to use dir_fd or follow_symlinks when specifying path
as an open file descriptor.
dir_fd and follow_symlinks may not be available on your platform.
If they are unavailable, using them will raise a NotImplementedError.
waitpid(pid, options, /)
Wait for completion of a given process.
Returns a tuple of information regarding the process:
(pid, status << 8)
The options argument is ignored on Windows.
walk(top, topdown=True, onerror=None, followlinks=False)
Directory tree generator.
For each directory in the directory tree rooted at top (including top
itself, but excluding '.' and '..'), yields a 3-tuple
dirpath, dirnames, filenames
dirpath is a string, the path to the directory. dirnames is a list of
the names of the subdirectories in dirpath (excluding '.' and '..').
filenames is a list of the names of the non-directory files in dirpath.
Note that the names in the lists are just names, with no path components.
To get a full path (which begins with top) to a file or directory in
dirpath, do os.path.join(dirpath, name).
If optional arg 'topdown' is true or not specified, the triple for a
directory is generated before the triples for any of its subdirectories
(directories are generated top down). If topdown is false, the triple
for a directory is generated after the triples for all of its
subdirectories (directories are generated bottom up).
When topdown is true, the caller can modify the dirnames list in-place
(e.g., via del or slice assignment), and walk will only recurse into the
subdirectories whose names remain in dirnames; this can be used to prune the
search, or to impose a specific order of visiting. Modifying dirnames when
topdown is false is ineffective, since the directories in dirnames have
already been generated by the time dirnames itself is generated. No matter
the value of topdown, the list of subdirectories is retrieved before the
tuples for the directory and its subdirectories are generated.
By default errors from the os.scandir() call are ignored. If
optional arg 'onerror' is specified, it should be a function; it
will be called with one argument, an OSError instance. It can
report the error to continue with the walk, or raise the exception
to abort the walk. Note that the filename is available as the
filename attribute of the exception object.
By default, os.walk does not follow symbolic links to subdirectories on
systems that support them. In order to get this functionality, set the
optional argument 'followlinks' to true.
Caution: if you pass a relative pathname for top, don't change the
current working directory between resumptions of walk. walk never
changes the current directory, and assumes that the client doesn't
either.
Example:
import os
from os.path import join, getsize
for root, dirs, files in os.walk('python/Lib/email'):
print(root, "consumes", end="")
print(sum([getsize(join(root, name)) for name in files]), end="")
print("bytes in", len(files), "non-directory files")
if 'CVS' in dirs:
dirs.remove('CVS') # don't visit CVS directories
write(fd, data, /)
Write a bytes object to a file descriptor.
DATA
F_OK = 0
O_APPEND = 8
O_BINARY = 32768
O_CREAT = 256
O_EXCL = 1024
O_NOINHERIT = 128
O_RANDOM = 16
O_RDONLY = 0
O_RDWR = 2
O_SEQUENTIAL = 32
O_SHORT_LIVED = 4096
O_TEMPORARY = 64
O_TEXT = 16384
O_TRUNC = 512
O_WRONLY = 1
P_DETACH = 4
P_NOWAIT = 1
P_NOWAITO = 3
P_OVERLAY = 2
P_WAIT = 0
R_OK = 4
SEEK_CUR = 1
SEEK_END = 2
SEEK_SET = 0
TMP_MAX = 2147483647
W_OK = 2
X_OK = 1
all = [‘altsep’, ‘curdir’, ‘pardir’, ‘sep’, ‘pathsep’, ‘linesep’, …
altsep = ‘/’
curdir = ‘.’
defpath = r’.;C:\bin’
devnull = ‘nul’
environ = environ({‘ALLUSERSPROFILE’: ‘C:\ProgramData’, ‘…c\hadoop…
extsep = ‘.’
linesep = ‘\r\n’
name = ‘nt’
pardir = ‘…’
pathsep = ‘;’
sep = r’’
supports_bytes_environ = False
FILE
h:\anaconda\lib\os.py
os.path 源码
在这里插入代码片
>>> help(os.path)
Help on module ntpath:
NAME
ntpath - Common pathname manipulations, WindowsNT/95 version.
DESCRIPTION
Instead of importing this module directly, import os and refer to this
module as os.path.
FUNCTIONS
abspath(path)
Return the absolute version of a path.
basename(p)
Returns the final component of a pathname
commonpath(paths)
Given a sequence of path names, returns the longest common sub-path.
commonprefix(m)
Given a list of pathnames, returns the longest common leading component
dirname(p)
Returns the directory component of a pathname
exists(path)
Test whether a path exists. Returns False for broken symbolic links
expanduser(path)
Expand ~ and ~user constructs.
If user or $HOME is unknown, do nothing.
expandvars(path)
Expand shell variables of the forms $var, ${var} and %var%.
Unknown variables are left unchanged.
getatime(filename)
Return the last access time of a file, reported by os.stat().
getctime(filename)
Return the metadata change time of a file, reported by os.stat().
getmtime(filename)
Return the last modification time of a file, reported by os.stat().
getsize(filename)
Return the size of a file, reported by os.stat().
isabs(s)
Test whether a path is absolute
isdir = _isdir(path, /)
Return true if the pathname refers to an existing directory.
isfile(path)
Test whether a path is a regular file
islink(path)
Test whether a path is a symbolic link.
This will always return false for Windows prior to 6.0.
ismount(path)
Test whether a path is a mount point (a drive root, the root of a
share, or a mounted volume)
join(path, *paths)
# Join two (or more) paths.
lexists(path)
Test whether a path exists. Returns True for broken symbolic links
normcase(s)
Normalize case of pathname.
Makes all characters lowercase and all slashes into backslashes.
normpath(path)
Normalize path, eliminating double slashes, etc.
realpath = abspath(path)
Return the absolute version of a path.
relpath(path, start=None)
Return a relative version of a path
samefile(f1, f2)
Test whether two pathnames reference the same actual file
sameopenfile(fp1, fp2)
Test whether two open file objects reference the same file
samestat(s1, s2)
Test whether two stat buffers reference the same file
split(p)
Split a pathname.
Return tuple (head, tail) where tail is everything after the final slash.
Either part may be empty.
splitdrive(p)
Split a pathname into drive/UNC sharepoint and relative path specifiers.
Returns a 2-tuple (drive_or_unc, path); either part may be empty.
If you assign
result = splitdrive(p)
It is always true that:
result[0] + result[1] == p
If the path contained a drive letter, drive_or_unc will contain everything
up to and including the colon. e.g. splitdrive("c:/dir") returns ("c:", "/dir")
If the path contained a UNC path, the drive_or_unc will contain the host name
and share up to but not including the fourth directory separator character.
e.g. splitdrive("//host/computer/dir") returns ("//host/computer", "/dir")
Paths cannot contain both a drive letter and a UNC path.
splitext(p)
Split the extension from a pathname.
Extension is everything from the last dot to the end, ignoring
leading dots. Returns "(root, ext)"; ext may be empty.
splitunc(p)
Deprecated since Python 3.1. Please use splitdrive() instead;
it now handles UNC paths.
Split a pathname into UNC mount point and relative path specifiers.
Return a 2-tuple (unc, rest); either part may be empty.
If unc is not empty, it has the form '//host/mount' (or similar
using backslashes). unc+rest is always the input path.
Paths containing drive letters never have a UNC part.
DATA
__all__ = ['normcase', 'isabs', 'join', 'splitdrive', 'split', 'splite...
altsep = '/'
curdir = '.'
defpath = r'.;C:\bin'
devnull = 'nul'
extsep = '.'
pardir = '..'
pathsep = ';'
sep = r'\'
supports_unicode_filenames = True
FILE
h:\anaconda\lib\ntpath.py
pickle 源码
>>> help(pickle)
Help on module pickle:
NAME
pickle - Create portable serialized representations of Python objects.
DESCRIPTION
See module copyreg for a mechanism for registering custom picklers.
See module pickletools source for extensive comments.
Classes:
Pickler
Unpickler
Functions:
dump(object, file)
dumps(object) -> string
load(file) -> object
loads(string) -> object
Misc variables:
__version__
format_version
compatible_formats
CLASSES
builtins.Exception(builtins.BaseException)
_pickle.PickleError
_pickle.PicklingError
_pickle.UnpicklingError
builtins.object
_pickle.Pickler
_pickle.Unpickler
class PickleError(builtins.Exception)
| Common base class for all non-exit exceptions.
|
| Method resolution order:
| PickleError
| builtins.Exception
| builtins.BaseException
| builtins.object
|
| Data descriptors defined here:
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.Exception:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.BaseException:
|
| __delattr__(self, name, /)
| Implement delattr(self, name).
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| __setattr__(self, name, value, /)
| Implement setattr(self, name, value).
|
| __setstate__(...)
|
| __str__(self, /)
| Return str(self).
|
| with_traceback(...)
| Exception.with_traceback(tb) --
| set self.__traceback__ to tb and return self.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from builtins.BaseException:
|
| __cause__
| exception cause
|
| __context__
| exception context
|
| __dict__
|
| __suppress_context__
|
| __traceback__
|
| args
class Pickler(builtins.object)
| This takes a binary file for writing a pickle data stream.
|
| The optional *protocol* argument tells the pickler to use the given
| protocol; supported protocols are 0, 1, 2, 3 and 4. The default
| protocol is 3; a backward-incompatible protocol designed for Python 3.
|
| Specifying a negative protocol version selects the highest protocol
| version supported. The higher the protocol used, the more recent the
| version of Python needed to read the pickle produced.
|
| The *file* argument must have a write() method that accepts a single
| bytes argument. It can thus be a file object opened for binary
| writing, an io.BytesIO instance, or any other custom object that meets
| this interface.
|
| If *fix_imports* is True and protocol is less than 3, pickle will try
| to map the new Python 3 names to the old module names used in Python
| 2, so that the pickle data stream is readable with Python 2.
|
| Methods defined here:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __sizeof__(self, /)
| Returns size in memory, in bytes.
|
| clear_memo(self, /)
| Clears the pickler's "memo".
|
| The memo is the data structure that remembers which objects the
| pickler has already seen, so that shared or recursive objects are
| pickled by reference and not by value. This method is useful when
| re-using picklers.
|
| dump(self, obj, /)
| Write a pickled representation of the given object to the open file.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| bin
|
| dispatch_table
|
| fast
|
| memo
|
| persistent_id
class PicklingError(PickleError)
| Common base class for all non-exit exceptions.
|
| Method resolution order:
| PicklingError
| PickleError
| builtins.Exception
| builtins.BaseException
| builtins.object
|
| Data descriptors inherited from PickleError:
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.Exception:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.BaseException:
|
| __delattr__(self, name, /)
| Implement delattr(self, name).
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| __setattr__(self, name, value, /)
| Implement setattr(self, name, value).
|
| __setstate__(...)
|
| __str__(self, /)
| Return str(self).
|
| with_traceback(...)
| Exception.with_traceback(tb) --
| set self.__traceback__ to tb and return self.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from builtins.BaseException:
|
| __cause__
| exception cause
|
| __context__
| exception context
|
| __dict__
|
| __suppress_context__
|
| __traceback__
|
| args
class Unpickler(builtins.object)
| This takes a binary file for reading a pickle data stream.
|
| The protocol version of the pickle is detected automatically, so no
| protocol argument is needed. Bytes past the pickled object's
| representation are ignored.
|
| The argument *file* must have two methods, a read() method that takes
| an integer argument, and a readline() method that requires no
| arguments. Both methods should return bytes. Thus *file* can be a
| binary file object opened for reading, an io.BytesIO object, or any
| other custom object that meets this interface.
|
| Optional keyword arguments are *fix_imports*, *encoding* and *errors*,
| which are used to control compatibility support for pickle stream
| generated by Python 2. If *fix_imports* is True, pickle will try to
| map the old Python 2 names to the new names used in Python 3. The
| *encoding* and *errors* tell pickle how to decode 8-bit string
| instances pickled by Python 2; these default to 'ASCII' and 'strict',
| respectively. The *encoding* can be 'bytes' to read these 8-bit
| string instances as bytes objects.
|
| Methods defined here:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __sizeof__(self, /)
| Returns size in memory, in bytes.
|
| find_class(self, module_name, global_name, /)
| Return an object from a specified module.
|
| If necessary, the module will be imported. Subclasses may override
| this method (e.g. to restrict unpickling of arbitrary classes and
| functions).
|
| This method is called whenever a class or a function object is
| needed. Both arguments passed are str objects.
|
| load(self, /)
| Load a pickle.
|
| Read a pickled object representation from the open file object given
| in the constructor, and return the reconstituted object hierarchy
| specified therein.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| memo
|
| persistent_load
class UnpicklingError(PickleError)
| Common base class for all non-exit exceptions.
|
| Method resolution order:
| UnpicklingError
| PickleError
| builtins.Exception
| builtins.BaseException
| builtins.object
|
| Data descriptors inherited from PickleError:
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.Exception:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.BaseException:
|
| __delattr__(self, name, /)
| Implement delattr(self, name).
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __reduce__(...)
| helper for pickle
|
| __repr__(self, /)
| Return repr(self).
|
| __setattr__(self, name, value, /)
| Implement setattr(self, name, value).
|
| __setstate__(...)
|
| __str__(self, /)
| Return str(self).
|
| with_traceback(...)
| Exception.with_traceback(tb) --
| set self.__traceback__ to tb and return self.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from builtins.BaseException:
|
| __cause__
| exception cause
|
| __context__
| exception context
|
| __dict__
|
| __suppress_context__
|
| __traceback__
|
| args
FUNCTIONS
dump(obj, file, protocol=None, *, fix_imports=True)
Write a pickled representation of obj to the open file object file.
This is equivalent to ``Pickler(file, protocol).dump(obj)``, but may
be more efficient.
The optional *protocol* argument tells the pickler to use the given
protocol supported protocols are 0, 1, 2, 3 and 4. The default
protocol is 3; a backward-incompatible protocol designed for Python 3.
Specifying a negative protocol version selects the highest protocol
version supported. The higher the protocol used, the more recent the
version of Python needed to read the pickle produced.
The *file* argument must have a write() method that accepts a single
bytes argument. It can thus be a file object opened for binary
writing, an io.BytesIO instance, or any other custom object that meets
this interface.
If *fix_imports* is True and protocol is less than 3, pickle will try
to map the new Python 3 names to the old module names used in Python
2, so that the pickle data stream is readable with Python 2.
dumps(obj, protocol=None, *, fix_imports=True)
Return the pickled representation of the object as a bytes object.
The optional *protocol* argument tells the pickler to use the given
protocol; supported protocols are 0, 1, 2, 3 and 4. The default
protocol is 3; a backward-incompatible protocol designed for Python 3.
Specifying a negative protocol version selects the highest protocol
version supported. The higher the protocol used, the more recent the
version of Python needed to read the pickle produced.
If *fix_imports* is True and *protocol* is less than 3, pickle will
try to map the new Python 3 names to the old module names used in
Python 2, so that the pickle data stream is readable with Python 2.
load(file, *, fix_imports=True, encoding='ASCII', errors='strict')
Read and return an object from the pickle data stored in a file.
This is equivalent to ``Unpickler(file).load()``, but may be more
efficient.
The protocol version of the pickle is detected automatically, so no
protocol argument is needed. Bytes past the pickled object's
representation are ignored.
The argument *file* must have two methods, a read() method that takes
an integer argument, and a readline() method that requires no
arguments. Both methods should return bytes. Thus *file* can be a
binary file object opened for reading, an io.BytesIO object, or any
other custom object that meets this interface.
Optional keyword arguments are *fix_imports*, *encoding* and *errors*,
which are used to control compatibility support for pickle stream
generated by Python 2. If *fix_imports* is True, pickle will try to
map the old Python 2 names to the new names used in Python 3. The
*encoding* and *errors* tell pickle how to decode 8-bit string
instances pickled by Python 2; these default to 'ASCII' and 'strict',
respectively. The *encoding* can be 'bytes' to read these 8-bit
string instances as bytes objects.
loads(data, *, fix_imports=True, encoding='ASCII', errors='strict')
Read and return an object from the given pickle data.
The protocol version of the pickle is detected automatically, so no
protocol argument is needed. Bytes past the pickled object's
representation are ignored.
Optional keyword arguments are *fix_imports*, *encoding* and *errors*,
which are used to control compatibility support for pickle stream
generated by Python 2. If *fix_imports* is True, pickle will try to
map the old Python 2 names to the new names used in Python 3. The
*encoding* and *errors* tell pickle how to decode 8-bit string
instances pickled by Python 2; these default to 'ASCII' and 'strict',
respectively. The *encoding* can be 'bytes' to read these 8-bit
string instances as bytes objects.
DATA
ADDITEMS = b'\x90'
APPEND = b'a'
APPENDS = b'e'
BINBYTES = b'B'
BINBYTES8 = b'\x8e'
BINFLOAT = b'G'
BINGET = b'h'
BININT = b'J'
BININT1 = b'K'
BININT2 = b'M'
BINPERSID = b'Q'
BINPUT = b'q'
BINSTRING = b'T'
BINUNICODE = b'X'
BINUNICODE8 = b'\x8d'
BUILD = b'b'
DEFAULT_PROTOCOL = 3
DICT = b'd'
DUP = b'2'
EMPTY_DICT = b'}'
EMPTY_LIST = b']'
EMPTY_SET = b'\x8f'
EMPTY_TUPLE = b')'
EXT1 = b'\x82'
EXT2 = b'\x83'
EXT4 = b'\x84'
FALSE = b'I00\n'
FLOAT = b'F'
FRAME = b'\x95'
FROZENSET = b'\x91'
GET = b'g'
GLOBAL = b'c'
HIGHEST_PROTOCOL = 4
INST = b'i'
INT = b'I'
LIST = b'l'
LONG = b'L'
LONG1 = b'\x8a'
LONG4 = b'\x8b'
LONG_BINGET = b'j'
LONG_BINPUT = b'r'
MARK = b'('
MEMOIZE = b'\x94'
NEWFALSE = b'\x89'
NEWOBJ = b'\x81'
NEWOBJ_EX = b'\x92'
NEWTRUE = b'\x88'
NONE = b'N'
OBJ = b'o'
PERSID = b'P'
POP = b'0'
POP_MARK = b'1'
PROTO = b'\x80'
PUT = b'p'
REDUCE = b'R'
SETITEM = b's'
SETITEMS = b'u'
SHORT_BINBYTES = b'C'
SHORT_BINSTRING = b'U'
SHORT_BINUNICODE = b'\x8c'
STACK_GLOBAL = b'\x93'
STOP = b'.'
STRING = b'S'
TRUE = b'I01\n'
TUPLE = b't'
TUPLE1 = b'\x85'
TUPLE2 = b'\x86'
TUPLE3 = b'\x87'
UNICODE = b'V'
__all__ = ['PickleError', 'PicklingError', 'UnpicklingError', 'Pickler...
FILE
h:\anaconda\lib\pickle.py