Python 面试题
Python面试315道题
- 第一部 Python面试题基础篇(80道)
- 1、为什么学习Python?
- 2、通过什么途径学习的Python?
- 3、Python和Java、PHP、C、C#、C++等其他语言的对比?
- PHP
- java
- c
- c#
- c++
- 4、简述解释型和编译型编程语言?
- 编译型语言
- 特点
- 总结
- 解释型语言
- 特点
- 总结
- 5、Python解释器种类以及特点?
- CPython
- IPython
- PyPy
- JPython
- IronPython
- 6、位和字节的关系?
- 7、b、B、KB、MB、GB 的关系?
- 8、请至少列举5个 PEP8 规范(越多越好)
- 9、通过代码实现如下转换:
- 10、请编写一个函数实现将IP地址转换成一个整数。
- 11、python递归的最大层数?
- 12、求结果:
- 13、ascii、unicode、utf-8、gbk 区别?
- 14、字节码和机器码的区别?
- 字节码
- 机器码
- 转换关系
- 使用
- 15、三元运算规则以及应用场景?
- 16、列举 Python2和Python3的区别?
- 17、用一行代码实现数值交换:
- 18、Python3和Python2中 int 和 long的区别?
- 19、xrange和range的区别?
- 20、文件操作时:xreadlines和readlines的区别?
- 21、列举布尔值为False的常见值?
- 22、字符串、列表、元组、字典每个常用的5个方法?
- 23、lambda表达式格式以及应用场景?
- 24、pass的作用?
- 25、*arg和**kwarg作用
- 26、is和==的区别
- 27、简述Python的深浅拷贝以及应用场景?
- 28、Python垃圾回收机制?
- 29、Python的可变类型和不可变类型?
- 30、求结果:
- 31、求结果:
- 32、列举常见的内置函数?
- 33、filter、map、reduce的作用?
- 1. map
- 2. filter
- 3. reduce
- 34、一行代码实现9*9乘法表
- 35、如何安装第三方模块?以及用过哪些第三方模块?
- 36、至少列举8个常用模块都有哪些?
- 37、re的match和search区别?
- 38、什么是正则的贪婪匹配?
- 1.哒哒哒哒哒哒多多多 正则表达式的贪婪与非贪婪匹配
- 2.编程中如何区分两种模式
- 39、求结果:a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) ) (Python中列表生成式和生成器的区别)
- 40、求结果:a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
- 41、def func(a,b=[]) 这种写法有什么坑?
- 42、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
- 43、如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
- 44、比较:a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
- 45、如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
- 46、一行代码实现删除列表中重复的值 ?
- 47、如何在函数中设置一个全局变量 ?
- 48、logging模块的作用?以及应用场景?
- 49、请用代码简答实现stack 。
- 实现一个栈stack,后进先出
- 50、常用字符串格式化哪几种?
- 51、简述 生成器、迭代器、可迭代对象 以及应用场景?
- 52、用Python实现一个二分查找的函数。
- 53、谈谈你对闭包的理解?
- 54、os和sys模块的作用?
- 55、如何生成一个随机数?
- 56、如何使用python删除一个文件?
- 57、谈谈你对面向对象的理解?
- 58、Python面向对象中的继承有什么特点?
- 59、面向对象深度优先和广度优先是什么?
- 60、面向对象中super的作用?
- 61、是否使用过functools中的函数?其作用是什么?
- 62、列举面向对象中带双下划线的特殊方法,如:__new__、__init__
- 63、如何判断是函数还是方法?
- 64、静态方法和类方法区别?
- 65、列举面向对象中的特殊成员以及应用场景
- 66、1、2、3、4、5 能组成多少个互不相同且无重复的三位数
- 67、什么是反射?以及应用场景?
- 68、metaclass作用?以及应用场景?
- 69、用尽量多的方法实现单例模式。
- 70、装饰器的写法以及应用场景。
- 71、异常处理写法以及如何主动抛出异常(应用场景)
- 72、什么是面向对象的MRO
- 73、isinstance作用以及应用场景?
- 74、写代码并实现:
- 75、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
- **JSON主要支持6种数据类型:**
- **定制支持datetime类型**
- 76、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
- 77、什么是断言(assert)?应用场景?
- 78、有用过with statement吗?它的好处是什么?
- 79、使用代码实现查看列举目录下的所有文件。
- 80、简述 yield和yield from关键字。
- 迭代器和生成器的区别?
第一部 Python面试题基础篇(80道)
你好! 闲来无事,打发时间!一共315道题,先来基础篇80道!
1、为什么学习Python?
python优势可以简单说一些,对于初学者来说很简单,从Python开始是最好的选择。因为它易于学习,功能强大,足以构建Web应用程序并自动化无聊的东西。实际上,几年前,脚本编写是学习Python的主要原因,这也是我被Python吸引并首选Perl的原因,而Perl是当时另一种流行的脚本语言。
对于有经验的程序员或已经了解Ruby,Java或JavaScript的人来说,学习Python意味着在你的工具库中获得一个新的强大工具,我还没有想出一个对工具说“不”的程序员,这是你学习一门新的编程语言时的正确查找方式。
正如经典的Automate the Boring Stuff with Python一书中所提到的,Python让你能够自动化琐碎的东西,让你专注于更多令人兴奋和有用的东西。
如果你是Java开发人员,那么也可以使用Groovy来实现这一点,但Groovy并未提供Python在API、库、框架和数据科学、机器学习以及Web开发等领域的广泛应用。
2、通过什么途径学习的Python?
自学、培训机构、学校里边教授学习
3、Python和Java、PHP、C、C#、C++等其他语言的对比?
PHP
PHP即“超文本预处理器”,是一种通用开源脚本语言。PHP是在服务器端执行的脚本语言,与C语言类似,
是常用的网站编程语言。PHP独特的语法混合了C、Java、Perl以及 PHP 自创的语法。利于学习,使用广泛,主要适用于Web开发领域。
java
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,
因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,
允许程序员以优雅的思维方式进行复杂的编程 [1] 。
Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点 [2] 。
Java可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等
c
C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。
C语言能以简易的方式编译、处理低级存储器。C语言是仅产生少量的机器语言以及不需要任何运行环境支持便能运行的高效率程序设计语言。
尽管C语言提供了许多低级处理的功能,但仍然保持着跨平台的特性,
以一个标准规格写出的C语言程序可在包括类似嵌入式处理器以及超级计算机等作业平台的许多计算机平台上进行编译。
c#
C#是微软公司发布的一种面向对象的、运行于.NET Framework和.NET Core(完全开源,跨平台)之上的高级程序设计语言。并定于在微软职业开发者论坛(PDC)上登台亮相。
C#是微软公司研究员Anders Hejlsberg的最新成果。C#看起来与Java有着惊人的相似;它包括了诸如单一继承、接口、与Java几乎同样的语法和编译成中间代码再运行的过程。
但是C#与Java有着明显的不同,它借鉴了Delphi的一个特点,与COM(组件对象模型)是直接集成的,而且它是微软公司 .NET windows网络框架的主角。
C#是一种安全的、稳定的、简单的、优雅的,由C和C++衍生出来的面向对象的编程语言。
它在继承C和C++强大功能的同时去掉了一些它们的复杂特性(例如没有宏以及不允许多重继承)。
C#综合了VB简单的可视化操作和C++的高运行效率,以其强大的操作能力、优雅的语法风格、创新的语言特性和便捷的面向组件编程的支持成为.NET开发的首选语言。
C#是面向对象的编程语言。它使得程序员可以快速地编写各种基于MICROSOFT .NET平台的应用程序,MICROSOFT .NET提供了一系列的工具和服务来最大程度地开发利用计算与通讯领域。
C#使得C++程序员可以高效的开发程序,且因可调用由 C/C++ 编写的本机原生函数,而绝不损失C/C++原有的强大的功能。
因为这种继承关系,C#与C/C++具有极大的相似性,熟悉类似语言的开发者可以很快的转向C#。
c++
C++是C语言的继承,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,
还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,
还可以进行基于过程的程序设计,因而C++就适应的问题规模而论,大小由之。
C++不仅拥有计算机高效运行的实用性特征,同时还致力于提高大规模程序的编程质量与程序设计语言的问题描述能力。
4、简述解释型和编译型编程语言?
编译型语言
使用专门的编译器,针对特定的平台,将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。
特点
在编译型语言写的程序执行之前,需要一个专门的编译过程,把源代码编译成机器语言的文件,如exe格式的文件,以后要再运行时,直接使用编译结果即可,如直接运行exe文件。因为只需编译一次,以后运行时不需要编译,所以编译型语言执行效率高。
总结
一次性的编译成平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
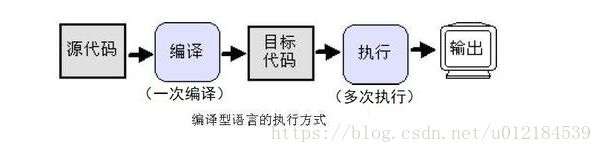
与特定平台相关,一般无法移植到其他平台;
现有的C、C++、Objective等都属于编译型语言。
解释型语言
使用专门的解释器对源程序逐行解释成特定平台的机器码并立即执行。
特点
解释型语言不需要事先编译,其直接将源代码解释成机器码并立即执行,所以只要某一平台提供了相应的解释器即可运行该程序。
总结
解释型语言每次运行都需要将源代码解释称机器码并执行,效率较低;
只要平台提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;

Python等属于解释型语言。
————————————————
版权声明:本文为CSDN博主「雷建方」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012184539/article/details/81348780
5、Python解释器种类以及特点?
CPython
由C语言开发的 使用最广的解释器,在命名行下运行python,就是启动CPython解释器.
IPython
基于cpython之上的一个交互式计时器 交互方式增强 功能和cpython一样
PyPy
目标是执行效率 采用JIT技术 对python代码进行动态编译,提高执行效率
JPython
运行在Java上的解释器 直接把python代码编译成Java字节码执行
IronPython
在微软 .NET 平台上的解释器,把python编译成. NET 的字节码
6、位和字节的关系?
一个字节 = 八位
7、b、B、KB、MB、GB 的关系?
b 比特 位
B ---字节
KB ---千比特
MB ---兆比特
GB ---吉比特
1B = 8b (8个位) 一个字节 等于 8位
1 KB = 1024B
1MB = 1024KB
1GB = 1024MB
英文和数字占一个字节
中文占一个字符,也就是两个字节
字符 不等于 字节。
字符(char)是 Java 中的一种基本数据类型,由 2 个字节组成,范围从 0 开始,到 2^16-1。
字节是一种数据量的单位,一个字节等于 8 位。所有的数据所占空间都可以用字节数来衡量。例如一个字符占 2 个字节,一个 int 占 4 个字节,一个 double 占 8 个字节 等等。
1字符=2字节;
1Byte=8bit
1k=2^10;b:位;B:字节1kb=1024 位1kB=1024 字节
8、请至少列举5个 PEP8 规范(越多越好)
Python英文文档 原文链接:link
大牛翻译 原文链接:link
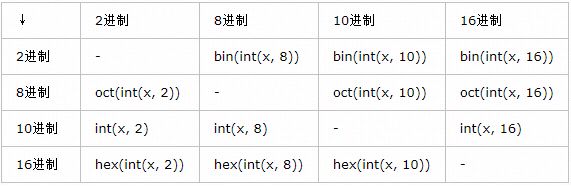
9、通过代码实现如下转换:
二进制转换成十进制: v=“0b1111011”
print(int(v,2)) #123
十进制转换成二进制: v = 18
print(bin(v)) #0b10010
八进制转换成十进制: v = ‘011’
print(int(v,8)) #9
十进制转换成八进制: v = 30
print(oct(v)) #0o36
十六进制转换成十进制: v = ‘0x12’
print(int(v,16)) #18
十进制转换成十六进制: v = 87
print(hex(v)) #0x57
10、请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
#coding:utf-8
class Switch(object):
def __init__(self, ip_str):
self.ip_str = ip_str
def ten_switch_two(self, num):
demo = list()
while num > 0:
ret = num % 2
demo.append(str(ret))
num = num // 2
temp = "".join((list(reversed(demo))))
head_zero = "0"*(8-len(temp))
ret = head_zero + temp
return ret
def two_switch_ten(self, num):
# 字符串转列表
num_list = list()
for i in num:
num_list.append(i)
temp = 0
s = len(num_list) - 1
for i in num_list:
temp += int(i) * 2 ** s
s -= 1
return temp
def run(self):
# 1.切割字符串
part_list = self.ip_str.split(".")
# 2.循环取出每个数字转成二进制数
temp_str = ""
for ip_part in part_list:
temp_str += self.ten_switch_two(int(ip_part))
ret = self.two_switch_ten(temp_str)
print(ret)
Switch("1.1.1.1").run()
11、python递归的最大层数?
Python的最大递归层数是可以设置的,默认的在window上的最大递归层数是 998。
可以通过sys.setrecursionlimit()进行设置,但是一般默认不会超过3925-3929这个范围。
12、求结果:
v1 = 1 or 3 #1
v2 = 1 and 3 #3
v3 = 0 and 2 and 1 #0
v4 = 0 and 2 or 1 #1
v5 = 0 and 2 or 1 or 4 #1
v6 = 0 or False and 1 #Fslse
13、ascii、unicode、utf-8、gbk 区别?
ASCII码使用一个字节编码,所以它的范围基本是只有英文字母、数字和一些特殊符号 ,只有256个字符。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面e799bee5baa6e79fa5e98193e58685e5aeb931333337396265(英文为 Basic Multilingual Plane,简写 BMP。它又简称为“零号平面”, plane 0)里的所有字符,要用四位十六进制数(例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五位或六位十六进制数了。旧版的Unicode标准使用相近的标记方法,但却有些微的差异:在Unicode 3.0里使用“U-”然后紧接着八位数,而“U+”则必须随后紧接着四位数。
Unicode能够表示全世界所有的字节
GBK是只用来编码汉字的,GBK全称《汉字内码扩展规范》,使用双字节编码。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
14、字节码和机器码的区别?
字节码
是一种包含执行程序、由一序列 op代码/数据对 组成的二进制文件。
是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
是编码后的数值常量、引用、指令等构成的序列。
机器码
是电脑的CPU可直接解读的数据,可以直接执行,并且是执行速度最快的代码。
转换关系
通常是有编译器将源码编译成字节码,然后虚拟机器将字节码转译为机器码
使用
通常是跨平台时使用,这样能够时代吗很好的在其他平台上运行。
15、三元运算规则以及应用场景?
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值
三元运算符的功能与’if…else’流程语句一致,它在一行中书写,代码非常精炼,执行效率更高
格式:[on_true] if [expression] else [on_false]
res = 值1 if 条件 else 值2
举例子:
a,b,c = 1,2,6
d = a if a > b else c
print(d)
16、列举 Python2和Python3的区别?
链接:点击我知道答案
17、用一行代码实现数值交换:
a = 1
b = 2
a,b = b,a
print(a, b)
18、Python3和Python2中 int 和 long的区别?
int(符号整数):通常被称为是整数或整数,没有小数点的正或负整数;
long(长整数):无限大小的整数,这样写整数和一个大写或小写的L。
python2中有long类型
python3中没有long类型,只有int类型
19、xrange和range的区别?
两种用法介绍如下:
1.range([start], stop[, step])
返回等差数列。构建等差数列,起点是start,终点是stop,但不包含stop,公差是step。
start和step是可选项,没给出start时,从0开始;没给出step时,默认公差为1。
例如:
>>> range(10) #起点是0,终点是10,但是不包括10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1,10) #起点是1,终点是10,但是不包括10
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1,10,2) #起点是1,终点是10,步长为2
[1, 3, 5, 7, 9]
>>> range(0,-10,-1) #起点是1,终点是10,步长为-1
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0,-10,1) #起点是0,终点是-10,终点为负数时,步长只能为负数,否则返回空
[]
>>> range(0) #起点是0,返回空列表
[]
>>> range(1,0) #起点大于终点,返回空列表
[]
2.xrange([start], stop[, step])
xrange与range类似,只是返回的是一个"xrange object"对象,而非数组list。
要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。
例如:
>>> lst = xrange(1,10)
>>> lst
xrange(1, 10)
>>> type(lst)
<type 'xrange'>
>>> list(lst)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
区别如下:
1.range和xrange都是在循环中使用,输出结果一样。
2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。
3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。
补充点:
#以下三种形式的range,输出结果相同。
>>> lst = range(10)
>>> lst2 = list(range(10))
>>> lst3 = [x for x in range(10)]
>>> lst
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst2
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst3
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst == lst2 and lst2 == lst3
True
在使用Python3时,发现以前经常用的xrange没有了,python3的range就是xrange
注意:Python 3.x已经去掉xrange,全部用range代替。
20、文件操作时:xreadlines和readlines的区别?
python3已经没有这个xreadlines的方法了
这俩的区别类似于xrange和range,在使用的时候感觉不出来区别,但是二者返回值类型不一样,带有x的返回值是生成器,不带的返回值是列表
21、列举布尔值为False的常见值?
# 列举布尔值是False的所有值
print("1. ", bool(0))
print("2. ", bool(-0))
print("3. ", bool(None))
print("4. ", bool())
print("5. ", bool(False))
print("6. ", bool([]))
print("7. ", bool(()))
print("8. ", bool({}))
print("9. ", bool(0j))
print("10. ", bool(0.0))
22、字符串、列表、元组、字典每个常用的5个方法?
大神链接link
23、lambda表达式格式以及应用场景?
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
add = lambda x, y : x+y
print(add(1,2)) # 结果为3
应用在函数式编程中 应用在闭包中。
24、pass的作用?
空语句 do nothing
保证格式完整
保证语义完整
25、*arg和**kwarg作用
定义简单的函数
首先我们可以定一个简单的函数, 函数内部只考虑required_arg这一个形参(位置参数)
def exmaple(required_arg):
print required_arg
exmaple("Hello, World!")
>> Hello, World!
那么,如果我们调用函数式传入了不止一个位置参数会出现什么情况?当然是会报错!
exmaple("Hello, World!", "another string")
>> TypeError: exmaple() takes exactly 1 argument (2 given)
定义函数时,使用*arg和kwarg
*arg和kwarg 可以帮助我们处理上面这种情况,允许我们在调用函数的时候传入多个实参
def exmaple2(required_arg, *arg, **kwarg):
if arg:
print "arg: ", arg
if kwarg:
print "kwarg: ", kwarg
exmaple2("Hi", 1, 2, 3, keyword1 = "bar", keyword2 = "foo")
>> arg: (1, 2, 3)
>> kwarg: {'keyword2': 'foo', 'keyword1': 'bar'}
从上面的例子可以看到,当我传入了更多实参的时候
*arg会把多出来的位置参数转化为tuple
**kwarg会把关键字参数转化为dict
再举个例子,一个不设定参数个数的加法函数
def sum(*arg):
res = 0
for e in arg:
res += e
return res
print sum(1, 2, 3, 4)
print sum(1, 1)
>> 10
>> 2
当然,如果想控制关键字参数,可以单独使用一个*,作为特殊分隔符号。限于Python 3,下面例子中限定了只能有两个关键字参数,而且参数名为keyword1和keyword2
def person(required_arg, *, keyword1, keyword2):
print(required_arg, keyword1, keyword2)
person("Hi", keyword1="bar", keyword2="foo")
>> Hi bar foo
如果不传入参数名keyword1和keyword2会报错,因为都会看做位置参数!
person("Hi", "bar", "foo")
>> TypeError: person() takes 1 positional argument but 3 were given
调用函数时使用*arg和**kwarg
直接上例子,跟上面的情况十分类似。反向思维。
def sum(a, b, c):
return a + b + c
a = [1, 2, 3]
# the * unpack list a
print sum(*a)
>> 6
def sum(a, b, c):
return a + b + c
a = {'a': 1, 'b': 2, 'c': 3}
# the ** unpack dict a
print sum(**a)
>> 6
作者:Jason_Yuan
链接:https://www.jianshu.com/p/e0d4705e8293
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
26、is和==的区别
在python中万物即对象,所以is比较的是id值相同不相同,而==仅比较值。
对于值大小在-5~256之间的变量,python因为有内存池缓存机制,会对该值分配内存,而不是变量,所以只要是该值的变量都指向同一个内存,即id相同。
但是,==仅比较值大小
27、简述Python的深浅拷贝以及应用场景?
深浅拷贝用法来自copy模块。
导入模块:import copy
浅拷贝:copy.copy
深拷贝:copy.deepcopy
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等.
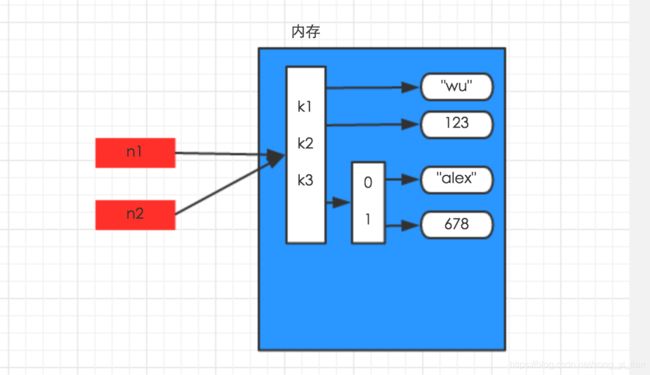
字典(列表)的深浅拷贝
赋值:
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n2 = n1
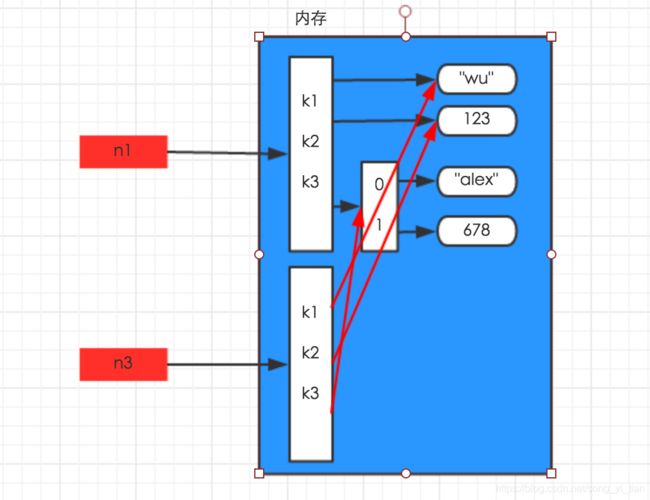
浅拷贝:
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n3 = copy.copy(n1)
深拷贝:
import copy
n1 = {‘k1’:‘wu’,‘k2’:123,‘k3’:[‘alex’,678]}
n4 = copy.deepcopy(n1)
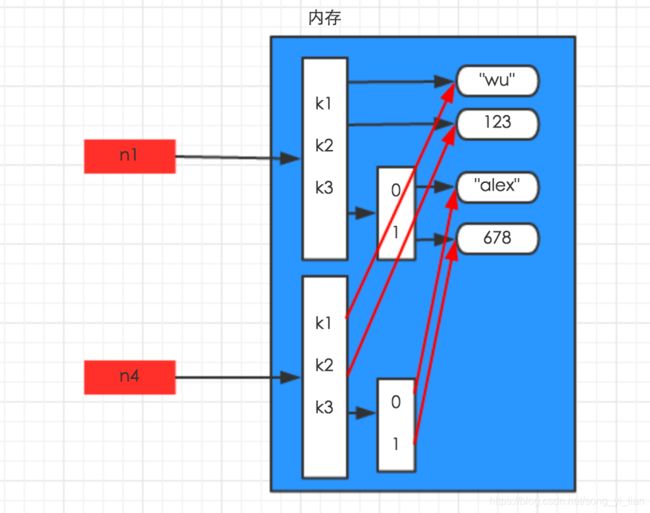
深拷贝的时候python将字典的所有数据在内存中新建了一份,所以如果你修改新的模版的时候老模版不会变。相反,在浅copy 的时候,python仅仅将最外层的内容在内存中新建了一份出来,字典第二层的列表并没有在内存中新建,所以你修改了新模版,默认模版也被修改了。
注释:搬运于 博客园 tank_jam
28、Python垃圾回收机制?
外部链接link
29、Python的可变类型和不可变类型?
可变类型 Vs 不可变类型
可变类型(mutable):列表,字典
不可变类型(unmutable):数字,字符串,元组
这里的可变不可变,是指内存中的那块内容(value)是否可以被改变
30、求结果:
v = dict.fromkeys([‘k1’,‘k2’],[])
v[‘k1’].append(666)
print(v)
v[‘k1’] = 777
print(v)
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
#运行结果
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
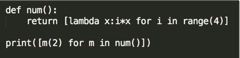
31、求结果:
[6, 6, 6, 6]
#代码示意:
[lambda x:x*i,lambda x:x*i,lambda x:x*i,lambda x:x*i]
def num():
lst = []
for i in range(4):
def foo(x):
return x*i
lst.append(foo)
return lst
# lst.append(lambda x:x*i)
g=num()
print(g) # [4个内存地址]
lst1=[]
for m in g:
lst1.append(m(2))
print(lst1)
lambda嵌套
在外层嵌套被调用的时候,嵌套在内的lambda能够获取到在外层函数作用域中变量名x的值。
注:
lambda是一个表达式,而不是语句。所以lambda能够出现在Python语法不允许def出现的地方。
lambda的主体是一个单独的表达式,而不是一个代码块。
lambda是一个表达式,而不是语句
32、列举常见的内置函数?
链接点一点 你就知道
33、filter、map、reduce的作用?
1. map
(1)map(function, iterable,……) ,第一个参数是一个函数,第二个参数是一个可迭代的对象,第一个参数function以参数序列中的每一个元素调用function函数,返回包含每次function函数返回值的一个迭代器。

运行结果如下:

在Python2中返回的是一个列表,但在Python3中返回的是一个迭代器。上述程序是在Python3中执行的。
其实上述程序还可以这样写

或者
*
(2)map中有多个可迭代对象

返回结果

2. filter
filter(function, iterable) filter函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
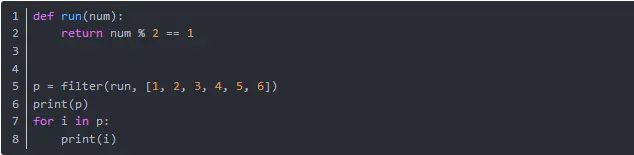
运行结果是

下面是用lambda函数写的

当把lambda表达式的返回结果改为零时

运行结果如下

3. reduce
在Python3中没有reduce内置函数,但在functools中有reduce类,reduce调用的格式:reduce(function, iterable),reduce的作用是将传给function(有两个参数 )对集合中的第1、2个元素进行操作,得到的结果再与第三个元素用function函数进行运算……
下面看一个程序

运行结果如下
![]()
作者:空口言_1d2e
链接:https://www.jianshu.com/p/5ef9dd70c3ab
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
34、一行代码实现9*9乘法表
print ('\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)]) for x in range(1,10)]))
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
35、如何安装第三方模块?以及用过哪些第三方模块?
通过pip安装第三方包很简单,比如我要安装pandas这个第三方模块,我从PyPI查询到这个模块后,官网页面上就提供了安装语句:
pip install pandas
但是,但是国内的网络环境你也知道,总是有那种或者这种的问题,导致在线安装速度很慢;所以呢,国内就有很多PyPI这个源的镜像,有名的就有清华大学的、豆瓣网的;我们可以设置通过这些国内的镜像来在线安装第三方模块。比如我要从清华大学提供的镜像源来安装pandas:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
当然了,每次输入这么一长串地址很麻烦,所以我们也可以把清华大学的镜像源设置为默认的安装源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
这样后续的安装就都会默认从清华大学镜像源去下载第三方模块。以下是国内比较好用的一些镜像源:
豆瓣:https://pypi.douban.com/simple/
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
36、至少列举8个常用模块都有哪些?
os模块,路径
re模块,正则表达式
sys模块,标准输入输出
math模块,数学公式
json模块,字符串与其他数据类型转换;pickle模块,序列化
random模块,生成随机数
time模块,时间模块
request模型,HTTP请求库
pyqt、pymql、pygame、Django、Flask、opencv-python、pillow-python、Scrappy……
37、re的match和search区别?
1、match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配;
2、也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
例如:
import re
print(re.match('super', 'superstition').span()) # (0,5)
print(re.match('super', 'insuperable')) # None
3、search()会扫描整个字符串并返回第一个成功的匹配:
例如:
import re
print(re.search('super', 'superstition').span()) #(0,5)
print(re.search('super', 'insuperable')) # <_sre.SRE_Match object; span=(2, 7), match='super'>
4、其中span函数定义如下,返回位置信息:
span([group]):
返回(start(group), end(group))。
数据类型是:
38、什么是正则的贪婪匹配?
1.哒哒哒哒哒哒多多多 正则表达式的贪婪与非贪婪匹配
如:String str=“abcaxc”;
Patter p=“ab*c”;
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c)。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab*c)。
2.编程中如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
量词:{m,n}:m到n个
*:任意多个
+:一个到多个
?:0或一个
. :除\n之外的任意字符
39、求结果:a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) ) (Python中列表生成式和生成器的区别)
[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
at 0x0000016CD8EFE8E0>
列表生成式语法:
[xx for x in range(0,10)] //列表生成式,这里是中括号
//结果复 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
(xx for x in range(0,10)) //生成器, 这里是小括号
//结果
二者的区别很明显:
一个直接返回了表达式的结果列表, 而另一个是一个对象,该对象包含了对表达式结果的计算引用, 通过循环可以直接输出
g = (x*x for x in range(0,10))
for n in g:
print n
结果
0
1
4
9
16
25
36
49
64
81
当表达式的结果数量较少的时候, 使用列表生成式制还好, 一旦数量级过大, 那么列表生成式就会占用很大的内存,
而生成器并不是立即把结果写入内存, 而是保存的一种计算方式, 通过不断的获取, 可以获取到相应的位置的值,所以占用的内存仅仅是zd对计算对象的保存
40、求结果:a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
1
2
False
True
实际上这涉及到了Python的 链式对比(ChainedComparisons)。在其他语言中,有一个变量 x,如果要判断x是否大于1,小于5,可能需要这样写代码:
if (x > 1 and x < 5)
但是在Python中,可以这样写代码:
if 1 < x < 5
Python能够正确处理这个链式对比的逻辑。回到最开始的问题上, 等于符号和 <小于符号,本质没有什么区别。所以实际上 22>1也是一个链式对比的式子,它相当于 2==2and2>1。此时,这个式子就等价于 TrueandTrue。所以返回的结果为True。
注:True相当于1,False相当于0
41、def func(a,b=[]) 这种写法有什么坑?
def func(a,b = []):
b.append(1)
print(a,b)
func(a=2)
func(2)
func(2)
'''
2 [1]
2 [1, 1]
2 [1, 1, 1]
函数的默认参数是一个list 当第一次执行的时候实例化了一个list
第二次执行还是用第一次执行的时候实例化的地址存储
所以三次执行的结果就是 [1, 1, 1] 想每次执行只输出[1] ,默认参数应该设置为None
'''
42、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
a = '1,2,3'
a1 = a.split(',')
list = []
for n in a1:
list.append(n)
print(list)
43、如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
a = ['1','2','3']
list = []
for i in a:
list.append(int(i))
print(list)
44、比较:a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
a = [1,2,3]
b = [(1),(2),(3) ]
c = [(1,),(2,),(3,) ]
print(f'他们分别都是列表:{a},{b},{c}')
print(f'他们的类型都是:{type(a)},{type(b)},{type(c)}')
print(f'其中元素类型为:{[type(x) for x in a]},{[type(x) for x in b]},{[type(x) for x in c]}')
他们分别都是列表:[1, 2, 3],[1, 2, 3],[(1,), (2,), (3,)]
他们的类型都是:<class 'list'>,<class 'list'>,<class 'list'>
其中元素类型为:[<class 'int'>, <class 'int'>, <class 'int'>],[<class 'int'>, <class 'int'>, <class 'int'>],[<class 'tuple'>, <class 'tuple'>, <class 'tuple'>]
45、如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
print([i*i for i in range(1,11)])
46、一行代码实现删除列表中重复的值 ?
print(set([1, 4, 9, 16, 25, 36, 49, 64, 81, 100,100]))
47、如何在函数中设置一个全局变量 ?
python中的global语句是被用来声明全局变量的。
a = 10
def function():
global a
a += 1
return a
function()
print(x)
#注解:如果注释掉global 代码
#会报错:UnboundLocalError: local variable 'a' referenced before assignment
48、logging模块的作用?以及应用场景?
logging
模块定义的函数和类为应用程序和库的开发实现了一个灵活的事件日志系统
作用:可以了解程序运行情况,是否正常
在程序的出现故障快速定位出错地方及故障分析
49、请用代码简答实现stack 。
Stack() 创建一个新的空栈
push(item) 添加一个新的元素item到栈顶
pop() 弹出栈顶元素
peek() 返回栈顶元素
is_empty() 判断栈是否为空
size() 返回栈的元素个数
实现一个栈stack,后进先出
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
# 判断是否为空
return self.items == []
def push(self,item):
# 加入元素
self.items.append(item)
def pop(self):
# 弹出元素
return self.items.pop()
def peek(self):
# 返回栈顶元素
return self.items[len(self.items)-1]
def size(self):
# 返回栈的大小
return len(self.items)
if __name__ == "__main__":
stack = Stack()
stack.push("H")
stack.push("E")
stack.push("L")
print(stack.size()) # 3
print(stack.peek()) # L
print(stack.pop()) # L
print(stack.pop()) # E
print(stack.pop()) # H
50、常用字符串格式化哪几种?
1.占位符%
%d 表示那个位置是整数;%f 表示浮点数;%s 表示字符串。
print('Hello,%s' % 'Python')
print('Hello,%d%s%.2f' % (666, 'Python', 9.99)) # 打印:Hello,666Python10.00
2.format
print('{k} is {v}'.format(k='python', v='easy')) # 通过关键字
print('{0} is {1}'.format('python', 'easy')) # 通过关键字
51、简述 生成器、迭代器、可迭代对象 以及应用场景?
可以参考
简书链接参考:点击进入
CSMN 生成器和迭代器区别:点击进入
52、用Python实现一个二分查找的函数。
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
if len(dataset) > 1:
mid = int(len(dataset) / 2)
if dataset[mid] == find_num: # find it
print("找到数字", dataset[mid])
elif dataset[mid] > find_num: # 找的数在mid左面
print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else: # 找的数在mid右面
print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])
return binary_search(dataset[mid + 1:], find_num)
else:
if dataset[0] == find_num: # find it
print("找到数字啦", dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
binary_search(data,20)
53、谈谈你对闭包的理解?
如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
闭包:
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
# 闭包函数的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer(a):
b = 10
# inner是内函数
def inner():
# 在内函数中 用到了外函数的临时变量
print(a + b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
# 在这里我们调用外函数传入参数5
# 此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo
# 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数
demo = outer(5)
# 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量
# demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数
demo() # 15
demo2 = outer(7)
demo2() # 17
闭包有啥用??!!
3.1装饰器!!!装饰器是做什么的??其中一个应用就是,我们工作中写了一个登录功能,我们想统计这个功能执行花了多长时间,我们可以用装饰器装饰这个登录模块,装饰器帮我们完成登录函数执行之前和之后取时间。
3.2面向对象!!!经历了上面的分析,我们发现外函数的临时变量送给了内函数。大家回想一下类对象的情况,对象有好多类似的属性和方法,所以我们创建类,用类创建出来的对象都具有相同的属性方法。闭包也是实现面向对象的方法之一。在python当中虽然我们不这样用,在其他编程语言入比如avaScript中,经常用闭包来实现面向对象编程
3.3实现单例模式!! 其实这也是装饰器的应用。单例模式毕竟比较高大,需要有一定项目经验才能理解单例模式到底是干啥用的,我们就不探讨了。
————————————————[搬运于]
原文链接:https://blog.csdn.net/sinolover/article/details/104254502
54、os和sys模块的作用?
os与sys模块的官方解释如下:
os:这个模块提供了一种方便的使用操作系统函数的方法。
sys:这个模块可供访问由解释器使用或维护的变量和与解释器进行交互的函数。
总结:os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
os 常用方法:
os.remove(‘path/filename’) 删除文件
os.rename(oldname, newname) 重命名文件
os.walk() 生成目录树下的所有文件名
os.chdir(‘dirname’) 改变目录
os.mkdir/makedirs(‘dirname’)创建目录/多层目录
os.rmdir/removedirs(‘dirname’) 删除目录/多层目录
os.listdir(‘dirname’) 列出指定目录的文件
os.getcwd() 取得当前工作目录
os.chmod() 改变目录权限
os.path.basename(‘path/filename’) 去掉目录路径,返回文件名
os.path.dirname(‘path/filename’) 去掉文件名,返回目录路径
os.path.join(path1[,path2[,…]]) 将分离的各部分组合成一个路径名
os.path.split(‘path’) 返回( dirname(), basename())元组
os.path.splitext() 返回 (filename, extension) 元组
os.path.getatime\ctime\mtime 分别返回最近访问、创建、修改时间
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否为绝对路径
os.path.isdir() 是否为目录
os.path.isfile() 是否为文件
sys 常用方法:
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.modules.keys() 返回所有已经导入的模块列表
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout 标准输出
sys.stdin 标准输入
sys.stderr 错误输出
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置
sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’
sys.copyright 记录python版权相关的东西
sys.api_version 解释器的C的API版本
55、如何生成一个随机数?
# 导入 random(随机数) 模块
import random
print(random.randint(0, 9))
56、如何使用python删除一个文件?
os.remove(path)
删除文件 path. 如果path是一个目录, 抛出 OSError错误。如果要删除目录,请使用rmdir().
57、谈谈你对面向对象的理解?
面向过程:的程序设计的核心是过程(流水线式思维),过程即解决问题的步骤,面向过程的设计就好比精心设计好一条流水线,考虑周全什么时候处理什么东西。
优点是:极大的降低了写程序的复杂度,只需要顺着要执行的步骤,堆叠代码即可。
缺点是:一套流水线或者流程就是用来解决一个问题,代码牵一发而动全身。
应用场景:一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server等。
面向对象:的程序设计的
优点是:解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点:可控性差,无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法预测最终结果。于是我们经常看到一个游戏人某一参数的修改极有可能导致阴霸的技能出现,一刀砍死3个人,这个游戏就失去平衡。
应用场景:需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方。
58、Python面向对象中的继承有什么特点?
减少代码和灵活制定新类
子类具有父类的属性和方法
子类不能继承父类的私有属性/方法
子类可以添加新的方法
子类可以修改父类的方法
59、面向对象深度优先和广度优先是什么?
Python的类可以继承多个类,Python的类如果继承了多个类,那么其寻找方法的方式有两种:
1、当类是经典类时,多继承情况下,会按照深度优先方式查找 ;
2、当类是新式类时,多继承情况下,会按照广度优先方式查找 。
简单点说就是:经典类是纵向查找(深度优先),新式类是横向查找(广度优先)
经典类和新式类的区别就是,在声明类的时候,新式类需要加上object关键字。
在python3中默认全是新式类
60、面向对象中super的作用?
什么是super?
super() 函数是用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
语法
以下是 super() 方法的语法:
super(type[, object-or-type])
参数
·type -- 类。
·object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
Python3.x 实例:
class A:
pass
class B(A):
def add(self, x):
super().add(x)
Python2.x 实例:
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)
具体应用示例:
举个例子
class Foo:
def bar(self, message):
print(message)
>>> Foo().bar("Hello, Python.")
Hello, Python.
当存在继承关系的时候,有时候需要在子类中调用父类的方法,此时最简单的方法是把对象调用转换成类调用,需要注意的是这时self参数需要显式传递,例如:
class FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
FooParent.bar(self, message)
>>> FooChild().bar("Hello, Python.")
Hello, Python.
这样做有一些缺点,比如说如果修改了父类名称,那么在子类中会涉及多处修改,另外,Python是允许多继承的语言,如上所示的方法在多继承时就需要重复写多次,显得累赘。为了解决这些问题,Python引入了super()机制,例子代码如下:
class FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
super(FooChild, self).bar(message)
>>> FooChild().bar("Hello, Python.")
Hello, Python
表面上看 super(FooChild, self).bar(message)方法和FooParent.bar(self, message)方法的结果是一致的,实际上这两种方法的内部处理机制大大不同,当涉及多继承情况时,就会表现出明显的差异来,直接给例子:
代码一:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
A.__init__(self)
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
A.__init__(self)
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
A.__init__(self)
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
B.__init__(self)
C.__init__(self)
D.__init__(self)
print("Leave E")
E()
结果为:
Enter E
Enter B
Enter A
Leave A
Leave B
Enter C
Enter A
Leave A
Leave C
Enter D
Enter A
Leave A
Leave D
Leave E
执行顺序很好理解,唯一需要注意的是公共父类A被执行了多次。
代码二:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
super(B, self).__init__()
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
super(C, self).__init__()
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
super(D, self).__init__()
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
super(E, self).__init__()
print("Leave E")
E()
结果:
Enter E
Enter B
Enter C
Enter D
Enter A
Leave A
Leave D
Leave C
Leave B
Leave E
在super机制里可以保证公共父类仅被执行一次,至于执行的顺序,是按照MRO(Method Resolution Order):方法解析顺序 进行的。
转载于:https://www.cnblogs.com/zhuifeng-mayi/p/9221562.html
MRO 参考链接:点击进入
61、是否使用过functools中的函数?其作用是什么?
参考链接:点击进入
1、偏函数:from functools import partial
用于其他进制的字符串与十进制数据之间的转换
import functools
def transform(params):
foo = functools.partial(int,base=2)
print(foo(params))
transform('1000000') # 64
transform('100000') # 32
2、用于修复装饰器
import functools
def deco(func):
@functools.wraps(func) # 加在最内层函数正上方
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
@deco
def index():
'''哈哈哈哈'''
x = 10
print('from index')
print(index.__name__)
print(index.__doc__)
# 加@functools.wraps
# index
# 哈哈哈哈
# 不加@functools.wraps
# wrapper
# None
即:用来保证被装饰函数在使用装饰器时不改变自身的函数名和应有的属性,
避免被别人发现该函数是被装饰器装饰过的。
__doc__为文档字符串,文档字符串写在Python文件的第一行,三个引号包含起来的字符串。
为什么要写文档字符串?
因为规范的书写文档字符串可以通过sphinx等工具自动生成文档。
文档字符串的风格有很多。
Plain
Epytext
reStucturedText
Numpy
Google
我们可以在pycharm上进行自定义设置默认的文档字符串风格。暂时推荐reStructuredText吧,紧凑,sphinx御用
62、列举面向对象中带双下划线的特殊方法,如:new、init
new 在实例化对象时触发,即控制着对象的创建
init 在对象创建成功后触发,完成对象属性的初始化
call 在调用对象时触发,也就是对象()时触发
setattr 在给对象赋值时触发,对象的属性若不存在则先创建
getattr 在对象.属性时触发,该属性必须不存在
mro 打印当前类的继承顺序
dict 打印出当前操作对象名称空间的属性和值
str 在打印对象时,触发,执行内部的代码
doc 类的文档字符串
63、如何判断是函数还是方法?
二者都是解决问题的实现功能
函数:通过函数名直接调用
方法:通过附属者的点语法去调用
变量:通过变量名访问变量值
属性:通过附属者.语法去调用
64、静态方法和类方法区别?
@classmethod
类方法:可以被类与对象调用的方法,第一个参数一定是当前类本身,对象调用的时候,本质上还是通过类去调用该方法的,可以通过id去证明。id(cls)
实例方法就是普通的方法,只是参数列表里的参数不会出现self和cls
@staticmethod
静态方法:直接通过类|实例.静态方法调用。被该方法修饰的函数,不需要self参数和cls参数,使用的方法和直接调用函数一样
逻辑上来说,实例方法类本身和其对象都可以调用,
类方法是专属于类的
静方法可以被类和对象调用,
类方法、静态方法 在被类直接调用时,没有经过实例化的过程,因此可以减少内存资源的占用。
65、列举面向对象中的特殊成员以及应用场景
参考链接:点解进入
66、1、2、3、4、5 能组成多少个互不相同且无重复的三位数
#for循环遍历
list = []
for i in range(1,6):
for j in range(1,6):
for k in range(1,6):
if i != j and i != k and j != k:
li = [i ,j ,k]
list.append(li)
print(len(list)) #60
67、什么是反射?以及应用场景?
python的反射,它的核心本质其实就是利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
如何利用字符串驱动不同的事件,比如导入模块、调用函数等等,这些都是python的反射机制,是一种编程方法、设计模式的体现,凝聚了高内聚、松耦合的编程思想,不能简单的用执行字符串来代替。详细链接:点击进入
68、metaclass作用?以及应用场景?
metaclass用来指定类是由谁创建的。
类的metaclass 默认是type。我们也可以指定类的metaclass值。在python3中
class MyType(type):
def __call__(self, *args, **kwargs):
return 'MyType'
class Foo(object, metaclass=MyType):
def __init__(self):
return 'init'
def __new__(cls, *args, **kwargs):
return cls.__init__(cls)
def __call__(self, *args, **kwargs):
return 'call'
obj = Foo()
print(obj) # MyType
69、用尽量多的方法实现单例模式。
单例概念:单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。
从具体实现角度来说,就是以下三点:一是单例模式的类只提供私有的构造函数,二是类定义中含有一个该类的静态私有对象,三是该类提供了一个静态的共有函数用于创建或获取它本身的静态私有对象。
讲解详情:点击进入
70、装饰器的写法以及应用场景。
#装饰器的写法:
def wrapper(func):
def inner(*args,**kwargs):
'被装饰之前的操作'
ret = func(*args,**kwargs)
'被装饰之后的操作'
return ret
return inner
装饰器的应用场景
1,引入日志
2,函数执行时间统计
3,执行函数前预备处理
4,执行函数后清理功能
5,权限校验等场景
6,缓存
7,事务处理
PS: Django在1.7版本之后,官方建议,中间件的写法也采用装饰器的写法
详见:点击进入
71、异常处理写法以及如何主动抛出异常(应用场景)
异常处理的常规写法:
try:
执行的主体函数
except Exception as e:
print(str(e))
主动抛出异常:
raise TypeError('出现了不可思议的异常')#TypeError可以是任意的错误类型
72、什么是面向对象的MRO
Python是支持面向对象编程的,同时也是支持多重继承的。
而支持多重继承,正是Python的方法解析顺序(Method Resoluthion Order, 或MRO)问题出现的原因所在。
MRO 参考链接:点击进入
73、isinstance作用以及应用场景?
isinstance作用:来判断一个对象是否是一个已知的类型;
其第一个参数(object)为对象,第二个参数为类型名(int…)或类型名的一个列表((int,list,float)是一个列表)。其返回值为布尔型(True or flase)。
若对象的类型与参数二的类型相同则返回True。若参数二为一个元组,则若对象类型与元组中类型名之一相同即返回True。
简单来说就是判断object是否与第二个参数的类型相同,举例如下:
# -*- coding: utf-8 -*-
p = '123'
print "1.",isinstance(p,str)#判断P是否是字符串类型
a = "中国"
print isinstance(a,unicode) #判断a是否是Unicode编码
print isinstance(a,(unicode,str))#判断a所属类型是否包含在元组中
list1 = [1,2,3,4,5]
print isinstance(list1,list)#判断list1是否是列表的类型
74、写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input wouldhave exactly one solution, and you may not use the same element twice.(给定一个整数数组,返回两个数字的索引,使它们加起来等于一个特定的目标。您可以假设每个输入都会只有一个解决方案,并且不能两次使用相同的元素。)
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1]
#方法一
nums = [2, 7, 11, 15]
target = 9
def twosum(array,target):
newarray=list(enumerate(array))
newarray.sort(key=lambda x:x[1])
i=0
j=len(newarray)-1
while i<j:
sumtwo=newarray[i][1]+newarray[j][1]
if sumtwo>target:
j-=1
elif sumtwo<target:
i+=1
elif sumtwo==target:
index1,index2=newarray[i][0]+1,newarray[j][0]+1
print('index=%d, index2=%d'%(index1,index2))
return index1,index2
twosum(nums,target)
#方法二
nums = [2, 7, 11, 15]
target = 9
def twosum(array,target):
for j in range(len(nums)):
num1 = nums[j]
for k in range(len(nums)):
num2 = nums[k]
if num1 + num2 == target and j != k:
print("两个数的下标是{},{}".format(j,k))
twosum(nums,target)
75、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
JSON(JavaScript Object Notation)是用于Web上数据交换的最广泛使用的数据格式。JSON是一种基于轻量级文本的数据交换格式,它完全独立于语言。它基于JavaScript编程语言的一个子集,易于理解和生成。
JSON主要支持6种数据类型:
● 字符串(String)
● Number
● Boolean
● null/empty
● 对象(Object)
● 数组(Array)
注意: string,number,boolean,null是简单数据类型或基元数据类型,而对象和数组则称为复杂数据类型。
字符串(String):JSON字符串必须用双引号编写,如C语言,JSON中有各种特殊字符(转义字符),您可以在字符串中使用,如\(反斜杠),/(正斜杠),b(退格),n (新行),r(回车),t(水平制表符)等。
示例:
{ "name":"Vivek" }
{ "city":"Delhi\/India" }
here / is used for Escape Character / (forward slash).
Number:以10为基数表示,不使用八进制和十六进制格式。
示例:
{ "age": 20 }
{ "percentage": 82.44}
Boolean:此数据类型可以是true或false。
示例:
{ "result" : true }
Null:这只是一个空值。
示例:
{
"result" : true,
"grade" :, //empty
"rollno" : 210
}
Object:它是在{}(花括号)之间插入的一组名称或值对。键必须是字符串,并且应该是唯一的,并且多个键和值对由(逗号)分隔。
语法:
{ key : value, .......}
示例:
{
"People":{ "name":"Peter", "age":20, "score": 50.05}
}
Array:它是一个有序的值集合,以[(左括号)和以…结尾(右括号)开头。数组的值用(逗号)分隔。
语法:
[ value, …]
示例:
{
"people":[ "Sahil", "Vivek", "Rahul" ]
}
{
"collection" : [
{"id" : 101},
{"id" : 102},
{"id" : 103}
]
}
JSON文档的示例:
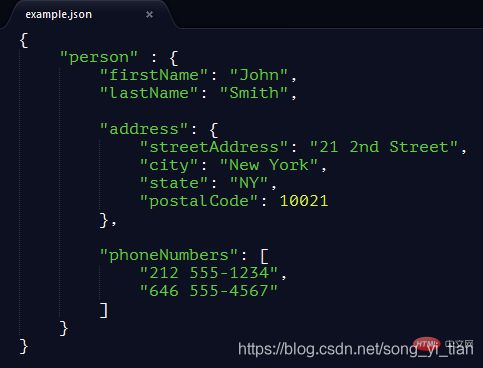
参考链接:搬运工
定制支持datetime类型
import json
from json import JSONEncoder
from datetime import datetime
class ComplexEncoder(JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
else:
return super(ComplexEncoder,self).default(obj)
d = {"hello":"你好",'name':'alex','data':datetime.now()}
print(json.dumps(d,cls=ComplexEncoder,ensure_ascii=False))
# {"hello": "你好", "name": "alex", "data": "2020-05-05 23:40:53"}
注解:strftime()函数的使用方法
trftime()函数可以把YYYY-MM-DD HH:MM:SS格式的日期字符串转换成其它形式的字符串。
strftime()的语法是strftime(格式, 日期/时间, 修正符, 修正符, …)
它可以用以下的符号对日期和时间进行格式化:
%d 日期, 01-31
%f 小数形式的秒,SS.SSS
%H 小时, 00-23
%j 算出某一天是该年的第几天,001-366
%m 月份,00-12
%M 分钟, 00-59
%s 从1970年1月1日到现在的秒数
%S 秒, 00-59
%w 星期, 0-6 (0是星期天)
%W 算出某一天属于该年的第几周, 01-53
%Y 年, YYYY
%% 百分号
strftime()的用法举例如下:
from datetime import datetime
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
76、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
在序列化时,中文汉字总是被转换为unicode码,在dumps函数中添加参数ensure_ascii=False即可解决。
77、什么是断言(assert)?应用场景?
Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。
断言应该用于:
☆防御型的编程
☆运行时检查程序逻辑
☆检查约定
☆程序常量
☆检查文档
大神链接:点击解惑
78、有用过with statement吗?它的好处是什么?
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
用法举例如下:
with open('output.txt', 'w') as f:
f.write('Hi there!')
当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。原文链接
79、使用代码实现查看列举目录下的所有文件。
思路分析:遍历一个文件夹,肯定是需要用到os模块了,os.listdir()方法可以列举某个文件夹内的所有文件和文件夹,os.path.isdir函数用于判断是否为文件夹。由于文件夹内肯定有多层次结构,那么应该要定义一个函数,然后使用递归的方式来实现枚举所有文件列表了。
import os
def dirpath(lpath, lfilelist):
list = os.listdir(lpath)
for f in list:
file = os.path.join(lpath, f) #拼接完整的路径
if os.path.isdir(file): #判断如果为文件夹则进行递归遍历
dirpath(file, lfilelist)
else:
lfilelist.append(file)
return lfilelist
lfilelist = dirpath(os.getcwd(), [])
for f in lfilelist:
print(f)
os.getcwd()是用于获取当前脚本所在的文件夹
80、简述 yield和yield from关键字。
1、可迭代对象与迭代器的区别
可迭代对象:指的是具备可迭代的能力,即enumerable. 在Python中指的是可以通过for-in 语句去逐个访问元素的一些对象,比如元组tuple,列表list,字符串string,文件对象file 等。
迭代器:指的是通过另一种方式去一个一个访问可迭代对象中的元素,即enumerator。在python中指的是给内置函数iter()传递一个可迭代对象作为参数,返回的那个对象就是迭代器,然后通过迭代器的next()方法逐个去访问。
#迭代器案例分析
list = [1,2,3,4,5]
li = iter(list)
print(next(li))
print(next(li))
print(next(li))
# 1
# 2
# 3
2、生成器
生成器的本质就是一个逐个返回元素的函数,即“本质——函数”
生成器有什么好处?
最大的好处在于它是“延迟加载”,即对于处理长序列问题,更加的节省存储空间。即生成器每次在内存中只存储一个值,比如打印一个斐波拉切数列:原始的方法可以如下所示:
def fab(max):
n, a, b = 0, 0, 1
L = []
while n < max:
L.append(b)
a, b = b, a + b
n = n + 1
return L
这样做最大的问题在于将所有的元素都存储在了L里面,很占用内存,而使用生成器则如下所示
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b #每次迭代时值加载这一个元素,而且替换掉之前的那一个元素,这样就大大节省了内存。而且程序在遇见yield语句时会停下来,这是后面使用yield阻断原理进行多线程编程的一个启发
a, b = b, a + b
n = n + 1
生成器其实就是下面这个样子,写得简单一些就是一次返回一条,如下:
def generator():
for i in range(5):
yield i
def generator_1():
yield 1
yield 2
yield 3
yield 4
yield 5
上面这两种方式是完全等价的,只不过前者更简单一些。
3、什么又是yield from呢?
简单地说,yield from generator 。实际上就是返回另外一个生成器。如下所示:
def generator1():
item = range(10)
for i in item:
yield i
def generator2():
yield 'a'
yield 'b'
yield 'c'
yield from generator1() #yield from iterable本质上等于 for item in iterable: yield item的缩写版
yield from [11,22,33,44]
yield from (12,23,34)
yield from range(3)
for i in generator2() :
print(i)
从上面的代码可以看出,yield from 后面可以跟的式子有“ 生成器 元组 列表等可迭代对象以及range()函数产生的序列”
上面代码运行的结果为:
a
b
c
0
1
2
3
4
5
6
7
8
9
11
22
33
44
12
23
34
0
1
转载于:https://www.cnblogs.com/petrolero/p/9803621.html
迭代器和生成器的区别?
迭代器是一个更抽象的概念,任何对象,如果它的类有 next 方法和 iter 方法返回自己本身,对于 string、list、dict、tuple 等这类容器对象,使用 for 循环遍历是很方便的。在后台 for 语句对容器对象调用 iter()函数,iter()是 python 的内置函数。iter()会返回一个定义了 next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是 python 的内置函数。在没有后续元素时,next()会抛出一个 StopIteration 异常。
生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数
据的时候使用 yield 语句。每次 next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置
和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常。