MapReduce知识点一
文章目录
- MapReduce 优缺点
- MapReduce流程
- 序列化
- MapReduce 并行处理
- 改变切片的大小
- InputFormat
- 分区
- Combiner
MapReduce 优缺点
MapReduce 分布式运算程序的编程框架
优点:使分布式编程变得简单,高容错性,适合PB级以上的数据处理
缺点: 不适合实时计算
MapReduce流程
- 客户端submit前,获取待处理的信息,根据配置生成任务规划,比如有多少个maptask等。
- 客户端提交信息到yarn,提交的信息包括job的配置,jar包等。
- 各个节点上启动maptask,调用InputFormat中的RecordReader,读取数据转成key/value对。
- 将读取的key/value交给mapper处理,map中调用我们自己写代码。
- map中逻辑代码执行完之后会调用context.wirte(key,value),witre会调用NewOutputCollector类中的MapOutputBuffer类,进而调用write方法写到环形缓冲区。 从map开始写入环形缓冲区,到reduce之前,这一部分叫做shuffle。写入缓存区之前先分区,将分区号一并写入环形缓存区。
- 当环形缓存区达到80%的时候开始溢写.即从内存写数据到文件。在写文件之前需要根据key进行全排序,排序方式为快排,排序之后是按区,区中按key值有序。
- 每一次溢写都会有一个数据文件,还有一个索引文件
- 当所有的数据执行完发生了多次溢写,有多个文件,接着合并文件,合并文件用的归并排序。每一个maptask有一个文件,所以最终会有多个文件,到此mapTask执行完毕
- ReduceTask从map端拉数据到ReduceTask,ReduceTask首先把从不同的maptask上拉取的文件进行合,因为文件本身就是有序的,所以用归并排序进行合并,合成一个文件。 每一个reduce对应一个分区,所以每一个ReduceTask拉取的数据都是自己分区的那个数据。
- 按key分组输入到我们自己写的reduce中,最后调用OutputFormat写出数据到磁盘。
序列化
Hadoop没有用Java的序列化Serializable,因为他是一个重量级的序列化框架,一个对象被序列化后会带有很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输,所以Hadoop开发了一套自己的框架机制writable。 之所以快,因为Writable机制只是传输必要的信息,因为少,所以快. 实现也很简单 实现Writable接口,实现write和readFileds即可。但是如果在MapReduce中作为key的话需要实现的是CompareWritable,因为MapReduce的shuffle中需要排序,所以用到比较。
MapReduce 并行处理
默认情况下map阶段的并行度由客户端在提交Job时的切片数量决定,每一个切片分配一个map task处理,默认情况下切片的大小和block的大小一致。
切片时不考虑文件的整体,只考虑单个文件,这句话的意思是一个文件夹下可能有好几个文件,作为输入的时候要按每一个具体文件切片。
切片的大小当然也可以设置,可以设置成不是block的大小,比如说设置成100M,那这样话如果数据有三个块,分别放到不同的DataNode上,block的大小是128M,就会出现网络传输,因为第一个片切分100M还剩28M,这28M会传输给下一个DataNode,下一个DataNode拿到这28M后加上本地的128M继续切分 100M,剩56M传给下一个节点交给下一个节点的map task处理,这样的话就消耗了网络流量,网络传输是比较珍贵的资源,没有和block大小一致有更高的性能。
改变切片的大小
切片的大小虽然默认是128M,但是也是可以改的,但是没有具体的哪个值是指定这个切片大小,我们可以看下FileInputFormat部分源码,因为默认使用的是FileINputFormat中的切片方法,所以我们看这个,当然还有其他的切片方法,下面会分析:
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
//最小值
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//最大值
long maxSize = getMaxSplitSize(job);
。。。。。。。。。。
//如果允许切片
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
//切片大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
由上面的切片大小方法computeSplitSize,可以知道由三个值决定,块的大小,最大值与最小值:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
看上面的计算切片大小的源码,可以知道规则是 在最大值(maxSize)和块大小(blockSize)取最小值,在最小值(minSize)和后面的结果取最大值,其实就是在minSize和maxSize,blockSiz三个值之间取了一个中间值作为切片大小。
minSize默认值是多少呢?看源码:
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
protected long getFormatMinSplitSize() {
return 1;
}
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
由上面的源码可以知道,由参数mapreduce.input.fileinputformat.split.minsize 设置,默认为1,所以如果不设置的话,默认大小为1
那maxSize的大小为多少呢?
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
}
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
maxSize大小由mapreduce.input.fileinputformat.split.maxsize设置,默认为long的最大值。
所以最大值为long的极大值,最小值为1,块的大小为128M,取中间值所以片的大小为128M.
块的大小我们不能改,所以我们如果要改切片大小的话,只能改minSize和maxSize,既然是取中间值,如果 我们想要片的大小比128M大,需要改minSize值,如果比128M小,则需要给maxSize的值。
根据我的理解,注意这里只是逻辑切片,决定好MapTask的数量等值之后,提交给ResourceManager,ResourceManager分配真正的maptask,到具体的NodeManager运行。
InputFormat
那么我们在写map程序的时候,需要重写maper,maper里面有一个map方法:
protected void map(LongWritable key, Text value, Context context){
}
第一个参数是偏移量,第二个是value,默认情况下是文件的一行值,有没有想过这个值是怎么来的么? 是由InputFormat这个类得来,InputFormat有两个方法:
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context) ;
public abstract RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context)
}
两个方法一是计算分片,一个是获取RecordReader,而RecordReader则是用来读取文件。
默认是的InputFormat为TextInputFormat,可以在JobContextImpl中看到“:
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
而TextInputFormat,继承自FileInputFormat,父类中getSplists就是 我们上面说的计算分片,而TextInputFormat返回的RecordReader是LineRecordReader,根据字面意思也知道返回的是行。
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
在理解LineRecordReader 这个类之前,我们应该先了解其父类RecordReader:
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
public abstract void initialize(InputSplit split,TaskAttemptContext context)
// 尝试读取下一个Key value 值,如果读到了则返回true,否则false
public abstract boolean nextKeyValue() ;
//获取key
public abstract KEYIN getCurrentKey() ;
//获取value
public abstract VALUEIN getCurrentValue();
//进度
public abstract float getProgress();
public abstract void close() ;
}
上面的nextKeyValue表示尝试读取下一个key/value的值,如果有的话,则调用方法getCurrentKey 和getCurrentValue来拿到key/value的值。这个规则不是我瞎掰的,有代码为证,在父类mapper中:
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
明白了RecordReader的规则,我们再看LineRecordReader 这个类,其实只需要看下nextKeyValue这个方法就好了:
public class LineRecordReader extends RecordReader<LongWritable, Text>{
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
。。。。。。。。。
}
@Override
public LongWritable getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}
}
所以看上面的代码就可以知道,读取的时候是按行读取的,in.readLine,而maper的第一个参数LongWritable则是每一行的开头的偏移量
明白了上面的规则,我们也可以自定义自己的RecordReader,如果定义自己的RecordReader,则也需要定义自己的InputFormat。
当然既然分片是在InputFormat中的getSplits进行的,hadoop默认定义了多个InputFormat的实现类用于实现不同的分片和不同的读取数据的机制,比如说KeyValueTextInputFormat,该format集成自FileInputFormat,分片机制和TextInputFormat完全一样,但是读取数据虽然也是按行读取,但是key/value则不同,key默认是每一行的按tab键分割的第一串字符,当然按什么分割可以自己在Configration中定义,还有一个NLineInputFormat,这个分片机制则是按行来分片,具体多少行分片可以自己定义,比如按三行来切片:
NLineInputFormat.setNumLinesPerSplit(job, 3);
分区
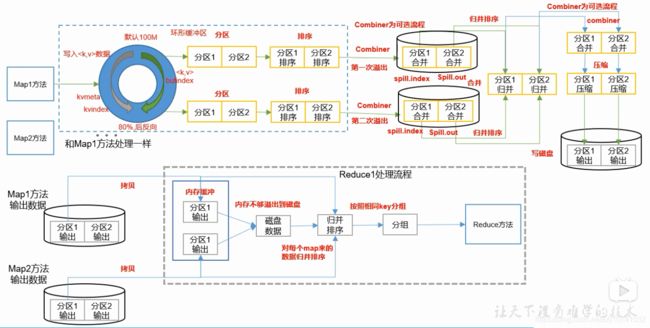
分区的数量不代表ReduceTask的数量,ReduceTask的数量可以使用job.setNumReduceTasks(2)指定。
根据指定ReduceTask的数量之后,默认分区算法是用每一个key的哈希值取模ReduceTask的数量,结果代表此数据的分区号。
每一个数据的分区在写入环形缓存区的时候已经计算完毕,一并写入环形缓存区。
在溢写的过程中会先排序,排序的规则是个二次排序,意思是先根据分区比较,之后才是key值的比较,这样排序的结果就是先分区有序,接着是分区内数据值的有序。
排序的代码是快排,类是QuickSort.java ,在排序的过程中,实际上排序的是环形缓冲区的索引,在MapOutputBuffer.java中,如下代码:
public int compare(final int mi, final int mj) {
final int kvi = offsetFor(mi % maxRec);
final int kvj = offsetFor(mj % maxRec);
final int kvip = kvmeta.get(kvi + PARTITION);
final int kvjp = kvmeta.get(kvj + PARTITION);
// sort by partition
if (kvip != kvjp) {
return kvip - kvjp;
}
// sort by key
return comparator.compare(kvbuffer,
kvmeta.get(kvi + KEYSTART),
kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART),
kvbuffer,
kvmeta.get(kvj + KEYSTART),
kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART));
}
需要注意的是自定义分区一定要小于等于ReduceTask的数量,否则的话会抛异常,也很好理解,如果ReduceTask的数量大于分区的数量,最多ReduceTask会输出一个空文件,但是如果分区的数量大于ReduceTask,就证明该分区没有ReduceTask处理,那么这部分数据就没了意义,所以直接抛异常了。
public synchronized void collect(K key, V value, final int partition){
。。。。。。
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
}
Combiner
上图中有多次用到Combiner:
Combiner虽然本质上是一个reduce,但是没有默认的实现,需要自己定义并且在job中设置才可以。Combiner的作用是先在本地的合并,减少网络之间的传输量。但是并不是所有的输出都适合使用Combiner,只有那些不会改变最终结果的才适合使用,重点是不会改变最终的结果!
使用它其实很简单,直接继承Reduce即可,所以Combiner的本质也是一个reduce,使用的话在job中设置一下即可:
job.setCombinerClass();
下篇再说说分组
欢迎关注我的微信公众号: 北风中独行的蜗牛
