mysql索引
一 为什么
1.减少存储引擎需要扫描的数据量
2.随机IO变成顺序IO:扫表只是扫描叶子节点,叶子节点是顺序排列的 / 覆盖索引
3.分组,排序操作避免使用临时表
二 是什么
加速对表中数据行检索创建的一种分散存储(在硬盘中存储是不连续的)的数据结构(索引字段与硬盘地址的映射表)
三 B-Tree
1..二叉查找树:二叉树的分布影响查找性能
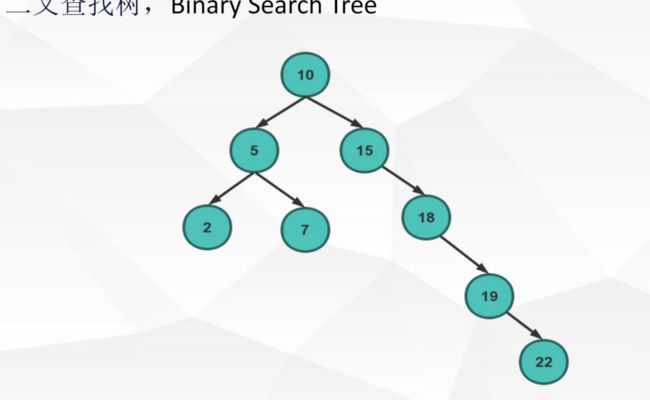
2.平衡二叉查找树:某一个节点的高度差不超过1,超过1则进行旋转操作保证分布平衡
完全平衡二叉查找树:所有节点高度差不超过1
缺点:层数决定IO次数,磁盘块(节点/页)保存数据量太小,未利用磁盘IO数据交换特性(操作系统定义一次内存与磁盘交换大小为4k,而节点数据大小很小,浪费),未利用好磁盘IO的预读能力
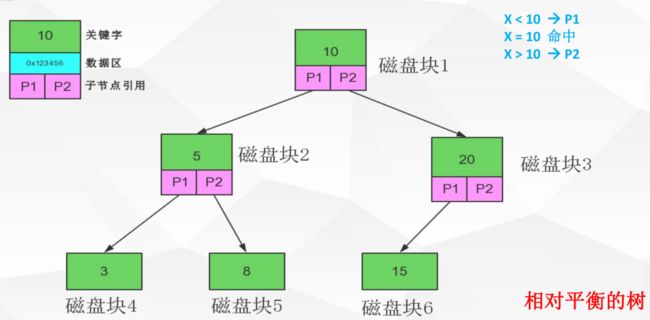
3.多路平衡二叉树--绝对平衡树B-Tree
关键字可以有多个,有n个关键字,就有n+1条路。因为一个节点存储的关键字多,所以数据也会变大,满足磁盘IO数据交换特性。新加入一个索引,二叉树的分布就要满足节点数是路数-1,所以每次增加都会重新排列,索引不宜建多。而数据类型选择较小的也会让节点的数据量更多,例如,选择int类型不选择double,char类型而不是varchar类型。

4.B+Tree--mysql索引选择

5.B+Tree 和 B-tree区别
1 ,B+ 节点关键字搜索采用闭合区间
2 ,B+ 非叶节点不保存数据相关信息,只保存关键字和子节点的引用
3 ,B+ 关键字对应的数据保存在叶子节点中
4 ,B+ 叶子节点是顺序排列的,并且相邻节点具有顺序引用的关系
6.为什么mysql选用B+Tree
B+ 树是B- 树的变种(PLUS 版)多路绝对平衡查找树,他拥有B- 树的优势
B+ 树扫库、表能力更强
B+ 树的磁盘读写能力更 强
B+树 树 的排序能力更强
B+ 树的查询效率更加 稳定(仁者见仁、智者见智
四 不同存储引擎对B+Tree的实现
每个存储引擎都会有一个表定义文件.frm文件
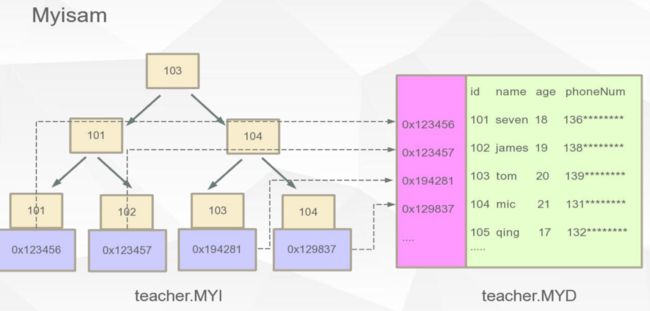
1.myIsam:数据和索引分离

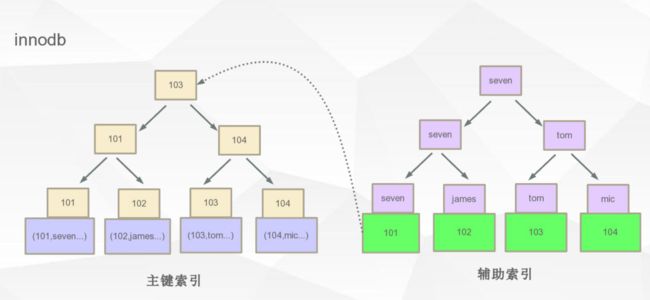
2.innoDB:以主键为索引组织数据存储,数据和索引放在一起,节点数据保存所有行数据
聚簇索引:数据库表行中的数据的物理顺序与键值的逻辑顺序相同
除了主键索引,也可以添加辅助索引。辅助索引数据只会存放索引字段以及指向主键索引节点,再从主键索引树种找到具体行数据
五 其他
1.列的离散型决定索引是否启用
count(distinct col) : count(col):比例越高,离散型越高,选择的就越少,选择性就越好
比例越低,相同关键字节点就越多,选择就越多,mysql会认为这样的索引不如全表索引,所以索引会失效
2.最左匹配原则
索引关键字比较大小,是对关键字从左到右依次进行,且不可跳过。具体怎么比较要根据创建数据库时采用什么排序规则。
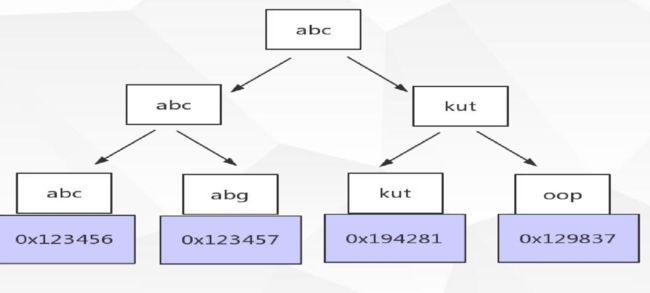
3.联合索引

4.覆盖索引
查询列就是索引关键字,可以直接返回,不用寻找叶子节点的数据,较少数据库IO,随机IO变为顺序IO,提高查询性能-->尽量不要使用select *.
5.索引使用提示
索引列的数据长度能少则少。
索引一定不是越多越好,越全越好,一定是建合适的。
匹配列前缀可用到索引 like 9999%,like %9999%、like %9999用不到索引;
Where 条件中 not in 和 <>操作无法使用索引;
匹配范围值,order by 也可用到索引;
多用指定列查询,只返回自己想到的数据列,少用select *;
联合索引中如果不是按照索引最左列开始查找,无法使用索引;
联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引;
联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引;
六 设置索引

6.1 索引类型:unique(唯一索引),normal(普通索引,给某列建立的索引),full_text(全文索引,所用于分词)
6.2 索引方法:hash,bTree
问题:hash索引利用hash运算得到hash值可以一次在hash值和数据的对应表中检索出数据,那为什么目前索引多使用BTree,而不是hash?
答案:1.hash值只能用于精确匹配,=,<>,in这些操作,而不能用于范围搜索,更不能用于排序.
2.hash算法每次都是全表扫描
3.hash索引不能利用部分索引键查询,也就是组合索引不能只用到前面一个或几个索引进行查询.
4.hash值大量相同时,hash索引效率不一定比btree高.