mycat基础
一 从哪来--数据库性能瓶颈的原因
1.数据库连接:数据库连接数有限
2.表数据量
2.1 mysql索引--B-Tree形式,是一种硬盘级索引,每次获取索引都要从硬盘读到内存,有一定IO损耗。
数据量越多,树越大。所以,索引对于小数据量的表来说,性能不如全表扫描.对于中大表来说比较合适,但对于 超大表,索引也会失效(考虑分库分表:a分库分表,全量扫描,不需要索引. b.分库分表,热点数据放到一个分片+索引)
2.2 全表扫描,数据太大
3.硬件资源(QPS/TPS)
二 是什么--基于cobar的开源框架,解决分库分表、读写分离问题的介于数据层和业务层的分布式数据存储中间件.
1.相关概念
1.1 逻辑库:mycat中的库,一个或多个数据库集群构成的逻辑库.
1.2 逻辑表:mycat中的表.
1.2.1 分片表:横向切分的表--全局序列号,保证主键约束在分布式条件下正常使用
1.2.2 分片规则:例如:哈希函数
1.2.3 全局表:字典表.好多个表都需要的数据,放到全局表,全局表改变,其他表都改变.所有分片都冗余一份字段数据
1.2.4 E-R表:关联关系的表,子表的记录与其所关联的父表的记录存放在同一个数据分片上,解决跨分片数据关联查询的问题
1.2.5 非分片表:不需要分片的表
1.3 分片节点:分片数据库,主从算一个节点
1.4 节点主机:有一个或多个分片节点的主机(写,读节点主机)
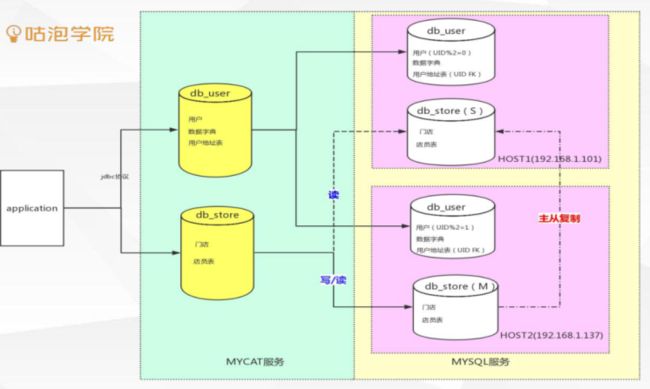
2.mycat原理
拦截永华发来的sql语句,对sql语句做特定分析(分片分析,路由分析,读写分离分析,缓存分析),然后将sql语句发往后端真实的数据库,并将返回结果做聚合排序处理,最后返回给用户.
4

三 适用场景
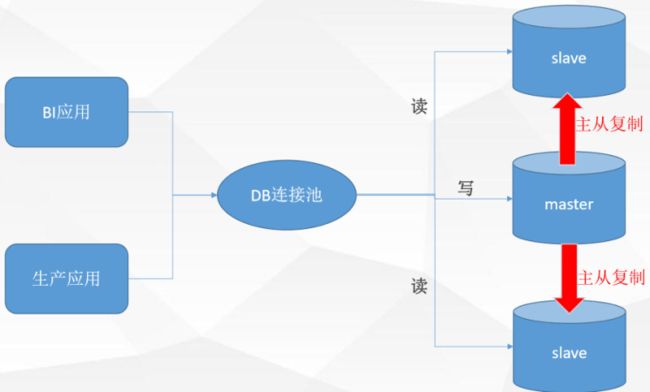
1.读写分离:解决了数据库连接数和数据库硬件资源的问题
缺陷:主从复制延时问题
2.分库分表
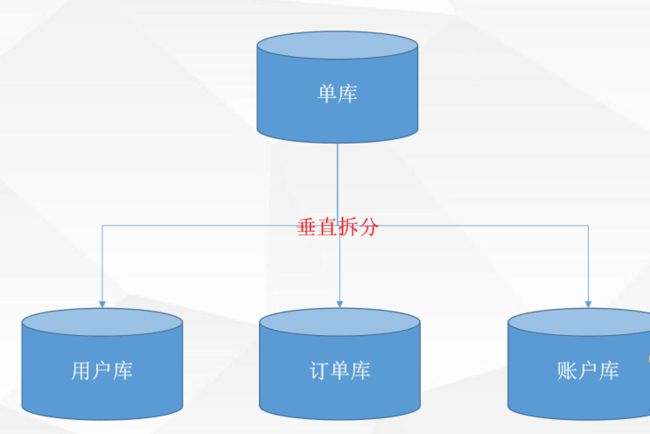
2.1垂直拆分--模块清晰,移植性高,解决了数据库连接数和数据库硬件资源的问题
缺陷:联表查询问题,分布式事务问题
2.2 水平拆分:一张大表拆成若干张小表
解决了表数据量大,数据库连接和硬件性能的问题。

3.多租户
方案一:独立数据库
方案二:共享数据库database,隔离数据结构schema(在mysql中database和schema同等概念)
方案三:共享数据库和数据结构(共享表,只不过每张表加一个字段标识是哪个租户)
四 为什么
由BIO升级为NIO,AIO,优化了buffer,增强了聚合,join等基本特性,兼容绝大多数数据库(native支持mycat集群,JDBC方式支持oracle,DB2,sqlserver,mongoDB等数据库)