RedisCluster模式启动的环境中,通过Redis中的每个连接,都可以访问 cluster nodes 访问到所有的服务器列表以及其所处于的角色(master/slave)。对于RedisCluster来说,在实际运行时,只会访问到其中的master节点,slave既不能用于write操作,也不能进行read。
原有JedisCluster
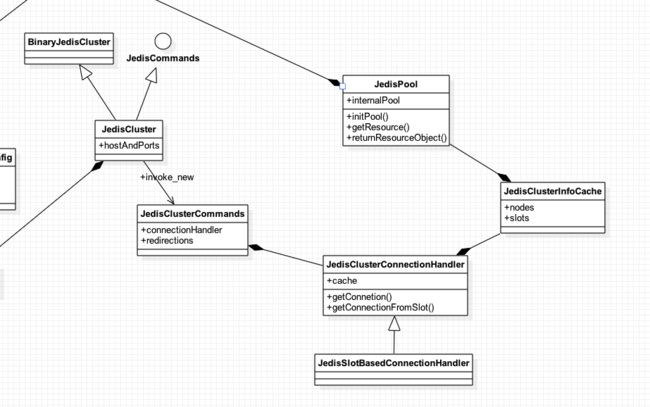
JedisCluster的UML图结果如上图所示,在每次执行JedisCluster相关操作时,都需要通过JedisClusterCommand提供connection来进行,该connection需要根据key来计算出对应的slot,以便可以进行后续redis相关操作。
return new JedisClusterCommand(connectionHandler, maxRedirections) {
@Override
public String execute(Jedis connection) {
return connection.get(key);
}
}.run(key);
在JedisClusterCommand.run方法中,会根据slot计算出对应的connection。
为了尽量减少对原有代码的侵入性,我们需要定义线程上下文(ThreadLocal)级别的变量,其中内置了访问的粒度(READ/WRITE),以便访问的为master还是slave Redis数据源。
改进的ZhenJedisCluster
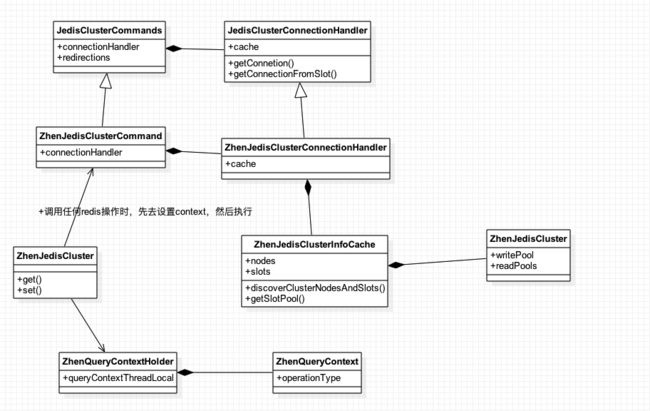
根据jedis连接来获得Cluster结构:
private Map getClusterNodes(Jedis jedis) {
Map hpToNodeObjectMap = new HashMap<>();
String clusterNodesCommand = jedis.clusterNodes();
String[] allNodes = clusterNodesCommand.split("\n");
for (String allNode : allNodes) {
String[] splits = allNode.split(" ");
String hostAndPort = splits[1];
ClusterNodeObject clusterNodeObject =
new ClusterNodeObject(splits[0], splits[1], splits[2].contains("master"), splits[3],
Long.parseLong(splits[4]), Long.parseLong(splits[5]), splits[6],
splits[7].equalsIgnoreCase("connected"), splits.length == 9 ? splits[8] : null);
hpToNodeObjectMap.put(hostAndPort, clusterNodeObject);
}
return hpToNodeObjectMap;
}
将其整理成可用结构,分出master节点,以及slave节点对应的master节点,区分读写:
Map masterNodes = new HashMap<>();
for (ClusterNodeObject clusterNodeObject : clusterNodeObjects) {
String ipPort = clusterNodeObject.getIpPort();
String[] ipPortSplits = ipPort.split(":");
HostAndPort hostAndPort = new HostAndPort(ipPortSplits[0], Integer.parseInt(ipPortSplits[1]));
setNodeIfNotExist(hostAndPort);
if (clusterNodeObject.isMaster()) {
ZhenJedisPool zhenJedisPool = new ZhenJedisPool();
zhenJedisPool.setWritePool(nodes.get(ipPort));
masterNodes.put(clusterNodeObject.getNodeId(), zhenJedisPool);
String[] slotSplits = clusterNodeObject.getSlot().split("-");
for (int i = Integer.parseInt(slotSplits[0]); i <= Integer.parseInt(slotSplits[1]); i++) {
this.slots.put(i, zhenJedisPool);
}
}
}
for (ClusterNodeObject clusterNodeObject : clusterNodeObjects) {
if (!clusterNodeObject.isMaster()) {
String masterNodeId = clusterNodeObject.getMasterNodeId();
ZhenJedisPool zhenJedisPool = masterNodes.get(masterNodeId);
zhenJedisPool.getReadPools().add(nodes.get(clusterNodeObject.getIpPort()));
}
}
改进的结构中,需要getConnectionFromSlot方法需要调用ZhenJedisClusterInfoCache.getSlotPool来根据slot以及当前读写状态(read/write)来获取对应的Jedis连接:
public JedisPool getSlotPool(int slot, ZhenQueryContext queryContext) {
r.lock();
try {
ZhenJedisPool zhenJedisPool = slots.get(slot);
if (queryContext.getOperationType() == OperationType.WRITE) {
return zhenJedisPool.getWritePool();
} else {
List readPools = zhenJedisPool.getReadPools();
return readPools.get(new Random().nextInt(readPools.size()));
}
} finally {
r.unlock();
}
}
对于JedisCluster中,在执行每一步操作之前,都需要设置对应的读写上下文,便于在内部选择master/slave connection:
@Override
public String get(final String key) {
ZhenQueryContextHolder.getInstance().setQueryContext(new ZhenQueryContext(OperationType.READ));
return new ZhenJedisClusterCommand(connectionHandler, maxRedirections) {
@Override
public String execute(Jedis connection) {
return connection.get(key);
}
}.run(key);
}
处理完成后,只需要在执行时使用我们提供的JedisCluster即可正常运行。
执行验证
当前节点如果为slave,也不能只读,需要额外设置属性 slave-read-only
可以证实,经过改造后确实调用到了指定的master节点上:
5974ed7dd81c112d9a2354a0a985995913b4702c 192.168.1.137:6389 master - 0 1470273087539 26 connected 0-5640
d08dc883ee4fcb90c4bb47992ee03e6474398324 192.168.1.137:6390 master - 0 1470273086034 25 connected 5641-11040
ffb4db4e1ced0f91ea66cd2335f7e4eadc29fd56 192.168.1.138:6390 slave 5974ed7dd81c112d9a2354a0a985995913b4702c 0 1470273087539 26 connected
c69b521a30336caf8bce078047cf9bb5f37363ee 192.168.1.137:6388 master - 0 1470273086536 28 connected 11041-16383
532e58842d001f8097fadc325bdb5541b788a360 192.168.1.138:6389 slave c69b521a30336caf8bce078047cf9bb5f37363ee 0 1470273086034 28 connected
aa52c7810e499d042e94e0aa4bc28c57a1da74e3 192.168.1.138:6388 myself,slave d08dc883ee4fcb90c4bb47992ee03e6474398324 0 0 19 connected
出现该问题,加上slave-readonly yes 参数后,重启发现也并没有什么作用,仍然报上面的错误,而且直接通过命令行连接时,仍然出现问题:
192.168.1.137:6390> get key1
-> Redirected to slot [9189] located at 192.168.1.138:6388
"value1"
经过查找,在github上发现问题所在, https://github.com/antirez/redis/issues/2202,如果连接到slave节点,可以通过readonly来进行处理:
//如果是只读连接 {
connection.readonly();
}
return execute(connection);
使用zookeeper监测集群状态变化
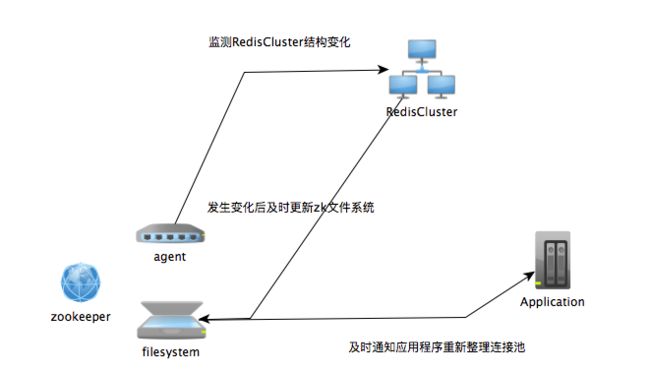
建立Redis agent,用于监测RedisCluster的状态变化,如果RedisCluster中的状态与zookeeper上的一致,不进行任何操作,否则更新zookeeper上的文件。
agent的执行时间间隔可以控制在1s,便于及时发现rediscluster的状态问题。
应用程序中需要注册监听该文件的变化,如果有变化及时进行更新redis读写池。
zookeeper agent
操作zookeeper可以使用curator框架,Curator框架提供了一套高级的API, 简化了ZooKeeper的操作。 它增加了很多使用ZooKeeper开发的特性,可以处理ZooKeeper集群复杂的连接管理和重试机制。
ZooKeeper原生的API支持通过注册Watcher来进行事件监听,但是Watcher通知是一次性的,因此开发过程中需要反复注册Watcher,比较繁琐。Curator引入了Cache来监听ZooKeeper服务端的事件。Cache对ZooKeeper事件监听进行了封装,能够自动处理反复注册监听,简化了ZooKeeper原生API繁琐的开发过程。
关于curator的基本介绍,可以参考: http://ifeve.com/zookeeper-curato-framework/
首先需要添加maven依赖:
org.apache.curator
curator-recipes
2.7.0
在主线程中进行间隔1s的轮询,查询zookeeper上的文件与当前redis状态,如果相同不做任何修改,否则进行更新。
建立zookeeper连接:
client = CuratorFrameworkFactory.newClient("xxx",
new RetryNTimes(5, 5000));
client.start();
获取zookeeper上的值与线上redis环境进行比对:
public void compareAndSet() throws Exception {
List jedisPoolFromCluster = getJedisPoolFromCluster();
String currentString = JSON.toJSONString(jedisPoolFromCluster);
if (client.checkExists().forPath(TOPO_PATH) == null) {
SysOutLogger.info("Start to create zk node: " + TOPO_PATH);
client.create().creatingParentsIfNeeded().forPath(TOPO_PATH, currentString.getBytes());
} else {
String statData = new String(client.getData().forPath(TOPO_PATH));
if (!currentString.equalsIgnoreCase(statData)) {
SysOutLogger.info("Node not synchronized with online, to reset...");
client.setData().forPath(TOPO_PATH, currentString.getBytes());
}
}
}
应用端监测文件修改
而在应用端,完全依赖zookeeper上的文件状态变更,来更新rediscluster中的slots,nodes等对象:
String content = new String(client.getData().forPath(TOPO_PATH), "UTF-8");
List zhenJedisPoolObjects =
JSON.parseObject(content, new TypeReference>() {
});
discoverClusterNodesAndSlots(zhenJedisPoolObjects);
final NodeCache nodeCache = new NodeCache(client, TOPO_PATH, false);
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
String content = new String(nodeCache.getCurrentData().getData(), "UTF-8");
List zhenJedisPoolObjects =
JSON.parseObject(content, new TypeReference>() {
});
discoverClusterNodesAndSlots(zhenJedisPoolObjects);
}
});
注意这里需要使用到curator中的NodeCache来操作,它可以帮助监听zookeeper上节点数据的变化。如果想要监听zookeeper上路径的变化,可以使用:PathChildrenCache,根据对应的事件类型event type:CHILD_ADDED, CHILD_REMOVED, CHILD_UPDATED来进行事件处理。
注意需要保证zookeeper上的redis连接,能够以正常的方式访问到(内外网切换)。