基于LR的新闻多分类(基于spark2.1.0, 附完整代码)
原创文章!转载请保留原始文章链接,谢谢!
环境:
- Scala2.11.8 + Java1.8.0_112
- Spark2.1.0 + HanLP1.3.2
完整项目代码见我的GitHub:https://github.com/yhao2014/ckoocML
(因为HanLP分词模型太大,未上传至项目中,需要的请从HanLP发布页下载,然后解压后将data目录整个放到ckoocML\dictionaries\hanlp\目录下即可)
注:GitHub上此部分代码已更改,进行了模块划分,主要分成了预处理类Preprocessor.scala和逻辑回归类LRClassifier.scala,以及基于LR分类的训练及测试LRClassTrainDemo.scala、LRClassPredictDemo.scala。但不影响本博文对LR多分类的实现和解读
主体流程
自从引进DataFrame之后,spark在ml方面,开始使用DataFrame作为RDD的上层封装,以屏蔽RDD层次的复杂操作,对应用开发者提供简单的DataFrame,以减少开发量。本文以最新的spark2.1.0版本为基础,构建从数据预处理、特征转换、模型训练、数据测试到模型评估的一整套处理流程。另外,经过综合考虑,本文分词方法选用HanLP分词工具(文档丰富、算法公开、代码开源,并且经测试分词效果比较好),数据使用的是从新闻网站爬取的新闻分类数据,数据格式如下:


说明:使用了4个分类的数据(文化、财经、军事和体育),每个分类使用了1000条数据,每行一条数据,有4个字段(分类、标题、日期和内容),使用"\u00EF"作分割符。
一、数据清洗转换
数据预处理步骤主要进行数据清洗、转换操作。主要代码如下:

首先从文件加载数据到RDD,然后按分割符进行切分。因为分类字段爬取下来时没有进行清洗,在这里我们需要将其分类提取出来,然后转换为spark上LR算法可以识别的Double形式,并按分类字段过滤掉未提取到分类或者分类不正确的脏数据,然后转换为DataFrame,并指定每个字段的字段名。
注意:这里必须要添加一行import spark.implicits._,否则不能引用到SparkSQL的toDF方法!
二、分词
在经过数据预处理之后,我们已经将数据转换为了我们想要的DataFrame格式,并且清洗掉了。接下来我们需要进行分词的操作,将新闻内容切分成一个个词语的形式,以便后续进行停用词去除以及转换为特征向量

这里我模仿spark的lm包下的StopWordsRemover类创建了Segmenter类,用于对数据进行分词,其内部调用了HanLP分词工具。(由于spark自带的StopWordsRemover等使用的闭包仅限于ml包,自定义的类无法调用,故只是采用了与StopWordsRemover类似的使用形式,内部结构并不相同,并且由于以上原因,Segmenter类没有继承Transformer类,故无法进行pipeline管道操作,此缺陷有待解决)
Segmenter类具体实现如下:
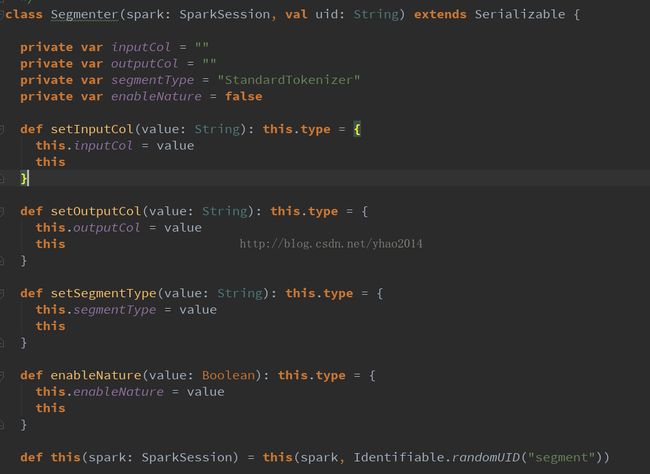


主要在transform方法中调用了HanLP相关的分词方法。注意,如果使用NShortSegment和CRFSegment,需要new相应的对象,这里我自己创建了MyNShortSegment和MyCRFSegment类,继承了HanLP中对应的类,并继承了Serializable特质(其实并没有做什么操作~)。主要是因为HanLP没有对它们实现序列化,直接在RDD中使用它们会报错。(当然你也可以对HanLP的源码进行修改,再重新打包。个人觉得比较麻烦,并且不易跟进HanLP发布进度,所以没去弄~)

此外,上面Segmenter代码的最后是使用DataFrame的join操作将原DataFrame与分词后的DataFrame进行了连接,与spark使用的schemaType元数据推断DataFrame结构的方式不同。
三、去除停用词
分词之后,我们需要对一些常用的无意义词(通常是语气词、连词等),如:“的”、“我们”、“是”等(统称为“停用词”)进行去除。因为这些词没有多大的意义,但是在自然语言中又经常使用,这些词不去掉会强烈的干扰我们对特征的抽取效果。(比如:在体育分类语料中,“的”共出现500次,“足球”共出现300次,那么谁更能代表体育这个分类呢?谁更应该作为特征被保留下来呢?)
去除停用词的操作我们直接调用ml包中的StopWordsRemover类:

由于spark的StopWordsRemover类中内置的停用词都是一些英文停用词,而我们在这里处理的是中文语料,故需要加载自己的停用词。这里我使用了HanLPdictionary目录下的stopwords.txt文件提供的停用词。(这里面都是一些基本停用词,如果对停用词要求比较高,可以在网上找几份停用词表进行合并,效果会更好一点)
有兴趣的同学可以进到transform方法中看一看,spark官方的去除停用词方法跟我们常用处理一样,将停用词转换成set,然后调用contains进行判断,然后过滤:

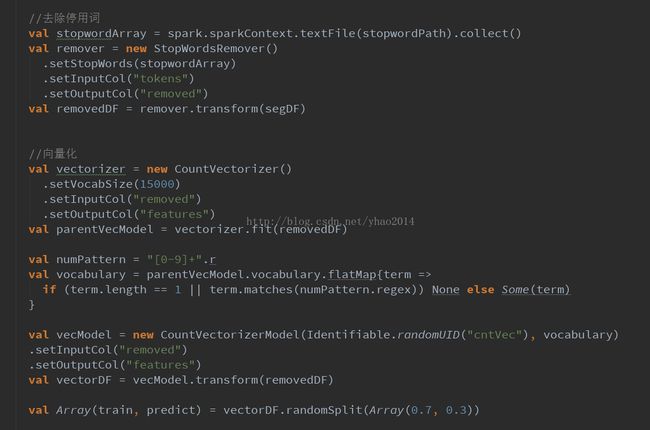
四、向量化
由于目前常用的分类、聚类等算法都是基于向量空间模型VSM(即将对象向量化为一个N维向量,映射成N维超空间中的一个点),VSM将数据转换为向量形式,便于对大规模数据进行矩阵操作等,也可以通过计算超空间中两个点之间的距离(一般是余弦距离)来计算两个向量之间的相似度。因此,我们需要将经过处理的语料转换为向量形式,这个过程叫做向量化。
这里我们也调用spark提供的向量化类CountVectorizer类进行向量化操作:

这里的vocabSize是词汇表大小,即转换为向量之后的向量维度。通过阅读fit方法(训练向量化模型,主要是计算vocabulary词汇表的过程),我们可以看到其逻辑也比较简单:wordcount计算词频 --> 计算文档频率 --> 按文档频率过滤-->取词频最大的vocabSize个词

从这里可以看出,所谓的训练CountVectorizer模型仅仅是对词频进行统计,计算出词频最大的vocabSize个词作为词汇表。下面我们继续看看transform方法:

transform方法也比较简单,将词汇表建立索引并转换为Map -->遍历并保留在词汇表中的词,及其词频 -->转换为稀疏向量形式
我们可以将向量化后的数据打印出来看看长什么样儿:


后面没有显示完,我们取第一条数据看看:

可以看到前面是标签,即类别序号,后面是一个稀疏向量,其元素分别代表:向量维度(2000)、特征索引数组(即词汇表中哪些索引号的词出现在该文档中)、词频数组(词汇表中索引词在该文档中出现的次数),例:最后一个元素1975表示词汇表中第1975个词出现在该文档中,出现的次数是4
五、模型训练
在经过向量化后,数据就可以用来进行分类模型的训练了!这里我们先使用最常用的分类模型——逻辑回归LogisticRegression。spark上提供的LR模型可以实现多分类,正好适用于我们的语料。
下面是分类模型训练的代码:

在new一个LogisticRegression时,可以对其参数进行设置,这里大概跟大家说一下:
- setMaxIter:设置最大迭代次数(默认100),具体迭代过程可能会在不足最大迭代次数时停止(参照下一条)
- setTol:设置容错(默认1E-6),每次迭代会计算一个误差值,误差值会随着迭代次数的增加逐渐减小,如果误差值小于设置的容错值,则停止迭代优化
- setRegParam:设置正则化项系数(默认0.0),正则化项主要用于防止过拟合现象,因此,如果你的数据集比较小,特征维数又比较多时,易出现过拟合,此时可以考虑增大正则化项系数
- setElasticNetParam:正则化范式比(默认0.0),正则化一般有两种范式:L1(Lasso)和L2(Ridge)。L1一般用于特征的稀疏化,L2一般用于防止过拟合。这里的参数即设置L1范式的占比,默认0.0即只使用L2范式
- setLabelCol:设置标签列(默认读取“label”列)
- setFeaturesCol:设置特征列(默认读取“features”列)
还有一个参数是setWeightCol,即设置各特征的权重,默认值是将每个特征权重设置为1.0,这里我们使用默认值就好了,如果对特征有特殊要求,可考虑重新设置对应的权重(如将标题作为一项特征,并且标题重要性更高,可将标题这一特征的权重设置大一点)
注意:由于我们的数据稀疏性本来就很高了(2000维的向量只有少数维度有值),因此切记不要把setElasticNetParam设置得过大!!因为setElasticNetParam越大表示L1正则所占比例越高,对向量稀疏化效果越好,而我们的向量本来就很稀疏了,再稀疏化特征基本都为0了,得到的分类效果跟随机分类没什么区别(不信的话可以把这个值设置大一点,然后把后面说到的预测结果的probability打印出来,可以看到在各类别上的概率差别不大)
关于参数的设置,一般根据语料特点和业务场景的不同有所不同,这是一个经验性的东西,没有一个固定的计算公式(所以对数据挖掘和算法工程师来说,调参是一件相当耗时并且头疼的问题)。我们这里暂时使用spark官方example里面的设置,后面再进行调优。
这里由于篇幅问题就不跟进去LR算法的源码了,有兴趣的同学可以自行走读源码。
开始训练时,spark默认会打印每次迭代的信息:

这里打印了每次迭代的步长(由算法内部自动设置),以及每次迭代完后计算出的误差值,可以看到我们经过40次迭代后达到迭代次数上线,就停止迭代优化过程了。
刚才我们在代码中设置了打印前100个结果,可以看到console中有预测结果的输出:
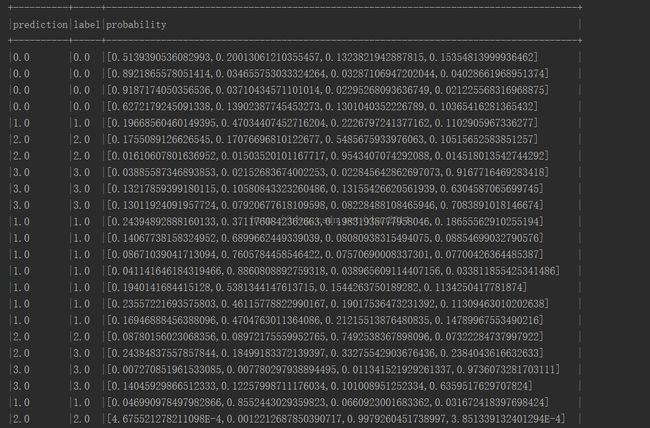
可以看到效果还是蛮不错的!等等,怎么全分对了?不应该吧,往下面找找原来还是有些分错了:

不过从这些来看就算是分错了,在概率上和正确类别的概率相差也不是很大,可能是因为文章本身区分度就不太好吧!
六、模型估计
虽说模型看上去效果不错,但是我们也需要一个量化指标来衡量其效果:这个模型的准确率、召回率和F1值(这3个指标是评判模型预测能力常用的一组指标,没听过的可以先去了解一下)有多高呢?好在spark提供了用于多分类模型评估的类MulticlassClassificationEvaluator,我们就使用这个来测一测这个模型到底怎么样
具体代码如下:

这个类比较蛋疼的是每次必须设置参数setMetricName(默认返回f1值)以获取不同的评价指标,能不能一次性返回所有指标呢?通过看MulticlassClassificationEvaluator的源码,我们可以看到其实是可以的:
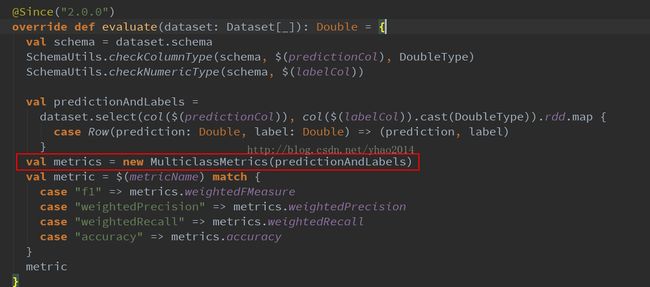
evaluate方法中的这个metrics实际上包含了所有的评价指标,但是头疼的是这东西并没有返回。不过!我们可以自己new这个东东来搞啊,于是自己写了以下代码:

运行结果如下:



运行了3次,结果都还不错,看来效果确实还可以。准确率基本能达到93%~94%的样子,这也是因为我们数据的类别区分度本身就比较好,如果选择的数据类别比较相近,分错的概率相对来说就比较大了。
整个测试的流程到这里基本结束了,一般数据挖掘的整体流程不外乎上面这些:数据清洗转换-->特征选择 -->向量化 -->模型选择与训练 -->模型测试 -->模型评估
但是!这仅仅是常规的处理流程,在使用算法的过程中,往往得到的结果并没有这么理想,这时我们需要对处理过程进行调优,接下来讲讲调优的事儿。
(本次测试的完整代码在最后面!)
================分割线 ====================
调优
下面我们将从以下几个方面来进行调优:
- 调整训练集大小
- 特征选择
- 模型调参
调整训练集大小
训练集的大小将直接决定我们模型的好坏。一般情况下,用于模型训练的训练集应当越大越好(打个比方,如果让你猜一个东西是什么,是不是给的提示越多,越容易才出来?),如果训练集过小,极易导致过拟合(即模型在训练数据上准确率特别高,几乎都可以分对,但是对于新数据,其预测的准确率并不是很高,这时可以称这个模型的泛化能力差。导致过拟合的原因是数据量太少,训练时模型把个别数据的局部特征当成了全局特征来处理,比如说:如果我们就给模型几片带锯齿边缘的树叶,它可能得到的结果是树叶都带锯齿边缘,那么如果给他一片光滑边缘的树叶,模型可能就把它识别成不是树叶)
因此我们首先尝试增大训练集看看效果会不会提升,这里我们将每个类别的数量从1000增加到2000,然后再运行一遍看看效果:
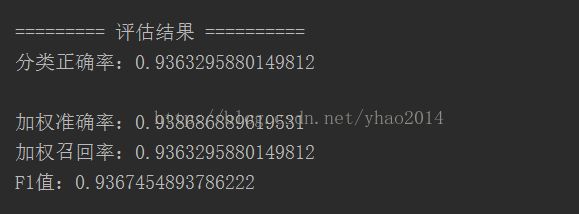
可以看到效果并没有得到提升,这也可能是由于准确率等本来就很高了,数据集的调整很难再有大的提升。其实,从我们选择的特征维数就可以估计,并不会产生过拟合现象(毕竟我们的维度相对于语料词数来说,还是比较少的)
特征选择
排除了过拟合,通过查看类别概率分布,发现每个文档在每个类别的概率相差不大,这意味着什么?可以猜测应该是我们的特征对样本数据的区分度不够,也就是说,使用目前选择的特征,无法很好地区分出哪些文档是属于哪个类别的!针对这种情况,我们先做以下两步操作:
- 过滤有效特征
- 增大特征维数
- 更改向量化方式
过滤有效特征
一般做特征选择时,都会尽量选择区分度大的特征,也就是容易从特征识别出是属于哪个类别(如从“足球”很容易看出应该是体育相关的文章)我们先把词汇表打印出来看看里面到底是些什么东西:

结果:

好吧!看来确实需要对词汇表做一些处理了,这里面都是些什么啊!我们可以做下面的操作:
- 过滤长度为1的词
- 过滤数字
代码实现如下:

结果:

分类结果:

感觉效果来说还不错,如果准确率本身不高的情况下,相信应该会有较大的提升!
增加特征维数
特征区分效果不好,会不会是特征数量太少呢?毕竟我们的语料是新闻长文本,每篇文档按200词计算,2000 * 4 *200 = 1600000,总共大于160万词,就算去除重复词、停用词,好歹10W应该是有的吧,我们此前设置词汇表大小才2000,会不会太小?我们试着把词汇表大小设置为5000看看效果怎么样:



看来效果果然有提升,同时,发现一个问题:多次运行得到的结果波动比较大,这个问题可以先思考一下,在下面我们进行模型调参的时候会讲到这个问题。
好了,我们再试试将特征增加到10000维看看效果:


可以看到各项指标还是有提高,我们再讲特征维度提高到15000:



看来特征维数我们设置为15000比10000的效果更好。下面我们为了节约时间直接将维度提升到50000试试:


可以看到准确率等反而出现了下降!
大家有时间还可以继续进行测试,其实可以发现随着维度的增加,准确率等先是不断的提高,然后反而会降低。降低就是因为产生了过拟合,特征数量太多,模型的泛化能力下降,此时就可以确定准确率最高时的特征维数比较合适。这里由于篇幅问题,15000~50000中间的就省略就不继续测试了。(注意,模型训练的时间会随着特征维度的增加大幅增加,这是因为中间进行向量计算时,其计算量会因为向量长度增加成几何增长,这也就是我们常说的“维度灾难”)
改进向量化方式
在上面流程中,我们使用了根据词频来选择向量的特征,这是一种常用的方法,但是还有另一种更常用的方法——TF-IDF,中文叫做“文档-逆文档频率”,这里的文档频率其实就是我们上面用到的词频,逆文档频率其实就是预料中文档的总数除以包含该词的文档数,然后再取对数,具体公式如下:

这里词频除以出现次数最多的词的词频是为了做标准化处理,消除不同文档长短带来的影响(也可以除以当前文档词的总数),而求逆文档频率的时候将包含词的文档数+1是为了做平滑处理,防止出现除零的情况。
使用TF-IDF与直接使用词频做特征选择最大的不同是TF-IDF选出来的词的区分度更高,因为TF-IDF越高的词,代表这个词更加为当前文档所独有,因此更能代表这篇文档的属性。
由于我们这里的各项指标都已经很高了,将TF改成TF-IDF效果不是很大,故不做此步骤的优化!如果你的分类准确率并不是很高,可以替换成TF-IDF做特征选择,效果应该会有所提升,TF-IDF在spark中也已经提供,具体使用可参考example中ml目录下的TfIdfExample.scala(注意,该示例中使用了HashingTF来提取词频,但是该过程没有生成我们上述的词汇表,也就是说我们不能针对词频提取的特征进行过滤等操作,推荐把此部分更换为我们上述提到的使用CountVectorizer来做词频计算,然后再使用IDF方法提取IDF值)
模型调参
我们这里使用到的LogisticRegression可以设置的参数在上面已经介绍过了,下面我们将针对这些参数进行调整,看看能否提高模型性能。
setMaxIter与setTol
这两个参数我们在上面也介绍过了,主要是用来控制模型迭代的次数。不知各位是否还记得,上面我们发现一个问题:使用40次迭代时,多次测试发现结果波动比较大,其实这个原因很明显:因为迭代次数不够,模型还没有收敛到最优,还处于波动状态,因此才会导致这个问题。如果我们设置迭代次数比较多,误差阈值比较小,这样虽然会延长模型训练的时间,但是训练处的模型会更加稳定,性能也会更优!
我们尝试设置setMaxIter=100,setTol=1E-7,看看结果怎么样(这里还是使用15000个特征,每个分类各2000篇文档):


可以看到这次模型确实收敛了,而且各项指标来看确实有所提高!
大家还可以对setRegParam和setElasticNetParam进行测试,这两个参数是控制正则化的,用于减小过拟合现象,这里我们就不进行测试了(如果数据本来就稀疏的情况下,增大setElasticNetParam可能会导致准确率下降!原因我们在上面参数说明的时候已经解释过了)
================分割线 ====================
完整代码
package preprocess
importorg.apache.log4j.{Level, Logger}
importorg.apache.spark.ml.classification.LogisticRegression
importorg.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel,StopWordsRemover}
importorg.apache.spark.ml.util.Identifiable
importorg.apache.spark.mllib.evaluation.MulticlassMetrics
importorg.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* Created by yhao on 2017/2/11.
*/
objectLRClassificationTest {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
// HanLP.Config.enableDebug()
val spark = SparkSession
.builder
.master("local[2]")
.appName("Segment Test")
.getOrCreate()
val filePath ="G:/test/classnews"
val stopwordPath ="dictionaries/hanlp/data/dictionary/stopwords.txt"
//数据清洗、转换
val textDF = clean(filePath, spark)
//分词
val segmenter = new Segmenter(spark)
.setSegmentType("StandardSegment")
.enableNature(false)
.setInputCol("content")
.setOutputCol("tokens")
val segDF = segmenter.transform(textDF)
//去除停用词
val stopwordArray =spark.sparkContext.textFile(stopwordPath).collect()
val remover = new StopWordsRemover()
.setStopWords(stopwordArray)
.setInputCol("tokens")
.setOutputCol("removed")
val removedDF = remover.transform(segDF)
//向量化
val vectorizer = new CountVectorizer()
.setVocabSize(15000)
.setInputCol("removed")
.setOutputCol("features")
val parentVecModel =vectorizer.fit(removedDF)
val numPattern = "[0-9]+".r
val vocabulary =parentVecModel.vocabulary.flatMap{term =>
if (term.length == 1 ||term.matches(numPattern.regex)) None else Some(term)
}
val vecModel = newCountVectorizerModel(Identifiable.randomUID("cntVec"), vocabulary)
.setInputCol("removed")
.setOutputCol("features")
val vectorDF =vecModel.transform(removedDF)
val Array(train, predict) =vectorDF.randomSplit(Array(0.7, 0.3))
//LR分类模型训练
train.persist()
val lr = new LogisticRegression()
.setMaxIter(100)
.setRegParam(0.2)
.setElasticNetParam(0.05)
.setLabelCol("label")
.setFeaturesCol("features")
.fit(train)
train.unpersist()
//LR预测
val predictions = lr.transform(predict)
// predictions.select("prediction","label", "probability").show(100, truncate = false)
//评估效果
val predictionsRDD =predictions.select("prediction", "label")
.rdd.
map { case Row(prediction: Double, label:Double) => (prediction, label) }
val metrics = newMulticlassMetrics(predictionsRDD)
val accuracy = metrics.accuracy
val weightedPrecision =metrics.weightedPrecision
val weightedRecall = metrics.weightedRecall
val f1 = metrics.weightedFMeasure
println("\n\n=========评估结果==========")
println(s"分类正确率:$accuracy")
println(s"\n加权准确率:$weightedPrecision")
println(s"加权召回率:$weightedRecall")
println(s"F1值:$f1")
spark.stop()
}
def clean(filePath: String, spark:SparkSession): DataFrame = {
import spark.implicits._
val textDF =spark.sparkContext.textFile(filePath).flatMap { line =>
val fields =line.split("\u00EF")
if (fields.length > 3) {
val categoryLine = fields(0)
val categories =categoryLine.split("\\|")
val category = categories.last
var label = -1.0
if (category.contains("文化"))label = 0.0
else if (category.contains("财经"))label = 1.0
else if (category.contains("军事"))label = 2.0
else if (category.contains("体育"))label = 3.0
else {}
val title = fields(1)
val time = fields(2)
val content = fields(3)
if (label > -1) Some(label, title,time, content) else None
} else None
}.toDF("label","title", "time", "content")
textDF
}
}
代码截图