Seaborn的使用
转载于 : https://www.cnblogs.com/abdm-989/p/12204640.html
Seaborn
既然有了matplotlib,那为啥还需要seaborn呢?其实seaborn是在matplotlib基础上进行封装,Seaborn就是让困难的东西更加简单。用Matplotlib最大的困难是其默认的各种参数,而Seaborn则完全避免了这一问题。seaborn是针对统计绘图的,一般来说,seaborn能满足数据分析90%的绘图需求,复杂的自定义图形,还是要Matplotlib。Seaborn旨在使可视化成为探索和理解数据的核心部分。其面向数据集的绘图功能对包含整个数据集的数据框和数组进行操作,并在内部执行必要的语义映射和统计聚合,以生成信息图。
5种主题风格
- darkgrid
- whitegrid
- dark
- white
- ticks
统计分析绘制图——可视化统计关系
统计分析是了解数据集中的变量如何相互关联以及这些关系如何依赖于其他变量的过程。常见方法可视化统计关系:散点图和线图。
常用的三个函数如下:
- replot()
- scatterplot(kind="scatter";默认)
- lineplot(kind="line",默认)
常用的参数
* x,y,hue 数据集变量 变量名
* date 数据集 数据集名
* row,col 更多分类变量进行平铺显示 变量名
* col_wrap 每行的最高平铺数 整数
* estimator 在每个分类中进行矢量到标量的映射 矢量
* ci 置信区间 浮点数或None
* n_boot 计算置信区间时使用的引导迭代次数 整数
* units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
* order, hue_order 对应排序列表 字符串列表
* row_order, col_order 对应排序列表 字符串列表
* kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点
size 每个面的高度(英寸) 标量
aspect 纵横比 标量
orient 方向 "v"/"h"
color 颜色 matplotlib颜色
palette 调色板 seaborn颜色色板或字典
legend hue的信息面板 True/False
legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False
share{x,y} 共享轴线 True/False用散点图关联变量
散点图是统计可视化的支柱。它描绘了使用点云的两个变量的联合分布,其中每个点代表数据集中的观察。因此观测两个变量之间的分布关系最好用散点图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
## 定义主题风格
sns.set(style="darkgrid")
## 加载tips
tips = sns.load_dataset("tips")
## 绘制图形,根据不同种类的三点设定图注
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips);
plt.show()
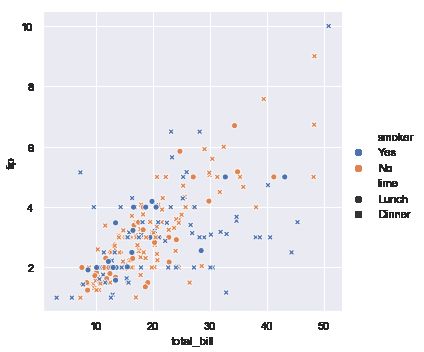
## 绘制渐变效果的散点图
sns.relplot(x="total_bill", y="tip", hue="size", palette="ch:r=-.5,l=.75", data=tips);
plt.show()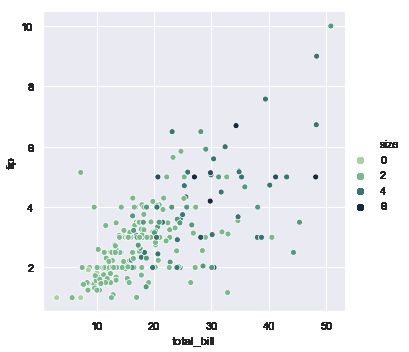
如果数据量大的情况下,用hex散点图。
eg:
## 设置颜色
sns.set(color_codes=True)
mean, cov = [0, 1], [(1, .5), (.5, 1)] # 设置均值(一组参数)和协方差(两组参数)
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("ticks"):
sns.jointplot(x=x, y=y, kind="hex", color="k")
plt.show()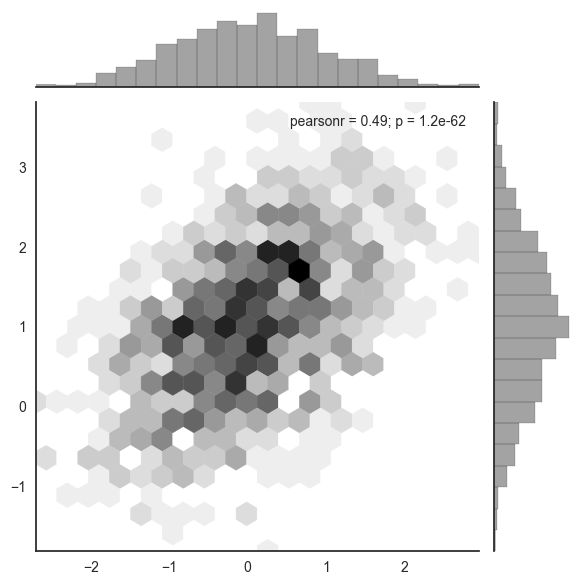
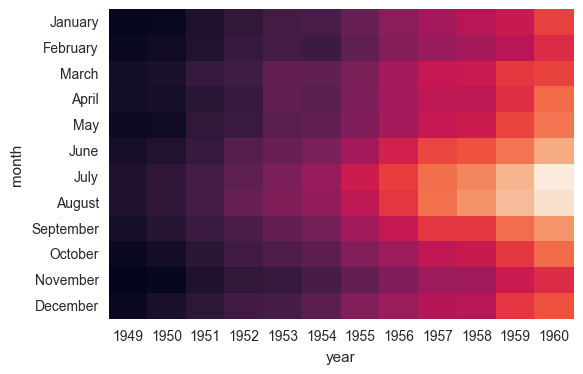
热点图
热点图是通过使用不同的标志将图或页面上的区域按照受关注程度的不同加以标注并呈现的一种分析手段,标注的 手段一般采用颜色的深浅、点的疏密以及呈现比重的形式。在数据分析中比较常用,如果离散数据波动变化比较 大,那么可以使用热点图来观察波动变化,另外特别是在相关性和相关系数的应用中,特征和特征之间会存在相关 系数,常用的方式是采用Pandas求出相关系数,此时可以采用热点图来清晰地观察特征和特征之间的相关程度。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
np.random.seed(0)
sns.set()
## 热点图的绘制 ax = sns.heatmap(flights, cbar=False)
直方图
直方图主要是用于单变量单特征数据分析。
eg:
sns.set(style="darkgrid")
np.random.seed(sum(map(ord, "distributions")))
x = np.random.gamma(6, size=200)
sns.distplot(x, kde=False, fit=stats.gamma)
plt.show()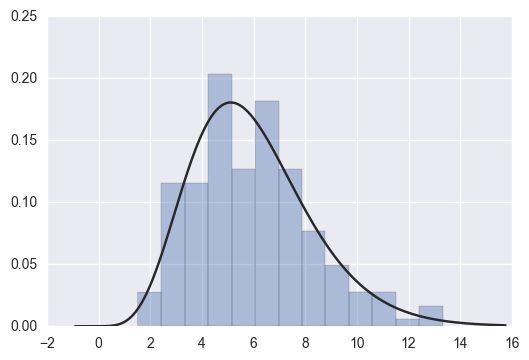
比较图
比较土主要适用于观察变量两两之间的关系。对角线是直方图(统计数量),其他的是散点图。
eg:采用的是鸢尾花的内部数据集
sns.set(color_codes=True)
iris = sns.load_dataset("iris")
sns.pairplot(iris)
plt.show()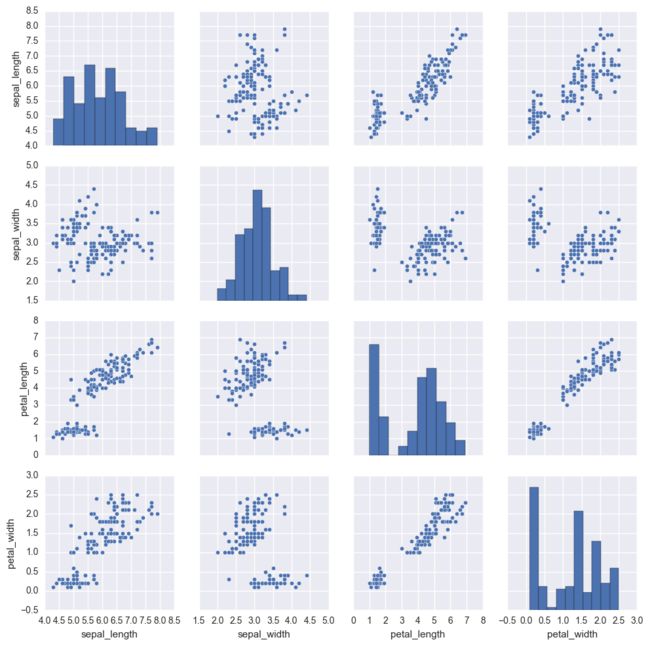
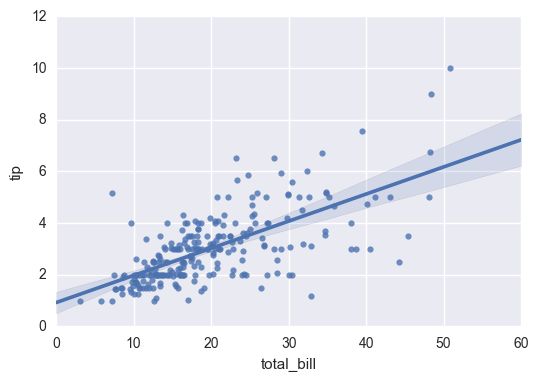
回归分析图
regplot()和lmplot()都可以绘制回归关系,推荐regplot()。
两者间主要的区别是:regplot接受各种格式的x y,包括numpy arrays ,pandas series 或者pandas Dataframe对象。相比之下,lmplot()只接受字符串对象。这种数据格式被称为’long-form’或者’tidy’。除了输入数据的便利性外,regplot()可以看做拥有lmplot()特征的一个子集。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "regression")))
tips = sns.load_dataset("tips")
## 使用regplot绘制
sns.regplot(x="total_bill", y="tip", data=tips)
plt.show()
rebust回归图,需要添加参数忽略某个异常点
eg:
anscombe = sns.load_dataset("anscombe")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, scatter_kws={"s": 80})
plt.show()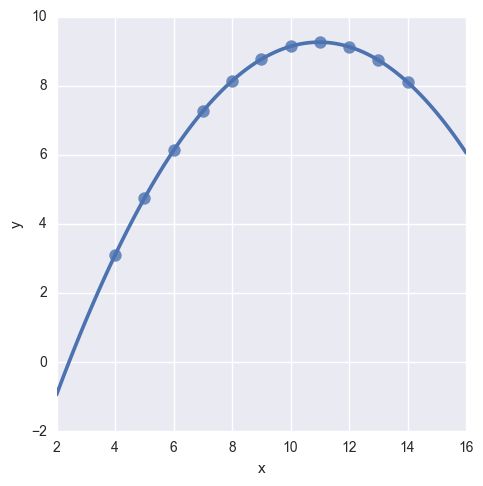
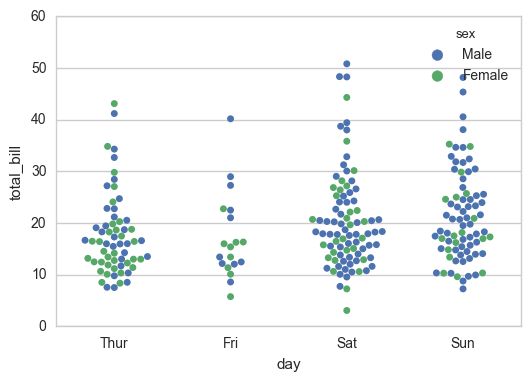
树形图
类似于散点图,用于显示每一个数据的分布情况
eg:
tips = sns.load_dataset("tips")
sns.swarmplot(x="day", y="total_bill",hue="sex",data=tips)
plt.show()