国际化困境(第二篇)
难得我写系列文章,我的作风更偏向于一鼓作气。(那接下去怎么说?再而衰,三而竭……希望不是这样,呵呵……)
七、OEM与ANSI的转换
好,接上次,上次讲到OEM和ANSI,在文章后面我还给出一张所谓“全图”,当然,只针对两个code page的0x80到0xFF的字符,一个是437,可以认为是英文版的OEM code page,一个是1252,可认为是英文版的ANSI code page,我还说了,一般情况下,Windows环境下是不需要显示OEM字符的,但有些文章是早在DOS时代就已经写好了,现在要拿到Windows下来显示,但由于编码不一样,那显示出来的东西就有可能不对了啊。在以前DOS环境下,我们经常能看到类似下图的这种“画面”,一些框框点点,当然,现在我没有DOS了,就用控制台来代替,不过之前要先切换code page到437,表示使用IBM PC的默认编码,然后选中字体为Licida Console。
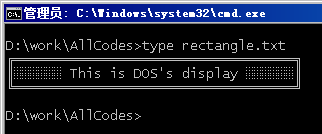
这个rectangle.txt可以用下面这段代码生成:
{ BYTE byChars[] = {0xC9, 0XCD, 0xCD, 0xCD, 0xCD, 0xCD, 0XCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0XCD, 0xCD, 0xCD, 0xCD, 0xCD, 0XCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xCD, 0XCD, 0xCD, 0xCD, 0xCD, 0xCD, 0xBB, 0x0D, 0x0A, 0xBA, 0xB0, 0xB0, 0xB0, 0xB0, 0xB0, 0xB0, 0x20, 0x54, 0x68, 0x69, 0x73, 0x20, 0x69, 0x73, 0x20, 0x44, 0x4f, 0x53, 0x27, 0x73, 0x20, 0x64, 0x69, 0x73, 0x70, 0x6c, 0x61, 0x79, 0x20, 0xb0, 0xb0, 0xb0, 0xb0, 0xb0, 0xb0, 0xba, 0x0d, 0x0a, 0xc8, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xcd, 0xbc, 0x0d, 0x0a}; HANDLE hFile = CreateFile(TEXT("rectangle.txt"), GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); DWORD dwWritten; WriteFile(hFile, byChars, sizeof(byChars), &dwWritten, NULL); CloseHandle(hFile); }
那我们在Windows环境下,直接打开rectangle.txt文件查看,会怎么样呢?我这里有个截图:
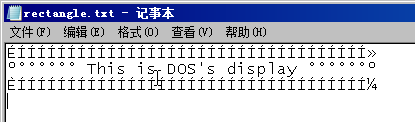
要有这种显示,得按照上一篇文章说的那样,在控制面板里的“区域和语言选项”里,把“非Unicode程序使用的语言”设置为英语(美国),否则显示效果可能会不同。为什么会这样呢?原因就是Windows使用的编码和DOS使用的编码不一样,这在上一篇已经提起过这个问题,并且在最后给出了一个图,大家对照这个图看,就知道为什么DOS下的点点框框,到了Windows下就变成了别的字符。那问题来了,像rectangle.txt这种文件是早就写好的DOS文件,我不想去改它啊,如果内容多,改起来多麻烦,但我现在用的是Windows啊,我能不能有别的办法让它“正常点”显示?办法是有的,请看下面的代码,其中m_edit绑定到一个Edit控件。
{ HANDLE hFile = CreateFile(TEXT("rectangle.txt"), GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); DWORD dwSize = GetFileSize(hFile,NULL); BYTE *pContent = new BYTE[dwSize+1]; DWORD dwRead; ReadFile(hFile, pContent, dwSize, &dwRead, NULL); CloseHandle(hFile); OemToChar((const char *)pContent, (char *)pContent); ::SetWindowTextA(m_edit.m_hWnd, (CHAR *)pContent); delete[] pContent; }
这里同样,需要修改系统设置,使用英语(美国),运行,下图是我的结果:

这样看起来就比较“整齐”了吧,如果你有兴趣想看看OemToChar这个函数是怎么转换的,可以把asciiex.txt的转换前后内码对比一下,代码我就不贴了,下图是我整理出来的图,供参考。

上图画得我好累,给点掌声吧……浅绿色横条是OEM字符,蓝色数字是它的内码,无浅绿条的符号是对应的ANSI字符,红色数字是ANSI的内码,大家体会体会这个转换是怎么一回事。
八、Locale
Locale中文直译是“场所”,但我想在这里叫做“语言环境”更合适一些,不同的Locale对字符串的表达就不太一样,比如说日期,中国人的写法是“2009-3-23”,美国人的写法是“Mar. 23, 2009”,英国人的写法是“23 March 2009”,这都是不一样的,除了日期外,还包括一些诸如货币,时间,数字的表达,各国也是不尽相同,或者说不同的语言环境下不同吧,那么,给这些所谓语言环境安排一个ID,来方便我们管理这些表达上的差距,这个ID就叫做Locale ID,简写为LCID,如何知道当前所使用的LCID?
LCID lcidSys = GetSystemDefaultLCID(); LCID lcidUser = GetUserDefaultLCID(); LCID lcidThread = GetThreadLocale(); TRACE(TEXT("System Default LCID: %d/nUser Default LCID: %d/nThread Locale: %d/n"), lcidSys, lcidUser, lcidThread);
有时候,你会发现这几个LCID不同,比如我打印出来的情况是:
System Default LCID: 1033
User Default LCID: 2052
Thread Locale: 2052
那么,这1033,2052到底代表什么呢?
我们认为Locale是一个跟语言有关的东西,所以LCID应该跟语言相对应,那全世界的语言很多啊,光是英语就有好多种,美国英语,英国英语,澳大利亚英语,加拿大英语……它们都是英语,应该说大部分都相同,但不同之处也是显而易见的,前面举的那个日期表达的例子,就可以看出来,英国人的习惯和美国人的习惯是不太一样,所以微软把语言分为两个部分,一部分叫“Primary Language ID”,另一部分叫“Sublanguage ID”,两者合一起才是Language ID,Language ID再外加一个Sort ID,就成为LCID,Sort ID是什么?就是排序方法ID了,像英文这种字母文字,是无所谓排序方法的,正序就a-z,逆序就z-a,但中文就不同了,哪个前,哪个后?我至少知道两种排序方法,一种是按照笔画,一种是按照拼音,另外还有日文,韩文等,也需要Sort ID。
那一共有多少种Primary Language ID和Sublanguage ID呢?他们值又是多少?MSDN上是有说明的,输入“MAKELANGID”查找一下即可,东西还比较多,我就不一一列了。比如美国英语,我们可以在Primary Language这张表中查到English的ID是0x09,然后在Sublanguage表中查到US English的sublanguage ID为0x01,MAKELANGID(0x09, 0x01),结果是0x409。然后再用MAKELCID(0x409, SORT_DEFAULT)生成LCID,由于英文无所谓排序,所以LCID正好就是Language ID。再比如我们再熟悉不过的中国大陆简体中文,中文,Primary ID是0x04,简体中文Sublanguage ID是0x02,MAKELANGID(0x04, 0x02),结果是0x804,再MAKELCID(0x804, SORT_CHINESE_PRCP),得出的结果是0x804,即2052,由于SORT_CHINESE_PRCP(按拼音排序)正好是0,所以LCID就是Language ID。
了解了Locale,我们接下去就要了解如何使用Locale了,前面说了,想日期格式,时间格式,货币格式,这种东西跟Locale是很有关系的,我们如何来获取这些东西的详情?有一个API可以帮我们忙——GetLocaleInfo。
下面的程序就是利用GetLocaleInfo来获取各种跟语言环境相关的显示格式。 我的打印结果如下: 这段代码将帮助你寻找答案。这是我的运行结果: 这是正常的,显示出来没有任何问题,但如果由于某些原因,漏掉了一个byte,情况会怎么样呢?如图所示: 是不是后面的字符都乱了?那为什么会漏掉这个字节?我现在也不知道怎么说,但这种情况以前经常发生,在DOS时代的时候,我们是使用一些外挂程序来处理中文的,最有名的一个叫UCDOS,运行了它,才能运行WPS,(如果你不知道WPS这个是什么的话,我强烈建议你马上到网上搜一下),当然很多人都不知道得这样干,他们只想用WPS打字,于是就给他们弄个傻瓜式的批处理文件,利用UCDOS,我们就能够输入汉字了,UCDOS有个可爱的特点,那就是能够删除半个汉字,这听起来有些不可思议,但以前确实可以,我现在已经找不到这么老的软件试给大家看了,由于允许删除半个汉字,后面的汉字解释就遇到了问题,当然电脑是不会认为有问题的,而我们读起来就完全不对了。有没有可能网络传输的时候漏掉一个byte呢?这个我也没法试验,可能性确实有吧,我想……而之后我会讲到UTF-8,就比较好地解决了这个问题。
struct StruLocaleInfo { DWORD dwValue; TCHAR *lpStrName; } g_localeAll[] = { LOCALE_ICALENDARTYPE, TEXT("LOCALE_ICALENDARTYPE"), LOCALE_ICALENDARTYPE, TEXT("LOCALE_ICALENDARTYPE"), LOCALE_ICENTURY, TEXT("LOCALE_ICENTURY"), LOCALE_ICOUNTRY, TEXT("LOCALE_ICOUNTRY"), LOCALE_ICURRDIGITS, TEXT("LOCALE_ICURRDIGITS"), LOCALE_ICURRENCY, TEXT("LOCALE_ICURRENCY"), LOCALE_IDATE, TEXT("LOCALE_IDATE"), LOCALE_IDAYLZERO, TEXT("LOCALE_IDAYLZERO"), LOCALE_IDEFAULTANSICODEPAGE, TEXT("LOCALE_IDEFAULTANSICODEPAGE"), LOCALE_IDEFAULTCODEPAGE, TEXT("LOCALE_IDEFAULTCODEPAGE"), LOCALE_IDEFAULTCOUNTRY, TEXT("LOCALE_IDEFAULTCOUNTRY"), LOCALE_IDEFAULTEBCDICCODEPAGE, TEXT("LOCALE_IDEFAULTEBCDICCODEPAGE"), LOCALE_IDEFAULTLANGUAGE, TEXT("LOCALE_IDEFAULTLANGUAGE"), LOCALE_IDEFAULTMACCODEPAGE, TEXT("LOCALE_IDEFAULTMACCODEPAGE"), LOCALE_IDIGITS, TEXT("LOCALE_IDIGITS"), LOCALE_IDIGITSUBSTITUTION, TEXT("LOCALE_IDIGITSUBSTITUTION"), LOCALE_IFIRSTDAYOFWEEK, TEXT("LOCALE_IFIRSTDAYOFWEEK"), LOCALE_IFIRSTWEEKOFYEAR, TEXT("LOCALE_IFIRSTWEEKOFYEAR"), LOCALE_IINTLCURRDIGITS, TEXT("LOCALE_IINTLCURRDIGITS"), LOCALE_ILANGUAGE, TEXT("LOCALE_ILANGUAGE"), LOCALE_ILDATE, TEXT("LOCALE_ILDATE"), LOCALE_ILZERO, TEXT("LOCALE_ILZERO"), LOCALE_IMEASURE, TEXT("LOCALE_IMEASURE"), LOCALE_IMONLZERO, TEXT("LOCALE_IMONLZERO"), LOCALE_INEGCURR, TEXT("LOCALE_INEGCURR"), LOCALE_INEGNUMBER, TEXT("LOCALE_INEGNUMBER"), LOCALE_INEGSEPBYSPACE, TEXT("LOCALE_INEGSEPBYSPACE"), LOCALE_INEGSIGNPOSN, TEXT("LOCALE_INEGSIGNPOSN"), LOCALE_INEGSYMPRECEDES, TEXT("LOCALE_INEGSYMPRECEDES"), LOCALE_IOPTIONALCALENDAR, TEXT("LOCALE_IOPTIONALCALENDAR"), LOCALE_IPAPERSIZE, TEXT("LOCALE_IPAPERSIZE"), LOCALE_IPAPERSIZE, TEXT("LOCALE_IPAPERSIZE"), LOCALE_IPOSSIGNPOSN, TEXT("LOCALE_IPOSSIGNPOSN"), LOCALE_IPOSSYMPRECEDES, TEXT("LOCALE_IPOSSYMPRECEDES"), LOCALE_ITIME, TEXT("LOCALE_ITIME"), LOCALE_ITIMEMARKPOSN, TEXT("LOCALE_ITIMEMARKPOSN"), LOCALE_ITLZERO, TEXT("LOCALE_ITLZERO"), LOCALE_RETURN_NUMBER, TEXT("LOCALE_RETURN_NUMBER"), LOCALE_S1159, TEXT("LOCALE_S1159"), LOCALE_S2359, TEXT("LOCALE_S2359"), LOCALE_SABBREVCTRYNAME, TEXT("LOCALE_SABBREVCTRYNAME"), LOCALE_SABBREVDAYNAME1, TEXT("LOCALE_SABBREVDAYNAME1"), LOCALE_SABBREVDAYNAME2, TEXT("LOCALE_SABBREVDAYNAME2"), LOCALE_SABBREVDAYNAME3, TEXT("LOCALE_SABBREVDAYNAME3"), LOCALE_SABBREVDAYNAME4, TEXT("LOCALE_SABBREVDAYNAME4"), LOCALE_SABBREVDAYNAME5, TEXT("LOCALE_SABBREVDAYNAME5"), LOCALE_SABBREVDAYNAME6, TEXT("LOCALE_SABBREVDAYNAME6"), LOCALE_SABBREVDAYNAME7, TEXT("LOCALE_SABBREVDAYNAME7"), LOCALE_SABBREVLANGNAME, TEXT("LOCALE_SABBREVLANGNAME"), LOCALE_SABBREVMONTHNAME1, TEXT("LOCALE_SABBREVMONTHNAME1"), LOCALE_SABBREVMONTHNAME2, TEXT("LOCALE_SABBREVMONTHNAME2"), LOCALE_SABBREVMONTHNAME3, TEXT("LOCALE_SABBREVMONTHNAME3"), LOCALE_SABBREVMONTHNAME4, TEXT("LOCALE_SABBREVMONTHNAME4"), LOCALE_SABBREVMONTHNAME5, TEXT("LOCALE_SABBREVMONTHNAME5"), LOCALE_SABBREVMONTHNAME6, TEXT("LOCALE_SABBREVMONTHNAME6"), LOCALE_SABBREVMONTHNAME7, TEXT("LOCALE_SABBREVMONTHNAME7"), LOCALE_SABBREVMONTHNAME8, TEXT("LOCALE_SABBREVMONTHNAME8"), LOCALE_SABBREVMONTHNAME9, TEXT("LOCALE_SABBREVMONTHNAME9"), LOCALE_SABBREVMONTHNAME10, TEXT("LOCALE_SABBREVMONTHNAME10"), LOCALE_SABBREVMONTHNAME11, TEXT("LOCALE_SABBREVMONTHNAME11"), LOCALE_SABBREVMONTHNAME12, TEXT("LOCALE_SABBREVMONTHNAME12"), LOCALE_SABBREVMONTHNAME13, TEXT("LOCALE_SABBREVMONTHNAME13"), LOCALE_SCOUNTRY, TEXT("LOCALE_SCOUNTRY"), LOCALE_SCURRENCY, TEXT("LOCALE_SCURRENCY"), LOCALE_SDATE, TEXT("LOCALE_SDATE"), LOCALE_SDAYNAME1, TEXT("LOCALE_SDAYNAME1"), LOCALE_SDAYNAME2, TEXT("LOCALE_SDAYNAME2"), LOCALE_SDAYNAME3, TEXT("LOCALE_SDAYNAME3"), LOCALE_SDAYNAME4, TEXT("LOCALE_SDAYNAME4"), LOCALE_SDAYNAME5, TEXT("LOCALE_SDAYNAME5"), LOCALE_SDAYNAME6, TEXT("LOCALE_SDAYNAME6"), LOCALE_SDAYNAME7, TEXT("LOCALE_SDAYNAME7"), LOCALE_SDECIMAL, TEXT("LOCALE_SDECIMAL"), LOCALE_SENGCOUNTRY, TEXT("LOCALE_SENGCOUNTRY"), LOCALE_SENGCURRNAME, TEXT("LOCALE_SENGCURRNAME"), LOCALE_SENGLANGUAGE, TEXT("LOCALE_SENGLANGUAGE"), LOCALE_SGROUPING, TEXT("LOCALE_SGROUPING"), LOCALE_SINTLSYMBOL, TEXT("LOCALE_SINTLSYMBOL"), LOCALE_SISO3166CTRYNAME, TEXT("LOCALE_SISO3166CTRYNAME"), LOCALE_SISO639LANGNAME, TEXT("LOCALE_SISO639LANGNAME"), LOCALE_SLANGUAGE, TEXT("LOCALE_SLANGUAGE"), LOCALE_SLIST, TEXT("LOCALE_SLIST"), LOCALE_SLONGDATE, TEXT("LOCALE_SLONGDATE"), LOCALE_SMONDECIMALSEP, TEXT("LOCALE_SMONDECIMALSEP"), LOCALE_SMONGROUPING, TEXT("LOCALE_SMONGROUPING"), LOCALE_SMONTHNAME1, TEXT("LOCALE_SMONTHNAME1"), LOCALE_SMONTHNAME2, TEXT("LOCALE_SMONTHNAME2"), LOCALE_SMONTHNAME3, TEXT("LOCALE_SMONTHNAME3"), LOCALE_SMONTHNAME4, TEXT("LOCALE_SMONTHNAME4"), LOCALE_SMONTHNAME5, TEXT("LOCALE_SMONTHNAME5"), LOCALE_SMONTHNAME6, TEXT("LOCALE_SMONTHNAME6"), LOCALE_SMONTHNAME7, TEXT("LOCALE_SMONTHNAME7"), LOCALE_SMONTHNAME8, TEXT("LOCALE_SMONTHNAME8"), LOCALE_SMONTHNAME9, TEXT("LOCALE_SMONTHNAME9"), LOCALE_SMONTHNAME10, TEXT("LOCALE_SMONTHNAME10"), LOCALE_SMONTHNAME11, TEXT("LOCALE_SMONTHNAME11"), LOCALE_SMONTHNAME12, TEXT("LOCALE_SMONTHNAME12"), LOCALE_SMONTHNAME13, TEXT("LOCALE_SMONTHNAME13"), LOCALE_SMONTHOUSANDSEP, TEXT("LOCALE_SMONTHOUSANDSEP"), LOCALE_SNATIVECTRYNAME, TEXT("LOCALE_SNATIVECTRYNAME"), LOCALE_SNATIVECURRNAME, TEXT("LOCALE_SNATIVECURRNAME"), LOCALE_SNATIVEDIGITS, TEXT("LOCALE_SNATIVEDIGITS"), LOCALE_SNATIVELANGNAME, TEXT("LOCALE_SNATIVELANGNAME"), LOCALE_SNEGATIVESIGN, TEXT("LOCALE_SNEGATIVESIGN"), LOCALE_SPOSITIVESIGN, TEXT("LOCALE_SPOSITIVESIGN"), LOCALE_SSHORTDATE, TEXT("LOCALE_SSHORTDATE"), LOCALE_SSORTNAME, TEXT("LOCALE_SSORTNAME"), LOCALE_STHOUSAND, TEXT("LOCALE_STHOUSAND"), LOCALE_STIME, TEXT("LOCALE_STIME"), LOCALE_STIMEFORMAT, TEXT("LOCALE_STIMEFORMAT"), LOCALE_SYEARMONTH, TEXT("LOCALE_SYEARMONTH") }; { INT iLocaleNum = sizeof(g_localeAll)/sizeof(StruLocaleInfo); INT i; TCHAR szToPrint[4096]; for(i=0; i
LOCALE_ICALENDARTYPE : 1
LOCALE_ICALENDARTYPE : 1
LOCALE_ICENTURY : 1
LOCALE_ICOUNTRY : 1
LOCALE_ICURRDIGITS : 2
LOCALE_ICURRENCY : 0
LOCALE_IDATE : 0
LOCALE_IDAYLZERO : 0
LOCALE_IDEFAULTANSICODEPAGE : 1252
LOCALE_IDEFAULTCODEPAGE : 437
LOCALE_IDEFAULTCOUNTRY : 1
LOCALE_IDEFAULTEBCDICCODEPAGE : 037
LOCALE_IDEFAULTLANGUAGE : 0409
LOCALE_IDEFAULTMACCODEPAGE : 10000
LOCALE_IDIGITS : 2
LOCALE_IDIGITSUBSTITUTION : 1
LOCALE_IFIRSTDAYOFWEEK : 6
LOCALE_IFIRSTWEEKOFYEAR : 0
LOCALE_IINTLCURRDIGITS : 2
LOCALE_ILANGUAGE : 0409
LOCALE_ILDATE : 0
LOCALE_ILZERO : 1
LOCALE_IMEASURE : 1
LOCALE_IMONLZERO : 0
LOCALE_INEGCURR : 0
LOCALE_INEGNUMBER : 1
LOCALE_INEGSEPBYSPACE : 0
LOCALE_INEGSIGNPOSN : 0
LOCALE_INEGSYMPRECEDES : 1
LOCALE_IOPTIONALCALENDAR : 0
LOCALE_IPAPERSIZE : 1
LOCALE_IPAPERSIZE : 1
LOCALE_IPOSSIGNPOSN : 3
LOCALE_IPOSSYMPRECEDES : 1
LOCALE_ITIME : 0
LOCALE_ITIMEMARKPOSN : 0
LOCALE_ITLZERO : 0
LOCALE_S1159 : AM
LOCALE_S2359 : PM
LOCALE_SABBREVCTRYNAME : USA
LOCALE_SABBREVDAYNAME1 : Mon
LOCALE_SABBREVDAYNAME2 : Tue
LOCALE_SABBREVDAYNAME3 : Wed
LOCALE_SABBREVDAYNAME4 : Thu
LOCALE_SABBREVDAYNAME5 : Fri
LOCALE_SABBREVDAYNAME6 : Sat
LOCALE_SABBREVDAYNAME7 : Sun
LOCALE_SABBREVLANGNAME : ENU
LOCALE_SABBREVMONTHNAME1 : Jan
LOCALE_SABBREVMONTHNAME2 : Feb
LOCALE_SABBREVMONTHNAME3 : Mar
LOCALE_SABBREVMONTHNAME4 : Apr
LOCALE_SABBREVMONTHNAME5 : May
LOCALE_SABBREVMONTHNAME6 : Jun
LOCALE_SABBREVMONTHNAME7 : Jul
LOCALE_SABBREVMONTHNAME8 : Aug
LOCALE_SABBREVMONTHNAME9 : Sep
LOCALE_SABBREVMONTHNAME10 : Oct
LOCALE_SABBREVMONTHNAME11 : Nov
LOCALE_SABBREVMONTHNAME12 : Dec
LOCALE_SABBREVMONTHNAME13 :
LOCALE_SCOUNTRY : ??
LOCALE_SCURRENCY : $
LOCALE_SDATE : /
LOCALE_SDAYNAME1 : Monday
LOCALE_SDAYNAME2 : Tuesday
LOCALE_SDAYNAME3 : Wednesday
LOCALE_SDAYNAME4 : Thursday
LOCALE_SDAYNAME5 : Friday
LOCALE_SDAYNAME6 : Saturday
LOCALE_SDAYNAME7 : Sunday
LOCALE_SDECIMAL : .
LOCALE_SENGCOUNTRY : United States
LOCALE_SENGCURRNAME : US Dollar
LOCALE_SENGLANGUAGE : English
LOCALE_SGROUPING : 3;0
LOCALE_SINTLSYMBOL : USD
LOCALE_SISO3166CTRYNAME : US
LOCALE_SISO639LANGNAME : en
LOCALE_SLANGUAGE : ??(??)
LOCALE_SLIST : ,
LOCALE_SLONGDATE : dddd, MMMM dd, yyyy
LOCALE_SMONDECIMALSEP : .
LOCALE_SMONGROUPING : 3;0
LOCALE_SMONTHNAME1 : January
LOCALE_SMONTHNAME2 : February
LOCALE_SMONTHNAME3 : March
LOCALE_SMONTHNAME4 : April
LOCALE_SMONTHNAME5 : May
LOCALE_SMONTHNAME6 : June
LOCALE_SMONTHNAME7 : July
LOCALE_SMONTHNAME8 : August
LOCALE_SMONTHNAME9 : September
LOCALE_SMONTHNAME10 : October
LOCALE_SMONTHNAME11 : November
LOCALE_SMONTHNAME12 : December
LOCALE_SMONTHNAME13 :
LOCALE_SMONTHOUSANDSEP : ,
LOCALE_SNATIVECTRYNAME : United States
LOCALE_SNATIVECURRNAME : US Dollar
LOCALE_SNATIVEDIGITS : 0123456789
LOCALE_SNATIVELANGNAME : English
LOCALE_SNEGATIVESIGN : -
LOCALE_SPOSITIVESIGN :
LOCALE_SSHORTDATE : M/d/yyyy
LOCALE_SSORTNAME : ??
LOCALE_STHOUSAND : ,
LOCALE_STIME : :
LOCALE_STIMEFORMAT : h:mm:ss tt
LOCALE_SYEARMONTH : MMMM, yyyy
你的情况可能跟这个不一样,实验过程中,你可以自行修改下GetLocaleInfo的第一个参数,看看结果。那现在问题来了,这些信息对我们来说,有什么用呢?
当然是有用的,要不微软花那么大力气搞这些东西出来干什么?当用户在使用你的软件的时候,在你提供的界面里输入一个你看起来很奇怪的日期,你会认为这是个合法的日期吗?在你的角度看来,这是不正确的,可在用户的角度看来这是正确的,这是地域差距引起的。在中国,我们喜欢说“年月日”,到了美国就变成了“月日年”,到了英国则是“日月年”,你如何来“兼容”用户这些使用习惯,来使得你的软件“放之四海而皆准”?而日期格式的差异仅仅是其中的一个,别的差异还多得是,看看上面这段程序运行的结果,这些东西是不是你都要考虑呢?这个时候,也许你真体会到了“国际化”原来真的是个big problem,并不是简单的“翻译”。
事实上,我们是不太可能考虑得如此的完全,否则代价太高了,而一些地域上的差距,也没有想象中的严重,所以我们就选择其中一部分认为是有必要考虑的,来考虑。
不过从这里可以看出来,做一个通用软件有多么不容易……
前面在获取LCID过程中,我们调用了3个函数,分别是GetSystemDefaultLCID,GetUserDefaultLCID和GetThreadLocale(),它们取回来的结果分别是系统默认的LCID,当前用户默认的LCID和调用线程的LCID。
九、DBCS
我在文章一开始的时候就提到过,这个论题是非常零碎的,可不是,现在我又开始回头接第四节的内容,讲DBCS了,DBCS即是Double Byte Character Set,双字节字符集。有时候也写作MBCS,Multi-Byte Character Set,多字节字符集,我们现在可以认为MBCS等同于DBCS,将的都是同样的东西。但别跟DBMS混淆啊,DBMS是数据库管理系统,跟这个没关系。
DBCS为什么诞生?看看第四节的内容,就知道了,很大程度上是由于汉字的存在,那前面提到的GBK编码其实就是一种DBCS编码了。显然,我们在GBK编码的文件中写入英文和数字这些ASCII字符,它们被正常显示出来是没问题的,GBK编码跟ASCII兼容,那问题是我们的电脑怎么知道文章中哪些是ASCII字符,哪些是汉字呢?这个还得我们写点程序看看。
{ CPINFO info; UINT iCP = 936; //GBK ASSERT(GetCPInfo(iCP, &info)); TRACE(TEXT("Code page %d's defalt char is [%c]/n"), iCP, info.DefaultChar[0]); TRACE(TEXT("Max size of a char: %d/n"), info.MaxCharSize); int i; const int iMaxLeadBytePairNum = 5; for(i=0; i
Code page 936's defalt char is [?]
Max size of a char: 2
Lead byte pair 0: 0x81-0xFE
第一个Default char的意思是当进行内码转换时候,把无法转换的字符置为这个Default char,在我这里显示出来是个“?”,一个问号,这也是系统给出的默认值,这会你可知道这个小问号的起源了吧?当你使用英文系统,对一个用GBK编码的文本文件读入,并用MultiByteToWideChar这个函数转换为Unicode(后面再具体讨论)显示出来的时候,你就往往会发现这种问号,这也是Windows给出的默认的转换失败符号,所以一般情况下,你看到这个小问号,就知道,在什么地方转换失败了,小问号是转换的时候产生的,现在可能你还不是很理解,但没关系,我后面还会强调。
第二个打印结果,Max size是2,这是说这个code page一个字符最大占用2个字节,事实上,在GBK编码中,所有中文字符占用的都是两个字节。
第三个打印出来的结果,这是关键的,Windows如何来识别接下去的一个字符是不是双字节字符,就靠这个Lead byte了,Windows会判断接下去的这个byte是否处于0x81到0xFE这个范围之内,如果是,则把这个byte和它的后一个byte看作是一个字符。从程序运行结果看得出,GBK的Lead byte只有一个区间,就是0x81-0xFE,我不清楚其它DBCS编码是否有多个区间,按MSDN上的说法,最多能容纳下5个区间,这个大家可以自行尝试了,比如看看日文Shift-JIS编码(932)的运行情况,我就不直接公布答案了。
大家想想看,这种DBCS编码方式存在什么问题呢?看看下面这个图:

本篇就先讲那么多,下一篇准备转入最重要的部分——UNICODE。应该这几天能整理好。
本篇小结
一个Locale对应许多语言相关的格式,它还对应一个ANSI code page和一个OEM codepage,同一个Locale的ANSI code page和OEM code page有些时候相同,比如中文(中国),有些时候不同,比如英语(美国)。OEM编码的文本要在Windows环境下有较好的显示,通常需要转换。DBCS是汉字处理的较早解决方法,DBCS是根据Lead byte来判断接下去的内容是否是代表一个双字节字符,这种方法容易由于丢失一个字节而产生通篇的乱码。