Python网络爬虫与信息提取(四):信息的标记和提取
Python网络爬虫与信息提取
- 1.信息的标记
- 2.HTML的信息标记
- 3.三种信息标记形式
- XML:Extensible Markup Language
- JSON:JavaScript Object Notation
- YAML:YAML Ain't Markup Language
- 3.三种信息标记形式的比较
- 4.信息提取的一般方法
- 5.基于bs4库的HTML内容查找方法
- 主要方法
- 6.实例
- “中国大学排名定向爬虫”实例
- 功能描述
- 程序的设计结构
- 代码实现
- 代码优化
1.信息的标记
- 标记后的信息可形成信息组织结构,增加了信息维度
- 标记后的信息可用于通讯、存储或展示
- 标记的结构与信息一样具有重要价值
- 标记后的信息更利于程序理解和运用
2.HTML的信息标记
- HTML是WWW (World Wide Web)的信息组织方式。
- HTML通过预定义的<>…标签形式组织不同类型的信息。
3.三种信息标记形式
XML:Extensible Markup Language



JSON:JavaScript Object Notation
有类型的键值对key:value
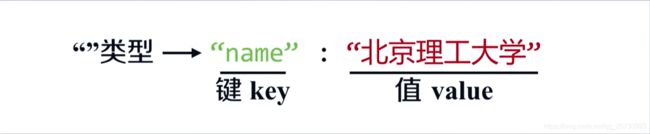


YAML:YAML Ain’t Markup Language
无类型键值对key:value

用缩进表示所属关系

-号表示值的并列关系


3.三种信息标记形式的比较
| 信息标记形式 | 表达式 | 描述 | 应用 |
|---|---|---|---|
| XML |  |
最早的通用信息标记语言,可拓展性好,但繁琐 | Internet上的信息交互与传递 |
| JSON |  |
信息有类型,适合程序处理(js),较XML简洁。 | 移动应用云端和节点的信息通信,无注释 |
| YAML |  |
信息无类型,文本信息比例最高,可读性好 | 各类系统的配置文件,有注释易读 |
4.信息提取的一般方法
| 方法 | 要求 | 优点 | 缺点 |
|---|---|---|---|
| 完整解析信息的标记形式,再提取关键信息 | 需要标记解析器,例如:bs4库的标签树遍历 | 信息解析准确 | 提取过程繁琐,速度慢 |
| 无视标记形式,直接搜索关键信息 | 对信息的文本查找函数即可 | 提取过程简洁,速度较快 | 提取结果准确性与信息内容无关 |
结合形式解析与搜索方法,提取关键信息
实例:
提取HTML页面中所有URL链接
思路:
1)搜索到所有标签
2)解析标签格式,提取href后的链接内容
import requests
from bs4 import BeautifulSoup
url = 'https://python123.io/ws/demo.html'
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
for link in soup.find_all("a"):
print(link.get("href"))
5.基于bs4库的HTML内容查找方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.soup.find_previous_siblings() | 在前续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.soup.find_previous_sibling() | 在前续平行节点中返回一个结果,字符串类型,同.find_all()参数 |
主要方法
<>.find_all(name, attrs, recursive, string, **kwargs)
返回一个列表类型,存储查找的结果。
name:对标签名称的检索字符串,返回列表格式。
对标签的检索:
print(soup.find_all('a'))
print(soup.find_all(['a', 'b']))
对True标签检索,则返回当前soup所有标签
print(soup.find_all(True))
对b开头的标签检索( ),需要导入正则表达式库(re库):
import re
print(soup.find_all(re.compile("b")))
attrs:对标签属性值的检索字符串,可标注属性检索。返回列表格式。
检索所有
标签中包含course字符串的所有信息:
print(soup.find_all('p', 'course'))
直接检索变钱属性中id=link1的信息:
print(soup.find_all(id='link1'))
直接检索变钱属性中id=link开头的信息,需要导入正则表达式库(re库):
print(soup.find_all(id=re.compile('link')))
recursive:是否对子孙全部检索,默认为True。值为False时,只对子元素进行检索。
检索当前soup的子元素是否有:
print(soup.find_all('a', recursive=False))
string:<>…中字符串区域的检索字符串。返回列表类型。
检索当前soup中所有只包含“Basic Python”字符串的域:
print(soup.find_all(string="Basic Python"))
检索当前soup中所有包含“python”字符串的域,需要导入正则表达式库(re库):
print(soup.find_all(string=re.compile('python')))
6.实例
“中国大学排名定向爬虫”实例
功能描述
输入:大学排名URL连接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests-bs4
定向爬虫:仅对输入URL进行爬取,不扩展爬取。
程序的设计结构
- 步骤1:从网络上获取大学排名网页内容(定义getHTMLText() )
- 步骤2:提取网页内容中信息到合适的数据结构(定义fillUnivList() )
- 步骤3:利用数据结构展示并输出结果(定义printUnivList() )
代码实现
import bs4
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except requests.HTTPError:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text, tds[1].text, tds[2].text])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2]))
def main():
uinfo = []
url = "http://zuihaodaxue.com/zuihaodaxuepaiming2019.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
if __name__ == '__main__':
main()
代码优化
输出结果中文字符对齐效果不好。
造成问题原因是:
输出的fomat()方法
| : | <填充> | <对齐> | <宽度> | , | <精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 | <左对齐,>右对齐,^居中对齐 | 槽的设定输出宽度 | 数字的前卫分隔符适用于整数和浮点数 | 浮点数小数部分的精度或字符串的最大输出长度 | 整数类型b,c,d,o,x,X浮点数类型e,E,f,% |
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
中文对齐问题的解决:
采用中文字符的空格填充chr(12288)
修改printUnivList()方法:
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" # 中间那个{3}指拿format()中下标为3(第四个)参数填充空格
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))