Android崩溃治理
目录
概述
现象描述
基本原理
面临的挑战
崩溃率的标准
崩溃的预防
提高代码的整洁性
网络层校验
经验的总结
崩溃的监控
基础SDK
线下检查
线上监控
输出
崩溃的处理
原则
Kotlin
Java常见崩溃
特定机型的崩溃处理
OOM
高级解决方案
总结
概述
现象描述
崩溃也叫闪退,指用户在操作手机APP时,APP突然退出的现象。退出之后还可能弹出停止运行对话框或者自动重启应用。一般会给用户造成极差的用户体验,可能引起用户卸载程序。如果是涉及重要业务流程的闪退,还可能引起行政或金钱方面的纠纷。
基本原理
JavaWeb程序在运行的过程中,只要还有其他线程运行,JVM虚拟机就不会关闭,进程就不会结束。但是在Android APP的运行过程中,不论是主线程、还是子线程、还是三方库的子线程,只要发生异常,就会引起应用崩溃。原因是JavaWeb程序中没有设置默认的线程异常处理器,而Android系统为每一个Android APP进程都设置了默认的线程异常处理器,源代码如下:
系统源码文件路径:android / platform / frameworks / base / jb-mr1-release / . / core / java / com / android / internal / os / RuntimeInit.java
1. public class RuntimeInit {
2. //其他代码
3. private static class UncaughtHandler implements Thread.UncaughtExceptionHandler {
4. public void uncaughtException(Thread t, Throwable e) {
5. try {
6. if (mCrashing) return;
7. mCrashing = true;
8. if (mApplicationObject == null) {
9. Slog.e(TAG, "*** FATAL EXCEPTION IN SYSTEM PROCESS: " + t.getName(), e);
10. } else {
11. Slog.e(TAG, "FATAL EXCEPTION: " + t.getName(), e);
12. }
13. // Bring up crash dialog, wait for it to be dismissed
14. ActivityManagerNative.getDefault().handleApplicationCrash(
15. mApplicationObject, new ApplicationErrorReport.CrashInfo(e));
16. } catch (Throwable t2) {
17. try {
18. Slog.e(TAG, "Error reporting crash", t2);
19. } catch (Throwable t3) {
20. // Even Slog.e() fails! Oh well.
21. }
22. } finally {
23. // Try everything to make sure this process goes away.
24. Process.killProcess(Process.myPid());
25. System.exit(10);
26. }
27. }
28. }
29. //其他代码
30. }
面临的挑战
下面是某款应用来自于友盟的崩溃用户占全部活跃用户的比率:
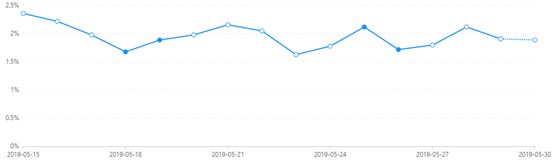
下面是目前的新增用户留存率:
留存率指的是新增用户第一次使用APP后,一段时间后第二次使用APP的比率

降低崩溃率对提高留存有很大作用。
崩溃率的标准
听云提出的移动应用崩溃率标准:
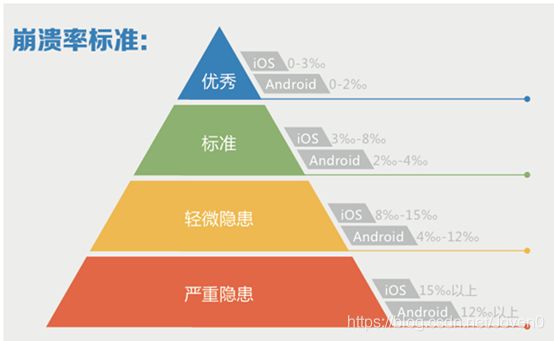
建议第一步先把崩溃率降低到5‰以下
崩溃的预防
提高代码的整洁性
代码的整洁性指代码不重复,不过度省略,分割合理,易于查找和管理,可读性强,易于理解。
整洁的代码可以使代码的初始的编写者和后来的改进者思路更清晰,更不容易忘掉一些细节,从而减少代码抛异常和出错的概率。整洁的代码可以使阅读和改进代码者心情愉悦,从而减少在高强度高压力困倦的时候写代码造成的疏漏。
编写代码的难度,取决于周边代码的阅读难度。阅读之前代码与书写新的代码,花费的时间比例超过10:1。想要快速实现需求,想要快速完成任务,想要轻松的写代码,请先让你书写的代码整洁易读。
具体提高代码整洁性的措施如下:
1.写完一段代码或者一个方法后,在Android Studio中按下快捷键Ctrl + Alt + L,可以自动格式化整个文件的代码,按下快捷键Ctrl + Alt + O可以快速排序和整理import语句,每一页源代码都尽量做到右上角打对勾,即No problems found
2.每一个方法尽量限制在100行以内,每个文件尽量限制在1000行以内,每行代码宽度最好在编辑器的控制线左边,超出的语句可以在表达式逗号或点号处换行。
3.初期可以参考《阿里巴巴Android开发手册》《阿里巴巴Java开发手册》PDF,后期可以结合实际情况制定一套自己的规范
网络层校验
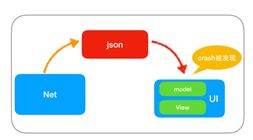
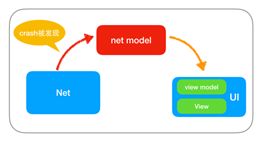
客户端的很大一部分的崩溃是因为网络接口API返回的脏数据。比如当API返回空值、空数组或返回不是约定类型的数据,App收到这些数据,就极有可能发生空指针、数组越界和类型转换错误等崩溃。而且这样的脏数据,特别容易引起线上大面积的崩溃。虽然经过完善的开发和测试,服务器API的数据大改的可能性不大,但预防的工作还是有必要做。建议之后可以专门做一期网络层优化,在网络层校验网络接口返回的数据有效性,并将Model层,分成NetModel和ViewModel两层,如下图所示:
经验的总结
当每一次版本迭代修复一些线上异常后,要及时进行总结归纳,结合网络上的技术资源,找到根本原因和深层次规律,总结成团队技术博客或小提示,以尽量减少同类问题的再次发生
崩溃的监控
目前APP内集成的通付盾和友盟统计都含有部分崩溃统计的功能,但他们都不是专业的崩溃统计供应商,短期可以满足使用要求,长期建议逐步形成以下的崩溃防控体系:
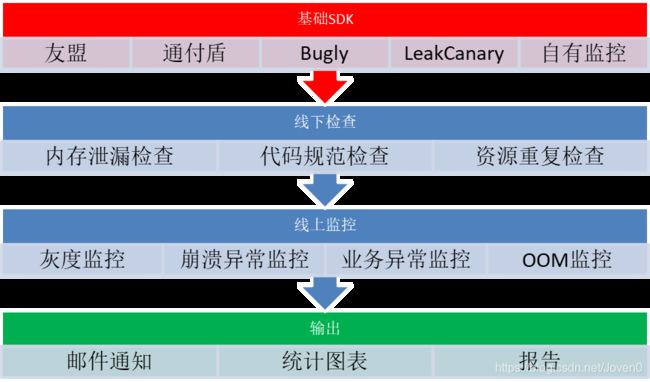
基础SDK
友盟统计主要擅长提供详尽的App运营的统计数据,功能强大,数据统计及时可靠,是国内小APP开发商主要使用的统计工具,它的崩溃统计功能只包含错误趋势,错误列表和错误详情。
通付盾是第三方安全监控工具,主要用于安全漏洞检测,恶意代码检测,内容违规检测和安全修复建议,其中也包含部分崩溃统计的功能,但是详尽度不如友盟。
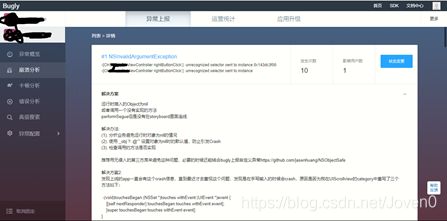
Bugly是腾讯公司内部崩溃统计框架产品化的产物,它的初衷就是为移动开发者提供专业的异常上报功能,除了包含友盟的所有功能,还包括根据错误堆栈直接搜索相应文档,匹配解决方案的功能和更详细的崩溃统计图表:
LeakCanary:是用于检测Android和Java内存泄漏的开源库,集成此库后在页面中检测到内存泄漏后,会自动弹出造成内存泄漏的相关的对象的信息,如下:
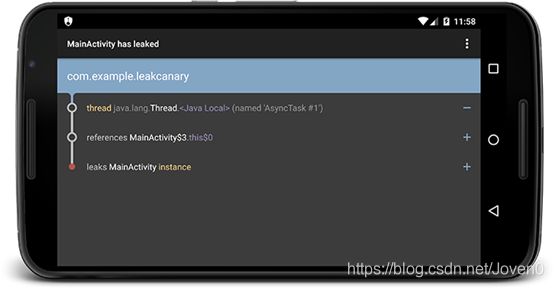
可以用于发布前的内存检查,也可以修改源码实现内存泄漏定时检测和上报的功能。
自有监控SDK:就是自己开发一套崩溃处理的框架,可以实现一些补充的崩溃处理功能,如自动业务降级(应用入口关闭),测试期间错误堆栈直接在APP上显示(类似React Native的错误红屏)等功能。
线下检查
内存泄漏检查:利用LeakCanary即可完成
代码规范检查:Android Studio自带Lint工具,可以对代码执行规范检查。
资源重复检查:可以写脚本或利用现有工具检查图片文件中是否有不同名但内容相同的文件,或者未被程序引用的图片。
线上监控
灰度监控:灰度指的是只发版到部分用户。我们可以尝试多种维度的灰度发布如:分渠道灰度,新装用户灰度,分杭州内和杭州外用户灰度等办法。灰度阶段是增量崩溃最容易暴露的阶段,如果这个阶段没有很好的把握住,会使得增量变存量,从而导致崩溃率上升。
崩溃异常监控:就是普通的应用崩溃时记录代码抛出的Exception信息,并在合适的时机上报,友盟和Bugly都已包含此功能。
业务异常监控:这部分需要结合现有的代码埋点和无痕埋点的统计信息,结合具体业务功能进行分析。
OOM监控:OOM指的是OutOfMemoryError的简称,即当前应用所占用的内存超过系统对每一个应用的内存占用限制,机型不同,限制不同,比如我手头的OPPO A37f手机的限制是256M。OOM的错误和普通的Exception异常一样也会被友盟之类的统计框架上报,之所以单独列出来是因为它发生时的崩溃堆栈信息往往不是导致问题的根本原因,而只是压死骆驼的最后一根稻草。
输出
邮件通知:友盟,通付盾和Bugly都自带邮件通知,打开设置即可,可以设置崩溃率超过多少的时候发邮件。
统计图表:即友盟或Bugly提供的后台数据查看页面,有多个维度的统计图表以网页方式呈现
报告:可以每月或季度出一份崩溃方面的报告,或者合并到其他App整体的报告中。
崩溃的处理
原则
对于崩溃的治理,我们尽量遵守以下三点原则:
- 由点到面。一个崩溃发生了,我们不能只针对这个崩溃去解决,而要去考虑这一类崩溃怎么去解决和预防。只有这样才能使得这一类崩溃真正被解决。
- 异常不能随便吃掉。随意的使用try-catch,只会增加业务的分支和隐蔽真正的问题,要了解崩溃的本质原因,根据本质原因去解决。崩溃的分支,更要根据业务场景去兜底,保证后续的流程正常。
- 预防胜于治理。当崩溃发生的时候,损失已经造成了,我们再怎么治理也只是减少损失。尽可能的提前预防崩溃的发生,可以将崩溃消灭在萌芽阶段。
Kotlin
目前Android端APP已大部分采用Kotlin语言来替代原来的Java语言,Kotlin有着诸多的特性,比如空指针安全、方法扩展、支持函数式编程、丰富的语法糖等。这些特性使得Kotlin的代码比Java简洁优雅许多,提高了代码的可读性和可维护性,节省了开发时间,提高了开发效率。但是在实际的使用过程中,我们发现看似写法简单的Kotlin代码,可能隐藏着不容忽视的崩溃问题。
Kotlin提供了非空断言运算符(!!)将任何值转换为非空类型,若该值为空则抛出异常。抛出异常如果不catch掉则会导致程序崩溃,目前程序里大量使用了非空断言如下图所示,虽然大部分本地API和网络接口并不会返回空对象,但是这种语法就像地雷,不一定什么情况什么时间就会碰到一次,所以有时候应该尽量避免此种写法。
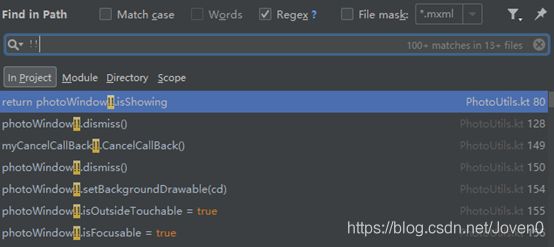
Java常见崩溃
常见的崩溃类型包括:空指针、角标越界、类型转换异常、实体对象没有序列化、数字转换异常、Activity或Service找不到等。这类崩溃是App中最为常见的崩溃,也是最容易反复出现的。在获取崩溃堆栈信息后,解决这类崩溃一般比较简单,更多考虑的应该是如何避免。下面介绍一个量比较大的崩溃。
NullPointerException
NullPointerException是我们遇到最频繁的,造成这种崩溃一般有两种情况:
- 对象本身没有进行初始化就进行操作。
- 对象已经初始化过,但是被回收或者手动置为null,然后对其进行操作。
针对第一种情况导致的原因有很多,可能是开发人员的失误、API返回数据解析异常、进程被杀死后静态变量没初始化导致,我们可以做的有:
- 对可能为空的对象做判空处理。
- 养成使用@NonNull和@Nullable注解的习惯。
- 尽量不使用静态变量,万不得已使用SharedPreferences来存储。
- 考虑使用Kotlin语言。
针对第二种情况大部分是由于Activity/Fragment销毁或被移除后,在Message、Runnable、网络等回调中执行了一些代码导致的,我们可以做的有:
- Message、Runnable回调时,判断Activity/Fragment是否销毁或被移除;加try-catch保护;Activity/Fragment销毁时移除所有已发送的Runnable。
- 封装LifecycleMessage/Runnable基础组件,并自定义Lint检查,提示使用封装好的基础组件。
- 在BaseActivity、BaseFragment的onDestory()里把当前Activity所发的所有请求取消掉。
特定机型的崩溃处理
众所周知,Android的机型众多,碎片化严重,各个硬件厂商可能会定制自己的ROM,更改系统方法,导致特定机型的崩溃。发现这类崩溃,主要靠云测平台配合自动化测试,以及线上监控,这种情况下的崩溃堆栈信息很难直接定位问题。下面是常见的解决思路:
- 尝试找到造成崩溃的可疑代码,看是否是特殊的API或者调用方式不当导致的,尝试修改代码逻辑来进行规避。
- 通过Hook来解决,Hook分为Java Hook和Native Hook。Java Hook主要靠反射或者动态代理来更改相应API的行为,需要尝试找到可以Hook的点,一般Hook的点多为静态变量,同时需要注意Android不同版本的API,类名、方法名和成员变量名都可能不一样,所以要做好兼容工作;Native Hook原理上是用更改后的方法把旧方法在内存地址上进行替换,需要考虑到Dalvik和ART的差异;相对来说Native Hook的兼容性更差一点,所以用Native Hook的时候需要配合降级策略。
- 如果通过前两种方式都无法解决的话,我们只能尝试反编译ROM,寻找解决的办法。
OOM
导致OOM的原因大部分如下:
- 内存泄漏,大量无用对象没有被及时回收导致后续申请内存失败。
- 大内存对象过多,最常见的大对象就是Bitmap,几个大图同时加载很容易触发OOM。
内存泄漏
内存泄漏指系统未能及时释放已经不再使用的内存对象,一般是由错误的程序代码逻辑引起的。在Android平台上,最常见也是最严重的内存泄漏就是Activity对象泄漏。Activity承载了App的整个界面功能,Activity的泄漏同时也意味着它持有的大量资源对象都无法被回收,极其容易造成OOM。
常见的可能会造成Activity泄漏的原因有:
- 匿名内部类实现Handler处理消息,可能导致隐式持有的Activity对象无法回收。
- Activity和Context对象被混淆和滥用,在许多只需要Application Context而不需要使用Activity对象的地方使用了Activity对象,比如注册各类Receiver、计算屏幕密度等等。
- View对象处理不当,使用Activity的LayoutInflater创建的View自身持有的Context对象其实就是Activity,这点经常被忽略,在自己实现View重用等场景下也会导致Activity泄漏。
对于Activity泄漏,目前已经有了一个非常好用的检测工具:LeakCanary,它可以自动检测到所有Activity的泄漏情况,并且在发生泄漏时给出十分友好的界面提示,同时为了防止开发人员的疏漏,我们也会将其上报到服务器,统一检查解决。另外我们可以在debug下使用StrictMode来检查Activity的泄露、Closeable对象没有被关闭等问题。
大对象
在Android平台上,我们分析任一应用的内存信息,几乎都可以得出同样的结论:占用内存最多的对象大都是Bitmap对象。随着手机屏幕尺寸越来越大,屏幕分辨率也越来越高,1080p和更高的2k屏已经占了大半份额,为了达到更好的视觉效果,我们往往需要使用大量高清图片,同时也为OOM埋下了祸根。
解决图片占用内存过大问题的思路主要是:
- 根据实际需要,也就是View尺寸来加载缩放后的图片,可以在分辨率较低的机型上尽可能少地占用内存。
- 另外也可以在服务端进行图片缩放处理,从而减轻客户端的内存压力。
对于图片内存优化,可以专门做一期迭代,首先进行内存占用分析工作,在各种操作情况下,通过Android Studio自带的Memory Profiler,堆转储和分配跟踪器等内存分析工具,找出具体的大对象根源,在结合实际,不对业务和稳定性造成太大影响的情况下修改相关逻辑。
高级解决方案
高级解决方案需要大块时间和对特定领域知识的钻研,建议之后落实
自定义Lint
Lint是Google提供的Android静态代码检查工具,可以扫描并发现代码中潜在的问题,提醒开发人员及早修正,提高代码质量。但是Android原生提供的Lint规则远远不够,缺少一些必要的检测,如一些Kotlin方面的检测,也不能检查代码规范。因此我们需要开发自定义Lint,目前我们通过自定义Lint规则已经实现了Crash预防、Bug预防、提升性能/安全和代码规范检查这些功能。如检查实现了Serializable接口的类,其成员变量(包括从父类继承的)所声明的类型都要实现Serializable接口,可以有效的避免NotSerializableException;强制使用封装好的工具类如ColorUtil、WindowUtil等可以有效的避免因为参数不正确产生的IllegalArgumentException和因为Activity已经finish导致的BadTokenException。
AOP增强辅助
AOP是面向切面编程的简称,在Android的Gradle插件1.5.0中新增了Transform API之后,编译时修改字节码来实现AOP也因为有了官方支持而变得非常方便。
在一些特定情况下,可以通过AOP的方式自动处理未捕获的异常:
- 抛异常的方法非常明确,调用方式比较固定。
- 异常处理方式比较统一。
- 和业务逻辑无关,即自动处理异常后不会影响正常的业务逻辑。典型的例子有读取Intent Extras参数、读取SharedPreferences、解析颜色字符串值和显示隐藏Window等等。
这类问题的解决原理大致相同,我们以Intent Extras为例详细介绍一下。读取Intent Extras的问题在于我们非常常用的方法 Intent#getStringExtra 在代码逻辑出错或者恶意攻击的情况下可能会抛出ClassNotFoundException异常,而我们平时在写代码时又不太可能给所有调用都加上try-catch语句,于是一个更安全的Intent工具类应运而生,理论上只要所有人都使用这个工具类来访问Intent Extras参数就可以防止此类型的Crash。但是面对庞大的旧代码仓库和诸多的业务,修改现有代码需要极大成本,还有更多的外部依赖SDK基本不可能使用我们自己的工具类,此时就需要AOP大展身手了。
我们可以专门制作一个Gradle插件,只需要配置一下参数就可以将某个特定方法的调用替换成另一个方法:
- WaimaiBytecodeManipulator {
- replacements(
- "android/content/Intent.getIntExtra(Ljava/lang/String;I)I=com/waimai/IntentUtil.getInt(Landroid/content/Intent;Ljava/lang/String;I)I",
- "android/content/Intent.getStringExtra(Ljava/lang/String;)Ljava/lang/String;=com/waimai/IntentUtil.getString(Landroid/content/Intent;Ljava/lang/String;)Ljava/lang/String;",
- "android/content/Intent.getBooleanExtra(Ljava/lang/String;Z)Z=com/waimai/IntentUtil.getBoolean(Landroid/content/Intent;Ljava/lang/String;Z)Z", ...)
- }
- }
上面的配置就可以将App代码(包括第三方库)里所有的Intent.getXXXExtra调用替换成IntentUtil类中的安全版实现。当然,并不是所有的异常都只需要catch住就万事大吉,如果真的有逻辑错误肯定需要在开发和测试阶段及时暴露出来,所以在IntentUtil中会对App的运行环境做判断,Debug下会将异常直接抛出,开发同学可以根据Crash堆栈分析问题,Release环境下则在捕获到异常时返回对应的默认值然后将异常上报到服务器。
总结
可以近期落实的有:
代码的整洁性:
崩溃监控中的Bugly和LeakCanary
崩溃处理原则
Kotlin
Java崩溃
其他建议单独成块优化:
针对OOM及相关内容可以单独做一期性能和内存优化
网络层可以单独做为一块内容
Gradle插件(AOP增强辅助)可以和Gradle配置优化单独做为一块内容
资源,图片,Drawable对象的优化可以单独做为一块内容
Lint自定义可以单独做为一块内容
参考:
1.《Android App为什么发生异常会导致应用崩溃,进程结束》
2.《友盟统计》
3.《app的崩溃率标准,优秀,合格,轻微隐患,严重隐患》
4.《【《代码整洁之道》精读与演绎】之一 让代码比你来时更干净》
5.《美团外卖Android Crash治理之路》
6.《Kotlin中文网——空安全》