poj Shortest Prefixes Babelfish 字典树的学习
字典树
/*转载
一:概念
下面我们有and,as,at,cn,com这些关键词,那么如何构建trie树呢?
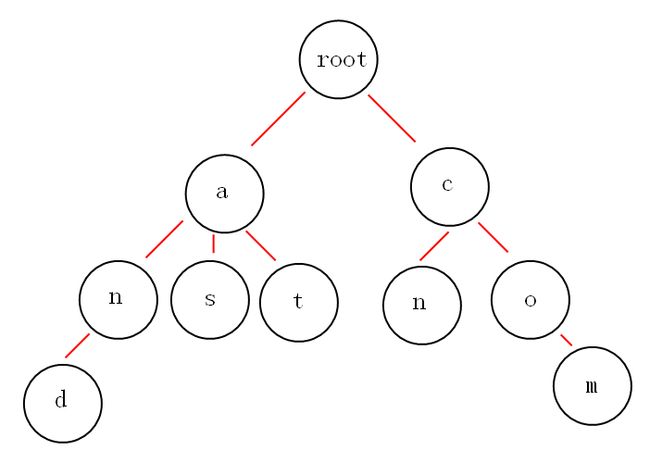
从上面的图中,我们或多或少的可以发现一些好玩的特性。
第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
第三:每个单词的公共前缀作为一个字符节点保存。
二:使用范围
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么
玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,
你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,
可以说这是秒杀的效果。
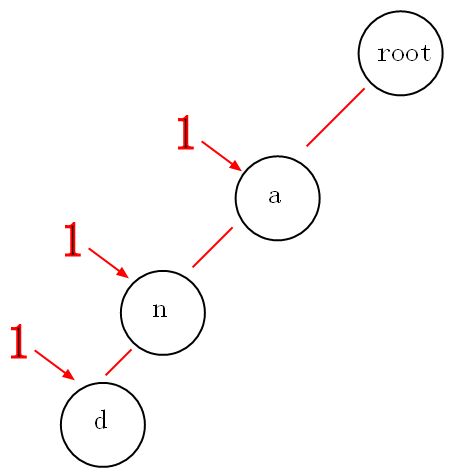
举个例子:现有一个编号为1的字符串”and“,我们要插入到trie树中,采用动态规划的思想,将编号”1“计入到每个途径的节点中,
那么以后我们要找”a“,”an“,”and"为前缀的字符串的编号将会轻而易举。
我们就用实例来学习字典树吧!
首先看一看这一个字典树的基本题目
|
Shortest Prefixes
Description
A prefix of a string is a substring starting at the beginning of the given string. The prefixes of "carbon" are: "c", "ca", "car", "carb", "carbo", and "carbon". Note that the empty string is not considered a prefix in this problem, but every non-empty string is considered to be a prefix of itself. In everyday language, we tend to abbreviate words by prefixes. For example, "carbohydrate" is commonly abbreviated by "carb". In this problem, given a set of words, you will find for each word the shortest prefix that uniquely identifies the word it represents.
In the sample input below, "carbohydrate" can be abbreviated to "carboh", but it cannot be abbreviated to "carbo" (or anything shorter) because there are other words in the list that begin with "carbo". An exact match will override a prefix match. For example, the prefix "car" matches the given word "car" exactly. Therefore, it is understood without ambiguity that "car" is an abbreviation for "car" , not for "carriage" or any of the other words in the list that begins with "car". Input
The input contains at least two, but no more than 1000 lines. Each line contains one word consisting of 1 to 20 lower case letters.
Output
The output contains the same number of lines as the input. Each line of the output contains the word from the corresponding line of the input, followed by one blank space, and the shortest prefix that uniquely (without ambiguity) identifies this word.
Sample Input carbohydrate cart carburetor caramel caribou carbonic cartilage carbon carriage carton car carbonate Sample Output carbohydrate carboh cart cart carburetor carbu caramel cara caribou cari carbonic carboni cartilage carti carbon carbon carriage carr carton carto car car carbonate carbona Source
Rocky Mountain 2004
|
大意是:找出能唯一标示一个字符串的最短前缀,如果找不出,就输出该字符串
这一看就是典型的字典树了。
代码如下:
#include
#include
#include
#include
using namespace std;
typedef char element;
typedef struct DicTrie
{
char g;
DicTrie *next[26];
int cnt;
}*Trie;
void Create( char *str, Trie T )
{
int i;
int id;
while ( *str )
{
id = str[0]-'a';
if ( T->next[id] == NULL )
{
T->next[id] = new DicTrie;
for ( i = 0; i < 26; i++ )
{
T->next[id]->next[i] = NULL;
}
T->next[id]->cnt = 1;
T->next[id]->g = str[0];
T = T->next[id];
str++;
}
else
{
T->next[id]->cnt++;
T = T->next[id];
str++;
}
}
}
char* Search( char *str, Trie T )
{
int id;
char s[25];
int i = 0;
while ( *str )
{
if ( T->cnt != 1 )
{
id = str[0]-'a';
s[i++] = str[0];
T = T->next[id];
str++;
}
else
{
s[i] = '\0';
return s;
}
}
s[i] = '\0';
return s;
}
int main()
{
char str[1002][25];
Trie T;
int i, j;
T = new DicTrie;
for ( i = 0;i < 26; i++ )
{
T->next[i] = NULL;
}
i = 0;
while ( gets(str[i]) && str[i][0] != 0 )
{
Create( str[i], T );
i++;
}
for ( j = 0;j < i; j++ )
{
char *str1 = Search( str[j], T );
printf ( "%s %s\n", str[j], str1 );
}
}
然后我们再来看一看另一个可以用字典树的题目吧!
| Time Limit: 3000MS | Memory Limit: 65536K | |
| Total Submissions: 40985 | Accepted: 17467 |
Description
Input
Output
Sample Input
dog ogday cat atcay pig igpay froot ootfray loops oopslay atcay ittenkay oopslay
Sample Output
cat eh loops
Hint
题意是
输入一个字典,字典格式为“英语à外语”的一一映射关系
然后输入若干个外语单词,输出他们的 英语翻译单词,如果字典中不存在这个单词,则输出“eh”
其实就用简单的map函数就可以直接用了,map好像是1900MS左右,hash我用的是大约在1600MS左右,而这题如果用字典树就会控制在700MS左右,是不是很快啊!就让我们看一下代码吧!
Memory: 17368K Time: 735MS
Language: G++ Result: Accepted
Source Code
#include
#include
#include
#include
using namespace std;
typedef struct DicTrie
{
struct DicTrie *next[26];
char word[11];
int isWord;
}*Trie;
void insertWord( Trie node, char *stc, char *str )
{
int id, i;
while ( *str )
{
id = *str-'a';
if ( node->next[id] == NULL )
{
node->next[id] = new DicTrie;
node->next[id]->isWord = 0;
for ( i = 0;i < 26; i++ )
{
node->next[id]->next[i] = NULL;
}
}
node = node->next[id];
str++;
}
node->isWord = 1;
strcpy( node->word, stc );
}
char* SearchWord(Trie node,char* st)
{
int id;
while(*st)
{
id=*st-'a';
if(node->next[id]==NULL)
{
return "eh";
}
node=node->next[id];
st++;
}
if(node->isWord)
{
return node->word;
}
else
{
return "eh";
}
}
int main()
{
int i;
char stc[11], str[11], st[25];
Trie node;
node = new DicTrie;
node->isWord = 0;
for ( i = 0;i < 26; i++ )
{
node->next[i] = NULL;
}
while ( gets(st) && st[0] != 0)
{
sscanf ( st,"%s %s", stc, str) ;
insertWord(node, stc, str);
}
while ( ~scanf ( "%s", st ) )
{
char *sum = SearchWord(node, st);
printf ( "%s\n" ,sum );
}
} 代码菜鸟,如有错误,请多包涵 !!!
如果有帮助记得支持我一下,谢谢!!!