本文译自《Diving into Apache Spark Streaming’s Execution Model》,作者: Tathagata Das, Matei Zaharia , Patrick Wendell 发布于 ENGINEERING BLOGJuly 30, 2015
有了这么多的分布式流处理引擎,人们经常问我们Apache Spark Streaming的独特优点。从早期开始,Apache Spark提供了一个统一的引擎,原生支持批处理和流工作负载。这不同于其他系统,其具有仅设计用于流的处理引擎,或者具有类似的批处理和流API,但是在内部编译到不同的引擎。 Spark的单执行引擎和统一的批处理和流式编程模型比其他传统的流系统带来了一些独特的优势。特别是,四个主要方面是:
- 从故障和分离器快速恢复
- 更好的负载平衡和资源使用
- 结合流数据与静态数据集和交互式查询
- 与高级处理库的本地集成(SQL,机器学习,图形处理)
在这篇文章中,我们概述了Spark Streaming的架构,并解释它如何提供上述好处。我们还讨论了项目中利用执行模型的一些有趣的正在进行的工作。
Stream Processing Architectures – The Old and the New
在高级别,现代分布式流处理流水线执行如下:
- 从数据源(例如活日志,系统遥测数据,IoT设备数据等)接收流数据到像Apache Kafka,Amazon Kinesis等一些数据摄取系统。
- 在集群上并行处理数据。 这是流处理引擎设计的目的,我们将在下面详细讨论。
- 将结果输出到下游系统,如HBase,Cassandra,Kafka等。
为了处理数据,大多数传统的流处理系统设计有连续的运算符模型,其工作如下:
- 有一组工作节点,每个节点运行一个或多个连续运算符。
- 每个连续运算符一次处理流数据一个记录,并将该记录转发到流水线中的其他运算符。
- 存在用于从摄取系统接收数据的“源”运算符和输出到下游系统的“sink”运算符。

连续运算符是一个简单而自然的模型。然而,随着当今趋向于更大规模和更复杂的实时分析,这种传统架构也遇到了一些挑战。我们设计Spark Streaming以满足以下要求:
- 快速故障和分段恢复 - 随着规模的增大,集群节点出现故障或不可预测的减速(即分段)的可能性更高。系统必须能够自动从故障和分离器中恢复,以实时提供结果。不幸的是,连续运算符到工作节点的静态分配使得传统系统很难从故障和分离器中恢复。
- 负载平衡 - 工人之间处理负载的不均匀分配可能导致连续运营商系统中的瓶颈。这更可能发生在大型集群和动态变化的工作负载中。系统需要能够基于工作负载动态地调整资源分配。
- 流式处理,批处理和交互式工作负载的统一 - 在许多使用情况下,以交互方式查询流式数据(毕竟流式处理系统在内存中拥有所有内容)或将其与静态数据集(例如预先计算楷模)。这在连续运营商系统中是困难的,因为它们不被设计为动态地引入用于ad-hoc查询的新运营商。这需要一个可以组合批量,流式和交互式查询的引擎。
- 高级分析(如机器学习和SQL查询) - 更复杂的工作负载需要不断学习和更新数据模型,甚至可以使用SQL查询查询流式数据的“最新”视图。同样,在这些分析任务之间有一个共同的抽象,使开发人员的工作更容易。
为了满足这些要求,Spark Streaming使用一种称为离散化流的新架构,它直接利用Spark引擎的丰富库和容错。
Architecture of Spark Streaming: Discretized Streams
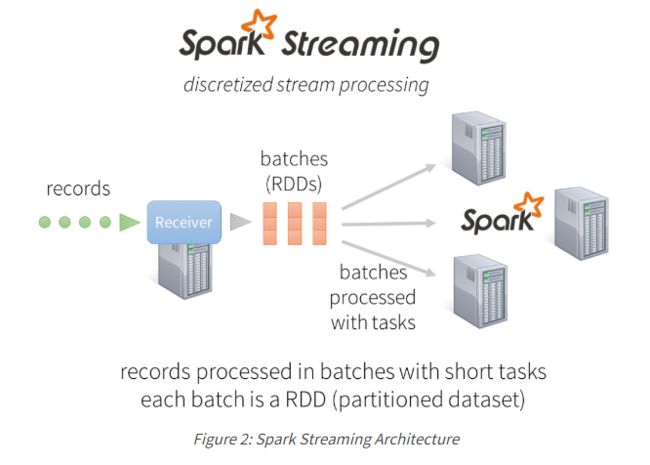
Spark Streaming不是一次处理流数据一条记录,而是将流数据离散化成微小的亚秒级微批次。 换句话说,Spark Streaming的接收器并行接受数据并将其缓存在Spark的工作节点的内存中。 然后,延迟优化的Spark引擎运行短任务(几十毫秒)来处理批次并将结果输出到其他系统。 注意,与传统的连续运算符模型不同,其中计算被静态地分配给一个节点,Spark任务根据数据的位置和可用资源被动态地分配给工作者。 这可以实现更好的负载平衡和更快的故障恢复,我们将在下面说明。
此外,每批数据是弹性分布式数据集(RDD),它是Spark中容错数据集的基本抽象。 这允许使用任何Spark代码或库处理流数据。
Benefits of Discretized Stream Processing
让我们看看这个架构如何允许Spark Streaming实现我们之前设置的目标。
Dynamic load balancing
将数据划分为小的微批次允许对资源的计算的细粒度分配。 例如,考虑一个简单的工作负载,其中输入数据流需要通过密钥进行分区和处理。 在大多数其他系统采用的传统的一次记录方法中,如果其中一个分区比其他分区的计算密集程度更高,则静态分配以处理该分区的节点将成为瓶颈并减慢管道。 在Spark Streaming中,作业的任务将自然地在工作负载之间平衡负载 - 一些工作负载将处理几个更长的任务,另一些工作将处理更多的更短任务。

Fast failure and straggler recovery
在节点故障的情况下,传统系统必须在另一个节点上重新启动故障的连续运算符,并重放数据流的某些部分以重新计算丢失的信息。 注意,只有一个节点正在处理重新计算,并且管道不能继续,直到新节点在重放之后赶上。 在Spark中,计算已经离散化为小的,确定性的任务,可以在任何地方运行而不影响正确性。 因此,故障任务可以在集群中的所有其他节点上并行重新启动,从而在所有节点上均匀分布所有重新计算,并且比传统方法更快地从故障中恢复。

Unification of batch, streaming and interactive analytics
Spark Streaming中的关键编程抽象是DStream或分布式流。 每批流数据由RDD表示,RDD是Spark对分布式数据集的概念。 因此,DStream只是一系列的RDD。 这种通用表示允许批处理和流工作负载无缝地互操作。 用户可以对每批流数据应用任意Spark函数:例如,很容易将DStream与预先计算的静态数据集(作为RDD)连接。
// Create data set from Hadoop file
val dataset = sparkContext.hadoopFile("file")
// Join each batch in stream with the dataset
kafkaDStream.transform { batchRDD =>
batchRDD.join(dataset).filter(...)
}
由于批处理的流数据存储在Spark的工作内存中,因此可以按需交互式查询。 例如,您可以通过Spark SQL JDBC服务器公开所有的流状态,我们将在下一节中显示。 Spark中批处理,流式处理和交互式工作负载的这种统一非常简单,但在没有这些工作负载的通用抽象的系统中很难实现。
Advanced analytics like machine learning and interactive SQL
Spark互操作性扩展到丰富的库,如MLlib(机器学习),SQL,DataFrames和GraphX。 让我们探讨一些用例:
Streaming + SQL and DataFrames
DStreams生成的RDD可以转换为DataFrames(Spark SQL的编程接口),并使用SQL查询。 例如,使用Spark SQL的JDBC服务器,您可以将流的状态公开给任何谈论SQL的外部应用程序。
val hiveContext = new HiveContext(sparkContext)
// ...
wordCountsDStream.foreachRDD { rdd =>
// Convert RDD to DataFrame and register it as a SQL table
val wordCountsDataFrame = rdd.toDF("word", "count")
wordCountsDataFrame.registerTempTable("word_counts")
}
// ...
// Start the JDBC server
HiveThriftServer2.startWithContext(hiveContext)
然后,您可以使用Spark附带的beeline客户端或Tableau等工具,通过JDBC服务器交互式查询不断更新的“word_counts”表。
show tables;
+--------------+--------------+
| tableName | isTemporary |
+--------------+--------------+
| word_counts | true |
+--------------+--------------+
1 row selected (0.102 seconds)
select * from word_counts;
+-----------+--------+
| word | count |
+-----------+--------+
| 2015 | 264 |
| PDT | 264 |
| 21:45:41 | 27 |
Streaming + MLlib
使用MLlib离线生成的机器学习模型可以应用于流数据。 例如,以下代码使用一些静态数据训练KMeans聚类模型,然后使用该模型对Kafka数据流中的事件进行分类。
// Learn model offline
val model = KMeans.train(dataset, ...)
// Apply model online on stream
val kafkaStream = KafkaUtils.createDStream(...)
kafkaStream.map { event => model.predict(featurize(event)) }
我们在我们的Spark Summit 2014 Databricks演示中演示了这种离线学习在线预测。 从那时起,我们还在MLLib中添加了流机器学习算法,可以从标记的数据流中连续训练。 其他Spark库也可以很容易地从Spark Streaming中调用。
Performance
鉴于Spark Streaming的独特设计,它运行速度有多快?实际上,Spark Streaming对批处理数据和利用Spark引擎的能力导致与其他流系统相当或更高的吞吐量。在延迟方面,Spark Streaming可以实现低至几百毫秒的延迟。开发人员有时会问,微批处理是否会增加太多的延迟。在实践中,批处理延迟只是端到端流水线延迟的一个小组件。例如,许多应用程序通过滑动窗口计算结果,并且甚至在连续的操作员系统中,该窗口仅周期性地更新(例如,每2秒滑动的20秒窗口)。许多管道从多个源收集记录,并等待短时间来处理延迟或乱序数据。最后,任何自动触发算法都倾向于等待一段时间来触发触发。因此,与端到端延迟相比,批处理很少增加显着的开销。事实上,DStream的吞吐量增益通常意味着您需要更少的机器来处理相同的工作负载。
Future Directions for Spark Streaming
Spark Streaming是Spark中使用最广泛的组件之一,而且流媒体用户还有更多的选择。我们团队正在处理的一些最重要的项目将在下面讨论。你可以期望这些在接下来的几个版本的Spark:
- 背压 - 流工作负载通常可以有突发数据(例如在奥斯卡期间tweet中的突然尖峰),并且处理系统必须能够优雅地处理它们。在即将到来的Spark 1.5版本(下个月)中,Spark将添加更好的反压机制,允许Spark Streaming动态控制此类突发的吞吐速率。此功能代表我们在Databricks和Typesafe的工程师之间的联合工作。
- 动态缩放 - 控制摄取速率可能不足以处理数据速率的较长期变化(例如白天夜间的持续较高的推特率)。可以通过基于处理需求动态地缩放集群资源来处理这样的变化。这在Spark Streaming架构中非常容易做到 - 由于计算已经分为小任务,如果从集群管理器(YARN,Mesos,Amazon EC2等)获取更多节点,它们可以动态重新分配到更大的集群, 。我们计划添加对自动动态缩放的支持。
- 事件时间和乱序数据 - 在实践中,用户有时会记录不按顺序传送,或者时间戳与提取时间不同。 Spark流将通过允许用户定义的时间提取功能支持“事件时间”。这将包括延迟或乱序数据的松弛持续时间。
- UI增强 - 最后,我们希望让开发人员轻松调试其流应用程序。为此,在Spark 1.4中,我们向流式Spark UI添加了新的可视化,使开发人员密切监视其应用程序的性能。在Spark 1.5中,我们通过显示更多输入信息(例如每个批处理中处理的Kafka偏移量)来进一步改进。
要了解有关Spark Streaming的更多信息,请阅读官方编程指南或介绍其执行和容错模型的Spark Streaming研究论文。
完。