翻译: https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_running_spark_on_yarn.html
版本: 5.14.2
在YARN上运行Spark应用程序
当Spark应用程序在YARN集群管理器上运行时,资源管理,调度和安全性由YARN控制。
继续阅读:
- 部署模式
- 配置环境
- 在YARN上运行Spark Shell应用程序
- 将Spark应用程序提交给YARN
- 监视和调试Spark应用程序
- 例如:在YARN上运行SparkPi
- 在YARN应用程序上配置Spark
- 动态分配
- 优化CDH部署中的YARN模式
部署模式
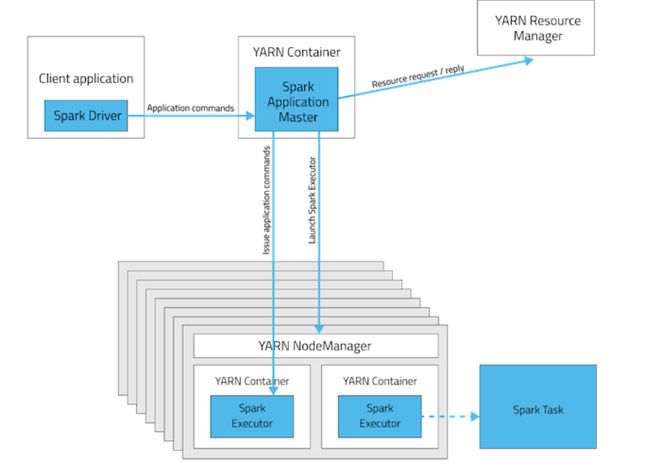
在YARN中,每个应用程序实例都有一个ApplicationMaster进程,该进程是为该应用程序启动的第一个容器。应用程序负责从ResourceManager请求资源。一旦分配了资源,应用程序将指示NodeManagers代表它启动容器。ApplicationMasters消除了对活动客户端的需求:客户端上启动应用程序的进程可以终止,YARN进行协作管理的进程继续进行。
有关指定部署模式的选项,请参阅spark-submit选项。
群集部署模式
在集群模式下,Spark驱动程序在集群主机上的ApplicationMaster中运行。YARN容器中的单个进程负责驱动应用程序并向YARN请求资源。启动应用程序的客户端不需要在应用程序的生命周期中运行。

集群模式不太适合交互式使用Spark。需要用户输入的Spark应用程序,例如 spark-shell and pyspark,需要Spark驱动程序在启动Spark应用程序的客户端进程中运行。
客户端部署模式
在客户端模式下,Spark驱动程序在提交作业的主机上运行。ApplicationMaster仅负责从YARN请求执行程序容器。容器启动后,客户端与容器通信以安排工作。
Deployment Mode Summary
| Mode | YARN客户端模式 | YARN集群模式 |
|---|---|---|
| Driver runs in | 客户 | ApplicationMaster |
| Requests resources | ApplicationMaster | ApplicationMaster |
| Starts executor processes | YARN NodeManager | YARN NodeManager |
| Persistent services | YARN ResourceManager和NodeManagers | YARN ResourceManager和NodeManagers |
| Supports Spark Shell | YES | No |
配置环境
Spark要求客户端配置文件包含 HADOOP_CONF_DIR or YARN_CONF_DIR 环境变量,指向集群目录。这些配置用于写入HDFS并连接到YARN ResourceManager。如果您使用Cloudera Manager部署,则会自动配置这些变量。如果您使用的是非托管部署,请确保按照在YARN上运行Spark中所述设置变量。
在YARN上运行Spark Shell应用程序
在YARN上使用运行spark-shell or pyspark ,使用 --master yarn --deploy-mode client 启动应用程序。
如果您正在使用Cloudera Manager部署,则会自动配置这些属性。
将Spark应用程序提交给YARN
要向YARN提交应用,请使用spark-submit,指定--master yarn 选项,请参阅spark-submit参数。
监视和调试Spark应用程序
要获取有关Spark应用程序行为的信息,可以参考YARN日志和Spark Web应用程序UI。这两种方法提供补充信息。有关如何查看由Spark应用程序和Spark Web应用程序UI创建的日志的信息,请参阅监控Spark应用程序。
例如:在YARN上运行SparkPi
这些例子演示了如何使用 spark-submit 用各种选项提交SparkPi Spark示例应用程序。在这些例子中,在JAR控制了逼近应该与pi接近多少之后通过的参数。
在CDH部署中,SPARK_HOME 默认为/usr/lib/spark 在包装安装和
在YARN集群模式下运行SparkPi
在集群模式下运行SparkPi:
- CDH 5.2和更低
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \
--deploy-mode cluster SPARK_HOME/examples/lib/spark-examples.jar 10
- CDH 5.3和更高
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \
--deploy-mode cluster SPARK_HOME/lib/spark-examples.jar 10
该命令会打印状态,直到作业完成或您按下control-C。终止spark-submit 集群模式下的进程不会像在客户端模式下那样终止Spark应用程序。要监视正在运行的应用程序的状态,请运行yarn application -list.
在YARN客户端模式下运行SparkPi
在客户端模式下run SparkPi:
- CDH 5.2和更低
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \
--deploy-mode client SPARK_HOME/examples/lib/spark-examples.jar 10
- CDH 5.3和更高
spark-submit --class org.apache.spark.examples.SparkPi --master yarn \
--deploy-mode client SPARK_HOME/lib/spark-examples.jar 10
在YARN集群模式下运行Python SparkPi
- 解压缩Python示例存档:
sudo su gunzip SPARK_HOME/lib/python.tar.gz
sudo su tar xvf SPARK_HOME/lib/python.tar
- run pi.py 文件:
spark-submit --master yarn --deploy-mode cluster SPARK_HOME/lib/pi.py 10
在YARN应用程序上配置Spark
除了spark-submit选项之外,在YARN上运行spark-submit的其他选项。
spark-submit on YARN Options
| 选项 | 描述 |
|---|---|
| archives | 逗号分隔的archives列表,被提取到每个执行者的工作目录中。对于 客户端部署模式,路径必须指向本地文件。对于集群部署模式,路径可以是本地文件,也可以是集群内全局可见的URL; 请参阅高级依赖关系管理。 |
| executor-cores | 每个执行器上分配的处理器内核数量。或者,您可以使用 spark.executor.cores 属性。 |
| executor-memory | 分配给每个执行程序的最大堆大小。或者,您可以使用spark.executor.memory 属性。 |
| num-executors | 为此应用程序分配的YARN容器总数。或者,您可以使用spark.executor.instances 属性。 |
| queue | 提交作业的YARN队列。有关更多信息,请参阅将应用程序和查询分配给资源池。默认: default。 |
在初始安装期间,Cloudera Manager根据您的群集环境调整属性。
除了命令行选项外,还提供以下属性:
| 属性 | 描述 |
|---|---|
| spark.yarn.driver.memoryOverhead | 每个驱动程序可以从YARN请求的额外off-heap 存储量。结合spark.driver.memory,这是YARN可用于为驱动程序进程创建JVM的总内存。 |
| spark.yarn.executor.memoryOverhead | 每个执行程序进程可从YARN请求的额外堆外存量。结合spark.executor.memory,这是YARN可用于为执行程序进程创建JVM的总内存。 |
动态分配
动态分配允许Spark根据工作负载动态扩展分配给应用程序的集群资源。当启用动态分配并且Spark应用程序有待处理任务的积压时,它可以请求执行程序。当应用程序空闲时,其执行程序将被释放并可被其他应用程序获取。
从CDH 5.5开始,默认启用动态分配。动态分配属性描述了控制动态分配的属性。
如果你设置spark.dynamicAllocation.enabled 为false 或使用 --num-executors 命令行参数或设置 spark.executor.instances 时,动态分配被禁用。有关动态分配如何工作的更多信息,请参阅资源分配策略。
当启用Spark动态资源分配时,所有资源都会分配给第一个可用的作业,导致后续应用程序排队。为了允许应用程序并行获取资源,将资源分配给池,在池中运行应用程序,并允许池中运行的应用程序被抢占。请参阅动态资源池。
如果您正在使用Spark Streaming,请参阅Spark Streaming和Dynamic Allocation中的建议。
动态分配属性

优化非 CM 部署CDH中的YARN模式
在不由Cloudera Manager管理的CDH部署中,Spark每次(spark-submit)运行时都会将Spark程序集JAR文件复制到HDFS 。您可以通过执行以下任一操作来避免此复制:
- 设置 spark.yarn.jar 为 JAR的本地路径:local:/usr/lib/spark/lib/spark-assembly.jar. 。
- 上传JAR并配置JAR位置:
- 手动将Spark程序集JAR文件上传到HDFS:
$ hdfs dfs -mkdir -p /user/spark/share/lib
$ hdfs dfs -put SPARK_HOME/assembly/lib/spark-assembly_*.jar /user/spark/share/lib/spark-assembly.jar
每次将Spark升级到新的 CDH版本时,您都必须手动上载JAR。
2. 设置spark.yarn.jar 为 HDFS路径:
spark.yarn.jar=hdfs://namenode:8020/user/spark/share/lib/spark-assembly.jar