深度学习第55讲:强化学习简介与Q-Learning实例
本节和下一节笔者将和大家来看一下强化学习(Reinforcement Learning)的相关内容。从整个机器学习的任务划分上来看,机器学习可以分为有监督学习、有监督和半监督学习以及强化学习,而我们之前一直谈论的图像、文本等深度学习的应用都属于监督学习范畴。自编码器和生成式对抗网络可以算在无监督深度学习范畴内。最后就只剩下强化学习了。但是我们这是深度学习的笔记,为什么要把强化学习单独拎出来讲一下呢?因为强化学习发展到现在,早已结合了神经网络迸发出新的活力,强化学习结合深度学习已经形成了深度强化学习(Deep Reinforcement Learning)这样的新领域,因为强化学习和深度学习之间的关系以及其本身作为人工智能的一个重要方向,我们都是有必要在系列笔记里体现一下的。
强化学习简介
强化学习是一种关于序列决策的工具,在许多领域都有研究,例如博弈论、控制论、运筹学、信息论、仿真优化、多主体系统学习、群体智能、统计学以及遗传算法等领域。具体而言就是描述决策主体如何基于环境而行动以获取收益最大化的问题。强化学习一个最著名的例子就是此前击败李世石和柯洁的 ALPHAGo,其实现下棋并战胜人类的背后原理技术就是深度强化学习。

本节笔者对强化学习技术做一个简短的概述,并给出一个典型的强化学习算法——Q-Learning的代码实例。下一节我们集中学习一下深度Q网络(Deep Q Network)。
强化学习跟此前的监督学习有着本质的区别:监督学习是训练模型由特征到标签的映射关系,而强化学习的学习过程却是一种从无到有的过程。简单来说,强化学习是让计算机实现从一开始什么都不懂,经过不断尝试和试错找到规律达到目的这样的一个过程。强化学习的主体与环境基于离散的时间步长相作用。在每一个时间 t,主体接收到一个观测Ot,通常其中包含奖励Rt。然后,它从允许的集合中选择一个动作At,然后送出到环境中去。环境则变化到一个新的状态 St+1,然后决定了和这个变化 (St,At,St+1)相关联的奖励Rt+1。强化学习主体的目标,是得到尽可能多的奖励。主体选择的动作是其历史的函数,它也可以选择随机的动作。可以看到状态(State)、动作(Action)和奖励(Reward)是强化学习的三个核心概念。

强化学习的模型和算法也有很多。我们把结合深度学习之前的算法可以称作传统的强化学习算法,比如 Q-Learning算法、Sarsa算法、Policy Gradients算法、蒙特卡洛树搜索等算法。另一种就是当下结合了深度学习的强化学习算法,其代表主要就是深度Q网络(DQN),以及结合神经网络之后的深度强化学习这一整个领域。
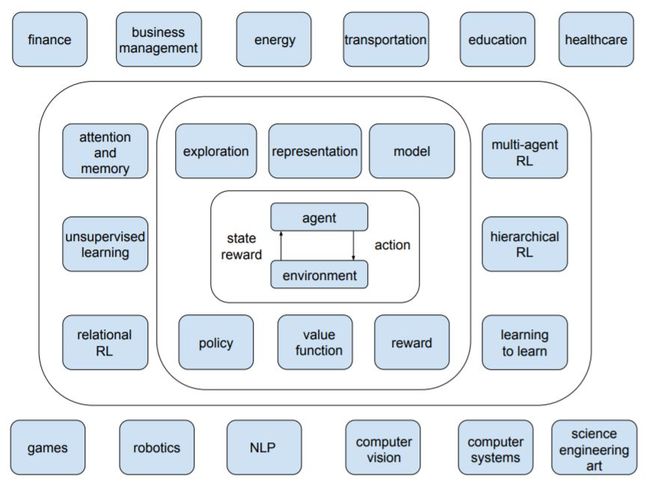
深度强化学习的核心框架:
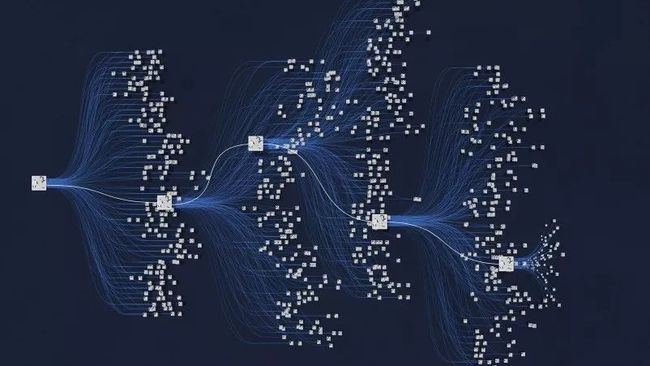
ALPHAGo背后的神经网络:
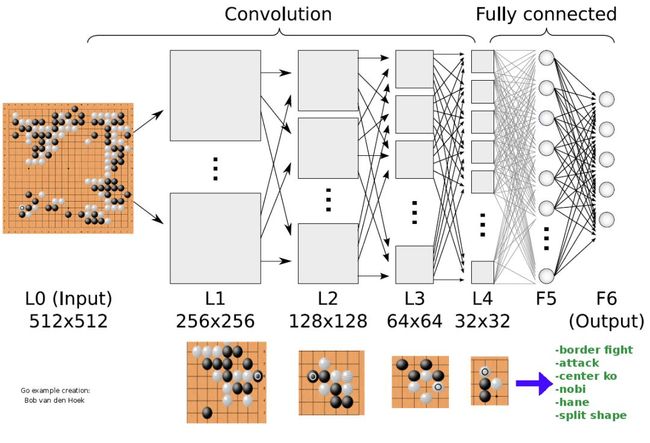
Q-Learning
作为强化学习很早期也很经典的一种算法,Q-Learning是一种基于值(Value Based)的算法。至于为什么叫 Q-Learning,是因为其本身是一种依靠 Q 函数来寻找最优的动作-状态决策的。关于 Q-Learning算法的细节和原理笔者这里不做详细描述,感兴趣的朋友可以直接研读相关论文:Watkins C J C H, Dayan P. Technical Note: Q-Learning[J]. Machine Learning, 1992, 8(3-4):279-292.
Q-Learning算法描述:

下面我们直接来看 Q-Learning 的代码实例。代码参考自:
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
导入相关模块并 预设参数值:
import numpy as np
import pandas as pd
import time
import warnings
warnings.filterwarnings('ignore')
# 状态宽度
N_STATES = 6
# 探索者的可用动作
ACTIONS = ['left', 'right']
# 贪心率
EPSILON = 0.9
# 学习率
ALPHA = 0.1
# 奖励递减值
GAMMA = 0.9
# 最大回合数
MAX_EPISODES = 13
# 移动间隔时间
FRESH_TIME = 0.3初始化 Q-Table:
def build_q_table(n_states, actions):
q_table = pd.DataFrame(np.zeros((n_states, len(actions))), columns=actions)
return q_table
q_table = build_q_table(N_STATES, ACTIONS)
q_table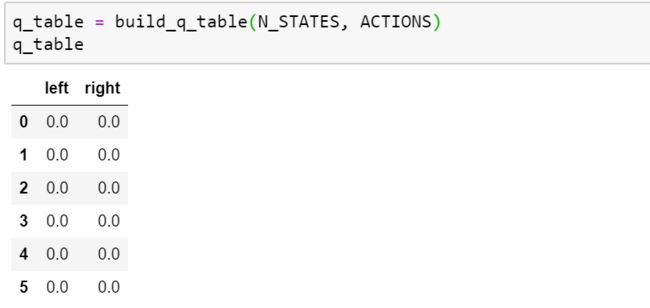 定义在某个状态地点State,选择行为Action:
定义在某个状态地点State,选择行为Action:
# 在某个 state 地点, 选择行为
def choose_action(state, q_table):
# 选出这个 state 的所有 action 值
state_actions = q_table.iloc[state, :]
# 非贪婪 or 或者这个 state 还没有探索过
if (np.random.uniform() > EPSILON) or (state_actions.all() == 0):
action_name = np.random.choice(ACTIONS)
else:
# 贪心策略
action_name = state_actions.argmax()
return action_name
choose_action(3, q_table)
定义环境反馈过程,以奖励R的形式给出:
# 定义环境反馈
def get_env_feedback(S, A):
# 主体与环境的交互过程
if A == 'right':
if S == N_STATES - 2:
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else:
R = 0
if S == 0:
S_ = S
else:
S_ = S - 1
return S_, R更新环境:
def update_env(S, episode, step_counter):
env_list = ['-']*(N_STATES-1) + ['T']
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)定义 Q-Learning训练过程:
def rl_process():
# 初始化 q table
q_table = build_q_table(N_STATES, ACTIONS)
# 回合
for episode in range(MAX_EPISODES):
step_counter = 0
# 回合初始位置
S = 0
# 是否回合结束
is_terminated = False
# 环境更新
update_env(S, episode, step_counter)
while not is_terminated:
A = choose_action(S, q_table) # 选行为
S_, R = get_env_feedback(S, A) # 实施行为并得到环境的反馈
q_predict = q_table.loc[S, A] # 估算的(状态-行为)值
if S_ != 'terminal':
# 实际的(状态-行为)值 (回合没结束)
q_target = R + GAMMA * q_table.iloc[S_, :].max()
else:
q_target = R
# 实际的(状态-行为)值 (回合结束)
is_terminated = True
# 更新 q_table
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # 探索者移动到下一个 state
S = S_
# 环境更新
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table运行程序并打印最终的 Q-Table:
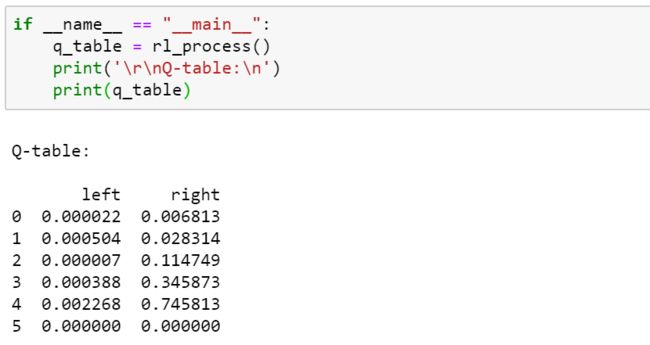
if __name__ == "__main__":
q_table = rl_process()
print('\r\nQ-table:\n')
print(q_table)结果如下:
参考资料:
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
DEEP REINFORCEMENT LEARNING
往期精彩:
一个数据科学从业者的学习历程


长按二维码.关注机器学习实验室
