SERF中去中心化系统的原理和实现
杨谕黔,FreeWheel基础架构部高级软件工程师。 目前主要从事服务化框架、容器化平台相关的研发与推广。关注和感兴趣的技术主要有Golang, Docker, Kubernetes等。
serf是出自Hashicorp的开源项目, 实现了去中心化的gossip(八卦)协议,其中gossip协议定义了一种类似病毒感染的消息传播过程。 一些著名的开源项目,如Docker和Consul,网络管理和服务发现的核心组件是基于serf实现的,然而它们背后的serf似乎还鲜为人知,一方面其复杂的理论以及不完善的文档让人望而却步;另一方面,gossip协议天然的数据弱一致性也制约了serf的使用场景。
本文希望从serf背后的分布式系统理论和部分源码实现出发,为项目中serf的使用带来一些启发,分为四个部分:
· serf初体验
· serf背后的分布式系统理论
· serf部分源码分析
· serf集群参数与调优
SERF初体验
serf提供了一种轻量级的方式来管理去中心化集群,并基于这个集群提供了UserEvent和Query等接口,处理一些用户层的事件,如服务发现、自动化部署等。本节通过具体的例子,介绍serf中的一些基本特性。
集群管理
基于serf搭建去中心化集群非常简单:在每个节点上启动serf agent,然后通过每个agent上的rpc接口(或使用serf命令行工具),就可以让agent快速建立连接并形成集群。
图1.1.1 启动独立的serf agent

图1.1.1 中启动了三个独立的serf agent,配置分别为:
Node |
Bind Address |
RPC Address |
node1 |
127.0.0.1:5001 |
127.0.0.1:7473 |
node2 |
127.0.0.1:5002 |
127.0.0.1:7474 |
node3 |
127.0.0.1:5003 |
127.0.0.1:7475 |
顺便提一下,agent启动时需要指定两个address,bind address和rpc address,分别提供集群间的通信接口和客户端操作集群的接口,serf默认采用UDP来广播gossip消息,因此在实际网络中部署时,需要为Bind Address配置相应的防火墙规则。另外还有一个advertise address,如果agent跑在容器等需要NAT的网络环境中时,可以使用advertise address对集群中其他节点暴露自己。
启动了serf agent之后,这些agent还没有建立集群,相互之间也没有通信,紧接着要做的是让这些agent连接起来成为一个集群,图1.1.1中启动了三个节点,接下来分两步让这三个节点建立连接,形成去中性化集群:
· node2 join node1 (如图1.1.2)
· node1 join node3 (如图1.1.3)
图1.1.2 node2 join node1

再次说明一下,rpc addr是客户端控制agent的接口,而bind addr才是集群间互相通信的接口,因此这里node2 join node1,实际上是通过node2的rpc接口告诉node2“join node1,它的bind address是127.0.0.1:5001”。
图1.1.3 node1 join node3

经过图1.1.2和1.1.3中的简单两步,我们就建立了node1,2,3间的去中心化集群,每个节点都维护了集群的状态信息。有人可能好奇集群中如果有节点挂掉,重启的话,其他节点能不能再次找到它呢?为了模拟这种故障重启的行为,图1.1.4中直接将node2进程kill掉。
图1.1.4 直接kill掉node2

很快集群中的节点就发现node2可能挂了,然后就开始了suspect的过程,大家互相传播了几次node2挂掉的“八卦消息”之后,就判定这个节点很可能真的挂了,就开始定期去尝试重新连接这个节点,让它重新加入集群。
图1.1.5 重新启动node2

图1.1.5中node2重启后,自动加入到集群中来了,集群对每个节点都抱着“不抛弃不放弃”的原则,每个节点都可能承担故障节点的恢复,整个集群不再依赖有限的几个master节点。
User Event和Query
UserEvent和Query是serf基于去中心化集群提供的高效消息封装。UserEvent是一些单向的不需要集群反馈的消息,而Query是双向的,需要集群给出反馈(QueryResponse)的消息。向集群发送消息可以针对任意节点进行,然后节点间可以互相传播这些消息。
serf中可以为Event和Query指定Handler,serf命令行中定义的Handler可以是任何一条shell命令,serf会将Event/Query的一些上下文以环境变量形式传入;如果在Go程序中引入serf API,也可以实现自定义的Handler,非常灵活。
图1.2.1 为node1,2,3指定不同的Event Handler,并建立节点之间的连接形成集群

图1.2.1中为node1,2,3分别指定了Event和Query的Handler和Tag来声明消息的广播范围
Node |
Tag |
Event Handler |
Query Handler |
node1 |
role=apiserver |
echo node1 >> node1.log |
echo hello,node1 |
node2 |
role=ui |
echo node2 >> node2.log |
echo hello,node2 |
node2 |
role=apiserver |
echo node3 >> node3.log |
echo hello,node3 |
图1.2.2中发送一个log Event,所有节点都会处理该Event,向对应的日志文件中写入一段文本

图1.2.3中向role=ui的节点发送一个Query,agent处理完消息之后将结果传回客户端
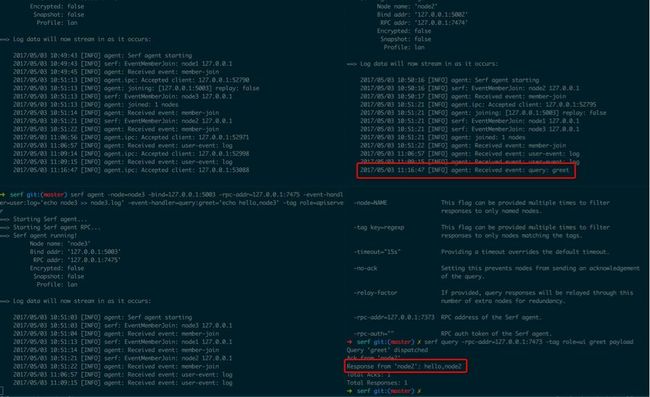
为了保证一般性,这里选择向集群中的node1发送该Query,而Query实际的处理节点是node2,最终可见返回的结果和日志中只有node2处理了该信息。
通过UserEvent/Query与Tag的组合,可以实现很多灵活的监控、日志收集和自动化运维工具。
小结
本节中的一些例子展示了serf的扩展性和Event、Query的使用场景,然而这些问题似乎在中心化的系统里也完全可以解决,那么去中心化集群的到底有什么优势让Docker和Consul选择用serf来实现其核心的服务发现和网络配置管理模块?
常见的中心化集群中,集群的状态是由有限的master节点维护的,通常使用heart-beat协议来更新和同步master和slave节点之间的状态和配置信息:
· master需要slave的heart-beat来维护slave的状态
· slave需要定时从master同步集群的配置变化
在集群规模较小时,去中心化集群与中心化集群相比并没有明显优势。
去中心化系统更多的是面向大规模分布式平台,当集群规模增加到数万甚至数十万节点时,主从模型的信息传播给节点和网络都会带来不小的负载,集群状态管理的效率和正确性也会随着规模的增大而下降,这就是为什么很多基于“主-从”模型的中心化系统都有集群规模的上限。
例如Kubernetes的集群规模上限为6k左右(v1.6+的官方数据),原因很简单,因为Kubernetes整个系统都受限于它背后的etcd集群的处理能力(QPS为万级别),在Kubernetes的上一个版本,集群规模上限只有2k(v1.6+里面容量增加可能是因为etcd3里面引入了rpc的接口,通信更高效了),如果超过这个规模,集群状态就无法保证有效同步,可能会出现各种不预期的行为。而基于serf的去中心化集群就没有这种限制,集群处理能力可以做到近似线性的扩展,效率和可靠性基本不受集群规模的影响。
从这个角度来看来,Docker的集群管理潜力比今天竞争者如Kubernetes要大得多,基于serf去中心化的Docker Swarm平台基本不受集群规模的影响,在节点规模达到数十万时依旧可以很好的运转,这是Kubernetes之类的平台所做不到的。
serf背后的分布式系统理论
serf可以从功能上,自上往下分为三个层次:
· 客户端接口:提供rpc接口来处理客户端对serf集群的输入,和格式化的输出
· 消息中间件:封装了各种消息,包含集群管理和UserEvent,Query等的处理逻辑
· gossip协议层:封装了gossip协议和基本的集群管理操作
本节简单介绍gossip协议层背后的分布式系统理论。
vivaldi algorithm
在去中心化系统中,信息是通过节点之间互相传播完成的,如果每个消息都向整个集群广播,会形成严重的网络风暴,这是需要严格避免的。那么如何在避免网络风暴的前提下,同时保证消息传递的效率和可靠性呢?Vivaldi算法就是为了解决这个问题提出的。
Vivaldi算法通过启发式的学习算法,在集群通信的过程中计算节点之间的RTT,并动态学习网络的拓扑结构,每个节点可以选择离自己“最近”的N个节点进行广播,这样就可以最大程度减少网络风暴的出现,调整N可以修改信息的传播速度和效率以及对网络带宽的影响。
SWIM协议
SWIM(Scalable Weakly-consistentInfection-style Process Group Membership Protocol)是在去中心化系统中节点状态监测的协议,定义了Failure和Suspicion等状态的监测协议和节点之间的消息传输模型。节点之间可以相互“告知”集群中所有节点的状态,当出现短暂的节点状态失效时,集群中会互相同步suspicion(疑似失效)状态并持续观察该“问题”节点的状态,并在多个节点都确认了该失效节点的状态后最终更新其状态为Failure,这也减少了集群中因为偶然网络环境干扰导致的状态误判。
Lamport timestamps
分布式系统中要解决的另外一个问题就是事件顺序性的问题,无论是中心化系统还是去中心化系统,都需要判断数据的时效性。物理时间是不可靠的,物理时间微小的偏差就可能造成程序中重大逻辑错误。
考虑有两个客户端A和B,发请求获取数据库的锁,那么数据库服务器应该把锁给谁呢?为了公平起见,通常使用客户端发请求的时间来判断“谁先谁后”,那么紧接着需要面临的问题就是物理时钟不可靠,不可靠的物理时钟可能导致本该分配给A的锁却最终被分配给了B。在分布式系统中,事件顺序的判断就变得尤为关键。
试想在分布式系统中,如果一个节点短暂的失效,断开了集群,稍后又加入集群,那么其之前可能记忆了自己的一些状态,重新加入集群后可能会广播一些过期和重复的消息,如果集群中无法识别消息的时效性,那么这些过期的、重复的消息可能就会被重复、错误的执行。
Lamport Timestamp为集群中每个事件都设定一个物理时钟无关的逻辑时钟,通过一种弱一致性的手段判断事件的因果关系。节点可以通过Lamport Timestamp过滤重复、过期的事件。
serf部分源码分析
前面介绍的例子中,通过使用serf提供的命令行工具来管理集群和消息。在Go程序中,可以使用serf为应用提供原生的集群管理和去中心化的消息中间件。
在Docker libnetwork中就使用了serf来管理容器化部署相关的ARP配置,在我看来这种比较野的路子确实需要一些“脑洞”。
本节总结了serf的部分源码实现,希望能为对serf感兴趣的团队的技术人提供一些思路。
memberlist(https://github.com/hashicorp/memberlist)封装了serf中的gossip协议层,并暴露了一些接口,让上层的应用与gossip协议层进行交互,本节介绍使用serf的源码(d787b2e8f72b5da48c43b84c2617234401084050)。
将serf自上往下划分为两个层次:
· serf层:实现对协议层接口的封装,包含对集群状态管理以及Event和Query的封装
· gossip协议层:处理集群检测、广播、以及信息安全相关的问题
其中gossip协议层暴露了Delegate接口,serf层通过实现Delegate接口来扩展协议层的功能。
图3.1.1 Delegate的定义
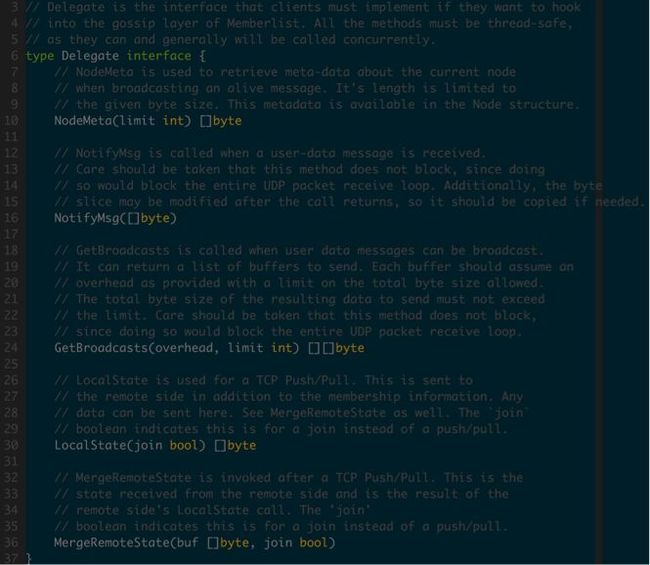
Delegate接口提供了5个回调函数接口,下面介绍serf中的实现。
NodeMeta
在serf中可以为每个节点设置具体的tag,用来过滤集群中节点。
图3.2.1 NodeMeta将节点的tag信息发布到集群中
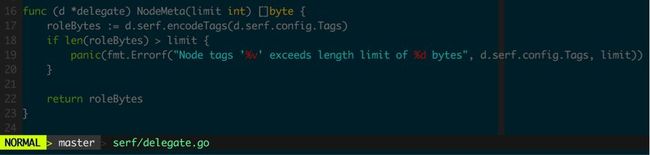 NotifyMsg
NotifyMsg
NotifyMsg是serf中整个消息中间件的核心接口,gossip协议层所有消息都会回调NotifyMsg。
图3.3.1 NotifyMsg实现

这里只关注两种用户层消息的处理机制,即UserEvent和Query(QueryResponse),其中UserEvent实现了集群中不需要反馈的、单向通信,Query和QueryResponse实现了集群中的双向通信。
先看一下当节点收到一个事件时的处理逻辑。
图3.3.2 handleUserEvent接收事件并进行预处理

在传递给EventCh之前handlerUserEvent做了一些预处理:
· 舍弃过期事件
· 舍弃已经处理过的事件
· 接收一个事件并加入recent cache(以便识别该事件是否在当前节点已经被处理过)
· 将事件通过channel发送给后续的Handler
顺带说一下serf中“最近处理过事件”的缓存机制,serf初始化一个节点时会定义一个最近事件的缓冲池,是N个不限长度的队列,缓存了N个连续Lamport Timestamp的事件,通过对其Lamport Timestamp取N的模来获取缓存中队列,并加入队列尾。
handleQuery发送数据时的逻辑和handleUserEvent是一样的,这里不再赘述。
定义消息有效性是“去中心化”集群中消息正确性的重要保障,“去中心化”集群中随时可以因为各种原因导致集群中一些节点和集群断开,当它们再次加入集群后有可能本地的一些状态没来得及与集群同步,就会出现广播了过期和重复消息的情况。对过期和重复消息的容错机制是“去中心化”集群需要具备的关键能力之一。
另外值得一提的是,serf配置中的几个channel,上面的代码中涉及其中的EventCh,既所有的UserEvent会被转发至这个channel,而后续的处理逻辑,即自定义的handler就可以来处理这些事件,这就是前面提到的serf中可以自定义event handler的问题。
serf集群参数与调优
构建serf集群涉及以下几个变量,实际应用中需要针对集群规模和当前的网络环境对这些参数进行调整,让集群获得较好的收敛速率:
· gossip interval: 向集群广播消息的时间间隔
· gossip fanout: 控制gossip协议层向集群中多少个相邻节点广播消息

图4.1 serf集群收敛仿真

可见集群收敛速率几乎不受受集群规模影响,即使集群节点数达到10w,集群也能在数秒内快速收敛。
注:这里的仿真结果是针对特定的平台参数,即丢包率,节点失效概率等参数进行的,实际应用中可以利用这里给出的公式,结合平台实际情况进行仿真。
总结
在现代分布式系统中,无论是工具还是应用模块,相互之间通信的能力显得越来越重要,serf提供了一种弱一致性的沟通渠道,让应用模块之间直接“沟通”,提升整个软件平台和服务的自主性。serf对我的吸引力来自它的两方面潜力:
· 简单、高效、可靠的去中心化集群管理
· 可以和Go程序整合,为Go程序模块提供原生的、不依赖外部存储的集群管理和通信能力
尽管如此,serf和去中心化系统不是“银弹”,在生产中应用serf时需要进行周详的考虑和严谨的规划,还需要针对平台具体情况对集群参数进行调整。相信serf和去中心系统在未来会为技术领域创造新的机遇和挑战。