强化学习是近年来最受关注的人工智能研究方向之一,相关的研究成果也层出不穷,有的甚至引起了全世界的广泛讨论。近日,卡内基梅隆大学、微软研究院、谷歌和 Citadel 等机构在 arXiv 上联合发表了一篇研究论文,提出了一种将深度强化学习应用于对话系统的新技术:BBQ 网络。本论文已被 AAAI 2018 大会接收。论文第一作者为 Zachary Lipton,另外 Citadel 首席人工智能官邓力也是该论文的作者之一,以上两位都曾出席过机器之心主办的 GMIS 2017 大会。
我们正越来越多地使用自然语言对话接口与计算机进行交互。简单的问答(QA)机器人已经在亚马逊的 Alexa、苹果的 Siri、谷歌的 Now 和微软的 Cortana(小娜)中为数百万用户提供服务了。这些 bot 通常执行的是单个交流的对话,但我们渴望开发出更通用的对话智能体,使其对话广度能接近人类对话者所表现出的能力。在这项成果中,我们研究了面向任务的 bot(Williams and Young 2004),即为了实现任务特定的目标而能执行多轮对话的智能体。在我们的案例中,我们的目标是协助用户预订电影票。
复杂的对话系统往往难以事先确定一个好的策略,而且环境的动态也可能会随时间改变。因此,通过强化学习(RL)而在线式和交互式地学习策略出现了并成为了一种流行的方法(Singh et al. 2000; Gasic et al . 2010; Fatemi et al. 2016)。受强化学习在 Atari 和棋盘游戏上的突破(Mnih et al. 2015; Silver et al. 2016)的启发,我们使用了深度强化学习(DRL)来学习对话系统的策略。深度 Q 网络(DQN)智能体通常是通过 ε-greedy 启发式方法来进行探索,但当奖励是稀疏的且动作空间很大时(对话系统就是这个情况),这种策略往往无效。在我们的实验中,随机探索的 Q 学习器永远无法在数千 episode 内取得成功。
我们提供了一种用于改善 Q 学习器的探索的有效的新解决方案。我们提出了一种贝叶斯探索策略,该策略鼓励对话智能体探索自己在动作选择时相对不确定的状态-动作区域。我们将算法命名为 Bayes-by-Backprop Q-network(简称 BBQN),该算法通过汤普森采样(Thompson sampling)进行探索,并从一个贝叶斯神经网络中抽取蒙特卡洛样本(Blundell et al. 2015)。为了得到 Q 学习的时间差分目标(temporal difference target),我们必须从一个冻结的目标网络(frozen target network)生成预测(Mnih et al. 2015)。我们的实验表明使用最大后验(MAP)分配来生成目标可以得到更好的表现水平(此外计算也很高效)。我们还证明了重放缓冲叠加(RBS/replay buffer spiking)的有效性,RBS 是一种简单的技术,其中我们使用一个过渡的小集合对经历重放缓冲进行预填充,该集合是从一个朴素但偶尔成功的基于规则的智能体得到的。证明这种技术对 BBQN 和标准 DQN 都至关重要。
我们在两个电影订票任务的不同变体上对我们的对话智能体进行了评估。我们的智能体可以与用户进行交互并预订电影票。是否成功取决于在对话结束时是否预订了电影票以及用户是否满意。我们使用了类似于 Schatzmann、Thomson 和 Young 2007 年研究中基于日程的用户模拟器对我们的算法进行基准评测和比较。为了使该任务的难度接近真实水平,我们的模拟器还引入了随机错误来作为语音识别和语言理解错误所带来的影响。在第一个任务变体中,我们的环境在所有训练轮次中保持固定。在第二个任务变体中,我们使用了一个非固定的、范围有延展的环境。在这种设置中,电影的新属性会随时间变得可用,能增加用户和智能体可以采用的对话动作的多样性。我们在固定环境和范围有延展的环境上的实验都表明 BBQN 的表现要优于使用 ε-greedy 探索、玻尔兹曼探索或 Osband et al. (2016) 引入的 bootstrap 方法的 DQN。此外,真实用户评估进一步巩固了我们的方法的有效性:BBQN 的探索比 DQN 更加有效。另外,我们还表明所有智能体只有在给出了 RBS 时才能工作,尽管预填充的对话的数量可以很小。
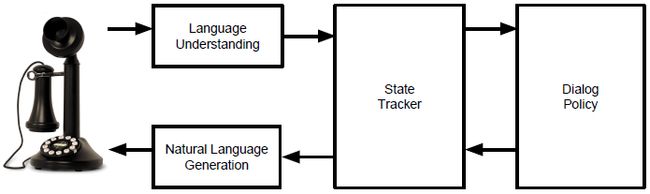
图 1:对话系统的组成
BBQN 是一种使用深度学习模型来学习对话策略的算法。BBQN 基于深度 Q 网络(Mnih et al. 2015),并使用了一个贝叶斯神经网络来近似 Q 函数和该近似中的不确定性。因为我们研究的是固定长度的对话表征,所以我们使用了 MLP,但也可以很简单地将我们的方法扩展到循环或卷积神经网络。
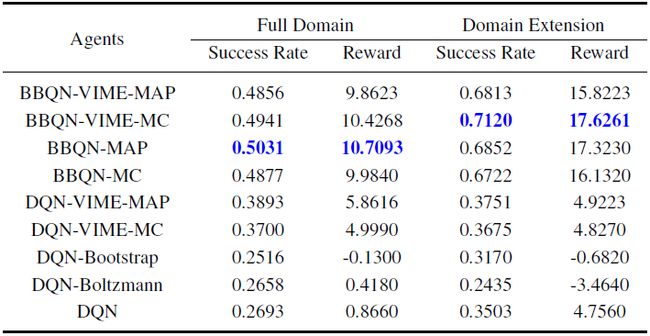
表 1:在 1 万组模拟对话(每组平均 5 轮以上)上训练得到的智能体的最终表现
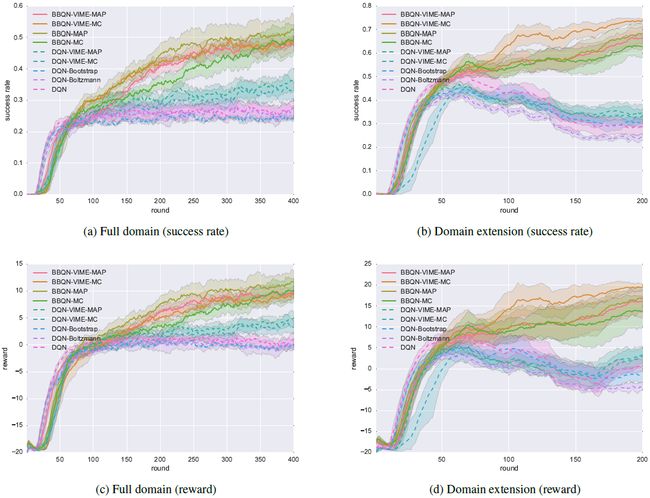
图 2:在全范围(所有环境属性一开始都可用)和范围有延展(每隔 10 轮对话就增加属性)的问题上的训练过程图示(带有置信区间)
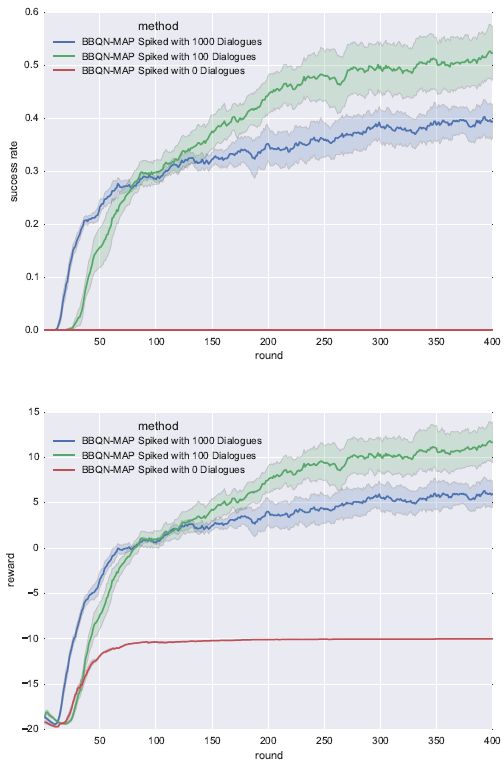
图 3:使用 100 组对话的 RBS 在成功率(上图)和奖励(下图)上都有提升
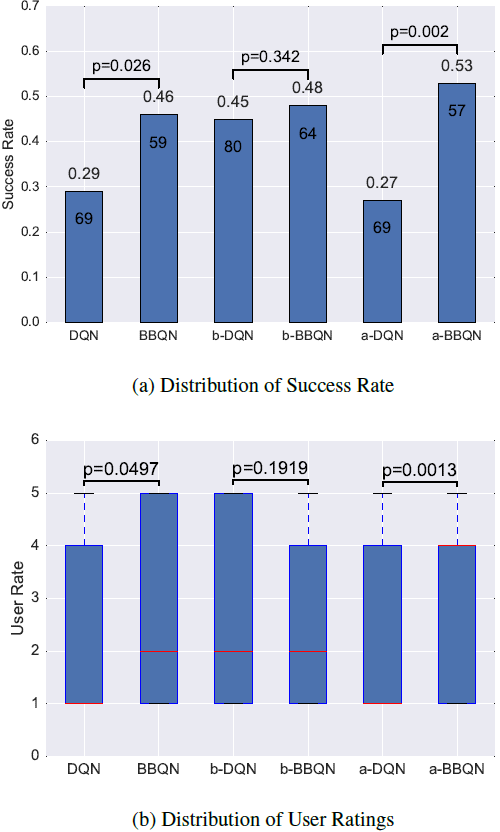
图 4:BBQN 智能体与 DQN 智能体在真实用户测试上得到的表现,测试对话的数量和 p 值在柱状图的每个柱上给出(均值差异明显,且 p<0.05)
论文:BBQ-Networks: Efficient Exploration in Deep Reinforcement Learning for Task-Oriented Dialogue Systems

论文链接:https://arxiv.org/abs/1711.05715
摘要:我们提出了一种新的算法,可以显著提升对话系统中深度 Q 学习智能体的探索效率。我们的智能体通过汤普森采样(Thompson sampling)进行探索,可以从 Bayes-by-Backprop 神经网络中抽取蒙特卡洛样本。我们的算法的学习速度比 ε-greedy、波尔兹曼、bootstrapping 和基于内在奖励(intrinsic-reward)的方法等常用的探索策略快得多。此外,我们还表明:当 Q 学习可能失败时,只需将少数几个成功 episode 的经历叠加到重放缓冲(replay buffer)之上,就能使该 Q 学习可行。