机器学习中之规范化,中心化,标准化,归一化,正则化,正规化
一、归一化,标准化和中心化
广义的标准化:
(1)离差标准化(最大最小值标准化)
(2)标准差标准化
(3)归一化标准化
(4)二值化标准化
(5)独热编码标准化
归一化 (Normalization)、标准化 (Standardization)和中心化/零均值化 (Zero-centered)
标准化
数据的标准化(normalization)是将数据按比例缩放(scale),使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。也就是归一化是标准化的特例,标准化的子集。
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
意义:数据中心化和标准化在回归分析中是取消由于量纲不同、自身变异或者数值相差较大所引起的误差。
中心化
中心化(又叫零均值化)
用途:在回归问题和一些机器学习算法中,以及训练神经网络的过程中,还有PCA等通常需要对原始数据进行中心化(Zero-centered或者Mean-subtraction(subtraction表示减去))处理和标准化(Standardization或Normalization)处理。
原理:
数据中心化:是指变量减去它的均值;
数据标准化:是指变量减去均值,再除以标准差。即数据中心化之后除以标准差。
目的:通过中心化和标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据。
(1)中心化(零均值化)后的数据均值为零。
(2)z-score 标准化后的数据均值为0,标准差为1(方差也为1)(中心化是标准化z-score 的第一步)。
通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。简言之,当原始数据不同维度上的特征即变量的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
其实,在不同的问题中,中心化和标准化有着不同的意义,
比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。
对数据进行中心化预处理,这样做的目的是要增加基向量的正交性。
对数据标准化的目的是消除特征之间的差异性。便于对一心一意学习权重。
归一化
1 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
两个优点:
1)归一化后加快了梯度下降求最优解的速度,提升模型的收敛速度。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2)归一化有可能提高精度。
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
3)深度学习中数据归一化可以防止模型梯度爆炸。
需要归一化的模型:
有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。
有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression(因为θ的大小本来就自学习出不同的feature的重要性吧?)。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛(模型结果不精确)。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
有些模型/优化方法的效果会强烈地依赖于特征是否归一化,如LogisticReg,SVM,NeuralNetwork,SGD等。
不需要归一化的模型:
(0/1取值的特征通常不需要归一化,归一化会破坏它的稀疏性。)
有些模型则不受归一化影响。模型算法里面没有关于对距离的衡量,没有关于对变量间标准差的衡量。比如decision tree 决策树,采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的。
ICA好像不需要归一化(因为独立成分如果归一化了就不独立了?)。
基于平方损失的最小二乘法OLS不需要归一化。
Kmeans,KNN一些涉及到距离有关的算法,或者聚类的话,都是需要先做变量标准化的。
以下是几种常用的变化方法:
1)Rescaling (min-max scaling): min-max标准化(Min-Max Normalization)/0-1 normalization/线性函数归一化/离差标准化
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]或[-1, 1]之间。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。

目的:
- 1、对于方差非常小的属性可以增强其稳定性;
- 2、维持稀疏矩阵中为0的条目。
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_minMax = min_max_scaler.fit_transform(X)
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]]) 2)Z-score标准化(zero-mean normalization):Standardization(一般狭义上的标准化指此种方法,spss默认的标准化方法就是z-score标准化。广义上的标准化包括归一化)
也叫标准差标准化。这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则标准化的效果会变得很糟糕。它们可以通过现有样本进行估计。在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
优点:当X的最大值和最小值未知,或孤立点左右了最大-最小规范化时,该方法有用。
广泛应用于:support vector machines, logistic regression, and artificial neural networks。
![]()
三种实现方法:
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
# calculate mean
X_mean = X.mean(axis=0)
# calculate variance
X_std = X.std(axis=0)
# standardize X
X1 = (X-X_mean)/X_std
# use function preprocessing.scale to standardize X
X_scale = preprocessing.scale(X)
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
scaler = preprocessing.StandardScaler()
X_scaled = scaler.fit_transform(X) 3)Scaling to unit length
也就是计算特征向量的欧氏长度。在线性代数中,将一个向量除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量。
![]()
4)Mean normalization
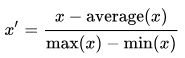
5)log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:
6)atan函数转换
用反正切函数也可以实现数据的归一化。
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。
7)Decimal scaling小数定标标准化
这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A的取值中的最大绝对值。
将属性A的原始值x使用decimal scaling标准化到x'的计算方法是:
x'=x/(10^j)
其中,j是满足条件的最小整数。
例如 假定A的值由-986到917,A的最大绝对值为986,为使用小数定标标准化,我们用每个值除以1000(即,j=3),这样,-986被规范化为-0.986。
注意,标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
8)Logistic/Softmax变换
参考:https://blog.csdn.net/pipisorry/article/details/77816624
9)模糊量化模式
参考:https://blog.csdn.net/pipisorry
具体说明中心化和标准化的作用:
- 左图表示的是原始数据
- 中间的是中心化后的数据,可以看出就是一个平移的过程,平移后中心点是(0,0)。同时中心化后的数据对向量也容易描述,因为是以原点为基准的。
- 右图将中心化后的数据除以标准差,得到为标准化的数据,可以看出每个维度上的尺度是一致的(红色线段的长度表示尺度),而没有处理之前的数据是不同的尺度标准。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
中心化(以PCA为例)下面两幅图是数据做中心化(centering)前后的对比,其实就是一个平移的过程,平移后所有数据的中心是(0,0)。
 在做PCA的时候,我们需要找出矩阵的特征向量,也就是主成分(PC)。比如说找到的第一个特征向量是a = [1, 2],a在坐标平面上就是从原点出发到点 (1,2)的一个向量。
在做PCA的时候,我们需要找出矩阵的特征向量,也就是主成分(PC)。比如说找到的第一个特征向量是a = [1, 2],a在坐标平面上就是从原点出发到点 (1,2)的一个向量。
如果没有对数据做中心化,那算出来的第一主成分的方向可能就不是一个可以“描述”(或者说“概括”)数据的方向了。

黑色线就是第一主成分的方向。只有中心化数据之后,计算得到的方向才能比较好的“概括”原来的数据。
根据侯杰泰的话:所谓 中心化 是指变量减去它的均值(即数学期望值)。对于样本数据,将一个变量的每个观测值减去该变量的样本平均值,变换后的变量就是中心化的。
二、正规化和规范化
和标准化是一个概念。(一般我们不认为归一化属于标准化,而是两个同级别的概念,区别见总结)
三、正则化
from sklearn import preprocessing
train_x = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]
# normalize the data attributes
x1 = preprocessing.normalize(train_x)
print(x1)
# standardize the data attributes
x2 = preprocessing.scale(train_x)
print(x2)
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals四、二值化(Binarization)
特征的二值化主要是为了将数据特征转变成boolean变量。在sklearn中,sklearn.preprocessing.Binarizer函数可以实现这一功能。实例如下:
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer(copy=True, threshold=0.0)
>>> binarizer.transform(X)
array([[ 1., 0., 1.],
[ 1., 0., 0.],
[ 0., 1., 0.]]) 总结
1 归一化特点
对不同特征维度的伸缩变换的目的是使各个特征维度对目标函数的影响权重是一致的,即使得那些扁平分布的数据伸缩变换成类圆形。这也就改变了原始数据的一个分布。好处:
1 提高迭代求解的收敛速度
2 提高迭代求解的精度

从采用大单位的身高和体重这两个特征来看,如果采用标准化,不改变样本在这两个维度上的分布,则左图还是会保持二维分布的一个扁平性;而采用归一化则会在不同维度上对数据进行不同的伸缩变化(归一区间,会改变数据的原始距离,分布,信息),使得其呈类圆形。虽然这样样本会失去原始的信息,但这防止了归一化前直接对原始数据进行梯度下降类似的优化算法时最终解被数值大的特征所主导。归一化之后,各个特征对目标函数的影响权重是一致的。这样的好处是在提高迭代求解的精度。
2 标准化特点
对不同特征维度的伸缩变换的目的是使得不同度量之间的特征具有可比性。同时不改变原始数据的分布。好处:
1 使得不同度量之间的特征具有可比性,对目标函数的影响体现在几何分布上,而不是数值上
2 不改变原始数据的分布

从上面两个坐标图可以看出,样本在数据值上的分布差距是不一样的,但是其几何距离是一致的。而标准化就是一种对样本数据在不同维度上进行一个伸缩变化(而不改变数据的几何距离),也就是不改变原始数据的信息(分布)。这样的好处就是在进行特征提取时,忽略掉不同特征之间的一个度量,而保留样本在各个维度上的信息(分布)。
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
如果把所有维度的变量一视同仁,在最后计算距离中发挥相同的作用应该选择标准化,如果想保留原始数据中由标准差所反映的潜在权重关系应该选择归一化。另外,标准化更适合现代嘈杂大数据场景。
在机器学习算法的目标函数(例如SVM的RBF内核或线性模型的l1和l2正则化),许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。进行标准化。
3 区别
一般不认为归一化属于标准化的特例,我们简单理解就是两个同级别的概念。
在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。总结原因有两点:
1、标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
2、标准化更符合统计学假设对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
(1)如果对输出结果范围有要求,用归一化
(2)如果数据较为稳定(图像或是视频的数据值处于固定区间),不存在极端的最大最小值,用归一化
(3)如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
4 问题
逻辑回归必须要进行标准化吗?
无论你回答必须或者不必须,你都是错的!
真正的答案是,这取决于我们的逻辑回归是不是用正则。
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。为什么呢?因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是: 身高 = 体重*x x就是我们训练出来的参数。当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。在上面两种情况下,都用L1正则的话,显然对模型的训练影响是不同的。
假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。
如果不用正则,那么标准化对逻辑回归有什么好处吗?
答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
做标准化有什么注意事项吗?
最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!(我之前就犯了这个错误)
代码实现
https://blog.csdn.net/pipisorry/article/details/52247679
https://blog.csdn.net/pipisorry/article/details/52247379
以上概念还是比较模糊,如有错误请及时提醒。