【论文解读 ICLR 2020 | LambdaNet】Probabilistic Type Inference using Graph Neural Networks

论文题目:LambdaNet: Probabilistic Type Inference using Graph Neural Networks
论文来源:ICLR 2020
论文链接:https://openreview.net/forum?id=r1lZ7AEKvB
代码链接:https://github.com/MrVPlusOne/LambdaNet
关键词:GNN,谓词,代码类型注释,attention,超边,指针网络
文章目录
- 1 摘要
- 2 引言
- 3 动机举例和问题设置
- 3.1 问题设置
- 4 类型依赖图
- 5 Neural Architecture
- 6 实验
- 7 总结
1 摘要
本文使用图神经网络进行推理,具体的场景是在 Python 或者 Typescript 之类的语言中自动进行代码的类型注释。
该方法首先使用轻量级的源代码分析生成一个程序抽象——类型依赖图。该图将类型变量和逻辑约束、名称以及使用信息联系在一起。给定这个图后,使用GNN在相关的类型变量间进行消息传播,最终进行类型的预测。
本文提出的方法可以预测标准的类型,例如number、string,也可以预测出训练中未出现过的用户自定义的类型。
2 引言
在过去的十年中,例如Python、Ruby、Javascript之类的动态类型语言获得了极大的普及,但它们缺乏静态类型系统,缺乏在编译时捕获错误的能力以及code completion的支持,在可维护性方面存在一定的缺陷。
Gradual typing可以解决这些不足:程序变量有可选的类型注释,这样类型系统就可以在需要的时候执行静态类型检查。有许多流行的编程语言可支持gradual typing,但由于它们大量使用动态语言结构并且缺乏主要的类型,编译器不能使用来自编程语言社区的标准算法进行类型推断。并且,手动向现有的代码库添加类型注释非常繁琐而且易出错。
为了减少从无类型的代码向静态类型代码过渡所涉及的人工工作,本文的工作使用基于学习的方法,自动地为无类型(或有部分类型)的代码库推断出可能的类型注释。
已有方法的缺点:
本文使用的是TypeScript,是Javascript的一种变形,该语言有大量的类型注释的程序作为训练数据。已经有一些使用机器学习为TypeScript推断类型标注的方法,但这些方法都有一些缺点:
(1)推断的结果来源于有限的类型词典,即推断的类型都是在训练过程中出现过的,不能推断出用户定义的数据类型。
(2)即使不考虑用户定义的类型,这些方法的准确率也不高。
(3)这些方法可能会产生不一致的结果,对于相同的变量可能因为出现位置的不同,导致预测出来的类型不同。
作者提出:
使用GNN对TypeScript进行类型推断,避免了上述问题。
本文的方法先使用轻量级的源代码分析,将程序转换成类型依赖图。图由节点和有标签的超边(hyperedges)组成,图中的节点代表类型变量,节点间的关系编码在了超边里。类型依赖图中除了表达了逻辑约束之外,还结合了设计命名和变量使用的上下文提示。
给定类型依赖图后,使用GNN为每种类型变量计算出一个向量表示,然后使用类似指针网络的结构进行类型预测。
GNN本身需要处理各种类型的超边(有些具有可变数量的参数),为此作者定义了恰当的图传播操作。
在预测层比较了类型变量的向量表示和候选类型的向量表示,从而可以灵活地处理在训练阶段未出现过的用户定义的类型。
另外,模型的预测结果具有一致性,因为模型进行的是变量级别的预测,而不是位置级别的预测。
贡献:
(1)提出了一个TypeScript的概率类型推断算法)(LambdaNet),使用了深度学习的方法,根据程序对应的类型依赖图的表示进行预测。
(2)使用GNN方法进行了类型变量的向量表示的计算,并且提出类似指针网络的方法对用户定义的类型进行预测。
(3)实验证明了LambdaNet的有效性以及和之前的方法相比的优越性。
3 动机举例和问题设置

图1展示了一个(type-annotated)TypeScript程序,本文工作的目的是给定未标注版本的代码,推断出图中所展示的类型。接下来以图1为例,来解释本文方法的各个方面。
1、类型限制(Typing constraints):
图1中的某些函数/操作符对可以被分配给程序变量的类型施加了强约束。例如,forward函数中的 x , y x, y x,y的类型必须能支持concat操作,因此 x , y x, y x,y的类型可以是string, array, Tensor,但不能是boolean。这启发了作者,将类型限制添加到了模型中。
2、上下文提示(Contextual hints):
只使用类型限制并不能确定变量的类型,例如对于restore函数中的network变量,在类型限制的条件下,需要network的类型是有time的类,但是有许多类都有这样的属性(例如 Date)。然而,变量名称network和类名MyNetwork间的相似度提示了network可能有类型MyNetwork。基于这一点,我们可以进一步传播库函数readNumber返回的类型(假定我们知道类型是number),进而推断出MyNetwork的time的类型有可能是number。
3、类型依赖图的需要:
有很多种展示程序的方式,例如token序列、抽象语义树、控制流图等等。然而这些表示方法都不利于推断出最可能的类型注释。因此本文使用静态分析的方法来推断一组与类型推断问题相关的谓词,并使用程序抽象的方式(类型依赖图)来表示这些谓词。
4、处理用户定义的类型:
先前的方法的预测结果只能是训练中出现过的类型。如图1所示,MyNetwork是自定义的类型,并且restore方法中使用了这一类型的变量。一个成功的模型应该能基于用户定义类型的定义动态地进行推断。
3.1 问题设置
本文的目标是训练出一个类型推断模型,将完全或部分未注释TypeScript程序 g g g作为输入,为每个缺失的注释预测出类型的概率分布。
预测空间为 Y ( g ) = Y l i b ∪ Y u s e r ( g ) \mathcal{Y}(g)=\mathcal{Y}_{lib}\cup \mathcal{Y}_{user}(g) Y(g)=Ylib∪Yuser(g),其中 Y u s e r ( g ) \mathcal{Y}_{user}(g) Yuser(g)为用 g g g声明的所有用户定义类型的集合(类/接口), Y l i b \mathcal{Y}_{lib} Ylib是通常使用的固定的库类型集合。
将预测范围限定在非多态(non-polymorphic)和非函数(non-function)的类型。也就是说,不区别“ L i s t < T > , L i s t < n u m b e r > , L i s t < s t r i n g > List
4 类型依赖图

类型依赖图 G = ( N , E ) \mathcal{G}=(N,E) G=(N,E)是一个超图,图中的节点 N N N代表类型变量,超边 E E E编码了节点之间的关系信息。通过对TypeScript程序源代码的中间表示形式进行静态分析,提取出给定程序的类型依赖图,这使得我们将唯一的变量与每个程序子表达式关联起来。图2展示了图1代码的中间表示。

类型依赖图编码了类型变量的属性和它们之间的关系。每一个超边都对应表1中的一个谓词。将这些谓词分为Logical和Contextual两类,第一类可看成对类型变量施加了强约束,第二类编码了从变量名、函数名和类名中抽取出来的有用的提示。

图3展示了从图2的中间表示中抽取出来的类型依赖图 G \mathcal{G} G中的一些超边。
如图3 A所示,我们分析后从代码中抽取出了谓词 S u b T y p e ( τ 13 , τ 5 ) SubType(\tau_{13}, \tau_5) SubType(τ13,τ5),因为和返回的表达式 v 4 v4 v4关联的类型变量必须是封闭函数返回类型的子类型。如图3 B所示,我们抽取出了谓词 O b j e c t n a m e , t i m e , f o r w a r d ( τ 8 , τ 1 , τ 2 , τ 9 ) Object_{name, time, forward}(\tau_8, \tau_1, \tau_2, \tau_9) Objectname,time,forward(τ8,τ1,τ2,τ9),因为 τ 8 \tau_8 τ8是一个对象类型,且它的成员name, time, forward分别对应的类型变量为 τ 1 , τ 2 , τ 9 \tau_1, \tau_2, \tau_9 τ1,τ2,τ9。
图3的A和B中的谓词对类型变量施加了强约束,C和D则是编码了从变量名中获得的上下文提示。图3 C表示类型变量 τ 14 \tau_{14} τ14和名为restore的表达有关。然而这类命名信息在TypeScript的结构类型系统中是不可见的,它将作为GNN结构(第5节介绍)中的一个输入特征。
类型依赖图不仅存储了与每个类型变量关联的唯一变量名,还编码了变量名和类名间的相似度信息。例如,MyNetwork类的实例通常被称为network或network1。为了捕获到这种对应关系,类型依赖图中还包含了名为NameSimilar的超边,如果类型变量 α , β \alpha, \beta α,β对应的tokenized names有非空的交集,则将它们连接起来。
如表1所示,称为Usage的超边促进了对象类型的类型推断。例如,对于var y = x.l,使用所有含有属性/方法 β i \beta_i βi且名为 l l l的类 α i \alpha_i αi,抽取出谓词 U s a g e l ( ( τ x , τ y ) , ( α 1 , β 1 ) , . . . , ( α k , β k ) ) Usage_l((\tau_x, \tau_y), (\alpha_1, \beta_1), ..., (\alpha_k, \beta_k)) Usagel((τx,τy),(α1,β1),...,(αk,βk)),连接x和y的类型变量。图3展示了从图2的代码中抽取出来的Usage超边。在下一节中,本文的GNN结构将使用特殊的注意力机制在这些usage edges间传递信息。
5 Neural Architecture
本文的用于类型预测的神经网络架构主要由两部分组成:(1)GNN在类型依赖图中进行消息传递,为每个类型变量生成向量表示;(2)指针网络将每个变量的类型嵌入和候选类型的嵌入(两者都是从上一步计算得到的)进行比较,生成一个可能的类型分配的分布。
给定类型依赖图 G = ( N , E ) \mathcal{G}=(N, E) G=(N,E),首先为每个节点计算一个向量嵌入 v n \mathbf{v}_n vn,这些向量里编码了类型信息。因为程序抽象是一个图,所以很自然地想到使用GNN架构。GNN架构将每个节点 n n n的初始向量 v n 0 \mathbf{v}^0_n vn0作为输入,在GNN中进行 K K K轮的消息传递,然后为每个类型变量生成最终的表示。
具体来说, v n t \mathbf{v}^t_n vnt表示节点 n n n在第 t t t步的向量表示,每一轮包括消息传递和聚合两步,如下式所示。其中 e e e表示连接节点 p 1 , . . . , p a p_1,...,p_a p1,...,pa的超边, j j j表示超边 e e e的第 j j j个参数, N \mathcal{N} N表示节点的邻居,消息传递函数 M s g e Msg_e Msge由边的类型决定。
![]()
(1)初始化
GNN中,节点对应于类型变量,并且每个类型变量都和一个程序变量或常数相对应。初始化的工作过程取决于 n n n是否是常数节点。
由于每个常数的类型是已知的,我们将类型为 τ \tau τ的常数节点设置为可训练的向量 c τ \mathbf{c}_{\tau} cτ,并且在GNN迭代过程不做更新(例如 ∀ t , v n t = c τ \forall{t}, \mathbf{v}^t_n=\mathbf{c}_{\tau} ∀t,vnt=cτ)。若 n n n为变量节点,则在迭代过程中我们没有它的类型信息。因此,我们使用统一的可训练的向量初始化所有的变量节点(例如 均初始化成同一个向量,但是在GNN迭代过程中会进行更新)。
(2)消息传递
M s g Msg Msg操作取决于边的类型(如 表1所示),并且同种超边的所有实例中参数是共享的。接下来描述每种超边在神经网络中的消息传递方式:
- FIXED:这些超边是有固定数量的参数的谓词,并且参数的位置顺序也是谓词表达的一部分。计算第 j j j个参数的消息:1)首先,将所有参数的嵌入向量拼接;2)然后,将其输入给第 j j j个参数的2层的MLP。
如表1所示,类型为Access的超边有一个标识符 l l l,这个标识符也看成一个额外的参数,并为其生成一个嵌入。
-
NARY:连接了可变数量的节点。给定一个NARY边 E l 1 , . . . , l k ( α , β 1 , . . . , β k ) E_{l_1,...,l_k}(\alpha, \beta_1,..., \beta_k) El1,...,lk(α,β1,...,βk), α \alpha α的消息计算为: { M L P α ( v l j ∣ ∣ v β j ) ∣ j = 1 , . . . , k } {\{MLP_{\alpha}(\mathbf{v}_{l_j}||\mathbf{v}_{\beta_j})|j=1,...,k}\} {MLPα(vlj∣∣vβj)∣j=1,...,k}, β j \beta_j βj的消息计算为 M L P β ( v l j ∣ ∣ v α ) MLP_{\beta}(\mathbf{v}_{l_j}||\mathbf{v}_{\alpha}) MLPβ(vlj∣∣vα)。
-
NPAIRS:是一种特殊的类别,如 U s a g e l ( ( α ∗ , β ∗ ) , ( α 1 , β 1 ) , . . . , ( α k , β k ) ) Usage_l((\alpha^*, \beta^*), (\alpha_1, \beta_1),...,(\alpha_k, \beta_k)) Usagel((α∗,β∗),(α1,β1),...,(αk,βk))。这种类型的边源于b = a.l的表示形式,用于连接 a a a和 b b b的类型变量,其中类 α i \alpha_i αi含有标签为 l l l的 β i \beta_i βi属性/方法。若 a a a的类型嵌入和类型 C C C的很相似,则 b b b的类型很有可能就是 C . l C.l C.l的类型。
因此,我们使用基于点积的attention来计算 α ∗ , β ∗ \alpha^*, \beta^* α∗,β∗的消息。使用 α ∗ \alpha^* α∗和 α j \alpha_j αj作为attention的Key, β j \beta_j βj作为attention的Values,来计算 β ∗ \beta^* β∗的消息(将key和value的角色调换计算 α ∗ \alpha^* α∗的消息)

(3)消息聚合
聚合所有传递给 n n n的消息,计算出嵌入 v n t v^t_n vnt。使用GAT中提出的基于attention的聚合操作的一种变形,进行消息聚合:
![]()
其中, w e w_e we是来自于边 e e e的消息所占的注意力权重,是经过softmax(a)计算得到的。其中, a e = L e a k y R e L u ( v n t − 1 ⋅ M 2 m e , n t ) a_e=LeakyReLu(v^{t-1}_n\cdot \mathbf{M}_2 m^t_{e,n}) ae=LeakyReLu(vnt−1⋅M2me,nt)。 M 1 , M 2 \mathbf{M}_1, \mathbf{M}_2 M1,M2是可训练的矩阵。注意,使用的是点乘的方式计算注意力权重,而不是使用线性模型进行计算。
(4)标识符嵌入
根据驼峰大小写以及下划线规则将变量名分解为单词token,并为在训练集中出现次数大于1的所有单词tokens分配一个可训练的向量。对于其他的token,随机地将它们映射成 < U n k n o w n − i >
每次运行GNN时,这种映射都是随机构造的,因此有助于神经网络区分不同的tokens,即使它们是罕见的tokens。对这些标记符嵌入和模型的其他部分一起进行端到端的训练。
(5)预测层
对于每个类型变量 n n n和每个候选类型 c ∈ Y ( g ) c\in \mathcal{Y}(g) c∈Y(g),我们使用MLP计算两者嵌入表示的兼容性分值: s n , c = M L P ( v n , u c ) s_{n, c}=MLP(\mathbf{v}_n, \mathbf{u}_c) sn,c=MLP(vn,uc),其中 u c \mathbf{u}_c uc是 c c c的嵌入向量。若 c ∈ Y l i b c\in \mathcal{Y}_{lib} c∈Ylib,则 v c \mathbf{v}_c vc是库类型 c c c的可训练的向量;若 c ∈ Y u s e r ( g ) c\in \mathcal{Y}_{user}(g) c∈Yuser(g),则它对应类型依赖图 g g g中的节点 n c n_c nc,令 u c = v n c \mathbf{u}_c= \mathbf{v}_{n_c} uc=vnc。
这一方法像一个指针网,我们使用前向传播计算得到的嵌入来预测这些类型的“指针”。
给定兼容性分值 s n , c s_{n,c} sn,c,我们使用softmax层将它们转换为概率分布: P n ( c ∣ g ) = e x p ( s n , c ) / ∑ c ′ e x p ( s n , c ′ ) P_n(c|g)=exp(s_{n,c})/\sum_{c^{'}}exp(s_{n, c^{'}}) Pn(c∣g)=exp(sn,c)/∑c′exp(sn,c′)。在测试阶段,最大化这一概率来计算出最可能的/top-N的类型。
6 实验
回答三个问题:
-
本文的方法和之前的方法进行比较效果如何?
-
本文的模型预测用户定义类型的能力如何?
-
本文模型的各个部分的有效性如何?
数据集:
Github中开源的TypeScript项目
对比方法:
DeepTyper,将程序看成是tokens序列,使用双向RNN进行类型预测。
实验结果:
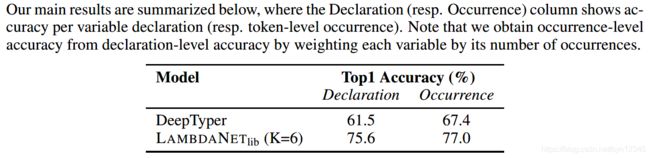

7 总结
本文提出LambdaNet框架,模型结合了使用GNN进行程序分析的长处,目的是用于类型推断。
LambdaNet框架不仅在预测库类型时比以往的state-of-the-art方法好,而且还可以有效预测出训练中未出现过的用户定义的类型。作者提出了logical和contextual类型的超边,消融实验证明了使用者两种超边的有效性。
未来工作:
(1)当前的模型只能处理简单的函数类型和一般化的类型,不能处理有结构的类型。
(2)在推理过程实行强约束,以保证类型分配结果的一致性。
这篇文章读得有点云里雾里,以前没有关注过使用GNN进行代码类型预测的任务。感觉本文并没有对如何构建出来类型依赖图进行介绍,静态分析得到程序的抽象是怎么分析出来的呢?个人对预测层指针网络的描述也不太理解。
个人感觉标识符的嵌入部分“根据驼峰大小写以及下划线规则将变量名分解为单词token”以及预测层部分 使得对用户定义类型的预测得以实现。
这篇文章读的不太懂,以后如果要进行和其相关的研究内容的话,再继续精读。