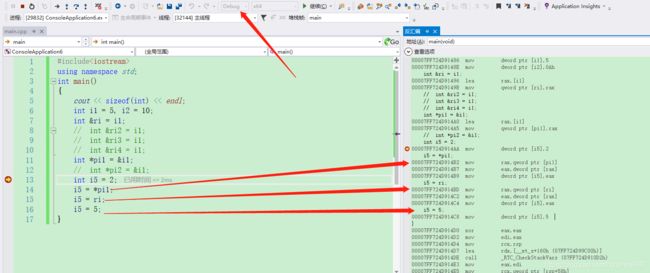
C++ 引用 参数传递 机制
本文主要分析C++引用赋值和引用参数传递的案例。
关于多开GDB,手懒把所有程序都编译成a.out的注意了,gdb中,不确定已经读取文件正在执行过程中会不会产生干扰。至少一次运行结束后,原来断点什么的就不存在了,文件找不到了。
(gdb) r
The program being debugged has been started already.
Start it from the beginning? (y or n) y
`/home/huqw/test/cpp/a.out' has changed; re-reading symbols.
Error in re-setting breakpoint 1: No source file named refParamStack.cpp.
Error in re-setting breakpoint 2: No source file named refParamStack.cpp.
Error in re-setting breakpoint 3: No source file named refParamStack.cpp.
Error in re-setting breakpoint 4: No source file named refParamStack.cpp.
两个源文件如下,一个swap()函数,分别传入普通参数和引用参数:
//为何引用能改变原变量,看一下函数的栈情况
#include
#include
void swap(int &a,int &b)
{
int temp = a;
a = b;
b = temp;
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
swap(i,j);
printf("i:%d,j:%d.\n",i,j);
}
//为何引用能改变原变量,看一下函数的栈情况
//对比试验,看看正常函数参数的堆栈情况
#include
#include
void swap(int a,int b)
{
int temp = a;
a = b;
b = temp;
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
swap(i,j);
printf("i:%d,j:%d.\n",i,j);
}
编译好两个目标文件,打开两个gdb,分别读取两个目标文件,打好断点,同时运行,

如上图,感觉有点串,一个文件的i和另一个文件的j一样,一个文件的j和另一个文件的i一样。。。。两个“例程”的地址已经混淆了?其实这倒也没什么,这只是逻辑地址,而且是静态的,很多文件编译好了变量的地址就不变了,“屡试不爽”了,但是装载到内存,各是各的,不影响。
继续向下运行,顺便也来验证一下传递引用和传递普通参数的区别。
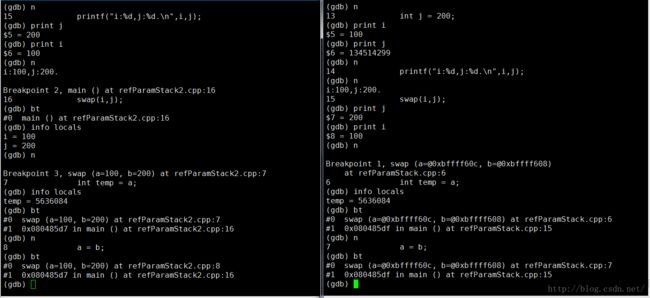
引用方面,函数内外地址一致是肯定的,a、b和i、j对应(至于info frame,目前还看不太好):
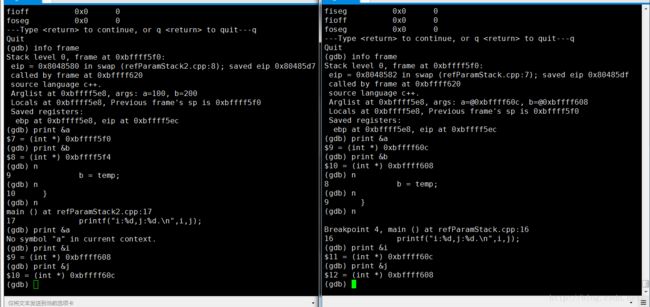
其实即使可执行的目标文件相同,调试打断点和显示代码还是要看源文件,所以最好用两个独立的源文件和两个独立的目标文件,免得产生干扰。
=========================================================================================================================
@符号的详细解释?不管能不能解释@符号,最起码可以找找相似,既然是@加地址,又因为传指针按理说也是传地址,所以用传指针的情况作对比。
代码如下:
//对照组:传递指针
#include
#include
void swap(int *a,int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
swap(&i,&j);
printf("i:%d,j:%d.\n",i,j);
}
gdb调试(函数内部堆栈):
(gdb) bt
#0 swap (a=0xbffff60c, b=0xbffff608) at refParamStack3.cpp:7
#1 0x080485df in main () at refParamStack3.cpp:15
但是指针和引用毕竟不同:层级不同,一个是直接当变量用,一个是指针,需要提取内容。
把原引用用例再加上普通引用(非函数参数)作为对比:
(gdb) n
14 int &refI = i;
(gdb) n
15 int &refJ = j;
(gdb) bt
#0 main () at refParamStack.cpp:15
(gdb) info locals
i = 100
j = 200
refI = @0xbffff604
refJ = @0x55fff4
另一个问题是,同一次运行中,出现了不一样的地址,在调用swap()前地址如下
(gdb) info locals
i = 100
j = 200
refI = @0xbffff604
refJ = @0x55fff4
调用中:
(gdb) print a
$1 = (int &) @0xbffff604: 100
(gdb) print b
$2 = (int &) @0xbffff600: 200
调用后如下:
(gdb) info locals
i = 200
j = 100
refI = @0xbffff604
refJ = @0xbffff600
原因应该是refJ还未定义完成,下一步应该就行了(可见也是分了声明和定义赋值两步)
可见,引用的格式就是@地址,不过具体反映到操作上,@的机制是什么?
=========================================================================================================================
通过汇编指令:
(gdb)layout asm
(gdb)si
查看详细操作
引用初始化的汇编过程示例:
int &refI = i;
int &refj = j;
b+ x0x80485af lea 0x14(%esp),%eax x
x0x80485b3 mov %eax,0x18(%esp) x
b+ x0x80485b7 lea 0x10(%esp),%eax x
x0x80485bb mov %eax,0x1c(%esp)
引用赋值测试:
引用refI指向i,进行如下操作:
refI = 300;
0x804859f movl $0x64,0x14(%esp) x
B+>x0x80485b7 mov 0x18(%esp),%eax x
x0x80485bb movl $0x12c,(%eax) x
x0x80485c1 lea 0x10(%esp),%eax x
x0x80485c5 mov %eax,0x1c(%esp) x
x0x80485c9 mov 0x10(%esp),%edx x
x0x80485cd mov 0x14(%esp),%eax x
x0x80485d1 mov %edx,0x8(%esp) x
x0x80485d5 mov %eax,0x4(%esp) x
x0x80485d9 movl $0x8048764,(%esp) x
x0x80485e0 call 0x8048498 x
x0x80485e5 mov 0x1c(%esp),%eax x
x0x80485e9 mov (%eax),%edx x
x0x80485eb mov 0x18(%esp),%eax x
x0x80485ef mov (%eax),%eax 可以看到
$0x12c存入eax指向的内存,而eax指向的内存
(gdb) print refI
$3 = (int &) @0xbffff604: 100
(gdb) print $eax
$4 = -1073744380
(gdb) print *($eax)
$5 = 100
(gdb) print &i
$6 = (int *) 0xbffff604
使用计算器换算一下十六进制和十进制,i的地址604和eax的值-1073744380是一样的,eax存的是i的地址,进行赋值操作也是直接给i所在的内存赋值。
所以,引用本质上是指针(32位也需要占用4字节空间)。
至于
和指针的操作层次不一样(指针还要再加*操作才能得到值);
只能初始化,不能再赋值;
这都是C++和编译器的规则了!也加上他毕竟和指针的层不一样,int &refI = i;这种特定操作只有声明时候有,注定不能像指针一样用refI = j;这种形式再绑定其他变量,用*操作又等于提取内存的值。
其他的话,想不到什么原理,目的估计就是用着方便(不用写提取符号*)和实现特定绑定(不能更改的特性,或者也可以叫防呆设定吧,安全设定,引用比指针操作起来安全,这都算是优点)。
做一个char类型的例子,char &refC = c;可以看到refC实际上存了一个c的地址,而不是副本,所以这个实际需要的存储空间是一个指针的大小。
x0x8048566 push %ebp x
x0x8048567 mov %esp,%ebp x
x0x8048569 sub $0x10,%esp x
x0x804856c movb $0x63,-0x5(%ebp) x
B+ x0x8048570 lea -0x5(%ebp),%eax x
>x0x8048573 mov %eax,-0x4(%ebp) x
x0x8048576 mov -0x4(%ebp),%eax x
x0x8048579 movb $0x64,(%eax) x
x0x804857c mov $0x0,%eax 对于引用,sizeof()不能准确反映内部情况,也许是在sizeof()调用时通过地址找到原变量c,传递的时候就和普通变量正常调用一样。
实测,已经被编译器优化成这样了:
x0x80485b3 movl $0x1,0x18(%esp) 差点忘了,sizeof是操作符,并不是函数!!!!这个操作肯定是提前约定好了!!!因为在程序运行前,还有大篇幅的初始化之类的操作,看不太懂了。
至于给引用的赋值是直接在原变量的地址上赋值,还是把变量读出来?
(refI = 300)这是取出地址到eax,直接从eax取出内存地址,给内存赋值的。
B+>x0x80485df mov 0x2c(%esp),%eax x
x0x80485e3 movl $0x12c,(%eax) x
(refC = 'D'),同上
0x80485b4 mov 0x28(%esp),%eax x
x0x80485b8 movb $0x64,(%eax) 也是,只是赋值,不加减,从内存读到eax,再从eax写回去,没什么必要!
光顾着gdb调试看原理了,忘了总结一条重点了,函数参数为引用时,函数的栈不需要额外存储引用,实际上什么也不传,而是直接就用ebp和偏移去找。估计要靠编译器优化和记忆。见下图:局部变量temp是ebp负向偏移0x4,也就是在swap()当前栈;而a和b,实际上也就是i和j,靠ebp正向偏移0x8和0xc去找,也就是上一层的栈。(PS:栈是负向增长,压栈等于指针减,又因为ebp是栈底,所以ebp正向偏移就是上一层的栈空间了)
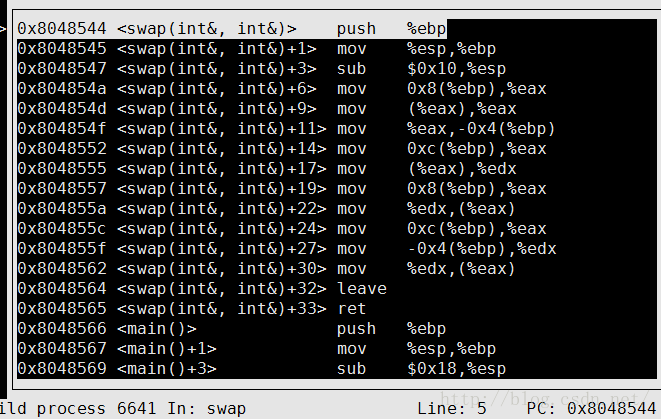
引用传递的优势终于找到了?(20200318:汇编情况可能和平台有关,寄存器方面的微小差别仍然不确定)
引用传递比较省栈空间,少申请就少开支,就更有效率吧?!
至于指针,还没试,但是根据指针的特性,空间开支是免不了的,借助指针能改原变量只是一种借助地址操作的巧妙用法,更改指针本身却不会对原变量产生任何影响。指针形参和其他形参本质上没有区别,都要分配空间,都是不影响原变量的副本。
那么引用的多层传递呢?按理说是一样的,这样多层传递的时候节省的开支就很可观了。(要和指针对比)
测试:
#include
#include
void func(int &c,int &d)
{
c = 1000;
d = 2000;
}
void swap(int &a,int &b)
{
func(a,b);
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
swap(i,j);
printf("i:%d,j:%d.\n",i,j);
}
调试
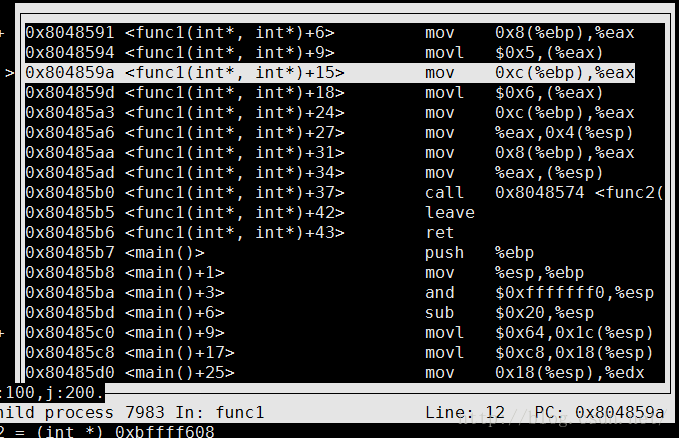
x0x8048591 mov 0x8(%ebp),%eax x
x0x8048594 movl $0x5,(%eax) x
x0x804859a mov 0xc(%ebp),%eax x
x0x804859d movl $0x6,(%eax) x x0x80485a3 mov 0xc(%ebp),%eax x
x0x80485a6 mov %eax,0x4(%esp) x
x0x80485aa mov 0x8(%ebp),%eax x
x0x80485ad mov %eax,(%esp) x
x0x80485b0 call 0x8048574 第一层func1(),用ebp正向偏移0x8和0xc去找地址进行操作。
(入栈sub 0x8,比较省,没复制那么多汇编语句进来看不到。)
在call func2之前,进行了两个变量地址的压栈操作,这样保证了下一个frame,也就是func2,的栈帧偏移仍然是0x8和0xc,但是这貌似还是要占用空间,并不能节省空间?或者说都免不了这一步(下边有说明,入栈传参,必须的步骤),总的来说还是要省?
x0x8048570 call *%eax x
x0x8048572 leave x
x0x8048573 ret x
x0x8048574 push %ebp x
x0x8048575 mov %esp,%ebp x
B+>x0x8048577 mov 0x8(%ebp),%eax x
x0x804857a movl $0x3e8,(%eax) x
x0x8048580 mov 0xc(%ebp),%eax x
x0x8048583 movl $0x7d0,(%eax) x
x0x8048589 pop %ebp x
x0x804858a ret
让func1和func2都传普通变量:
#include
#include
void func2(int c,int d)
{
c = 1000;
d = 2000;
}
void func1(int a,int b)
{
a = 5;
b = 6;
func2(a,b);
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
func1(i,j);
printf("i:%d,j:%d.\n",i,j);
}
其实不管是传递引用还是普通参数,调用函数前的压栈操作都一样的,都是压入到esp偏移0和偏移4(本例两个int变量),这两个栈空间应该就是为了向下传参用的(如果下边不调用func2(),会不会少开辟点栈空间?)
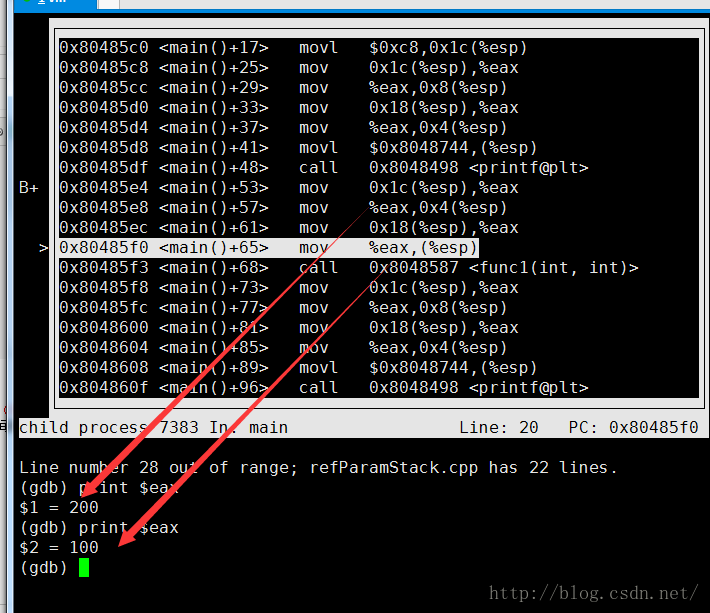
形参都要有,只不过传递引用是给地址,传递变量是给值。下图是形参传递数值的。
下图是引用传递地址的(负数十进制换算一下十六进制就好了):
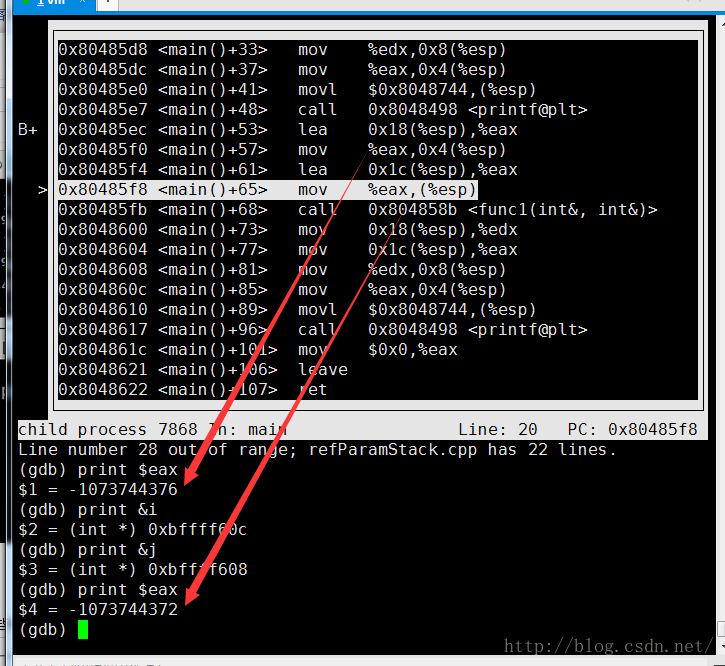
另外,到最后一层,func2()的时候,esp都没有自减操作了,是不需要么(另外,哪些栈空间是存返回值,以及如何返回,还没留意。。)
一个指针的例子,进行对比:
#include
#include
int func2(int *c,int *d)
{
*c = 1000;
*d = 2000;
}
int func1(int *a,int *b)
{
*a = 5;
*b = 6;
func2(a,b);
}
int main(){
int i = 100;
int j = 200;
printf("i:%d,j:%d.\n",i,j);
func1(&i,&j);
printf("i:%d,j:%d.\n",i,j);
}
如下图,调用函数时的传参,和引用是一样的
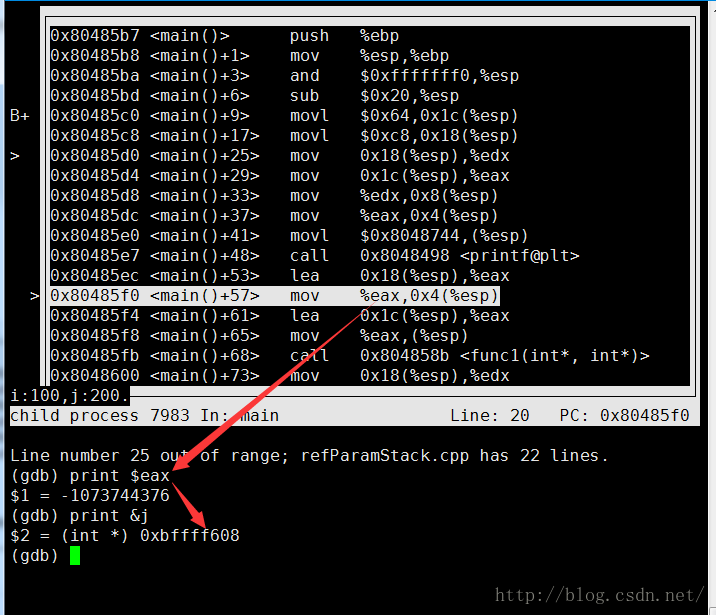
赋值操作也是一样的(提取地址到eax,再通过eax找到内存地址,对内存直接操作):
mov 0xc(%ebp),%eax
movl $0x6,(%eax)
额外加一句指针赋值:
int func1(int *a,int *b)
{
a = b;
局部栈变量a(副本)发生改变。
B+ x0x8048591 mov 0xc(%ebp),%eax x
x0x8048594 mov %eax,0x8(%ebp)
可见,局部的更改都只在局部栈空间,局部的指针变量的值。而指针对内容的修改,是因为对内存进行了提取,再对内存中的原变量进行操作。
而引用,首先要和指针一样传递地址,其次,修改时等于自动带了地址提取功能,改的是原变量的内存。
PS:仔细留意可以发现函数调用时,参数入栈顺序是反的。
比如i和j,传给a和b,先把j入栈,再把i入栈。
据说C/C++这样做的好处是支持可变参数列表(个数)。
再加一例测试:
#include
#include
int func2(int *c,int *d)
{
*c = 1000;
*d = 2000;
}
int func1(int *a,int *b,...)
{
a = b;
*a = 5;
*b = 6;
func2(a,b);
}
int main(){
int i = 100;
int j = 200;
int k = 300;
int l = 400;
printf("i:%d,j:%d.\n",i,j);
func1(&i,&j,&k,&l);
printf("i:%d,j:%d.\n",i,j);
}
调试,变量的声明:
x0x80485c6 movl $0x64,0x1c(%esp) x
B+ x0x80485ce movl $0xc8,0x18(%esp) x
x0x80485d6 movl $0x12c,0x14(%esp) x
x0x80485de movl $0x190,0x10(%esp) 调用函数时入栈顺序刚好相反:
B+ x0x8048602 lea 0x10(%esp),%eax x
x0x8048606 mov %eax,0xc(%esp) x
>x0x804860a lea 0x14(%esp),%eax x
x0x804860e mov %eax,0x8(%esp) x
x0x8048612 lea 0x18(%esp),%eax x
x0x8048616 mov %eax,0x4(%esp) x
x0x804861a lea 0x1c(%esp),%eax x
x0x804861e mov %eax,(%esp) 仔细分析,一个帧(frame)的栈结构也出来了:帧栈的前半部分(因为地址递减,所以是高地址)是本地参数,帧栈的后半部分(低地址)是保留下来,给函数传参用的。(大小随要调用函数的不同而不同。)
无法画线,大概示意图如下:
$ebp
i 0x1c(%esp)--------------------->|
j 0x18(%esp)-------------->| |
k 0x14(%esp)------->| | |
l 0x10(%esp)->| | | |
param4 0xc(%esp) <-| | | |
param3 0x8(%esp)<---------| | |
param2 0x4(%esp)<----------------| |
param1 0x0(%esp)<-----------------------|
$esp
x0x80485bd push %ebp x
x0x80485be mov %esp,%ebp x
x0x80485c0 and $0xfffffff0,%esp x
x0x80485c3 sub $0x20,%esp
不解的一点是,无论是两个参数还是4个参数,main压栈时都是同样的与操作和自减20。栈底都是esp偏移0x1c和0x18。但是这个栈空间只够4个参数的,五个怎么办?
下边是六个变量的声明和传参测试(代码就不贴了):
声明与定义:
0x80485bd push %ebp x
x0x80485be mov %esp,%ebp x
x0x80485c0 and $0xfffffff0,%esp x
x0x80485c3 sub $0x40,%esp x
x0x80485c6 movl $0x1,0x3c(%esp) x
x0x80485ce movl $0x2,0x38(%esp) x
x0x80485d6 movl $0x3,0x34(%esp) x
x0x80485de movl $0x4,0x30(%esp) x
x0x80485e6 movl $0x5,0x2c(%esp) x
x0x80485ee movl $0x6,0x28(%esp) x 传参与调用:
B+>x0x8048612 lea 0x28(%esp),%eax x
x0x8048616 mov %eax,0x14(%esp) x
x0x804861a lea 0x2c(%esp),%eax x
x0x804861e mov %eax,0x10(%esp) x
x0x8048622 lea 0x30(%esp),%eax x
x0x8048626 mov %eax,0xc(%esp) x
x0x804862a lea 0x34(%esp),%eax x
x0x804862e mov %eax,0x8(%esp) x
x0x8048632 lea 0x38(%esp),%eax x
x0x8048636 mov %eax,0x4(%esp) x
x0x804863a lea 0x3c(%esp),%eax x
x0x804863e mov %eax,(%esp) x
x0x8048641 call 0x804858b 总结或猜测,终于,main压栈,esp变成自减40了,估计是栈的一个取整的模式,够多少个变量和参数,main函数加0x10的栈空间。
PS:此例esp自减虽然是0x20,如果传参只传两个,esp总的自减是0x10,所以单位是0x10。下边的参数也有以0x10为单位的。
帧栈的顶格前(不是半)部分是参数,帧栈的顶格后(不是半)部分是要传递的参数,中间是预留。
示意图如下:
$ebp
i 0x1c(%esp)--------------------->|
j 0x18(%esp)-------------->| |
k 0x14(%esp)------->| | |
l 0x10(%esp)->| | | |
m
n
.........
........
param6
param5
param4 0xc(%esp) <-| | | |
param3 0x8(%esp)<---------| | |
param2 0x4(%esp)<----------------| |
param1 0x0(%esp)<-----------------------|
$esp
这样就直观了,帧栈的空间是要预先分配好的,多大就是多大,假设变量一百个,但是给函数传的参数未必有一百个,但总不能就用100+2的大小啊,所以要预留出来一定大小的空间,也就是中间的一片空白。
具体来说,这个大小应该是编译阶段根据实际代码已经计算出来决定了,不然怎么分配合适的大小呢。
当然变量和参数也不是对应关系,只是本例这样用,比如声明6个变量,传2个变量,栈空间是0x30。
最后,可变参数列表这多出来的参数要怎么使用呢?又没有形参。
用argv[]之类的?是默认的还是要手动写的?
前边的a和b也可以用argv[]吗?
这应该是另一个基础,我给忘了。