强化学习笔记+代码(七):Actor-Critic、A2C、A3C算法原理和Agent实现(tensorflow)
本文主要整理和参考了李宏毅的强化学习系列课程和莫烦python的强化学习教程
本系列主要分几个部分进行介绍
- 强化学习背景介绍
- SARSA算法原理和Agent实现
- Q-learning算法原理和Agent实现
- DQN算法原理和Agent实现(tensorflow)
- Double-DQN、Dueling DQN算法原理和Agent实现(tensorflow)
- Policy Gradients算法原理和Agent实现(tensorflow)
- Actor-Critic、A2C、A3C算法原理和Agent实现(tensorflow)
一、Actor-Critic
Actor-Critic是集合和ploicy gradient和Q-learning的方法。
先来回顾一下policy gradient:
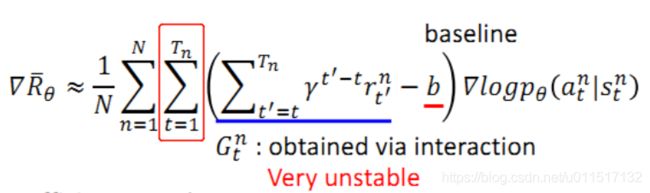
可以看出policy gradient是基于回合更新的,因此我们需要需要很大的耐心和环境产生交互样本,进行回合训练,并且由于每个回合是不稳定的,因此我们需要的大量的样本。

我们再来回顾一下Q-learning

Q-learning学习的是每个动作的价值,要求动作必须是离散的。
policy gradient和Q-learning都有各自的优缺点。我们可以将两者整合起来,即记忆使用off-policy的学习,也可以使用连续的动作。
下面两段话摘自莫烦python的强化学习教程:Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率。

Actor 和 Critic, 他们都能用不同的神经网络来代替 . 在 Policy Gradients 的影片中提到过, 现实中的奖惩会左右 Actor 的更新情况. Policy Gradients 也是靠着这个来获取适宜的更新. 那么何时会有奖惩这种信息能不能被学习呢? 这看起来不就是 以值为基础的强化学习方法做过的事吗. 那我们就拿一个 Critic 去学习这些奖惩机制, 学习完了以后. 由 Actor 来指手画脚, 由 Critic 来告诉 Actor 你的那些指手画脚哪些指得好, 哪些指得差, Critic 通过学习环境和奖励之间的关系, 能看到现在所处状态的潜在奖励, 所以用它来指点 Actor 便能使 Actor 每一步都在更新, 如果使用单纯的 Policy Gradients, Actor 只能等到回合结束才能开始更新。
以前我们用过回合的奖励来进行policy gradient的更新,Actor-Critic将回合奖励替换成动作的价值,来对网络进行学习,自然就将Q-learning结合了起来:

将奖励的期望 E ( G t n ) E(G^n_t) E(Gtn)替换为对应的动作价值 Q π θ ( s t n , a t n ) Q^{π_θ}(s^n_t, a^n_t) Qπθ(stn,atn),基准线 b b b替换为 V π θ ( s t n ) V^{π_θ}(s^n_t) Vπθ(stn)。(因为在policy gradient中b代表的是前面G的期望,因此使用 V π θ ( s t n ) V^{π_θ}(s^n_t) Vπθ(stn)是合适的)。
二、Advantage Actor-Critic(A2C)
但是上面Actor-Critic存在很大的缺陷,因为经过上面的结合后,模型会涉及到两个网络 Q π θ ( s t n , a t n ) Q^{π_θ}(s^n_t, a^n_t) Qπθ(stn,atn)和 V π θ ( s t n ) V^{π_θ}(s^n_t) Vπθ(stn)。两个网络同时在更新,这会让结果非常的不稳定。我们还需要对Actor-Critic进一步的优化。
我们考虑 Q ( s t , a t ) Q(s_t, a_t) Q(st,at)到底是什么呢? Q ( s t , a t ) Q(s_t, a_t) Q(st,at)是衡量的是状态 s t s_t st下动作 a t a_t at的价值。这个价值实际上执行动作 a t a_t at获得的奖励+下一个状态 s t + 1 s_{t+1} st+1的价值。于是我们有可以进行如下调整。

于是参数更新的梯度变为如下方式:

具体的,我们可以得到如下的学习方式:


即我们通过网络 V π ( s t n ) V^π(s^n_t) Vπ(stn)来指导学习,通过网络 π π π来执行动作(动作可以使不连续的)。由于对数据的浅层特征相对来说意义比较明确(比如CNN前几层提取通用特征),因此 V π ( s t n ) V^π(s^n_t) Vπ(stn)可以和 π π π共享部分参数(李宏毅老师的例子:阿光作为actor下棋,佐为做critic,非常的形象!强烈推荐这部动画,非常好看!!!):



三、Asynchronous Advantage Actor-Critic(A3C)
Asynchronous:非共时的
就是A2C复制多份,同时训练,加快模型整体的训练速度。


按照李宏毅老师的说法,没有硬件实力,可以不用去尝试A3C
四、Advantage Actor-Critic的Agent实现
本文相对于莫烦python中的案例改动比较多,由于莫烦python中的案例不稳定,很难收敛。对代码进行了一些改造,将Actor和Critic放在一个类中实现,并且共享了一部分权重。
本文基于如下架构进行Advantage Actor-Critic的Agent实现。其中Actor和Critic的第一层权重共享:

import numpy as np
import pandas as pd
import tensorflow as tf
import gym
class Advantage_Actor_Critic(object):
def __init__(self, n_features, n_actions, actor_lr=0.01, critic_lr=0.01, reward_decay=0.9):
self.n_features = n_features
self.n_actions = n_actions
#奖励衰减值
self.gamma = reward_decay
#actor网络学习率
self.actor_lr = actor_lr
#critic网络学习率
self.critic_lr = critic_lr
self._build_net() #建立网络
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
def _build_net(self):
tf.reset_default_graph() #清空计算图
#网络输入当前状态
self.s = tf.placeholder(tf.float32, [1, self.n_features], "state")
#当前选择的动作值,只要Critic使用
self.a = tf.placeholder(tf.int32, None, "act")
#Critic产生的td_error,用于更新Actor
self.actor_td_error = tf.placeholder(tf.float32, None, "td_error")
#下一步状态st+1的价值,用于更新Critic网络
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
#执行动作获得的奖励,由环境反馈
self.r = tf.placeholder(tf.float32, None, 'r')
#权重初始化方式
w_initializer = tf.random_normal_initializer(0.0,0.1)
b_initializer = tf.constant_initializer(0.1)
n_l1 = 20 #n_l1为network隐藏层神经元的个数
#此处Actor和Critic共享权重
with tf.variable_scope("share-l1"):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer)
l1 = tf.nn.relu(tf.matmul(self.s, w1)+b1)
#此处是属于Actor
with tf.variable_scope("Actor"):
w21 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer)
b21 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer)
#Actor的输出兀()
self.acts_prob = tf.nn.softmax(tf.matmul(l1, w21)+b21)
#创建Critic。输出当前状态s动作a的价值
with tf.variable_scope("Critic"):
w22 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer)
b22 = tf.get_variable('b2', [1], initializer=b_initializer)
#Actor的输出兀()
self.v = tf.matmul(l1, w22)+b22
#Critic的loss计算
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + self.gamma * self.v_ - self.v
self.critic_loss = tf.square(self.td_error)
with tf.variable_scope('critic_train_op'):
self.critic_train_op = tf.train.AdamOptimizer(self.critic_lr).minimize(self.critic_loss)
#Actor的loss计算
with tf.variable_scope('exp_v'):
#计算更新公式中梯度log部分
neg_log_prob = -tf.reduce_sum(tf.log(self.acts_prob)*tf.one_hot(self.a, self.n_actions), axis=1)
#计算损失,将之前policy gradient中的Gt和基准线b的差,改为Critic的td error即可
self.exp_v = tf.reduce_mean(neg_log_prob * self.actor_td_error)
with tf.variable_scope('actor_train_op'):
self.actor_train_op = tf.train.AdamOptimizer(self.actor_lr).minimize(self.exp_v)
def actor_learn(self, s, a, td):
s = s[np.newaxis, :]
#训练并返回损失
exp_v, _ = self.sess.run([self.exp_v, self.actor_train_op], feed_dict = {self.s: s, self.a: a, self.actor_td_error: td})
return exp_v
def critic_learn(self, s, r, s_):
#当前状态和下一个状态
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
#下一个状态st+1的价值
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.critic_train_op], {self.s: s, self.v_: v_, self.r: r})
#返回td_error用于更新Actor网络
return td_error
#需要根据actor选动作
def choose_action(self, s):
s = s[np.newaxis, :]
#得到动作的概率
probs = self.sess.run(self.acts_prob, {self.s: s})
#按照概率选择动作
action = np.random.choice(range(probs.shape[1]), p=probs.ravel())
return action
def run_maze(RENDER):
for i_episode in range(3000):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER:
env.render()
#根据actor输出概率选择动作
a = advantage_actor_critic.choose_action(s)
#根据选择动作,得到下一步状态、奖励、是否结束和信息
s_, r, done, info = env.step(a)
if done:
r = -20
#记录奖励
track_r.append(r)
#使用critic网络学习td error
td_error = advantage_actor_critic.critic_learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
#利用critic网络输出td error学习actor
advantage_actor_critic.actor_learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
#状态变动
s = s_
t+= 1
if done:
#当前回合获得的总奖励
ep_rs_sum = sum(track_r)
if 'running_reward' not in locals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD:
RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
if __name__=="__main__":
RENDER=False
DISPLAY_REWARD_THRESHOLD=200
env = gym.make('CartPole-v0')
env = env.unwrapped # 取消限制
env.seed(1)
N_F = env.observation_space.shape[0]
N_A = env.action_space.n
advantage_actor_critic = Advantage_Actor_Critic(n_features=N_F, n_actions=N_A)
run_maze(RENDER)
运行后学习效果如下:

可以看到,模型收敛很快,每次得到的奖励越来越多,能力越来越强!