Julia:高性能 GPU 计算的编程语言
【IT168 评论】Julia是一种用于数学计算的高级编程语言,它不仅与Python一样易于使用,而且还与C一样快。Julia是出于性能考虑而创建的,它的语法与其他编程语言相似,但是却拥有和编译型语言相媲美的性能。
如今,在多核CPU和大型并行计算系统的编程中,Julia已经非常受欢迎了。随着Julia的发展,其在GPU计算中也受到了众多青睐。GPU的性能可以通过提供更多的高级工具进行民主化,这些工具更易于被应用数学家和机器学习程序员使用。在这篇文章中,我将重点介绍使用Julia软件包CUDAnative.jl进行本地GPU编程,通过本地PTX代码生成功能增强Julia编译器。
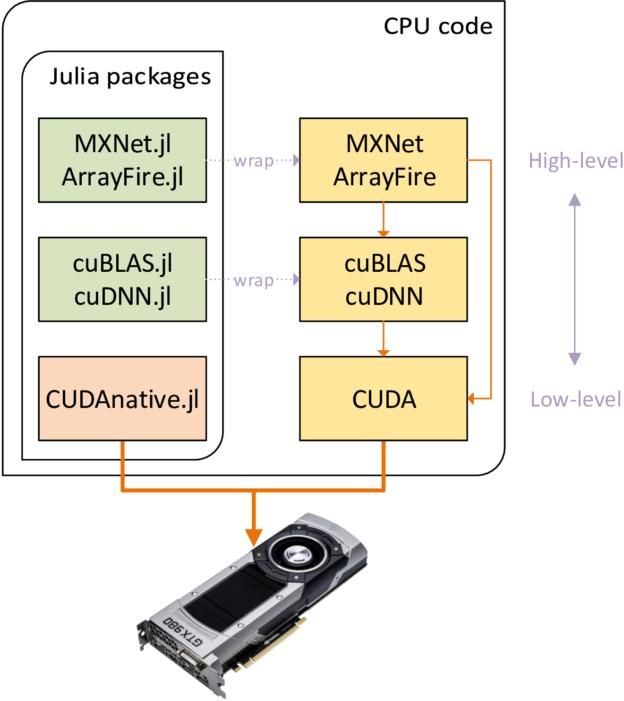
图1.使用不同抽象级别的库和Julia包进行GPU编程
现有的GPU-Accelerated Julia Packages
Julia包生态系统已经包含了相当多的与GPU相关且针对不同抽象级别的软件包,如图1所示。在最高抽象级别包括类似 和 TensorFlow.jl的域特定包,可以透明地使用系统中的GPU。使用ArrayFire 可以进行更通用的开发 ,如果需要线性代数或深层神经网络算法等专门的CUDA实现,可以使用供应商特定的软件包,如 或 cuDNN.jl。所有这些软件包本质上都是原生库的包装器,利用Julia的外部函数接口(FFI)以最小的开销调用库的API。如果想要了解更多信息,可以点击下面的GitHub地址:https://github.com/JuliaGPU/
这个列表中缺少的是最低的抽象级别,你可以在CUDA C ++中编写内核并管理执行。灵活的实现或优化现有软件包不能实现的抽象表达算法,是CUDAnative.jl的魅力所在。
基于CUDAnative.jl的Native GPU Programming
CUDAnative.jl包添加了原生GPU编程能力的Julia编程语言。与CUDAdrv.jl 或CUDArt.jl 包一起使用时,要分别与CUDA驱动程序和运行时库进行连接,之后就可以在Julia中进行低级别CUDA开发,而无需外部语言或编译器。下面的程序是演示如何计算两个向量的和:

这个例子的真正主力是@cuda macro,它生成专门的代码,用于将内核函数编译成GPU汇编,将其上传到驱动程序,并准备执行环境。与Julia的即时(JIT)编译器一起,形成非常有效的内核启动序列,从而避免了与动态语言相关联的运行时开销。生成的代码也有特定的参数类型; 使用不同类型的参数可以调用相同的内核。
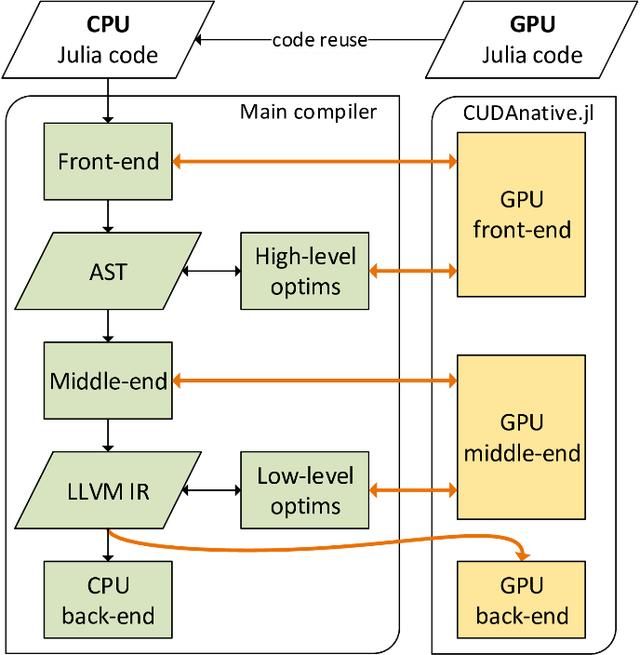
图2. CUDAnative.jl编译器的原理图。
Julia GPU编译器的设计避免提供自定义工具链来编译(GPU兼容的)Julia源代码到GPU汇编的子代。如图2所示,它尽可能地与现有的Julia编译器集成。只有在生成机器代码的最后一步才会完全支持GPU包。
重用Julia编译器有很多优点,首先硬件支持微小包:CUDAnative.jl只有1300行代码。其次,CUDAnative.jl避免了多个独立的语言实现,虽然可能会导致语法略有些不同,但同时你也可以像使用GPU代码一样使用Julia实现GPU功能。第三,你可以使用动态类型多方法,元编程,任意类型和对象等。当然这其中也会有一些不兼容或者限制,例如,限制缺乏Julia GPU运行时库、垃圾回收器,不过值得欣慰的是,Julia团队正在不断努力来覆盖更多语言和库。
示例: Parallel Reduction
Parallel Reduction是一个很有趣的例子,它是一种用于从输入值序列中计算总和或其他单个值的协作并行算法。本文中列举了Julia代码在一部分。
以下代码片段显示了使用GPU随机播放指令缩减内部函数。

该函数有两个参数,缩减运算符函数和减小值。Julia编译器基于这些参数的类型生成专用代码,不仅避免了运行时类型检查,而且完全内联函数参数。这可以在下面的代码清单中看到,当与+操作符一起调用此函数时生成PTX代码,以及作为参数的32位整数。
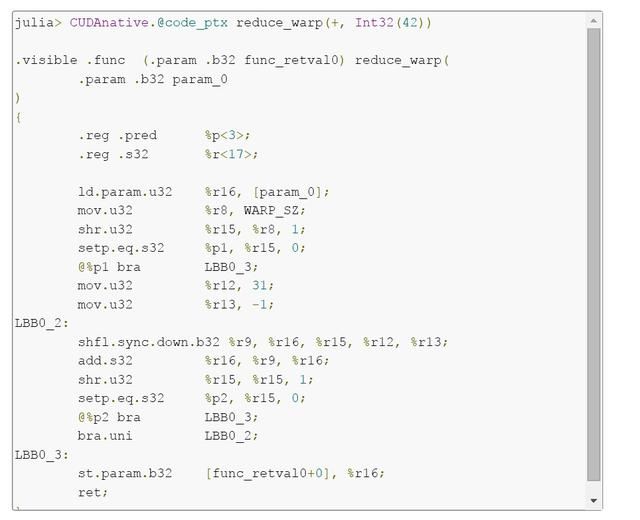
功能专业化是自动的,其赋予了Julia标准库中的大部分通用代码。在这个例子中,它生成了类似于nvcc的非常干净紧凑的PTX代码。
性能
前文我们介绍道CUDAnative.jl可以为小功能生成高效的PTX代码,但是其如何支持现实生活中的应用程序?为了评估这一点,Julia团队移植了 来异构加速Julia。因为移植这样的应用程序需要很大的努力,所以我们专注10个小基准。
图3中的图表比较了这些基准测试的原始CUDA C ++实现与Julia端口的性能。Julia版本几乎是逐字的端口,也就是说,没有算法变化,也没有引入高级概念。如图所示,使用Julia进行GPU计算并不会遭受任何广泛的性能损失。唯一的异常值是nn基准,与CUDAnative.jl相比,由于稍微更好的寄存器使用情况,其性能显着提高。平均来说,CUDAnative.jl端口与静态编译的CUDA C ++相同。
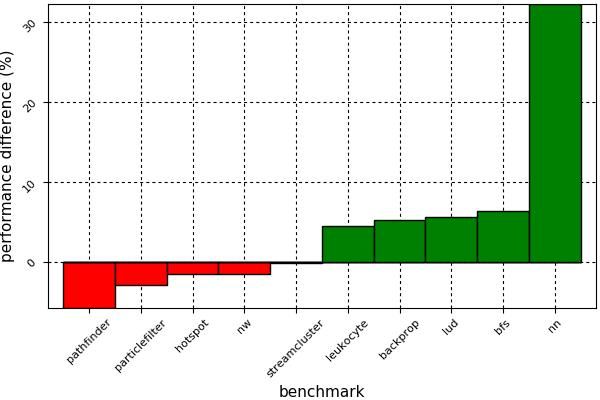
图3.来自Rodinia benchmark suite 几个基准测试的CUDA C ++和CUD
NVIDIA工具
CUDAnative.jl还旨在与CUDA工具包中的现有工具兼容。例如,它会生成必要的行号信息,以便NVIDIA Visual Profiler按预期的方式工作,并将 以进行更细粒度的控制。行号信息还可以与cuda-memcheck这样的工具相结合,实现精确的回溯:
LLVM NVPTX后端不支持完整调试信息 ,因此cuda-gdb无法正常工作。
高级编程
Julia动态语言语义的组合、专门的JIT编译器和一级元编程有可能创建非常强大的高级抽象,这在其他动态语言中是很难实现的。例如, CuArrays.jl 包将CUBLAS.jl的性能和CUDAnative.jl的灵活性相结合,提供了与Julia中其他阵列一样的CUDA加速数组。它建立在Julia对高阶函数的支持之上,这些功能是自动且专用的:在CuArray上调用映射或广播会生成专门针对操作和数组类型的内核,与上述reduce_warp示例非常相似。
此外,Julia最近已经获得了syntactic loop fusion的支持,根据介绍文档显示,假设我们实现了![]() ,现在要计算
,现在要计算![]() 并将结果存储在X中。你可以执行以下操作:
并将结果存储在X中。你可以执行以下操作:

整个计算将融合到单一的GPU内核,性能可以与hand-written 相当。代码是动态类型的,对于CPU阵列甚至是分布式容器,只要实现相关方法,它也同样适用。这被称为 duck typin,它更容易实现真正的通用代码。目前Julia团队正在努力实现所有必需的接口,以使用GPU阵列与ForwardDiff.jl或Knet.jl等软件包。
除此之外,Julia具有强大的外部功能界面,用于调用其他语言环境。它允许Cxx.jl这样的 ,和用于C ++的FFI,解析相应地头文件并调用函数。同时团队还在使用该接口来创建 CUDAnativelib.jl 来调用CUDA设备库,其中一些库作为模板化的C ++头文件发布。
前文中在GitHub中列出的许多软件包基本都已经成熟了,支持各种平台和Julia版本。但CUDAnative.jl及其依赖关系还没有那么成熟,例如兼容性方面仅支持Linux和MacOS。感兴趣的朋友可以去尝试!