KALDI之aishell模型说话人识别之V1
1.首先,成功安装kaldi在服务器上,用git clone那种方式安装(和在本地Unbuntu乌班图环境安装没区别)。
2数据准备部分
然后进入目录cd egs/aishell/V1
2.1首先改cmd的配置:
vim cmd.sh
- 1
改为:
export train_cmd=run.pl #"queue.pl --mem 2G":wq保存后。
2.2输入:
vim run.sh
看见data=/export/a05/xna/data改成想存放语料的路径,返回后,新建对应的文件夹。
下载并解压aishell 178小时语料库到相应的路径{
一、数据准备
1、首先在根目录下建立路径:/export/a05/xna/data然后下载数据集。这里下载数据集要在run.sh前面加sudo命令,这是路径的缘故。下载数据集用到的脚本是local/download_and_untar.sh 需要下载两个数据文件:data_aishell 和 resource_aishell.
2、数据准备阶段运行脚本:local/aishell_data_prep.sh 运行脚本后会产生 以下文件:
spk2utt: 这里存放的是测试集好训练集中每个样例名称及其它下面的语音文件名称。这个文件在test下面则说明是test集的相关信息,如果在train 文件下则说明是train集的相关信息。文件内容如下所示(只展示部分样例)
---------------------
作者:gwpjiayou
来源:CSDN
原文:https://blog.csdn.net/gwpjiayou/article/details/80255939
版权声明:本文为博主原创文章,转载请附上博文链接!
}
3.在v1目录下的run.sh有个数据准备的脚本
# Data Preparation
local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript

根据这个提示直接进入local
cd local然后打开 vim aishell_data_prep.sh (你注意下这个脚本要求的路径 和生成文件的路径就ok了)
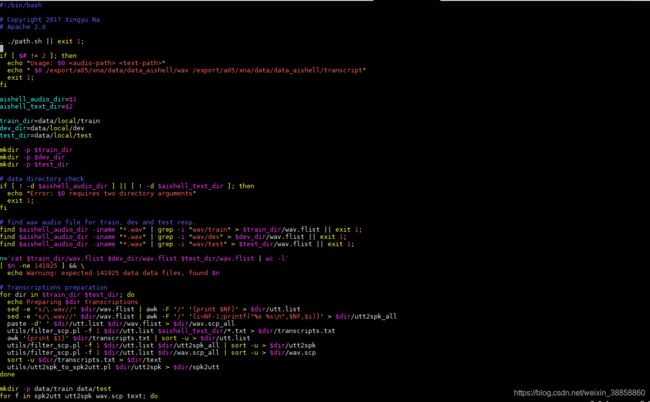
生成文件的路径:
{train_dir=data/local/train
dev_dir=data/local/dev
test_dir=data/local/test}
然后执行aishell_data_prep.sh(注意此时目录在local下,直接执行./aishell_data_prep.sh会报错《
./aishell_data_prep.sh: line 6: ./path.sh: No such file or directory
》没有这样的文件或者目录,aishell_data_prep.sh第6行提示![]() ,那么退出当前目录cd .. / ,然后在执行./aishell_data_prep.sh)
,那么退出当前目录cd .. / ,然后在执行./aishell_data_prep.sh)
然后又会报错
Usage: ./local/aishell_data_prep.sh
./local/aishell_data_prep.sh /mnt/md1/voiceprint/data/data_aishell/wav /mnt/md1/voiceprint/data/data_aishell/transcript 重新打开aishell_data_prep.sh找到错误(执行aishell_data_prep.sh文件时候没有传递参数(即路径变量wav和transcript))

然后重新执行aishell_data_prep.sh
./local/aishell_data_prep.sh /mnt/md1/voiceprint/data/data_aishell/transcript /mnt/md1/voiceprint/data/data_aishell/wav然后没反应 ,然后内心狂妄烦躁,最后发现wav和transcript路径变量的位置传递反了,一定要按着aishell_data_prep.sh文件里面变量位置参数来传递执行。正确执行在v1目录下如下:
./local/aishell_data_prep.sh /mnt/md1/voiceprint/data/data_aishell/wav /mnt/md1/voiceprint/data/data_aishell/transcript 然后会提示
data_aishell/transcript
Preparing mnt/md1/voiceprint/data/local/train transcriptions
Preparing mnt/md1/voiceprint/data/local/test transcriptions
./local/aishell_data_prep.sh: AISHELL data preparation succeeded
这就是所谓的数据准备部分完成了,生成所谓的spk2utt:文件,可以在cd kaldi-trunk/egs/aishell/v1/data/train目录下vim spk2utt查看它。
然后在/kaldi-trunk/egs/aishell/v1$ 目录下执行vim run.sh
注释掉#数据准备部分
# Data Preparation
local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript3.特征提取
然后目录切换到V1下,即
cd kaldi-trunk/egs/aishell/v1
#打开V1顶层run.sh
vim run.sh
然后看特征提取的提示部分,如下
mfccdir=mfcc
for x in train test; do
#重点还是进入steps目录下,根据make_mfcc.sh脚本提示生成相应的文件
steps/make_mfcc.sh --cmd "$train_cmd" --nj 10 data/$x exp/make_mfcc/$x $mfccdir
sid/compute_vad_decision.sh --nj 10 --cmd "$train_cmd" data/$x exp/make_mfcc/$x $mfccdir
utils/fix_data_dir.sh data/$x
done然后 cs steps,然后执行vim make_mfcc.sh,打开后如下

看上面图中的代码 echo "e.g.: $0 data/train exp/make_mfcc/train mfcc"照着这个格式准备三个文件,最后那两个应该是输出文件夹。后面两个是输出目录,你可以不用准备,它会自动帮你生成。
接下来你需要写这三个
1、data/train
2、exp/make_mfcc/train
3、mfcc
在kaldi-trunk/egs/aishell/v1/data下能查看到train,就说明已有data/train了。再接着打开train显示如下:
![]()
然后执行
./make_mfcc.sh data/train exp/make_mfcc/train mfcc会报错
![]()
./make_mfcc.sh data/train exp/make_mfcc/train mfcc
./make_mfcc.sh: line 19: parse_options.sh: No such file or directory
打开make_mfcc.sh第19行如下

然后退出执行下面代码
. ./cmd.sh
. ./path.sh
. utils/parse_options.sh || exit 1;注意.和.之间的空格
.空格./cmd.sh
然后我就这样被拒绝了-bash: ./cmd.sh: Permission denied
![]()
然后加权限
chmod 755 cmd.sh path.sh
chmod 755 utils/parse_options.sh || exit 1;
加完权限接着执行
. ./cmd.sh
. ./path.sh
. utils/parse_options.sh || exit 1;再次执行./step/make_mfcc.sh
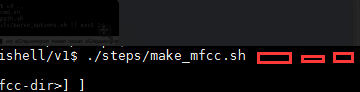
那又是一顿暴躁啊,注意图上代码的位置,变量传参又给狗吃了!!!!!
根据make_mfcc.sh文件里面的第23行 echo "e.g.: $0 data/train exp/make_mfcc/train mfcc"
在/mnt/md1/voiceprint/kaldi-trunk/egs/aishell/v1$目录下执行
./steps/make_mfcc.sh data/train exp/make_mfcc/train mfcc
./steps/make_mfcc.sh data/train exp/make_mfcc/train mfcc然后特征提取这部分成功提示如下:
