Sidecar和DaemonSet,WePay是如何选择的?

在我们最近的文章中,我们介绍了 使用Linkerd作为服务网格代理,并发起了一系列的文章,记录了WePay工程团队对于将服务网格和gRPC这样的模式和技术引入到基础设施的看法。
针对本系列的第二部分,我们将重点介绍一些我们一直在试验并且在Google Kubernetes Engine(GKE)中使用的容器模式。具体来说,我们将基础架构的一些服务(服务网格代理和其他代理等)引入到一个面向服务架构(SOA)的Kubernetes集群时用到了Sidecar和DaemonSet两种模式。

很久以前,在非常早期的Kubernetes集群中,许多微服务都是诞生自Google Cloud Platform项目,它们需要借助基础设施来完成日志采集,请求路由,监控度量及其他类似的工具集或者流程。随着时间的推移,每个微服务所提供的数据要么被其他的微服务消费,要么是一些站点可靠性工程师(SRE),开发工具和/或是产品开发工程师使用。
 图1:Kubernetes集群里最初的容器布局
图1:Kubernetes集群里最初的容器布局
加入到这些集群的每个微服务可以拥有多个副本,它的数量可以是一个或多个。图1展示了一个基础设施的样例,其中包括一些微服务,并且每个副本一侧均运行着多个Sidecar。对于开发,维护,监控或是消费这些微服务的人来说,包括可靠性,可维护性和生命周期在内的许多事情都非常重要。
下面,我们将根据这些需求深入研究Sidecar和DaemonSet这两种容器模式,并进行相互比较。具体来说,我们将会把注意力放在Kubernetes集群(这也是我们微服务的家)中机器资源的使用,Sidecar(代理)的生命周期管理以及不同应用程序的请求延迟等。
在比较DaemonSet和Sidecar模式时,首先想到的一点是,在生产级别的基础设施里,Sidecar模式最终会比DaemonSet模式占用更多的机器资源。总的来说,并非所有的基础设施服务或者代理都需要和我们的主应用程序并排部署。为此,我们将会研究一些案例,在这些案例中,我们致力于让我们的基础设施代理用于不止一个的跑在WePay Kubernetes集群里的应用主容器。
在运行不到10个微服务的基础设施中,这可能还不是一个需要直面的问题,但是随着基础设施的成熟和业务的增长,十个变成了二十或者三十个。实际上,它最终可能成长为拥有多个集群,其中包含超过几十甚至数百个需要监控和跟踪的微服务。
我们不妨考虑一下图1展示的基础设施里的三个微服务,最终我们将会有15个容器,其中只有20%是微服务的容器。如今,如果我们下定决心要向pool里加入更多的基础设施代理的话,那么使用的容器和资源数量会发生如下变化:
 函数1:基础设施里所有Sidecar模式的容器总数(N是微服务的数量)
函数1:基础设施里所有Sidecar模式的容器总数(N是微服务的数量)
按照函数1的等式添加新代理的话,我们将会从15个容器增长到20个,其中只有三个用于微服务。此外,我们注意到,有任何代理服务是通过像Java这样的资源密集型语言实现时,资源问题往往会变得更富有挑战,举个例子,随着时间的推移,内存使用量往往会大幅增长。
举一个现实生活中的例子,Buoyant最近主动从Scala和JVM(Linkerd)迁移到了Rust(Conduit),以便在Kubernetes或者任何其他容器化的基础设施中,服务网格代理能够运行的更轻更快。
基于我们在容器资源管理方面的经验,在我们打算往基础设施的容器池添加任何新代理时,我们主要把精力放在研究它们的资源利用率和空间占用。
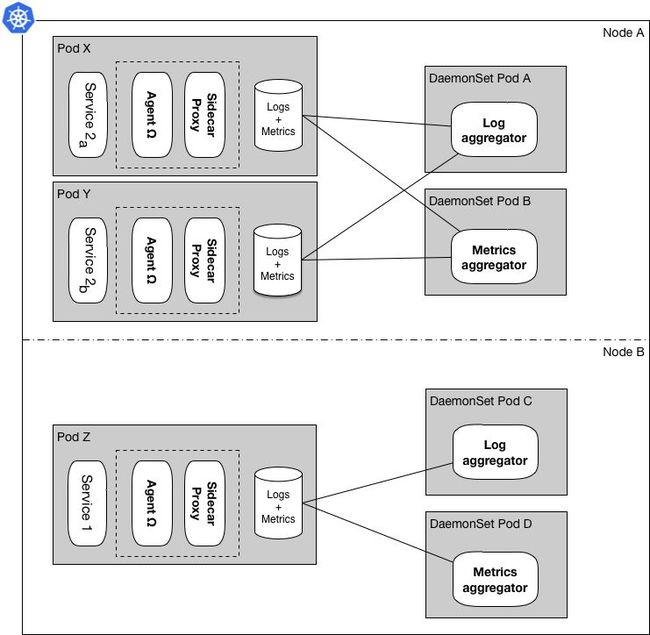 图2:一些agent重构成使用DaemonSet模式
图2:一些agent重构成使用DaemonSet模式
随着时间的推移,我们不断向集群里添加新的代理时,我们学到的一个更重要的经验教训是,一些代理可以一次性处理多个微服务容器而且可以用来监控整个容器池。举个例子,起初每个微服务容器都有一个日志聚合的Sidecar,它会将微服务的日志以流的形式传输到一个集中式的日志栈,但是随着集群的增长,我们将这些聚合器重构成了图2所示的模式。
在这张图中,日志记录和监控指标的聚合代理处理的是所分配的节点中所有服务容器的日志和监控指标数据,而不是图1中的一对一关系,而Sidecar代理和代理Ω则继续保留与他们的微服务容器一对一的关系。使用这种混合模式,我们能够显著的减少代理容器的数量,从前面的例子中可以看到,所有容器的总和从20变成了16:
 公式2:基础设施里所有DaemonSet模式的容器总数(N是微服务的数量)
公式2:基础设施里所有DaemonSet模式的容器总数(N是微服务的数量)
如今基础设施上已经运行了超过数十个的微服务,而随着向生产环境添加更多新的基础设施代理,它还将持续体现出资源使用方面显著的改善。
在WePay,我们遵循敏捷开发的软件模式来开发我们的产品和工具,因此,从开发,审查/更新,再到部署,我们一直重复这样的循环,直到有一天开发的软件不再使用或者下线方才结束。对于基础设施里使用的所有代理程序,无论它是一个开源项目还是内部构建的,它们均有各自的生命周期,而且对于任何代理程序上的任何改进都需要发布到所有活跃环境。
在实现我们的应用程序容器和部署我们的代理程序的过程中,我们已经意识到,维护Sidecar模式并不一定都是好的做法,而且可能被过度使用的主要理由有两个。上面提到的第一个问题,是浪费了机器资源,第二个问题则是代理和微服务容器的生命周期之间的差异。换句话说,尽管我们将一些容器紧密地捆绑在一起可能是有其实际意义的,但是对于部署到整个集群的所有容器来说,并非都需要以这个模式运行。
举个例子,比如本系列前一篇文章中所提到的,一个服务网格代理会被用于将请求从出发地路由到目的地,下面图3展示了使用Sidecar模式的请求。
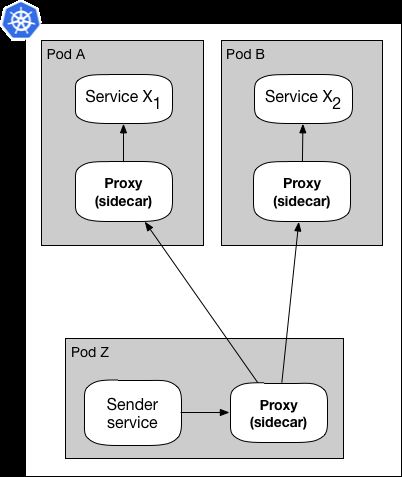 图3:使用网格代理Sidecar的Sidecar模式
图3:使用网格代理Sidecar的Sidecar模式
Sender服务将请求发送到一侧的Sidecar代理,该代理通过服务发现选择目标代理,而最终,目标代理(例如在Pod A中)将请求转发到服务X*1容器。图4展示了使用DaemonSet模式实现相同的功能:
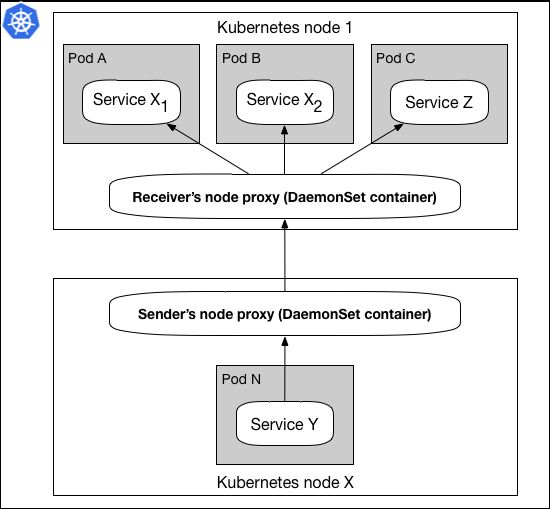 图4:使用网格代理节点容器的DaemonSet模式
图4:使用网格代理节点容器的DaemonSet模式
无论这些代理中的任何一员是否部署在应用程序容器一侧,该代理仍然能够实现它的目的,这意味着它的逻辑和执行独立于任何应用程序容器(我们将在下一节中讨论网络范畴)。
这适用于所有安装在Kubernetes集群中的容器以及独立部署的代理。当然,这里假设在Sidecar和DaemonSet模式之间转换时没有任何功能或数据访问方面的损失。
Sidecar模式在生命周期方面的挑战非常大,我们开始看到一些服务栈自身提供的一些工具,比如Istio的sidecar-injector以及Linkerd项目中的linkerd-inject,它们允许在一个单独的地方配置代理Sidecar。值得一提的是,集中配置Sidecar只能简化配置,并不能解决同一Kubernetes Pod中容器执行的中断问题。在大多数情况下,用户需要重新创建整个Pod以使得所有更改对Pod生效。在图3中,如果需要更新代理(Sidecar),则必须重新启动/重新创建整个Pod才能让变更生效。这意味着必须停止Pod A中的所有容器,重新创建一个Pod来代替Pod A。
然而,如果这些容器的生命周期是分开的,就像在DaemonSet模式下那样,更新一个容器不会中断其他容器,而且减少了不可预知的问题以及宕机的风险。举个例子,在图2中,DaemonSet Pod C中的日志聚合器的升级不会中断跑在Pod Z里的服务1,而这在很多用例中都可以派上用场。
不同的模式之间常常讨论的另一个主要区别是数据和代理之间的距离。这意味着,分别在Sidecar和DaemonSet模式下发出的相同请求,代理发送或者接收需要经过的跳数或重定向次数之间的差异。

如图5所示,在最坏的情况下,发送到Sidecar容器的请求需要的步骤更少并且传输的更快。在这种情况下,当sender服务发送包并使用localhost将该包传输到目的地时,要想将包发送到代理的话只需要在同一网络空间里将其转发到相应的端口即可。另一方面,当使用主机名或者IP发送相同的包到代理时,除了localhost的传输步骤之外,还需要经过主机名解析并且网络传输路径也更远。
延迟这方面的话,如果使用高性能的域名解析服务和网络传输设备,多余的步骤是可以省略的,但是网络空间和传输范围是两个容器模式之间的最显著的差异。

图6展示了我们在调研中考虑的另一个侧重点,请求分组。 DaemonSet容器必须为集群节点中的所有目标容器提供服务,而Sidecar容器只需要关注跑在Pod里的容器。这种分组可能对某些代理有意义。
在Sidecar和DaemonSet模式之间进行选择时会有许多不同侧重点的考虑,但是多年来机器资源的使用,代理和微服务的生命周期管理以及不同应用程序之间的请求延迟一直是我们关注的焦点。具体来说,我们最终的使用方式如下:
使用DaemonSet模式降低资源使用量
在我们可以使用DaemonSets的情况下,让应用程序和基础架构代理的升级变得更加轻松
再者,在必要时优化容器之间的延迟。
原文链接:https://wecode.wepay.com/posts/scds-battle-of-containerization

