数据结构java版本
文章目录
- 数据结构java版本
- 1.Array
- 2. Stack
- 3. Queue
- 4. LinkedList
- 5. Tree
- 5.1 树 Tree
- 5.1.1 二分搜索树 Balanced Binary Tree
- 5.1.2 平衡二叉树
- 5.1.3 2-3树
- 5.1.4 红黑树
- 5.2 树相关的其它数据结构
- 5.2.1 堆Binary Heap 和优先队列 PriorityQueue
- 5.2.2 线段树 (区间树) Segment Tree
- 5.2.3 字典树(前缀树,n叉树)Trie
- 5.2.4 并查集 Union Find
- 6. Set和Map
- 7. 哈希表
- 1. 哈希函数设计
- 2. 哈希冲突
- 8.总结
- 书籍
数据结构java版本
基于liuyubobobo老师的玩转算法系列–玩转数据结构 更适合0算法基础入门到进阶(java版)
源代码 https://github.com/liuyubobobo/Play-with-Data-Structures
数据结构与算法Java版本
数据结构: 逻辑结构 + 物理结构
四大逻辑结构
- 集合
- 线性
- Array
- Stack
- Queue
- LinkedList
- 树形
- 图形
物理结构(数据元素在内存中的存储形式)
- 顺序存储
- 链式存储
1.Array
CRUD
动态数组: 扩容 2*capacity ,缩容 capacity/4
泛型 : Array array = new Array<>();
2. Stack
只能从一端进行数据操作
FILO: first in last out 先进后出 相当于约一个木桶
void push(E) 添加元素 入栈
E pop() 栈顶拿出元素 出栈
E peek() 查看栈顶元素
int getSize() 栈中有多少元素
boolean isEmpty() 栈中是否为空
底层实现可以使用 动态数组实现以上操作 class ArrayStack implements Stack
应用: 编译器 >> 括号匹配 [Leetcode 20.有效的括号]
3. Queue
队列是数组的子集,只能从队尾添加元素,从队首取出元素
Queue
- void enqueue(E) 插入队尾
- E dequeue() 取出队首元素
- E getFront() 查看队首元素
- int getSize()
- boolean isEmpty()
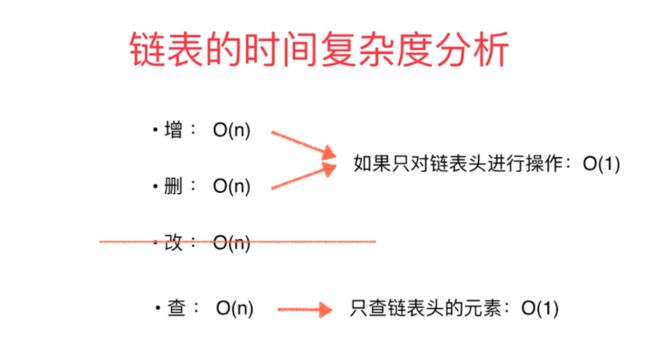
使用ArrayQueue implements Queue时,dequeue()取出队首元素是 O(n)的 时间复杂度,因为每次拿出数组0的元素时,其他数据要向前挪动一位。
使用循环队列可以解决这个问题,也就是添加两个标记front(头),tail(尾)。取出队首元素时,改变front和taiil位置使得实际存储不需要再进行挪动。

4. LinkedList

-
数据存储在“节点”(Node)中
class Node{ E e; Node next; }
5. Tree
二分搜索树 (Binary Search Tree)
平衡二叉树 ( Balanced Binary Tree );红黑树
堆;并查集
线段树;Trie(字典树,前缀树)
5.1 树 Tree
5.1.1 二分搜索树 Balanced Binary Tree
public class BST<E extends Comparable<E>> {
private class Node {
public E e;
public Node left, right;
public Node(E e) {
this.e = e;
left = null;
right = null;
}
}
private Node root;
private int size;
}
元素个数。
添加元素。
// 向二分搜索树中添加新的元素e
public void add(E e){
root = add(root, e);
}
// 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e){
if(node == null){
size ++;
return new Node(e);
}
if(e.compareTo(node.e) < 0)
node.left = add(node.left, e);
else if(e.compareTo(node.e) > 0)
node.right = add(node.right, e);
return node;
}
查找是否包含元素。
// 看二分搜索树中是否包含元素e
public boolean contains(E e){
return contains(root, e);
}
// 看以node为根的二分搜索树中是否包含元素e, 递归算法
private boolean contains(Node node, E e){
if(node == null)
return false;
if(e.compareTo(node.e) == 0)
return true;
else if(e.compareTo(node.e) < 0)
return contains(node.left, e);
else
return contains(node.right, e); //e.compareTo(node.e) > 0
}
遍历:
-
深度(深度优先)遍历: **前preOrder,中inOrder,后序postOrder遍历,中序遍历打印后所有元素就是有序,后序变量会先将当前数下的所有子树打印。**先延树的一支往下遍历最深的树。
// 二分搜索树的前序遍历 public void preOrder(){ preOrder(root); } // 前序遍历以node为根的二分搜索树, 递归算法 private void preOrder(Node node){ if(node == null) return; System.out.println(node.e); preOrder(node.left); preOrder(node.right); } // 二分搜索树的中序遍历 public void inOrder(){ inOrder(root); } // 中序遍历以node为根的二分搜索树, 递归算法 private void inOrder(Node node){ if(node == null) return; inOrder(node.left); System.out.println(node.e); inOrder(node.right); } // 二分搜索树的后序遍历 public void postOrder(){ postOrder(root); } // 后序遍历以node为根的二分搜索树, 递归算法 private void postOrder(Node node){ if(node == null) return; postOrder(node.left); postOrder(node.right); System.out.println(node.e); }-
Non-Recursion-PreOrder :非递归的前序遍历可以使用栈来实现。
// 二分搜索树的非递归前序遍历 public void preOrderNR(){ if(root == null) return; //使用栈保存二分 //获取栈顶元素在将树的右子树和左子树分别压入栈 Stack<Node> stack = new Stack<>(); stack.push(root); while(!stack.isEmpty()){ Node cur = stack.pop(); System.out.println(cur.e); if(cur.right != null) stack.push(cur.right); if(cur.left != null) stack.push(cur.left); } }
-
-
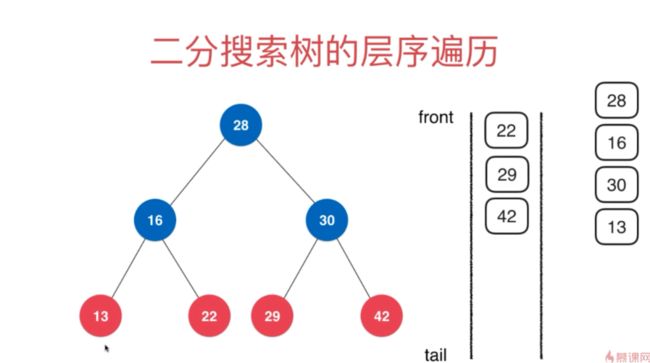
层序(levelOrder,广度优先)遍历:将树的每一层遍历出来。要使用队列将节点入队,取出是将节点的左右子节点再入队。这样就保证取出的元素一定是一层层获取的。
// 二分搜索树的层序遍历 public void levelOrder(){ if(root == null) return; Queue<Node> q = new LinkedList<>(); q.add(root); while(!q.isEmpty()){ Node cur = q.remove(); System.out.println(cur.e); if(cur.left != null) q.add(cur.left); if(cur.right != null) q.add(cur.right); } } -
选择深度还是广度在遍历效果都是一样的,但是进行搜索就会不同。如果结果在右子树,那么使用深度需要很久才能找到对应的,这就适合使用广度遍历,所以使用哪个遍历跟搜索策略有关。
删除节点:

-
删除最小节点
// 返回以node为根的二分搜索树的最小值所在的节点 private Node minimum(Node node){ if(node.left == null) return node; return minimum(node.left); } // 从二分搜索树中删除最小值所在节点, 返回最小值 public E removeMin(){ E ret = minimum(); root = removeMin(root); return ret; } // 删除掉以node为根的二分搜索树中的最小节点 // 返回删除节点后新的二分搜索树的根 private Node removeMin(Node node){ if(node.left == null){ Node rightNode = node.right; node.right = null; size --; return rightNode; } node.left = removeMin(node.left); return node; } -
删除最大节点
// 返回以node为根的二分搜索树的最大值所在的节点 private Node maximum(Node node){ if(node.right == null) return node; return maximum(node.right); } // 从二分搜索树中删除最大值所在节点 public E removeMax(){ E ret = maximum(); root = removeMax(root); return ret; } // 删除掉以node为根的二分搜索树中的最大节点 // 返回删除节点后新的二分搜索树的根 private Node removeMax(Node node){ if(node.right == null){ Node leftNode = node.left; node.left = null; size --; return leftNode; } node.right = removeMax(node.right); return node; } -
删除任意节点
-
如果删除节点左子树为空
-
如果删除节点右子树为空
-
如果删除节点左右子树都不为空
1960年Hibbard提出-Hibbard Deletion:
// 从二分搜索树中删除元素为e的节点 public void remove(E e){ root = remove(root, e); } // 删除掉以node为根的二分搜索树中值为e的节点, 递归算法 // 返回删除节点后新的二分搜索树的根 private Node remove(Node node, E e){ if( node == null ) return null; if( e.compareTo(node.e) < 0 ){ node.left = remove(node.left , e); return node; } else if(e.compareTo(node.e) > 0 ){ node.right = remove(node.right, e); return node; } else{ // e.compareTo(node.e) == 0 // 待删除节点左子树为空的情况 if(node.left == null){ Node rightNode = node.right; node.right = null; size --; return rightNode; } // 待删除节点右子树为空的情况 if(node.right == null){ Node leftNode = node.left; node.left = null; size --; return leftNode;565 // 待删除节点左右子树均不为空的情况 // 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点 // 用这个节点顶替待删除节点的位置 Node successor = minimum(node.right); successor.right = removeMin(node.right); successor.left = node.left; node.left = node.right = null; return successor; } } -
5.1.2 平衡二叉树
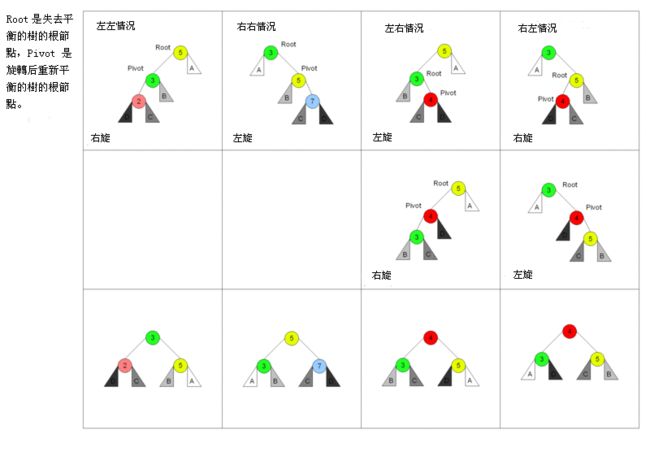
AVL树:有树的发明人G.M.Adelson-Velsky和E.m.Landis名字的首字母组成。对于任意一个节点,左右子树的高度差不能超过1。


向y的左子树插入元素,导致y.factory>1,而x,z都还是AVL树
插入前
y.factory = getBalanceFactor(node) = getHeight(x) - getHeight(T4)=1
插入后
y.factory = getBalanceFactor(node) = getHeight(x) - getHeight(T4)>1
结论:插入后x的高度要变大1,但x的平衡因子还要满足高度差不大于1,高度不变的情况都不会导致平衡因子的变化
| 插入前 | 插入后 | |||
|---|---|---|---|---|
| x.factory=-1(×) | 向z添加元素,z的高度不变(×) | |||
| 向z添加元素,z的高度+1 | x.factory=0,x的高度不会变化(×) | |||
| 向T3添加元素,T3的高度不变(×) | ||||
| 向T3添加元素,T3的高度+1 | x.factory=-2,x的平衡因子>2,不满足条件(×) | |||
| x.factory=0 | 向z添加元素,z的高度不变(×) | |||
| 向z添加元素,z的高度+1 | x.factory=1,x.hight+1(✔) | |||
| 向T3添加元素,T3的高度不变(×) | ||||
| 向T3添加元素,T3的高度+1 | x.factory=-1,x.hight+1(✔) | |||
| x.factory=1(×) | 向z添加元素,z的高度不变(×) | |||
| 向z添加元素,z的高度+1 | x.factory=2,x的平衡因子>2,不满足条件(×) | |||
| 向T3添加元素,T3的高度不变(×) | ||||
| 向T3添加元素,T3的高度+1 | x.factory=0,x的高度不会变化(×) |

5.1.3 2-3树
2-3树和红黑树是等价的。理解了2-3树对理解B类树也有很大帮助。
一个节点可以存放一个(正常树节点)或着两个元素(左边比右边小,有三个引用指向比两个元素小,在两个元素中间和比两个元素大的节点)


2-3树添加元素永远不会添加到一个为空的位置,会添加到最后一个叶子节点上。
如果添加的节点变成了四节点,会将四节点变成二节点。
-
如果添加元素插入2-节点

-
如果添加元素插入3-节点
-
如果3-节点没有父节点

-
如果3-节点父节点是2-节点


-
如果3-节点父节点是3-节点


-
例如:
-
2-3树为空的时候添加一个节点42
-
再添加一个节点37,会和之前的节点融合


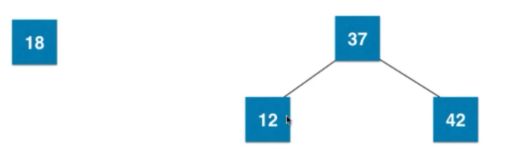
3. 添加一个节点12,会先和37,42组成三节点,然后拆成一个子树。



-
添加一个节点18

-
添加一个节点6




-
添加一个节点5




5.1.4 红黑树
红黑树和2-3树等价,将3-节点中左边的元素定义为红节点,将右边的元素定义为黑色的节点。
使用二分搜索树来定义三节点。
左倾红黑树:



红黑树的性质
- 每个节点或者是红色或者是黑色。
- 根节点是黑色节点。
- 每一个叶子节点(最后的空节点)是黑色的。空树本身也是红黑树,此时节点也是黑色的。
- 如果一个节点是红色的,那么他的孩子节点都是黑色的。
- 从任意一个节点到叶子节点,经过的黑色节点个数是一样的。(红黑树是保持“黑平衡”的二叉树,红黑树不是完全平衡二叉树,最大高度:2logn)
红黑树的时间复杂度
对红黑树的增删改查的时间复杂度:O(logn)
-
添加元素


红黑树相关问题
Splay Tree (伸展树):另一种统计性能优秀的数结构。
Splay Tree应用了局部性原理:刚被访问的内容下次高概率再次被访问。
java.util中的TreeMap和TreeSet基于红黑树。
算法导论中红黑树有不同的实现。
5.2 树相关的其它数据结构
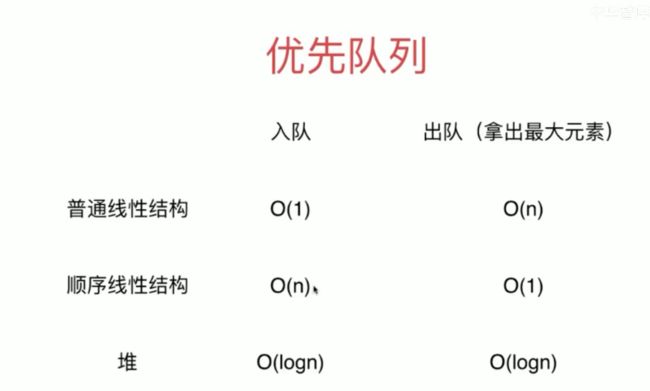
5.2.1 堆Binary Heap 和优先队列 PriorityQueue
-
队列
普通队列: 先进先出,后进后出
优先队列 PriorityQueue:出队顺序和入队顺序无关,和优先级有关
广义队列:栈也可以理解为一个队列
-
堆
二叉堆 Binary Heap
-
二叉堆是完全二叉树(子节点都在同一层)
-
堆中每个父节点都大于其子节点(最大堆,如果父节点小于子节点就是最小堆)
-
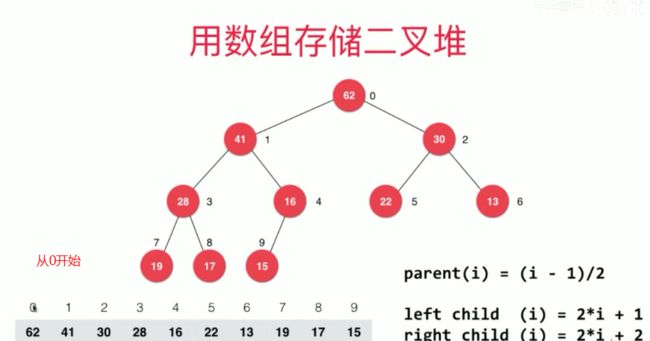
可以使用数组存放堆
-
如果起始位从下标1开始:
下标n对应的父节点下标 parent(n)= n/2
下标n对应的左子树节点下标 leftChild(n)=2n
下标n对应的右子树节点下标 rightChild(n)=2n+1
-
如果起始位从下标0开始:
下标n对应的父节点下标 parent(n)= (n-1)/2
下标n对应的左子树节点下标 leftChild(n)=2n+1
下标n对应的右子树节点下标 rightChild(n)=2n+2
-
添加元素 sift up(上浮)

取出元素 extract sift down (只取出堆顶元素)


replace:取出最大元素后,放入一个新元素
实现 1. 先extractMax,在add,两次O(logn)操作
2. 直接将堆顶元素替换后Sift Down ,一次O(logn)操作
heapify:将任意数组整理成堆的形状
问题:在N个元素中选出前M个元素
时间复杂度:
排序:NlogN
使用优先队列:NlogM
使用优先队列,维护当前看到的前M个元素(需要使用最小堆或者定义元素值越小优先级越高(重写CompareTo方法))
问题: 获取数组N出现频率最高的前M个元素
java的PriorityQueue是最小堆,先将数组N存入TreeMap其他堆:

index heap 索引堆
二项堆
斐波那契堆
-
5.2.2 线段树 (区间树) Segment Tree
Segment Tree:线段树不是完全二叉树,是平衡二叉树,堆也是平衡二叉树(数的最深和最浅之差小于1)
线段树经典问题:
区间染色问题。一段墙进行染色(每次颜色可以覆盖上次的颜色),m次操作后我们可以在[i,j]区间内看到多少种颜色?
| 使用数组 | 使用线段树 | |
|---|---|---|
| 染色操作(更新区间) | O(n) | O(logn) |
| 查询操作(查询区间) | O(n) | O(logn) |
基于一段区间(区间内数据在不停变化)的统计查询
2018年注册用户到现在(时间不停变化,用户也在消费)为止消费最高的用户?消费最少的用户?学习时间最长的用户?某个空间中天体总量(天体会运动或爆炸)?
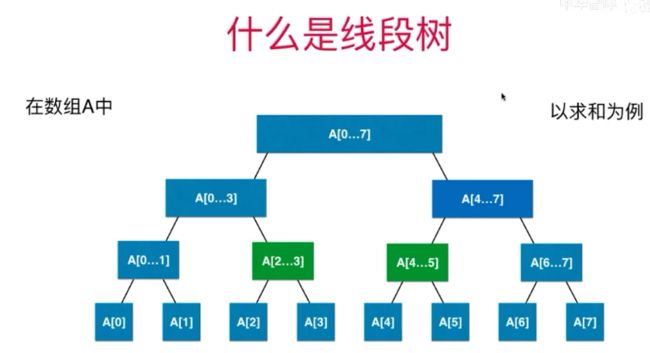


如果使用数组存储线段树(知道某个节点元素在数组中的下标,可以计算出节点的父节点和左右子节点下标,从而找到对应元素),如果区间有n个元素,数组表示这个线段树需要4n个元素空间。(我们不考虑添加元素,即区间固定,使用4n的静态空间即可。)
区间相关问题RMQ(Range Minimun Query)解决:
有的也可以使用树状数组Binary Index Tree这个数据结构解决。
5.2.3 字典树(前缀树,n叉树)Trie
Trie(前缀树):提高字符串查询效率


压缩字典树 Compressed Trie

三分搜索树 Ternary Search Trie 每个节点只有三个孩子,大于等于小于的三个节点。

还有一种数据结构:后缀树。
更多字符串问题:
子串查询:经典算法(KMP,Boyer-Moore,Rabin-Karp)
文件压缩,模式匹配(正则表达式),编译原理(代码也是字符串,进行编译)
5.2.4 并查集 Union Find
并查集 Union Find可以非常高效的解决网络中节点连接状态的问题。
网络中节点的连接状态:
- 网络是一个抽象的概念,如:用户之间形成的网络
- 数学中的集合类的实现
两个节点的连接问题和路径问题的区别:
- 连接问题比路径问题的答案跟少。
- 比如堆NLogM和二分搜索树NLogN。
主要有以下方法
union(p,q):合并p对应的元素和q对应的元素
isConnectioned(p,q):查询是否可连接

public interface UnionFind{
int getSize();
//p和q是对应合并的数组元素对应的下标
boolean isConnected(int p, int q);
void unionElements(int p, int );
}

基于树高度(rank)的优化:控制链表深度,每次将节点深度小的集合合并到深度高的集合中的根节点上。为什么叫rank呢?因为当进行了路径压缩后,高度就会变化,但是我们并不需要维护高度,路径压缩后,两个节点对应的rank(范围)对比大致是一样的,我们只要求元素是否可关联,不需要精确维护高度信息,所以被称为rank优化。
Path Compression(路径压缩)
路径压缩方法一:在find查找时,将当前节点的父节点指向父节点的父节点。
parent[p] = parent[parent[p]]

路径压缩方法二:在find查找时,将当前节点的所有节点都直接指向根节点。

6. Set和Map
集合和映射(或称为字典)是高层数据结构(队列和栈也是,我们设计好这些数据结构的接口,使用底层数据结构实现。底层可以用数组,链表或树实现。)

7. 哈希表
哈希表充分体现了算法设计领域的经典思想:空间换时间。
哈希表的两个需要解决的问题:
-
哈希函数:对一个键值对象,将键通过一个函数转化为索引,这个函数就是哈希函数。键通过哈希函数得到的索引分布越均匀越好。
-
哈希冲突:当多个键经过哈希函数得到的索引一样时,就产生了哈希冲突。

1. 哈希函数设计
-
整数
小范围正整数直接使用
小范围负整数进行偏移 如:-100 ~ 100 >> 0 ~ 200
大整数
如身份证号,通常做法:取模 比如取大整数后四位 mod 10000,取模时摸一个素数可以使得得到的索引分布越均匀。

图片来源: http://planetmath.org/goodhashtableprimes
-
浮点型
在计算机中都是32或64位的二进制表示,只不过计算机解析成了浮点数,我们可以将这个表示浮点的二进制直接当做整型处理。
-
字符串
可以将字符串转成整形处理


int hash = 0; for (int i = 0; i < s.length; i++) { hash = (hash * B + s.charAt(i)) % M;复合类型

哈希函数设计原则:
- 一致性:如果a == b,则hash(a) == hash(b)
- 高效性:计算高效简洁
- 均匀性:哈希值均匀分布
-
java中提供了hashCode
2. 哈希冲突
链地址法 Seperate Chaining 分离链


M要变成动态变化,当n变大时,m也变大,重构hashTable。
平均每个地址承载的元素多过一定的程度,进行扩容:
N / M >= upperTol (tolerance容忍,公差) upperTol = 10
当 N / M < lowerTol 时进行缩容。 lowerTol = 2
哈希表:均摊复杂度为O(1)
相对于树,牺牲了:顺序性
更多哈希冲突的处理方法:
我们上面用的是封闭地址法: Seperate Chaining
开发地址法:Open Addressing
再哈希法:Rehashing
Coalesced Hashing :综合了Seperate Chaining 和 Open Addressing
8.总结


书籍
-
算法4 (Algorithms)
-
算法导论