1、安装scrapy,pip install scrapy即可
2、新建项目scrapy startproject jdtu,类似django的新建项目方式,建好好目录层级如下
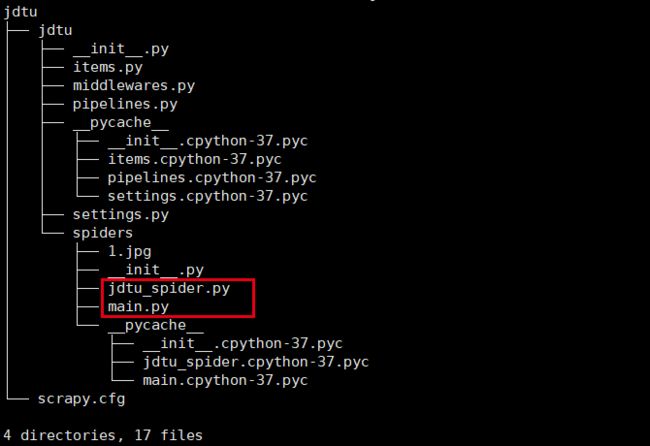
目录层级
ps:其中标红的是我们新建的文件
由于是框架,所以自带了很多的方法,封装了很多的功能,本次用到的只是最皮毛也最常用的部分,如抓取页面,查找标签,下载图片等。
3、新建项目之后如果是django项目是可以直接运行的,但是scrapy直接运行好像会报错,先动手代码吧,文件功能
Item.py--类似对抓取的一个实体(如图片的标题加url加注释)的定义
Middlewares.py--框架内部的东西,暂时没用到
Pipelines.py--框架核心功能之一,对抓取到的item通过管道传递给这个文件内的方法处理(如下载、保存、重命名等)
Settings.py--毫无悬念,总的配置文件,配置爬虫名、是否启用图片管道和文件管道等等
4、写代码之前首先要想好item中的内容
Item.py
import scrapy
class JdtuItem(scrapy.Item):
title = scrapy.Field()
image_urls = scrapy.Field()
Jdtu_spider.py(新建的爬虫主要文件)
import scrapy
from jdtu.items import JdtuItem
from scrapy.selector import Selector
# start_url中抓取当页二级网址列表,进入二级网址后是按页分隔的图册,所以写了两个Parsel方法进行抓取
class JdTuSpider(scrapy.spiders.Spider):
name = "jdtu"
allowd_domains = ["jingdiantu.com"]
start_urls = [
# "https://www.jingdiantu.com/list-性感美女.html",
"https://www.jingdiantu.com/list-网络美女.html",
"https://www.jingdiantu.com/list-丝袜美腿.html",
]
num = 1
# 自定义抓取图册方法
def MyParse1(self, response):
item = JdtuItem()
selector = Selector(response)
base_url = "https://www.jingdiantu.com"
item['title'] = selector.xpath('//p[@class="imgbox"]/img/@alt').extract()
item['image_urls'] = selector.xpath('//p[@class="imgbox"]/img/@lazysrc').extract()
yield item
# 为避免抓取到下一篇的url直接进入下一个主题图册,添加flag_url以做区分
next_site = selector.xpath('//div[@class="page"]//a[@class="current"]/following-sibling::a[1]/@href').extract()
flag_site = selector.xpath('//div[@class="page"]//a[@class="current"]/following-sibling::a[2]/@href').extract()
# 如果flag存在,说明next_site不是下一篇的URL
if flag_site:
yield scrapy.Request("https:" + next_site[0], callback=self.MyParse1)
# 抓取start_url中本页左右图册URL
def parse(self, response):
item = JdtuItem()
selector = Selector(response)
base_url = "https://www.jingdiantu.com"
sites = selector.xpath('//div[@class="piclist"]//li//a/@href').extract()
for site in sites:
site_url = "https:" + site
yield scrapy.Request(site_url, callback=self.MyParse1)
Pipelines.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline #内置的图片管道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# from scrapy.pipelines.images import ImagesPipeline
image_store = "/mnt/hgfs/images"
class JdtuPipeline(object):
def process_item(self, item, spider):
return item
# 自定义图片下载的管道方法,需settings文件中完成注册才会被使用
class jdtuPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
image_url_f = "https:" + image_url
# 通过meta将image_url和对应的其在列表中的index位置传递出去,可以在file_path方法中使用
yield scrapy.Request(image_url_f, meta={'item':item,'index':item['image_urls'].index(image_url)})
# 处理完item之后调用的方法
def item_completed(self, results, item, info):
image_paths = [x['path']for ok, x in results if ok]
# print("image_path:%s"%image_paths)
if not image_paths:
raise DropItem("Item contains no images")
return item
# file_path方法返回图片保存地址,如full/image.jpg,如需修改保存图片名或增加分级目录可以重写该方法
def file_path(self, request, response=None, info=None):
item = request.meta['item']
index = request.meta['index']
# 通过get_media_requests方法的meta参数传递的数据可以获取到图片url的title等item自定义数据
image_new = item['title'][index] + '/' + request.url.split('/')[-1]
return image_new
Settings.py中需要新增的或修改的行
# 告诉对方服务器我是浏览器,你别误会
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
# 启用我们自己的管道方法
ITEM_PIPELINES = {
'jdtu.pipelines.jdtuPipeline': 1,
}
IMAGES_EXPIRES = 30
IMAGES_STORE = '/mnt/hgfs/images'
# 缩略图尺寸设置
IMAGES_THUMBS = {
'small': (35, 50),
'big': (155, 200),
}
# 图片小于多少不下载
IMAGES_MIN_HEIGHT = 80
IMAGES_MIN_WIDTH = 80
到这里其实已经可以运行了。
5、运行项目
a、进入到创建的项目的一级目录,执行:scrapy crawl jdtu命令即可运行。scrapy框架本身会打印很多的日志出来,习惯就好、、(不想习惯的可以去改源码(▽))。
只是这种方法很不人性化,又要死记,所以还有另一个更好的方法,见2
b、新建一个main.py文件(文件名随意的),注意目录层级文件位置,可参考上方截图,里面写如下代码
Main.py
from scrapy.cmdline import execute
execute("scrapy crawl jdtu".split())
之后我们只需要进入到main.py所在的目录执行python main.py即可运行项目。
方法b还有一个最大的好处就是方便IDE调试,如pycharm配置等
纯手写,边学边写,转载请注明出处:https://www.jianshu.com/p/ced81607f6c0