KALDI之aishell之v1模型后续3
#extract ivector
sid/extract_ivectors.sh --cmd "$train_cmd" --nj 10 \
exp/extractor_1024 data/train exp/ivector_train_1024
该脚本为一组话语,给定的特征和训练有素的iVector提取器提取iVectors。
#开始配置部分。
NJ= 30
num_threads = 1#ivector-extract使用的线程数。 将此值设置为> 1通常没有帮助。仅当您使用的扬声器少于要运行的作业数时,它才有用。
CMD= “run.pl”
阶段= 0
num_gselect = 20#使用对角线模型的高斯选择:要选择的高斯数
min_post = 0.025#使用后的最小值(在此以下的后方被修剪掉)
posterior_scale = 1.0#此比例有助于控制高相关的成功特征。 例如。 尝试0.1或0.3。
apply_cmn = true#如果为true,则应用滑动窗口倒谱均值归一化
结束配置部分。
echo“$ 0 $ @”#打印命令行进行日志记录
echo " e.g.: $0 exp/extractor_2048_male data/train_male exp/ivectors_male"
#这里要小心:扬声器级别的iVectors现在已经进行了长度标准化,即使它们与话语级别相同。
This script extracts iVectors for a set of utterances, given
# features and a trained iVector extractor.
# Begin configuration section.
nj=30
num_threads=1 # Number of threads used by ivector-extract. It is usually not
# helpful to set this to > 1. It is only useful if you have
# fewer speakers than the number of jobs you want to run.
cmd="run.pl"
stage=0
num_gselect=20 # Gaussian-selection using diagonal model: number of Gaussians to select
min_post=0.025 # Minimum posterior to use (posteriors below this are pruned out)
posterior_scale=1.0 # This scale helps to control for successve features being highly
# correlated. E.g. try 0.1 or 0.3.
apply_cmn=true # If true, apply sliding window cepstral mean normalization
# End configuration section.
echo "$0 $@" # Print the command line for logging
if [ -f path.sh ]; then . ./path.sh; fi
. parse_options.sh || exit 1;
if [ $# != 3 ]; then
echo "Usage: $0 "
echo " e.g.: $0 exp/extractor_2048_male data/train_male exp/ivectors_male"
echo "main options (for others, see top of script file)"
echo " --config # config containing options"
echo " --cmd (utils/run.pl|utils/queue.pl ) # how to run jobs."
echo " --nj # Number of jobs (also see num-threads)"
echo " --num-threads # Number of threads for each job"
echo " --stage # To control partial reruns"
echo " --num-gselect # Number of Gaussians to select using"
echo " # diagonal model."
echo " --min-post # Pruning threshold for posteriors"
echo " --apply-cmn # if true, apply sliding window cepstral mean"
echo " # normalization to features"
exit 1;
fi
srcdir=$1
data=$2
dir=$3
#就是找后面那三个路径 有没有对应的文件
for f in $srcdir/final.ie $srcdir/final.ubm $data/feats.scp ; do
[ ! -f $f ] && echo "No such file $f" && exit 1;
done
# Set various variables.
#按 并行线程数 把数据分成相应的份数,放到不同的文件夹后面方便并行运算
#-p 如果父目录不存在则创建
#训练数据根据–nj 参数分割,用于并行处理
mkdir -p $dir/log
sdata=$data/split$nj;
utils/split_data.sh $data $nj || exit 1;
#就是把srcdir/delta_opts这个文件里面的打印出来 放到 第一个delta_opts的变量里面
如果有错误就输出到/Dev/null里面
delta_opts=`cat $srcdir/delta_opts 2>/dev/null`
## Set up features.
#个feats变量定义,这个变量作为后续其他命令的参数,这个主要处理特征数据的
#{kaldi函数,apply-cmvn apply-cmvn 的输入3个文件:
–utt2spk=ark:sdata/JOB/utt2spk语料和录音人员关联文件scp:sdata/JOB/utt2spk语料和录音人员关联文件scp:sdata/JOB/cmvn.scp 说话人相关的均值和方差 scp:$sdata/JOB/feats.scp 训练用特征文件 对feats.scp做归一化处理 输出是 ark:-|,利用管道技术把输出传递给下一个函数作为输入
if $apply_cmn; then
feats="ark,s,cs:add-deltas $delta_opts scp:$sdata/JOB/feats.scp ark:- | apply-cmvn-sliding --norm-vars=false --center=true --cmn-window=300 ark:- ark:- | select-voiced-frames ark:- scp,s,cs:$sdata/JOB/vad.scp ark:- |"
else
feats="ark,s,cs:add-deltas $delta_opts scp:$sdata/JOB/feats.scp ark:- | select-voiced-frames ark:- scp,s,cs:$sdata/JOB/vad.scp ark:- |"
fi
if [ $stage -le 0 ]; then
echo "$0: extracting iVectors"
dubm="fgmm-global-to-gmm $srcdir/final.ubm -|"
$cmd --num-threads $num_threads JOB=1:$nj $dir/log/extract_ivectors.JOB.log \
gmm-gselect --n=$num_gselect "$dubm" "$feats" ark:- \| \
fgmm-global-gselect-to-post --min-post=$min_post $srcdir/final.ubm "$feats" \
ark,s,cs:- ark:- \| scale-post ark:- $posterior_scale ark:- \| \
ivector-extract --verbose=2 --num-threads=$num_threads $srcdir/final.ie "$feats" \
ark,s,cs:- ark,scp,t:$dir/ivector.JOB.ark,$dir/ivector.JOB.scp || exit 1;
fi
if [ $stage -le 1 ]; then
echo "$0: combining iVectors across jobs"
for j in $(seq $nj); do cat $dir/ivector.$j.scp; done >$dir/ivector.scp || exit 1;
fi
if [ $stage -le 2 ]; then
# Be careful here: the speaker-level iVectors are now length-normalized,
# even if they are otherwise the same as the utterance-level ones.
##这里要小心:扬声器级别的iVectors现在已经进行了长度标准化,即使它们与话语级别相同。
echo "$0: computing mean of iVectors for each speaker and length-normalizing"
$cmd $dir/log/speaker_mean.log \
ivector-normalize-length scp:$dir/ivector.scp ark:- \| \
ivector-mean ark:$data/spk2utt ark:- ark:- ark,t:$dir/num_utts.ark \| \
ivector-normalize-length ark:- ark,scp:$dir/spk_ivector.ark,$dir/spk_ivector.scp || exit 1;
fi
#如何运行工作。
#作业数量(也见num-threads)
#每个作业的线程数
#控制部分重播
#要选择的高斯数
#对角线模型。
#修剪后墙的门槛
#如果为true,则应用滑动窗口复倒谱平均值
#特征标准化
接着根据run.sh文件到这一步了extract ivector
sid/extract_ivectors.sh 在v1目录下执行下面一句话(注意前面两个传递参数文件路径)
./sid/extract_ivectors.sh exp/extractor_male data/train exp/ivectors_male
结果如下:

根据run.sh顶层脚本执行到这一步
#train plda
$train_cmd exp/ivector_train_1024/log/plda.log \
ivector-compute-plda ark:data/train/spk2utt \
'ark:ivector-normalize-length scp:exp/ivector_train_1024/ivector.scp ark:- |' \
exp/ivector_train_1024/plda
执行以下代码:
直接执行run.sh
报错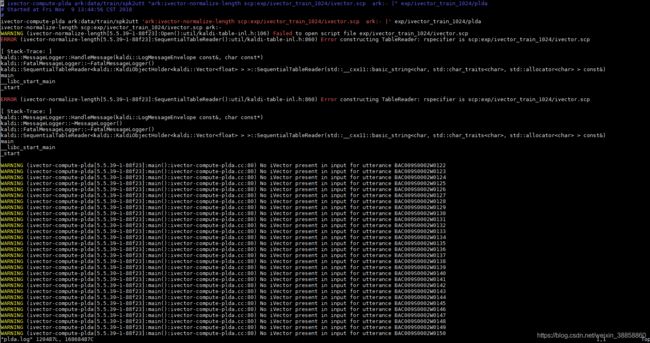
一定一步一步跑实验的时候,写个记录。不然文件目录错了要哭死也不知道哪里错了。找不到对应的文件!!!!!!! 我写了记录,修改文件目录位置耽误了我大半天时间!!!!!!!!!!!!!!!!!!!!!!!!!!!!
然后train plda 这一步 不知道如何管道传输参数,直接执行顶层./run.sh(最好备份一份,然后修改一下前面传递参数的路径)
结果如下(训练的比较慢):
