SQL 最佳实践(基础篇)
0x00 前言
作为一名客户端开发工程师,虽然对 SQL 能力的要求不会像数据分析师或者后端那么严格,但基础的能力还是要会的,比如开发过程中,上报了数据入库,要分析的时候要会查出来,或者制定一些数据报表展示等等。例外,如果有指标建设,那就更需要比较强的 SQL 实践基础了。
0x01 CRUD
SQL 其实用起来是比较简单的,实际使用中无非就是增删改查(Create, Retrieve, Update, Delete),下面简单介绍下 CRUD 基本使用姿势,其中只会讲到实际中高频用到的情况。
0x02 环境配置
https://www.jianshu.com/p/65595b0e59ad,可以参考这篇文章,比较详细了,命令行稍微有些麻烦,习惯用可视化可以用 workbench,具体就不做介绍了,安装成功可以用命令 create database; 创建数据库,show databases; 命令查询所有的数据库,会输出以下的界面。

创建 student 表
create table student(
stu_id int,
name varchar(20),
gender varchar(10),
major varchar(50),
class varchar(20),
grade int,
primary key(stu_id)
);
常用命令
// 启动:
sudo /usr/local/mysql/support-files/mysql.server start
// 关闭
sudo /usr/local/mysql/support-files/mysql.server stop
// 进入mysql(要求输入mysql登录密码)
mysql -u root -p
// 退出mysql
exit
//use 使用数据库
use xxx;
//查看当前使用的数据库
select database();
//显示表
show tables;
// 在表中添加新列
alter table student add age int;
// 查看表结构信息
desc student;
// 删除表
drop table student;
// 复制表
create table student1 like student;
0x03 查询
简单粗暴的 select * 查询表的所有数据,不过不推荐这样用,有很多文章具体列了哪些缺点,我个人认为主要还是低效率,浪费资源,推荐使用指定列名的方式做查询

基本查询方式
SELECT <列名> FROM <表名> WHERE <条件>
比如查询 grade 大于 90 的学生信息,SQL 可以这么写,根据实际情况可以灵活在 where 后面使用 and、or、in、like、%,此外还有 not in、not like 等取反条件
select stu_id,name from student where grade >= 90;
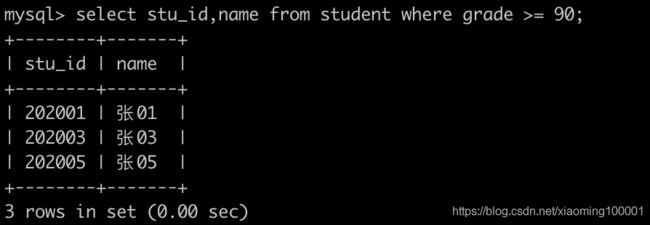
条件语句
- IF,基本表达式
IF( expr1 , expr2 , expr3 ),意思是expr1条件为true,则值是expr2 ,反之值就是expr3 - CASE WHEN,基本表达式
CASE WHEN 条件 THEN 结果 ELSE 其他结果 END 别名 - IFNULL,表达式
IFNULL( expr1 , expr2),在 expr1 的值不为 NULL 的情况下返回 expr1,否则返回 expr2
聚合函数
标准SQL 中的聚合函数 聚合函数是将组中的行汇总为单个值的函数。 例如, COUNT 、 MIN 和 MAX 都是聚合函数。 与
GROUP BY 子句一起使用时,汇总的组通常至少具有一行。
常见聚合函数
- count:统计行的数量
- sum:统计某列的合计值
- avg:计算某列的均值
- max:计算某列的最大值
- min:计算某列的最小值
相信大家基本都会用 Excel,其实数据表可以当做一张报表来处理,每条查询的结果对应多条记录的集合,基本等同于 Excel 的行列,这些聚合函数跟 Excel 的数学表达式基本类似
此外,不同的数据查询引擎会提供更加高级的表达式,例如计算分位值、取模运算、字符串运算等等,用起来很爽
COUNT(*) 和 COUNT(1) 区别
作用都是统计行数,但两者是有重要的区别的,很多人可能会有这样的结论,“SELECT COUNT(*) 最终会转化成 SELECT COUNT(1),而 SELECT COUNT(1) 省略了转换的这一步,所以 SELECT COUNT(1) 效率更高”,其实并不是这样的
《高性能 MySQL》这本书给到的答案 COUNT(1) 和 COUNT(*) 执行优化器的优化完全是一样的,并没有快慢之分,但推荐使用后者,因为这是SQL92定义的标准统计行数的语法,所以也不知道为啥要设计 COUNT(1) 。
GROUP BY
根据 BY 指定的规则对数据分组,简单理解就是把一个大的数据分类,再对不同的类进行数据处理
使用需要注意语法规则,查询的字段要么包含在 group by 语句的后面分组,要么字段要包含在聚合函数。使用场景比较常见,比如对查询不同班级优秀的学生数量
简单理解下分组的聚合过程,可以看下这边文章 https://zhuanlan.zhihu.com/p/23284940 ,感觉讲得不错,借用下作者的图。可以想象成 Excel 整理数据的流程,这样基本就可以理解了
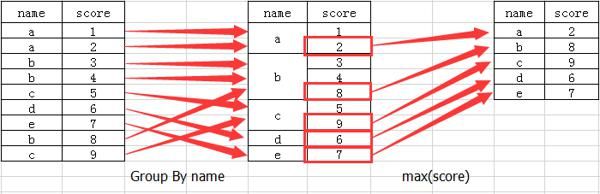
HAVING
HAVING 的作用是过滤 GROUP BY 分好组后对应组的数据,条件可以包含聚合函数,执行顺序自然是在 GROUP BY 之后
多表查询
上面主要介绍的是查询的基本语法,实际中单表查询的 case 还是比较多的,绝大数情况需要联表查询,就是联结,联结就是用一条 SELECT 语句从多个表中查询数据,join 语句的好处还有就是使用了索引,优化了查询。通过联结,让多张表中的数据互相关联起来,联结又分为内连接、左连接、右连接、全外连接和交叉连接
下面的 Demo 需要连表分析,现在 Demo 数据库里头仅有一张 student 表,需要再准备一张 major 表
创建 major 表
create table major(
_id int,
major varchar(50),
info varchar(100),
primary key(_id)
);


内连接
把表的交集连接在一起,产生新的结果集
例如,查询学生专业简介信息,那 SQL 我们可以这么写
select
stu.stu_id,stu.name,stu.gender,stu.major,m.info
from
student stu
inner join major m on stu.major = m.major

左连接
查询主表中所有的记录,联结表找不到的列默认 NULL
select
stu.stu_id,stu.name,stu.gender,stu.major,m.info
from student stu
left join major m on stu.major = m.major

右连接
跟左连接正好相反,直接看例子就懂了

全连接
A 和 B的全集,需要结合 left join 和 union all 使用
UNION 和 UNION ALL
UNION 与 UNION ALL 表示并集,把两个 SELECT 查询的结果合并成一个,前提是两个 SELECT 所查询的列数量和字段类型一致。不同的是 UNION 会去除重复行,而 UNION ALL 不会去除重复行。
交叉连接
又称"笛卡尔连接"或者"叉乘",比如 A 和 B 表叉乘,结果集就是 A* B
0x04 插入
使用 INSERT 语句,比较简单不细说
insert into student (stu_id,name,gender,major,class,grade) values (202001,'张01','男','计算机专业','3年7班',99)
0x05 更新
更新数据使用 UPDATE 语句
0x06 删除
删除数据使用 DELETE 语句
0x07 小结
实践比较多主要还是 SELECT 查询,其他操作比较容易而且使用并不是很常见,客户端同学掌握这些基本够用了,下期跟大家分享分析函数以及高级查询,欢迎大家一起交流、共同学习进步。