数据导入导出工具
本节课程重点:
exp/imp,expdp/impdp使用
使用exp/imp,expdp/impdp实现表空间传输
sql*loader数据加载工具的使用
1、exp/imp导入导入工具
客户端工具,导入导出的文件是在本地,而不是像RMAN是放到服务端工具
高版本向下兼容低版本
可以就数据库按表空间、用户或某些表保存到操作系统下的一个二进制文件里。
2、exp/imp导入导出模式
exp/imp 一共有四种模式: Full,User,Tables,Tablespaces
严格意义上,exp/imp、expdp、impdp都不是备份工具
11g : exp -> 10g imp 11g:运行一个脚本($ORACLE_HOME/rdbms/admin/xx)
full
导出账户要具有exp_full_database,在full模式下将导出数据库中所有用户的对象
一般建议使用system用户执行导出操作
user
具有create session的用户,即可以对属于自己的schema进行导出,User模式下将导出该模式下所有的对象
tables
导出指定的表(表名可用通配符)
对于分区表,可以利用该模式导出某个或全部分区
tablespaces
transport tablespace
3、expdp/impdp
是服务器端工具
10g以后出现
降HWK,shink,move操作可以实现。
userid
file
log
owner
table
exp userid=test/test file=db_str.dmp log=db_str.log owner=test1
exp userid=test/test file=db_str.dmp tables=table1,table2 log=db_str.log
compress 不是压缩数据,而是指示exp如何控制create table中的storage语句。建议设置为N
rows 是否导出数据,N只导出表结构
filesize
file
exp userid=test/test file=f1,f2,f3,f4,... filesize=2G
query 指定只导出一部分数据的功能
query=\"where rownum\<2\"
direct 很强大,Y是直接路径导出,数据量大建议设置成Y
exp userid=test/test file=db_str.dmp tables=big_table direct=y
recordlength
buffer
parfile 将参数信息全部放到参数文件里
exp userid=test/test parfile=exp.par
exp scott/tiger rows=n file='/u02/dmp/scott.dmp'
exp scott/tiger rows=y file='/u02/dmp/scott.dmp'
exp userid=scott/tiger log=scott.log file='/u02/dmp/scott02.dmp' query=\"where rownum\<10\"
exp userid=scott/tiger log=scott.log file='/u02/dmp/scott02.dmp' query=\"where rownum\<10\" tables=emp
exp userid=scott/tiger log=scott.log file='/u02/dmp/scott02.dmp' query=\"where rownum\<10\" tables=emp compress=y
imp
indexfile
ignore
commit
fromuser
touser
导出的用户权限不能大于导入用户的权限
alter user belt quota unlimited on users;
imp scott/tiger show=y full=y file=scott.dmp
11G中新参数:
deferred_segment_creation 用于控制段的延迟创建,创建表时,oracle并没有立即创建相应的段,而是在往里面插入数据时创建对应的段。
10G中表与段是等同的概念
10G exp--》11G Imp
--=========================================================
不同版本的EXP/IMP问题
一般来说,从低版本导入到高版本问题不大,麻烦的是将高版本的数据导入到低版本中,在Oracle9i之前,不同版本Oracle之间的EXP/IMP可以通过下面的方法来解决:
1、在高版本数据库上运行底版本的catexp.sql;11G的库里运行10G数据库软件下ORACLE_HOME/rdbms/admin/catexp.sql
2、使用低版本的EXP来导出高版本的数据;
3、使用低版本的IMP将数据库导入到低版本数据库中;
4、在高版本数据库上重新运行高版本的catexp.sql脚本。
expdp/impdp做表空间传输操作:
通常可以通过系统包DBMS_TTS来检查表空间是否自包含
SQL>connect /as sysdba
SQL>exec dbms_tts.transport_set_check('TTS',TRUE);
SQL>select * from TRANSPORT_SET_VIOLATIONS;
表空间自包含检查完后进行表空间传输就方便了
(1)首先将表空间设置成只读表空间
SQL>alter tablespace TTS read only;
(2)导出表空间
expdp system/oracle TRANSPORT_TABLESPACES=TTS DUMPfile=exp_tts.dmp DIRECTORY=MYDIR
此时导出的元数据,比较小
(3)转移需要数据,元数据exp_tts.dmp,数据文件tts.dbf传输到目标主机.
(4)alter tablespace tts read write;
(5)在目标数据库中将表空间插入到数据库中
impdp system/oracle directory=mydir dumpfile=exp_tts.dmp transport_datafiles='/home/oracle/tts.dbf' remap_tablespaces=TTS:TTS2
传输表空间
1、检查子包含
exec dbms_tts.transport_set_check('TTS_TEST',true);
exec dbms_tts.transport_set_check('TTS,USERS',true);
select * from transport_set_violations;

2、将表空间设置成只读【此步很重要,否则无法拷贝可用的表空间对应的数据文件】
alter tablespace tts_test read only;

3、exp导出表空间元数据
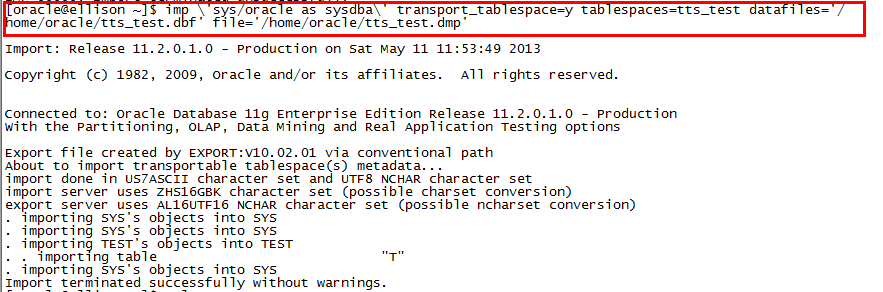
exp \'sys/oracle as sysdba\' transport_tablespace=y tablespaces=tts_test file=tts_test.dmp log=tts_test.log
【alter tablespace ts_name read write;】

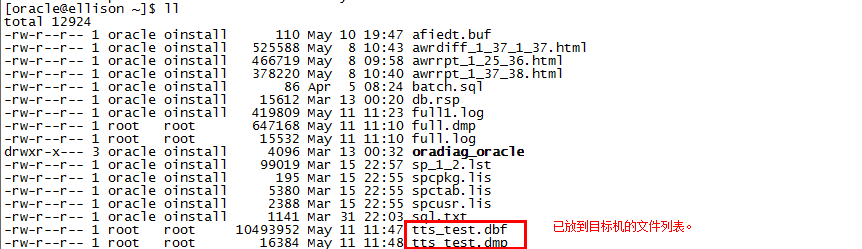
4、转移需要的数据:exp元数据,表空间的数据文件拷贝到目标主机
使用传统的拷贝命令将dmp和dbf拷贝到目标机即可。 scp,U 盘等。
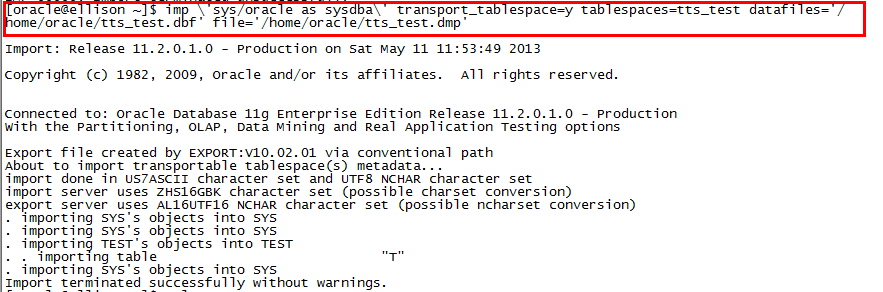
5、在目标主机上导入表空间元数据
imp system/oracle tablespaces=tts transport_tablespace=y file=exp_tts.dmp datafiles='tts.dbf'
再执行imp导入表空间元数据前,要注意将表空间的数据文件放到想放到的地方,免得之后麻烦,修改数据文件的路径信息。
此处图省事,直接放到了Oracle的家目录,不过最好统一管理,放到数据库对应的数据文件目录中:
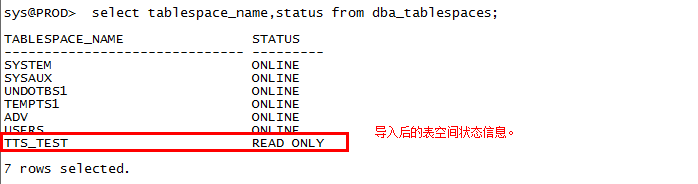
查看导入状态信息:
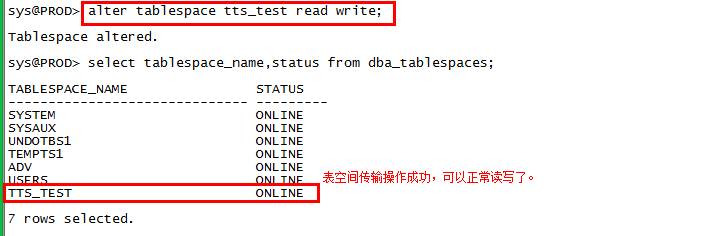
--=============================================================
expdp/impdp
服务器段的工具,10G以后才有的
命令选项【具体选项说明,查看expdp help=y帮助中的信息】:
content
: (exp : rows,ignore)
all,data_only,metadata_only
directory
col DIRECTORY_PATH for a50
col DIRECTORY_NAME for a20
select DIRECTORY_NAME,DIRECTORY_PATH from dba_directories;
create directory dump_dir as '/u02/dmp';grant read,write on directory EXPDP_DUMP_DIR to scott;
directory
dumpfile
: 指定了目录,就已指定的为准,优先级高于directory
exclude
expdp system/oracle directory=dump_dir dumpfile=scott.dmp exclude=tables
filesize
file
full=y|n 工作中也比较常用的,做全库导出,一般用system用户做全库导出
expdp system/oracle directory=dump_dir dumpfile=full.dmpdp full=y
60G/h
imp/exp没有并行
expdp/impdp是可以并行的
include
job_name
指定要到处作业的名称,默认SYS_XXX
job_name=jobname_string
logfile 指定记录操作的日志文件
parallel 开并行
expdp system/oracle directory=dump_dir dumpfile=full.dmpdp full=y parallel=4
并行数要 < core * 2
query 为导出的数据加过滤条件,linux下注意转义字符
parfile 指定使用的参数文件,此文件包含命令常用的选项列表,就是key=value的形式,key是选项,value是对应的选项值
schemas
tables 指定导出的表
tablespaces
transport_tablespaces 做传输表空间要用到
remap_schema=oldUsername:newUsername 做映射
最好不用exp/imp做全库的导入和导出数据迁移操作,而尽量使用数据泵去做。
expdp/impdp做传输表空间,注意与exp/imp操作上的区别!
SQL*LOADER数据加载工具
SQL*LOADER 数据加载工具,通常用来将数据文件导入到数据库中
【只能处理纯文本数据】
使用sql*loader将文本文件中的数据加载到Oracle的具体步骤:
分析数据
在数据库中建立表
准备控制文件
执行导入命令
查看日志,处理导入失败的数据
1、准备要加载的数据:
可以在excel中编辑,再另存为csv格式[以','区分个字段的数据的文本格式文件]

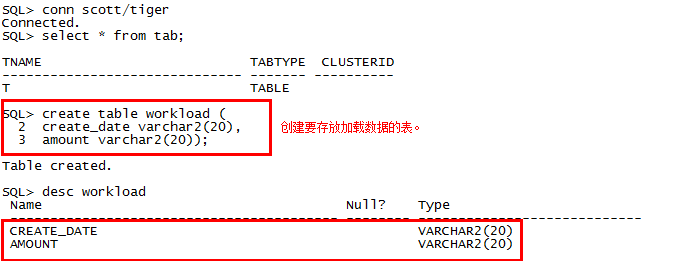
2、在指定的scott模式下创建存放导入数据的表:
sqlplus scott/tiger
SQL> create table workload (
create_date varchar2(20),
amount varchar2(20));
3、写控制文件paratab.ctl内容:
load data
infile 'workload.csv'
append
into table workload
fields terminated by ","
(create_date,amount)

4、执行sqlldr导入命令:
sqlldr scott/tiger control=paratab.ctl

5、检查sqlldr生成的日志文件,bad文件,discard文件等,确定导入是否成功完成,如果存在bad记录,查找原因,重复以上步骤。

查询数据表,确认已导入的数据:

sql*loader功能很强大,想具体研究,参见联机文档[详细使用方法参见联机文档BOOKS->utility中SQL*LOADER章节]:
找文档的具体步骤:
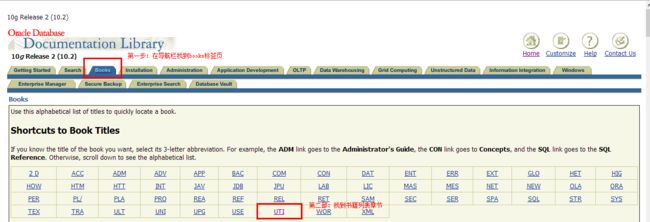

在接下来打开的页面中,就是本次课程着重讲解的Oracle数据库导入导出工具exp/imp,数据泵expdp/impdp以及数据加载工具sql*loader的具体内容。课堂上仅仅是简单地入门,阅读联机文档中的相关章节可以对以上工具有更全面的了解。
如何从Oracle数据库中抽取数据并做成可视化报表?
从excel中取数据:
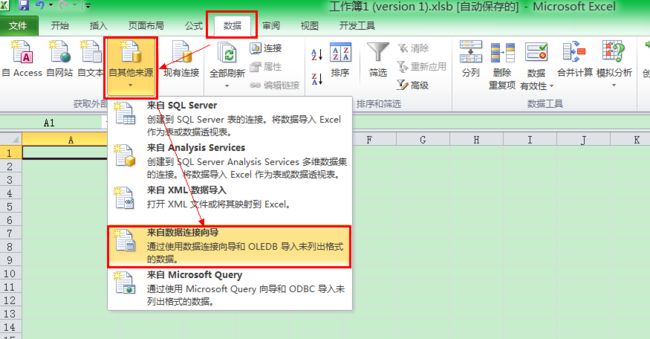
要保证机器上已经安装了Oracle client软件,否则看不到这一行信息:
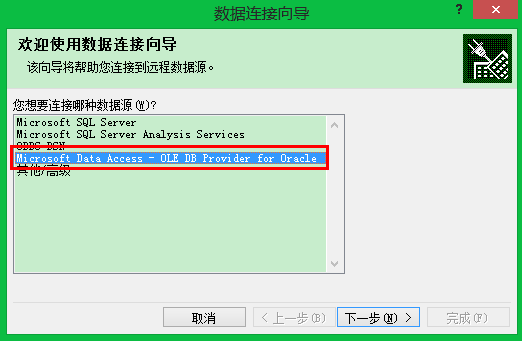
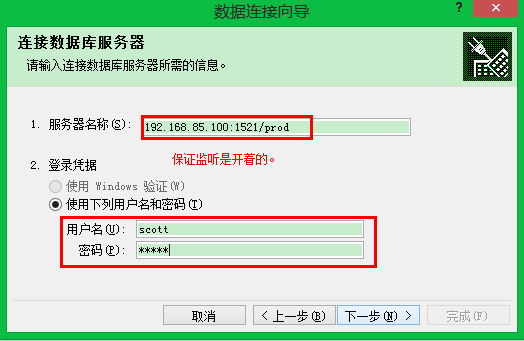

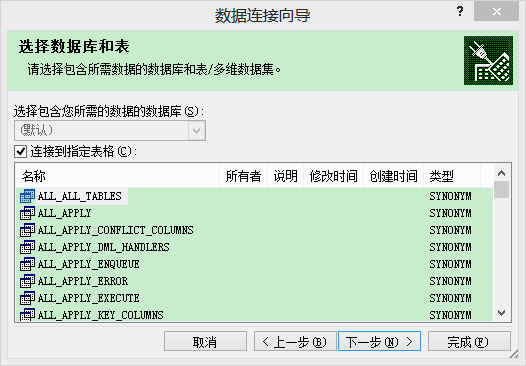

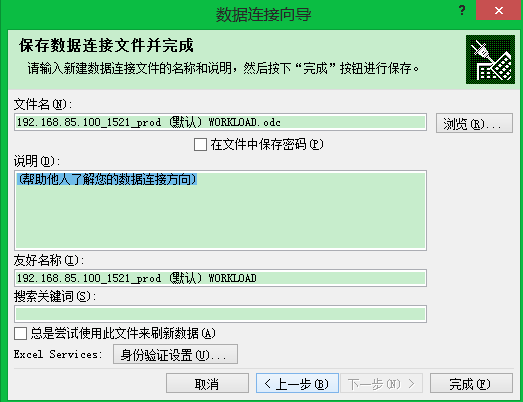

下面的自己可以按照需求做处理啦!数据已经全导出来啦!
下面的自己可以按照需求做处理啦!数据已经全导出来啦!
从sqldevloper中取数据做报表
就是导入导出功能!学着用就可以啦,不过一般很少去用,不是很方便,显然比不上sql*loader.