一招教你如何修复MySQL slave中继日志损坏问题
【摘要】MySQL的Crash safe slave是指slave crash后,把slave重新拉起来可以继续从Master进行复制,不会出现复制错误也不会出现数据不一致。
PS:华为云数据库特惠专场钜惠来袭,全场10元起购,直降108000元!新购满额送P30 Pro,点此抢购。

Contents
1 背景
2 Relay log的获取与应用
2.1 源码分析
2.1.1 配置参数relay_log_recovery=OFF重启后,slave机制与源码
2.1.2 配置参数relay_log_recovery=ON重启后,slave机制与源码
3 修复计划
3.1 具体实现思路
3.2 流程图
4 总结
1 背景
MySQL的Crash safe slave是指slave crash后,把slave重新拉起来可以继续从Master进行复制,不会出现复制错误也不会出现数据不一致。为保证crash safe slave,需解决由于未同步刷盘导致的binlog文件接收位置和实际不一致或者relay log文件不完整的问题,因此relay_log_recovery为ON是必需配置参数之一。但是设置relay_log_recovery为ON会导致MySQL正常重启或者宕机恢复时以备库的SQL线程执行位置为起点重新向主库请求binlog,可能由于之前主备时延大,请求点的binlog已被主机清除,最终导致主备复制关系异常,因此设置relay_log_recovery为OFF是生产环境常见的设置。但是,此设置在OS的oom-killer事件以及OS异常断电等情况可能导致备库relay log的部分event不完整, MySQL重启后,SQL线程回放执行到不完整的event就会导致主备复制关系中断,查看error.log可以看到类似如下的错误信息:
2 Relay log的获取与应用
MySQL支持的复制方式按连接协议来区分,可以分为
• 非GTID模式,通过binlog文件名和文件的偏移来决定复制位点信息
• GTID模式,通过GTID信息来决定复制位点信息
2.1 源码分析
2.1.1 配置参数relay_log_recovery=OFF重启后,slave机制与源码
1)基于binlog复制(非GTID)模式,MySQL重启后,重连主库时,备库的IO线程读取slave_master_info表记录的master_log_name以及master_log_pos值向主库请求binlog。
1. |-init_slave()
2. /* read all the slave repositories on disk (either in FILE or TABLE form) and create corresponding slave info objects
3. */
4. |-Rpl_info_factory::create_slave_info_objects
5. |-load_mi_and_rli_from_repositories
6. |-Master_info::mi_init_info()
7. /* Creates or reads information from the repository, initializing the Master_info.*/
8. |-Master_info::read_info()
9. |-get_info()
10. //初始化mi master_log_pos && master_log_name 备库的SQL线程读取slave_relay_log_info表记录的relay_log_name以及relay_log_pos值开始应用relay log。
1. |-init_slave()
2. |-Rpl_info_factory::create_slave_info_objects
3. |-load_mi_and_rli_from_repositories
4. |-Relay_log_info::rli_init_info
5. |-Relay_log_info::read_info()
6. //rli group_relay_log_pos && group_master_log_pos &&
7. group_relay_log_name && group_master_log_name 2)基于GTID复制模式,MySQL重启后,重连主库时,备库的IO线程通过读取mysql.gtid_executed表以及binlog文件获取Executed_Gtid_Set,通过读取realy_log文件获取Retrieved_Gtid_Set,并将两者的并集发送到主库请求binlog。
1. mysqld_main ()
2. //读持久化介质mysql.gtid_executed表
3. |-Gtid_state::read_gtid_executed_from_table ()
4. //读持久化介质binlog
5. |-MYSQL_BIN_LOG::init_gtid_sets ()
6. |-init_slave ()
7. |-Rpl_info_factory::create_slave_info_objects ()
8. |-load_mi_and_rli_from_repositories ()
9. |-Relay_log_info::rli_init_info ()
10. |-MYSQL_BIN_LOG::init_gtid_sets ()
11. |-Relay_log_info::init_relay_log_pos () 对于备库的SQL线程其应用relay log的起始从slave_relay_log_info表读取,其执行过程如果发现事务的gtid已经存在,则ev->apply_event时就会忽略这个事务,保证不会重复执行同一个事务。
2.1.2 配置参数relay_log_recovery=ON重启后,slave机制与源码
当参数relay_log_recovery为ON,不论是单线程还是多线程回放,MySQL正常重启或者宕机恢复时以备库的SQL线程执行位置为起点重新向主库请求binlog。基于binlog复制发送的是slave_relay_log_info表读取relay_log_name以及Relay_log_pos值。基于GTID复制模式发送的是备库执行完的gtid_sets。
1. static void recover_relay_log(Master_info *mi)
2. {
3. Relay_log_info *rli=mi->rli;
4. // Set Receiver Thread's positions as per the recovered Applier Thread.
5. mi->set_master_log_pos(max(BIN_LOG_HEADER_SIZE,
6. rli->get_group_master_log_pos()));
7. mi->set_master_log_name(rli->get_group_master_log_name());
8. rli->set_group_relay_log_name(rli->relay_log.get_log_fname());
9. rli->set_event_relay_log_name(rli->relay_log.get_log_fname());
10. rli->set_group_relay_log_pos(BIN_LOG_HEADER_SIZE);
11. rli->set_event_relay_log_pos(BIN_LOG_HEADER_SIZE);
12. } 3 修复计划
当备库配置master_info_repository与relay_log_info_repository都为TABLE时,对于SQL线程而言,会在一个事务提交的同时更新表slave_relay_log_info,其得到原子性保证,即SQL线程执行位置始终是对的。但异常宕机可能导致丢失master info,IO线程会dump到重复的日志和SQL线程可能会重复执行同一个事务,这样就会导致主备复制出错,这样对于非gtid复制的模式,所以为保证主备正常且数据一致,relay_log_recovery=ON为Crash safe slave必需参数。
但是如果开启了gtid就可以避免上述问题,GTID复制协议保证了数据的一致性,且ev->apply_event时会忽略已执行的事务。因此对于备库设置为relay_log_recovery=OFF的配置,relay log文件中可能存在的损坏的event可直接清除,避免出现主备复制关系异常。
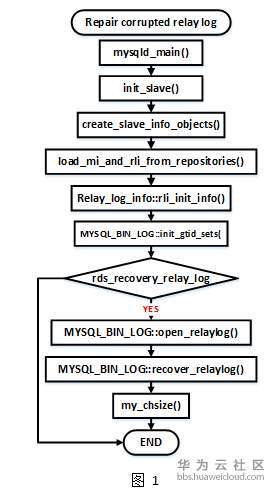
3.1 具体实现思路
方案:
1、在MySQL启动初始化过程中进行损坏relay log(不完整event)修复。
2、在初始化Gtid_sets的MYSQL_BIN_LOG:init_gtid_set()处,若配置参数设置了功能启动开关rds_recovery_relay_log=ON,则进入下面流程。
3、扫描relay log时,判断其是否是正常关闭,非正常关闭则进入修复检测流程。
4、读取非正常关闭relay log文件,遍历其event,并记录更新合法的event的位置,若存在非完整event则退出,返回记录的最新合法event位置。
4、根据返回的合法event位置截断relay log,清除文件中损坏的部分。
5、后续流程正常进行
3.2 流程图
4 总结
设置rds_relay_log_recovery参数设置为ON,可解决OS宕机等情况导致MySQL备库的relay log的不完整导致主备异常情况。建议使用方法,在OS宕机等情况,重启mysql服务时,设置开启rds_relay_log_recovery=ON,可预防relay_log_recovery=ON的潜在缺点即自sql thread执行完的gtid起请求的binlog已被master purge。
最后,华为云数据库特惠专场钜惠来袭,比自建好用还省钱,全场10元起购,直降108000元,新购满额送P30 Pro,点此抢购。