外贸电商数据平台(一) shopee
该项目主要针对东南亚电商平台shopee
主体功能涉及:商品店铺、商品关键词等条件筛选
项目本身采用mysql数据库存储,考虑到验证需要建表建字段等,较为繁琐,故改为表格文件csv作存储展示
shopee本身具有多个国家站点,本次主要围绕东南亚周边五个国家以及印尼和台湾省地区共七个站点
手动条件输入,由于项目本身前端部分由专业人士完成,引入较困难,故此改为手动输入
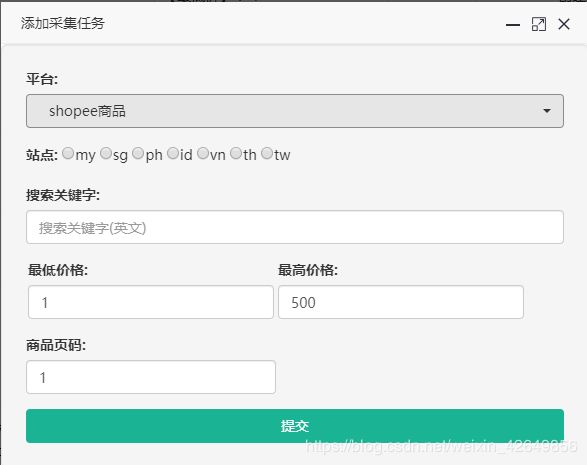
# 条件输入
class Condition(object):
# 获取输入条件
def run(self):
print('1.shopee商品搜索' + '\t' + '2.shopee店铺搜索' + '\t' + '3.shopee单品链接')
platform = self.get_platform()
config = self.search_other(platform)
return config
# 渠道选择
def get_platform(self):
search_method = input('请选择商品采集渠道:')
platform = ''
if search_method == '1':
platform = 'shopee_product'
elif search_method == '2':
platform = 'shopee_store'
elif search_method == '3':
platform = 'shopee_link'
return platform
# 平台站点
def site_choose(self):
print()
print('+' + '-' * 28 + '+')
print('|' + '平台站点选择'.center(22) + '|')
print('|' + ' ' * 28 + '|')
print('|' + '1.新加坡'.ljust(11) + '2.马来西亚'.ljust(10) + '|')
print('|' + '3.泰国'.ljust(12) + '4.菲律宾'.ljust(11) + '|')
print('|' + '5.越南'.ljust(12) + '6.印尼'.ljust(12) + '|')
# print('|' + '7.台湾'.ljust(12) + ' '.ljust(14) + '|')
print('+' + '-' * 28 + '+', '\n')
# 获取平台站点
def get_site(self):
terrace = input('请选择shopee平台站点(1-7):')
site = ''
if terrace == '1':
site = 'sg'
elif terrace == '2':
site = 'my'
elif terrace == '3':
site = 'th'
elif terrace == '4':
site = 'ph'
elif terrace == '5':
site = 'vn'
elif terrace == '6':
site = 'id'
elif terrace == '7':
site = 'tw'
return site
# 其他搜索条件
def search_other(self, platform):
low_price = 'None'
high_price = 'None'
end_page = 'None'
shop_id = 'None'
item_id = 'None'
if platform == 'shopee_link':
keyword = input('请输入shopee单品链接:')
site = re.findall('https://(.*?)/', keyword)[0][-2:] # 单品匹配出站点
shop_id = re.findall(r'-i.(\d+).', keyword)[0] # 店铺id
item_id = re.findall(r'-i.(\d+).(\d+)', keyword)[0][1] # 商品id
else:
self.site_choose()
site = self.get_site()
if platform == 'shopee_product':
keyword = input('请输入要搜索的商品(英文):')
pub.exchange_rate()
low_price = input('请输入商品的最低价:')
high_price = input('请输入商品的最高价:')
else:
print('\n', '示例:https://shopee.sg/shop/139267434/search?page=3&sortBy=pop' + '\t' + '—>139267434', '\n')
keyword = input('请输入要搜索的店铺:')
end_page = input('请输入商品列表页码:') # 商品列表页码,如1..,2则为第2页
config = {'cid': 0, 'site': site, 'platform': platform, 'keyword': keyword, 'end_page': end_page,
'low_price': low_price, 'high_price': high_price, 'shop_id': shop_id, 'item_id': item_id}
return config
主体采集程序
# -*- coding:utf-8 -*-
import re
# shopee采集
class ShopeeSpider(object):
# 主函数
def main(self, config):
begin, start = pub.begin_time()
cid = config['cid']
config['start'] = start
# sql.del_data(cid)
# sql.save_start(cid, start)
# sql.updata_status(cid)
try:
self.task_allocation(config)
end, over = pub.end_time()
# sql.save_succeed(cid, over) # 保存结束时间和状态
print('程序耗时%.02f秒' % (end - begin))
except Exception as error:
print('错误信息:', error)
# sql.save_error(cid, str(error))
# 获取地址及平台站点
def get_website(self, config):
site = config['site']
website = ' '
if site == 'sg':
website = 'shopee.sg'
elif site == 'my':
website = 'shopee.com.my'
elif site == 'th':
website = 'shopee.co.th'
elif site == 'ph':
website = 'shopee.ph'
elif site == 'vn':
website = 'shopee.vn'
elif site == 'id':
website = 'shopee.co.id'
elif site == 'tw':
website = 'xiapi.xiapibuy.com'
return website
# 拼接条件作文件路径
def get_path(self, config):
sort = '单品'
folder_path = ''
platform = 'shopee'
if config['low_price'] != 'None' and config['end_page'] != 'None':
sort = '商品'
folder_path = config['keyword'] + "_" + "价格" + config['low_price'] + "-" + config[
'high_price'] + "_" + "页码" + "-" + config['end_page']
elif config['end_page'] != 'None':
sort = '店铺'
folder_path = config['keyword'] + "页数" + "-" + config['end_page']
path = "商品采集/" + "shopee/" + config['site'] + "/" + sort + "/" + folder_path # 文件夹路径,拼接搜索条件
header = ['商 品 ID', '商品标题', '商品主图', '店铺名称', '品牌名称', '发货地点', '产品现价', '当月销量',
'评价人数', '收藏人气', '店铺评分', '详情链接', '商品副图', '变体信息', '商品短描', '产品原价',
'商品分类', '高清大图', '变体图片', '商品长述', '商品站点', '包装内容', '商品平台'] # 数据标题
pub.mkdir(path) # 传入文件夹路径,并调用函数
pub.save_csv(path, header, platform) # 传入参数,并写入csv标题
return path
# 分配任务
def task_allocation(self, config):
website = self.get_website(config)
path = self.get_path(config)
config['website'] = website
config['path'] = path
platform = config['platform']
if platform == 'shopee_link':
config['count'] = 1
url = 'https://{}/api/v2/item/get?itemid={}&shopid={}'.format(website, config['item_id'], config['shop_id'])
self.parse_details(url, config)
else:
url = self.condition_search(config)
urls = self.parse_list(url, config)
self.details(urls, config)
# 条件整合搜索
def condition_search(self, config):
website = config['website']
keyword = config['keyword']
low_price = config['low_price']
high_price = config['high_price']
end_page = int(config['end_page'])
if low_price == 'None':
page = str((end_page - 1) * 30)
url = 'https://{}/api/v2/search_items/?by=pop&limit=30&match_id={}&newest={}&order=desc&page_type=shop'.format(
website, keyword, page)
else:
page = str((end_page - 1) * 50)
url = 'https://{}/api/v2/search_items/?by=relevancy&keyword={}&limit=50&newest={}&order=desc&page_type=search &price_max={}&price_min={}'.format(
website, keyword, page, high_price, low_price)
return url
# 解析列表页接口,获取详情url
def parse_list(self, url, config):
urls = []
website = config['website']
con = pub.get_content(url)
items = con['items']
for item in items:
itemid = item['itemid']
shopid = item['shopid']
link = 'https://{}/api/v2/item/get?itemid={}&shopid={}'.format(website, itemid, shopid)
urls.append(link)
return urls
# 商品详情
def details(self, urls, config):
count = 1
for url in urls:
config['count'] = count
self.parse_details(url, config)
count += 1
# 解析详情页
def parse_details(self, det_url, config):
begin, start = pub.begin_time()
config['start'] = start
con = pub.get_content(det_url)
url, ID = self.get_ID(con, config)
item = self.get_static(con)
pictures = self.show_pictures(con)
category_text = self.get_category(con)
desc = self.get_desc(con)
variants = self.get_skuinfo(con)
info = {
'platform': 'shopee',
'config': config,
'item': item,
'ID': ID,
'url': url,
'pictures': pictures,
'category_text': category_text,
'desc': desc,
'long_descroption': '',
'variants': variants
}
pub.details(info)
end, over = pub.end_time()
print('当前耗时%.02f秒' % (end - begin), '\n')
# 获取描述信息
def get_desc(self,con):
deacribe = []
trace = con['item']['description']
deacribe.append(trace)
desc = pub.exp3(deacribe)
return desc
# 获取ID
def get_ID(self, con, config):
website = config['website']
itemid = str(con['item']['itemid'])
shopid = str(con['item']['shopid'])
# name = con['item']['name']
# new_name = name.replace(' ', '-').replace('#', '-').replace('?', '')
url = "https://{}/shopee-i.{}.{}".format(website, shopid, itemid)
return url, itemid
# 获取单属性元素
def get_static(self, con):
# brand = con['item']['brand']
sales = str(con['item']['sold'])
comment = str(con['item']['cmt_count'])
collect = str(con['item']['liked_count'])
title = con['item']['name']
try:
pre_price = con['item']['price_max']
except:
pre_price = con['item']['price']
present_price = str(int(pre_price) / 100000)
try:
ori_price = con['item']['price_before_discount']
original_price = str(int(ori_price) / 100000)
except:
original_price = ''
item = {
'title': title,
'sales': sales,
'comment': comment,
'collect': collect,
'present_price': present_price,
'original_price': original_price,
'location': '',
'store_name': '',
'box_content': '',
'grade': '',
'weight': ' ',
'brand': 'No brand'
}
return item
# 展示图
def show_pictures(self, con):
master_map = 'https://cf.shopee.com.my/file/' + con['item']['image']
imgs = con['item']['images']
other_imgs = ['https://cf.shopee.com.my/file/' + i + '_tn' for i in imgs]
extra_imgs = pub.exp3(other_imgs)
pictures = {
'master_map': master_map,
'extra_imgs': extra_imgs,
'HD_imgs': '',
'var_img': ''
}
return pictures
# 获取分类
def get_category(self, con):
category = []
categories = con['item']['categories']
for index in range(0, len(categories)):
display_name = categories[index]['display_name']
category.append(display_name)
category_text = pub.exp3(category)
return category_text
# 获取变体
def get_skuinfo(self, con):
info_list = []
models = con['item']['models']
for index in range(0, len(models)):
name = models[index]['name']
if ',' in name:
name_list = name.split(',')
else:
name_list = []
name_list.append(name)
info_list.append(name_list)
variants = pub.exp3(info_list)
return variants
主体完整代码
# -*- coding:utf-8 -*-
import re
import public
pub = public.Pulic()
# sql = public.MysqlSave()
# shopee采集
class ShopeeSpider(object):
# 主函数
def main(self, config):
begin, start = pub.begin_time()
cid = config['cid']
config['start'] = start
# sql.del_data(cid)
# sql.save_start(cid, start)
# sql.updata_status(cid)
try:
self.task_allocation(config)
end, over = pub.end_time()
# sql.save_succeed(cid, over) # 保存结束时间和状态
print('程序耗时%.02f秒' % (end - begin))
except Exception as error:
print('错误信息:', error)
# sql.save_error(cid, str(error))
# 获取地址及平台站点
def get_website(self, config):
site = config['site']
website = ' '
if site == 'sg':
website = 'shopee.sg'
elif site == 'my':
website = 'shopee.com.my'
elif site == 'th':
website = 'shopee.co.th'
elif site == 'ph':
website = 'shopee.ph'
elif site == 'vn':
website = 'shopee.vn'
elif site == 'id':
website = 'shopee.co.id'
elif site == 'tw':
website = 'xiapi.xiapibuy.com'
return website
# 拼接条件作文件路径
def get_path(self, config):
sort = '单品'
folder_path = ''
platform = 'shopee'
if config['low_price'] != 'None' and config['end_page'] != 'None':
sort = '商品'
folder_path = config['keyword'] + "_" + "价格" + config['low_price'] + "-" + config[
'high_price'] + "_" + "页码" + "-" + config['end_page']
elif config['end_page'] != 'None':
sort = '店铺'
folder_path = config['keyword'] + "页数" + "-" + config['end_page']
path = "商品采集/" + "shopee/" + config['site'] + "/" + sort + "/" + folder_path # 文件夹路径,拼接搜索条件
header = ['商 品 ID', '商品标题', '商品主图', '店铺名称', '品牌名称', '发货地点', '产品现价', '当月销量',
'评价人数', '收藏人气', '店铺评分', '详情链接', '商品副图', '变体信息', '商品短描', '产品原价',
'商品分类', '高清大图', '变体图片', '商品长述', '商品站点', '包装内容', '商品平台'] # 数据标题
pub.mkdir(path) # 传入文件夹路径,并调用函数
pub.save_csv(path, header, platform) # 传入参数,并写入csv标题
return path
# 分配任务
def task_allocation(self, config):
website = self.get_website(config)
path = self.get_path(config)
config['website'] = website
config['path'] = path
platform = config['platform']
if platform == 'shopee_link':
config['count'] = 1
url = 'https://{}/api/v2/item/get?itemid={}&shopid={}'.format(website, config['item_id'], config['shop_id'])
self.parse_details(url, config)
else:
url = self.condition_search(config)
urls = self.parse_list(url, config)
self.details(urls, config)
# 条件整合搜索
def condition_search(self, config):
website = config['website']
keyword = config['keyword']
low_price = config['low_price']
high_price = config['high_price']
end_page = int(config['end_page'])
if low_price == 'None':
page = str((end_page - 1) * 30)
url = 'https://{}/api/v2/search_items/?by=pop&limit=30&match_id={}&newest={}&order=desc&page_type=shop'.format(
website, keyword, page)
else:
page = str((end_page - 1) * 50)
url = 'https://{}/api/v2/search_items/?by=relevancy&keyword={}&limit=50&newest={}&order=desc&page_type=search &price_max={}&price_min={}'.format(
website, keyword, page, high_price, low_price)
return url
# 解析列表页接口,获取详情url
def parse_list(self, url, config):
urls = []
website = config['website']
con = pub.get_content(url)
items = con['items']
for item in items:
itemid = item['itemid']
shopid = item['shopid']
link = 'https://{}/api/v2/item/get?itemid={}&shopid={}'.format(website, itemid, shopid)
urls.append(link)
return urls
# 商品详情
def details(self, urls, config):
count = 1
for url in urls:
config['count'] = count
self.parse_details(url, config)
count += 1
# 解析详情页
def parse_details(self, det_url, config):
begin, start = pub.begin_time()
config['start'] = start
con = pub.get_content(det_url)
url, ID = self.get_ID(con, config)
item = self.get_static(con)
pictures = self.show_pictures(con)
category_text = self.get_category(con)
desc = self.get_desc(con)
variants = self.get_skuinfo(con)
info = {
'platform': 'shopee',
'config': config,
'item': item,
'ID': ID,
'url': url,
'pictures': pictures,
'category_text': category_text,
'desc': desc,
'long_descroption': '',
'variants': variants
}
pub.details(info)
end, over = pub.end_time()
print('当前耗时%.02f秒' % (end - begin), '\n')
# 获取描述信息
def get_desc(self,con):
deacribe = []
trace = con['item']['description']
deacribe.append(trace)
desc = pub.exp3(deacribe)
return desc
# 获取ID
def get_ID(self, con, config):
website = config['website']
itemid = str(con['item']['itemid'])
shopid = str(con['item']['shopid'])
# name = con['item']['name']
# new_name = name.replace(' ', '-').replace('#', '-').replace('?', '')
url = "https://{}/shopee-i.{}.{}".format(website, shopid, itemid)
return url, itemid
# 获取单属性元素
def get_static(self, con):
# brand = con['item']['brand']
sales = str(con['item']['sold'])
comment = str(con['item']['cmt_count'])
collect = str(con['item']['liked_count'])
title = con['item']['name']
try:
pre_price = con['item']['price_max']
except:
pre_price = con['item']['price']
present_price = str(int(pre_price) / 100000)
try:
ori_price = con['item']['price_before_discount']
original_price = str(int(ori_price) / 100000)
except:
original_price = ''
item = {
'title': title,
'sales': sales,
'comment': comment,
'collect': collect,
'present_price': present_price,
'original_price': original_price,
'location': '',
'store_name': '',
'box_content': '',
'grade': '',
'weight': ' ',
'brand': 'No brand'
}
return item
# 展示图
def show_pictures(self, con):
master_map = 'https://cf.shopee.com.my/file/' + con['item']['image']
imgs = con['item']['images']
other_imgs = ['https://cf.shopee.com.my/file/' + i + '_tn' for i in imgs]
extra_imgs = pub.exp3(other_imgs)
pictures = {
'master_map': master_map,
'extra_imgs': extra_imgs,
'HD_imgs': '',
'var_img': ''
}
return pictures
# 获取分类
def get_category(self, con):
category = []
categories = con['item']['categories']
for index in range(0, len(categories)):
display_name = categories[index]['display_name']
category.append(display_name)
category_text = pub.exp3(category)
return category_text
# 获取变体
def get_skuinfo(self, con):
info_list = []
models = con['item']['models']
for index in range(0, len(models)):
name = models[index]['name']
if ',' in name:
name_list = name.split(',')
else:
name_list = []
name_list.append(name)
info_list.append(name_list)
variants = pub.exp3(info_list)
return variants
# 条件输入
class Condition(object):
# 获取输入条件
def run(self):
print('1.shopee商品搜索' + '\t' + '2.shopee店铺搜索' + '\t' + '3.shopee单品链接')
platform = self.get_platform()
config = self.search_other(platform)
return config
# 渠道选择
def get_platform(self):
search_method = input('请选择商品采集渠道:')
platform = ''
if search_method == '1':
platform = 'shopee_product'
elif search_method == '2':
platform = 'shopee_store'
elif search_method == '3':
platform = 'shopee_link'
return platform
# 平台站点
def site_choose(self):
print()
print('+' + '-' * 28 + '+')
print('|' + '平台站点选择'.center(22) + '|')
print('|' + ' ' * 28 + '|')
print('|' + '1.新加坡'.ljust(11) + '2.马来西亚'.ljust(10) + '|')
print('|' + '3.泰国'.ljust(12) + '4.菲律宾'.ljust(11) + '|')
print('|' + '5.越南'.ljust(12) + '6.印尼'.ljust(12) + '|')
# print('|' + '7.台湾'.ljust(12) + ' '.ljust(14) + '|')
print('+' + '-' * 28 + '+', '\n')
# 获取平台站点
def get_site(self):
terrace = input('请选择shopee平台站点(1-7):')
site = ''
if terrace == '1':
site = 'sg'
elif terrace == '2':
site = 'my'
elif terrace == '3':
site = 'th'
elif terrace == '4':
site = 'ph'
elif terrace == '5':
site = 'vn'
elif terrace == '6':
site = 'id'
elif terrace == '7':
site = 'tw'
return site
# 其他搜索条件
def search_other(self, platform):
low_price = 'None'
high_price = 'None'
end_page = 'None'
shop_id = 'None'
item_id = 'None'
if platform == 'shopee_link':
keyword = input('请输入shopee单品链接:')
site = re.findall('https://(.*?)/', keyword)[0][-2:]
shop_id = re.findall(r'-i.(\d+).', keyword)[0]
item_id = re.findall(r'-i.(\d+).(\d+)', keyword)[0][1]
else:
self.site_choose()
site = self.get_site()
if platform == 'shopee_product':
keyword = input('请输入要搜索的商品(英文):')
pub.exchange_rate()
low_price = input('请输入商品的最低价:') # 商品最低价
high_price = input('请输入商品的最高价:') # 商品最高价
else:
print('\n', '示例:https://shopee.sg/shop/139267434/search?page=3&sortBy=pop' + '\t' + '—>139267434', '\n')
keyword = input('请输入要搜索的店铺:')
end_page = input('请输入商品列表页码:') # 商品列表终止页
config = {'cid': 0, 'site': site, 'platform': platform, 'keyword': keyword, 'end_page': end_page,
'low_price': low_price, 'high_price': high_price, 'shop_id': shop_id, 'item_id': item_id}
return config
if __name__ == '__main__':
test = Condition()
config = test.run()
sh = ShopeeSpider()
sh.main(config)
共有采集文件
# -*- coding:utf-8 -*-
from fake_useragent import UserAgent
import urllib.request
import urllib.parse
import requests
import pymysql
import logging
import execjs
import json
import time
import csv
import re
import os
# 公共解析块
class Pulic(object):
# 开始时间
def begin_time(self):
start = time.time()
now_time = int(time.time())
return start, now_time
# 结束时间
def end_time(self):
end = time.time()
over = int(time.time())
return end, over
# 日志存储
def logg(self, data):
logger = logging.getLogger(__name__) # 日志
logger.setLevel(level=logging.INFO) # 日志级别
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 日志时间、执行程序路径、日志当前行号、日志级别、日志信息
sh = logging.StreamHandler() # 往屏幕上输出
sh.setFormatter(formatter) # 设置屏幕上显示的格式
# today = datetime.now()
# log_file_path = "login-{}-{}-{}.log".format(today.year, today.month, today.day)
handler = logging.FileHandler('error.log', encoding='utf-8') # 往文件输出
handler.setFormatter(formatter) # 设置文件写入格式
logger.addHandler(handler) # 把对象加入到logger里
logger.addHandler(sh)
logger.info(data)
# 平台汇率换算
def exchange_rate(self):
print()
print('+' + '-' * 38 + '+')
print('|' + '汇率换算'.center(34) + '|')
print('|' + ' ' * 38 + '|')
print('|' + '1.人民币兑新加坡元'.ljust(20) + '1:0.2'.ljust(10) + '|')
print('|' + '2.人民币兑马来西亚林吉特'.ljust(17) + '1:0.6'.ljust(10) + '|')
print('|' + '3.人民币兑泰铢'.ljust(22) + '1:4.5'.ljust(10) + '|')
print('|' + '4.人民币兑菲律宾比索'.ljust(19) + '1:7.5'.ljust(10) + '|')
print('|' + '5.人民币兑越南盾'.ljust(21) + '1:3376.5'.ljust(10) + '|')
print('|' + '6.人民币兑印尼卢比'.ljust(20) + '1:2061.5'.ljust(10) + '|')
print('+' + '-' * 38 + '+', '\n')
# 建立文件夹
def mkdir(self, path):
path = path.strip() # 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在 存在 True, 不存在 False
# 判断结果
if not isExists: # 如果不存在则创建目录
os.makedirs(path) # 创建目录操作函数
print(path + ' 创建成功')
return True
else:
print(path + ' 目录已存在') # 如果目录存在则不创建,并提示目录已存在
return False
# 表格详情页存储
def save_csv(self, path, info, platform):
csv_file = open(path + '/' + platform + '商品详情.csv', 'a', newline='', encoding='utf-8-sig')
writer = csv.writer(csv_file)
writer.writerow(info)
csv_file.close() # 写入完成,关闭文件
# 获取html页面
def gbk_html(self, url):
ua = UserAgent() # 调用
headers = {'User-Agent': ua.random} # 随机
res = requests.get(url, headers=headers)
res.encoding = "gbk"
html = res.text
return html
# 获取html页面
def utf8_html(self, url):
ua = UserAgent() # 调用
headers = {'User-Agent': ua.random} # 随机
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
html = res.text
return html
# 获取数据流
def get_content(self, url):
ua = UserAgent() # 调用
headers = {'User-Agent': ua.random} # 随机
content = requests.get(url, headers=headers).content
bs = str(content, encoding="utf-8") # 将字节流转为str类型
con = json.loads(bs)
return con
# 单属性转文字
def exp1(self, parseHTML, formula):
example = lambda x: parseHTML.xpath(formula)[0].strip().replace('(', '').replace(')', '') if parseHTML.xpath(
formula) else ''
return example(formula)
# 价格区间分割
def exp2(self, arg):
example = lambda x: x.split('-')[1] if '-' in x else x
return example(arg)
# 数组字符转json
def exp3(self, arg):
example = lambda x: json.dumps(x) if len(x) > 0 else ''
return example(arg)
# url、img前缀判断
def exp4(self, arg):
example = lambda x: 'https:' + x if x[0:6] != 'https:' else x
return example(arg)
# 将xpath列表转为字符列表
def exp6(self, prop):
example = lambda x: [x[i].text for i in range(0, len(x))]
return example(prop)
# url、img列表带前缀转换
def exp7(self, arg):
example = lambda x: ['https:' + i if i[0:6] != 'https:' else i for i in x]
return example(arg)
# 获取收藏人气
def get_coolect(self, parseHTML, coll):
try:
collect = parseHTML.xpath(coll)[0].replace('(', '').replace(')', '').replace('(', '').replace(
')', '').replace('.', '0').replace('人气', '') # 收藏
except:
collect = ''
return collect
# 变体图片
def var_picture(self, parseHTML, var_info):
var_imgs_dict = {}
pict = parseHTML.xpath(var_info)
var_pictures = parseHTML.xpath(var_info + '/@style') # 变体图片
num = len(var_pictures)
for var_info in pict:
if num > 0:
try:
var_name = var_info.xpath('./span')[0].text
link = var_info.xpath('./@style')[0]
var_picture = link.replace('background:url(', '').replace(') center no-repeat;', '')
var_photo = self.exp4(var_picture)
var_img = self.picture_replace(var_photo)
var_imgs_dict[var_name] = var_img
num = num - 1
except:
pass
var_imgs = self.exp3(var_imgs_dict)
return var_imgs
# 合并变体
def get_variant(self, parseHTML, match_list):
info_list = [] # 匹配变体信息块
for match in match_list:
prop = parseHTML.xpath(match)
if prop:
var_info = self.exp6(prop)
info_list.append(var_info)
variant = self.exp3(info_list) # 转换json数组
return variant
# 展示大图
def show_picture(self, parseHTML, match):
img_list = []
lazy = 'https://cbu01.alicdn.com/cms/upload/other/lazyload.png'
pic = parseHTML.xpath(match) # 展示大图
for pictures_index in range(0, len(pic)):
picture = pic[pictures_index]
if 'tbvideo' not in picture and picture != lazy:
photo = self.exp4(picture)
img = self.picture_replace(photo)
img_list.append(img)
return img_list
# 图片大小更改
def picture_replace(self, photo):
match_formula = re.compile(r'(\d+)x(\d+)')
num_items = re.findall(match_formula, photo)
num = list(num_items[0])[0]
photo = photo.replace(num + 'x' + num, '800x800')
return photo
# 主副套图
def set_figure(self, img_list):
master_map = img_list[0]
img_list.remove(master_map)
other_img = self.exp3(img_list)
return master_map, other_img
# lazada、shopee详情信息
def details(self, info):
config = info['config']
count = config['count']
path = config['path']
start = config['start']
cid = config['cid']
site = config['site']
platform = info['platform']
ID = info['ID']
url = info['url']
desc = info['desc']
variants = info['variants']
category_text = info['category_text']
long_descroption = info['long_descroption']
pictures = info['pictures']
master_map = pictures['master_map']
extra_imgs = pictures['extra_imgs']
HD_imgs = pictures['HD_imgs']
var_img = pictures['var_img']
item = info['item']
title = item['title']
store_name = item['store_name']
brand = item['brand']
location = item['location']
present_price = item['present_price']
original_price = item['original_price']
sales = item['sales']
comment = item['comment']
collect = item['collect']
grade = item['grade']
weight = item['weight']
box_content = item['box_content']
print('第%02d个商品解析成功' % count)
#
# details_info = [cid, platform, site, ID, title, master_map, store_name, brand, location, present_price,
# original_price, sales, comment, collect, grade, url, extra_imgs, HD_imgs, weight,
# variants, desc, category_text, start, long_descroption, var_img, variants, box_content]
# sql.save_details(details_info)
cav_info = [ID + '\t', title, master_map, store_name, brand, location, present_price,
sales, comment, collect, grade, url, extra_imgs, variants, desc, original_price,
category_text, HD_imgs, var_img, long_descroption, site, box_content, platform]
self.save_csv(path, cav_info, platform)