Python实现数据可视化(饼状图,柱状图)
emmm…
今天看到好友转发的消息p1,讲了一个掷骰子的游戏p2,然后算了一下发现期望是3.1左右,好像要比每次支付的2.99元要多?
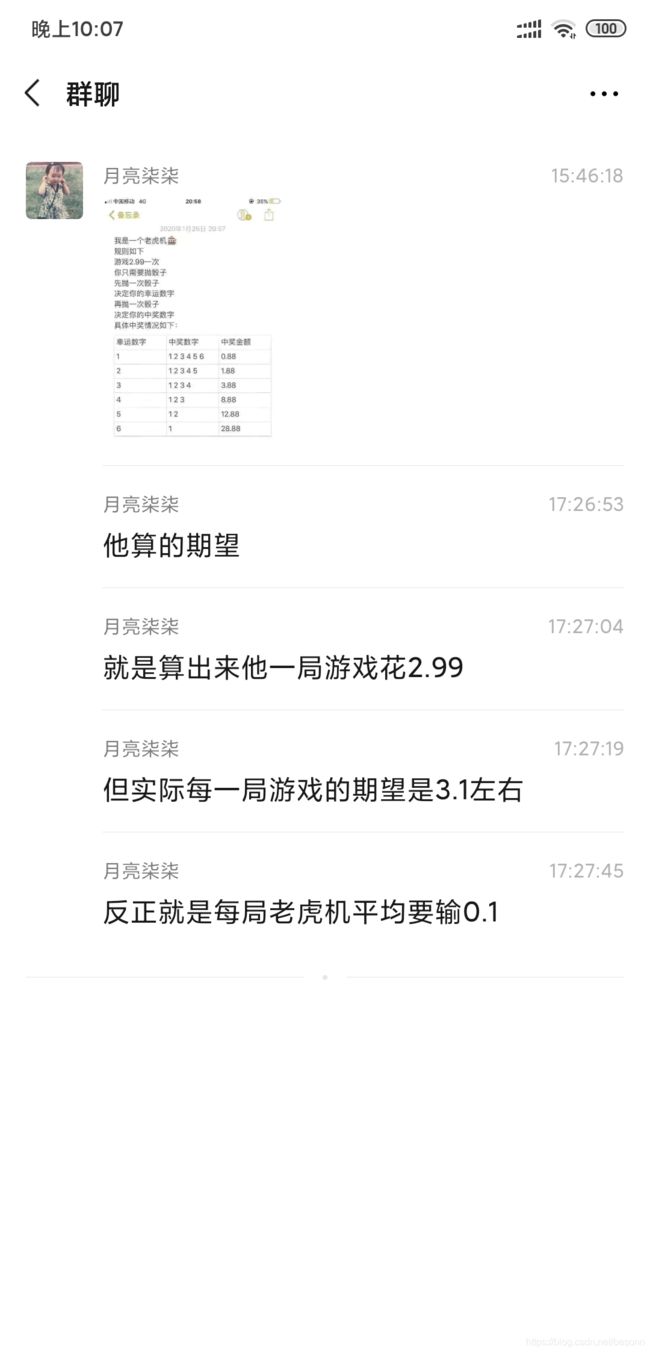
感觉这个用编程来解正好[旺柴]正好最近在看python就索性拿来当成一个练手的小项目[吃瓜]
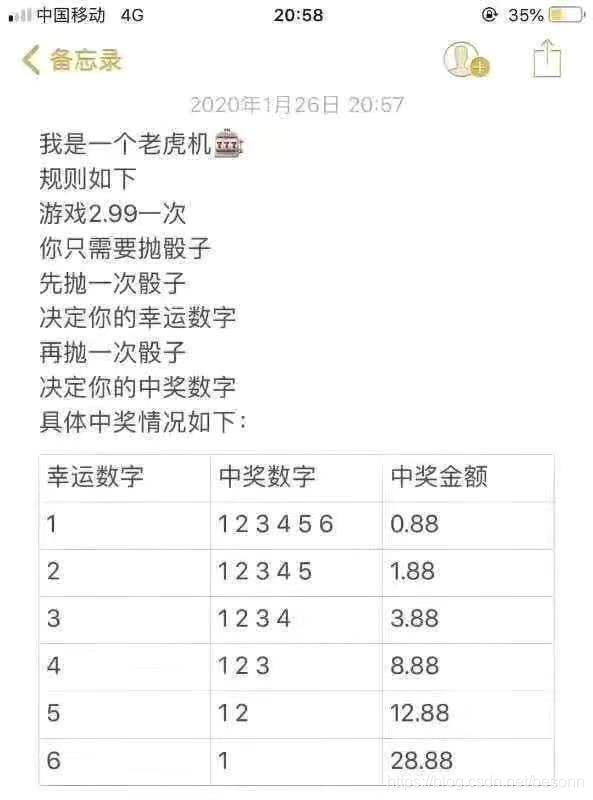
问题:计算期望
思路:不想按照掷骰子的概率去算…所以直接用随机数生成器进行n次独立实验的模拟,然后把频率当成概率计算期望,当然关键还是数据可视化
p3进行n次模拟,这里取的一千万次1e8, 本来想取一亿次模拟但是python太慢了[捂脸]将每次获奖类型保存在prize列表里,存入.csv文件
p4p5p6读取文件画饼状图,这里坑了我好几次,最后还是统计出像样的数据和图来了(p7
Wechar_Game.py
import random
import numpy as np
payment = 2.99 # 每次支付
prize=[] # 储存每次获奖情况
n=10000000 #n次实验
lucky_num=np.random.randint(1,7,n) # 第一次掷色子,幸运数字
get_num=np.random.randint(1,7,n) # 第二次掷色子,中奖数字
for i in range(0,n): # 遍历列表
if lucky_num[i]==1:
prize.append(0) # 0.88元
elif lucky_num[i]==2 and get_num[i]!=6:
prize.append(1) # 1.88元
elif lucky_num[i]==3 and get_num[i]!=5 and get_num[i]!=6:
prize.append(2) # 3.88元
elif lucky_num[i]==4 and(get_num[i]==1 or get_num[i]==2 or get_num[i]==3):
prize.append(3) # 8.88元
elif lucky_num[i]==5 and (get_num[i]==1 or get_num[i]==2):
prize.append(4) # 12.88元
elif lucky_num[i]==6 and get_num[i]==1:
prize.append(5) #28.88元
else:
prize.append(6) # 未中奖
#print("%f %f" %(prize/n,payment))
np.savetxt('prizes.csv', prize) # 存储到csv
Graph.py
import csv
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def read_prizes():
# 读取文件
pr = pd.read_csv("prizes.csv")
prizes=[]
# 设置中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#设置变量
none=0 # 未中奖
six=0 # 0.88
five=0 # 1.88
four=0 # 3.88
three=0 # 8.88
two=0 # 12.88
one=0 # 28.88
for num in pr.iloc[:,0]: # 遍历第一列所有数据
# 将str 转化成 float
if float(num) == 0:
six+=1
elif float(num)==1:
five+=1
elif float(num)==2:
four+=1
elif float(num)==3:
three+=1
elif float(num)==4:
two+=1
elif float(num)==5:
one+=1
elif float(num)==6:
none+=1
#图标
labels = ['谢谢惠顾','0.88安慰奖', '1.88鼓励奖', '3.88理财奖','8.88惊爆奖','12.88特等奖','28.88感恩大回馈']
# 对应变量
values = [none,six,five,four,three,two,one]
# 角度
explode=[0,0.1,0,0,0,0]
# 图例颜色
colors = ['gray','y', 'm', 'b','g','r','c']
# 图标题目
plt.title("搏一搏 单车变摩托(1e8)", fontsize=25)
# 各项属性
plt.pie(values, labels=labels, colors=colors, startangle=180, shadow=True, autopct='%1.6f%%')
plt.axis('equal')
# 保存图片
plt.savefig('E:\\Documents\\千万.png')
# 显示图片
plt.show()
if __name__ =="__main__":
read_prizes()
分析一下:千万次独立重复实验后把频率看成概率,期望计算结果p8,发现和最初3.1左右差别不大,一定比2.99大。所以真的重复那么多次很可能赚钱[捂脸]但是单次不回本的概率可以达到0.72219269!也就是大约72%!
总结一下遇到的坑:
- 忘记了不中奖这一种情况……
- 忽略了python区间(a,b)取前不取后的特性……
- csv格式保存文件是科学计数法保存成字符转的类型,想要使用还需要转化成数字进行计算
- pandas里, pr = pd.read_csv(’.csv’) ,pr是一个数据的矩阵,如何使用。
方法归类:
data = pd.read_csv(self.path)
print(data)
print(data.describe())
print(data.head(5)) #前5行
print(data.iloc[0,:]) #第一行所有数据
print(data.iloc[[1,3,4],:]) #第2 4 6行
print(data.iloc[:,:]) #所有航所有列
print(data.loc[:,'cid'])
for index,row in data.iterrows():
print(row['cid'],row['name'],type(row['cid']),type(row['name']))
- 画图
直方图用到的:
https://www.cnblogs.com/Pythonmiss/p/10642589.html
直方图拟合正态分布曲线:
https://blog.csdn.net/jiangjiang_jian/article/details/80664709