时隔一年,盘点CVPR 2019影响力最大的20篇论文

CVPR 2019 已经过去一年了,本文盘点其中影响力最大的 20 篇论文,这里的影响力以谷歌学术上显示的论文的引用量排序,截止时间为2020年7月22日。
其中的一些结论蛮有意思的:
1. 这 20 篇论文全部开源了。不开源的论文复现代价大,别人参考的门槛会高很多,维护好论文对应的开源软件能极大提高论文影响力。
2. 方向分布在GAN、人脸识别、神经架构搜索、语义分割、图像合成、姿态估计、迁移学习、3D目标检测、全景分割、目标跟踪、图像分类、网络结构设计(可变形卷积)、对抗学习、三维重建等方向。
3. 引用数排名第一的 StyleGAN 引用次数 956 远超第二名 ArcFace 689 次,和第三名 Mnasnet 486 次。第 10 名 FBnet 228次,第20 名 Sophie 157 次。
4. 这些论文绝大多数有工业界巨头的身影,英伟达贡献 2 篇 (第一名来自英伟达),谷歌贡献 5 篇,Facebook 贡献 8 篇, 国内商汤 1 篇,京东 1篇。
5. 目标检测是计算机视觉领域非常火的方向,但入选的两篇全是3D点云目标检测。
6. 人脸识别在工业界应用很火,但只有一篇论文入前20(大名鼎鼎的 ArcFace),说明这个领域的技术也许已经趋于成熟。
。。。
大家发现还有那些有意思的规律,欢迎在文末留言交流。
No.1 StyleGAN
A style-based generator architecture for generative adversarial networks
StyleGAN-基于样式的生成对抗网络
作者 | Tero Karras, Samuli Laine, Timo Aila
单位 | 英伟达
论文 | https://arxiv.org/abs/1812.04948
代码 | https://github.com/NVlabs/stylegan
解读 | https://zhuanlan.zhihu.com/p/63230738
引用次数 | 956

No.2 Arcface 人脸识别
Arcface: Additive angular margin loss for deep face recognition
用于深度人脸识别的加法角余量损失
作者 | Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou
单位 | 伦敦帝国学院;InsightFace
论文 | https://arxiv.org/abs/1801.07698
代码 | https://github.com/deepinsight/insightface
解读 | https://zhuanlan.zhihu.com/p/76541084
引用次数 | 689

No.3 Mnasnet,神经架构搜索
Mnasnet: Platform-aware neural architecture search for mobile
移动端自动设计网络
作者 | Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le
单位 | 谷歌
论文 | https://arxiv.org/abs/1807.11626
代码 | https://github.com/tensorflow/tpu/tree/
master/models/official/mnasnet
引用次数 | 486

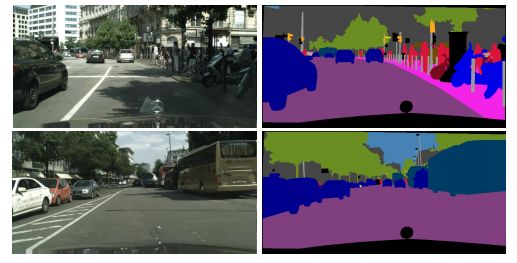
No.4 DANet 场景分割(语义分割)
Dual attention network for scene segmentation
场景分割的双注意力网络
作者 | Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, Hanqing Lu
单位 | 中科院;京东;国科大
论文 | https://arxiv.org/abs/1809.02983
代码 | https://github.com/junfu1115/DANet
引用次数 | 400
No.5 AutoAugment 数据增广
AutoAugment: Learning augmentation strategies from data
作者 | Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, Quoc V. Le
单位 | 谷歌大脑
论文 | https://arxiv.org/abs/1805.09501
代码 | https://github.com/tensorflow/models/tree/
master/research/autoaugment
引用次数 | 377

No.6 SPADE 图像合成
Semantic image synthesis with spatially-adaptive normalization
具有空间适应性归一化的语义图像合成技术
作者 | Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
单位 | UC Berkeley ;英伟达;MIT CSAIL
论文 | https://arxiv.org/abs/1903.07291
代码 | https://github.com/NVlabs/SPADE
备注 | CVPR 2019 Oral
引用次数 | 292
No. 7 HRNet 人体姿态估计
Deep high-resolution representation learning for human pose estimation
用于人体姿态估计的深度高分辨率表征学习
作者 | Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang
单位 | 中国科学技术大学;微软亚洲研究院
论文 | https://arxiv.org/abs/1902.09212
代码 | https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
解读 | https://zhuanlan.zhihu.com/p/57876066
引用次数 | 282

No.8 Auto-Deeplab NAS+语义分割
Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation
作者 | Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan Yuille, Li Fei-Fei
单位 | 约翰斯霍普金斯大学;谷歌;斯坦福大学
论文 | https://arxiv.org/abs/1901.02985
代码 | https://github.com/tensorflow/models/tree/
master/research/deeplab
解读 | 谷歌Auto-DeepLab:自动搜索图像语义分割架构算法开源实现
备注 | CVPR 2019 Oral
引用次数 | 233

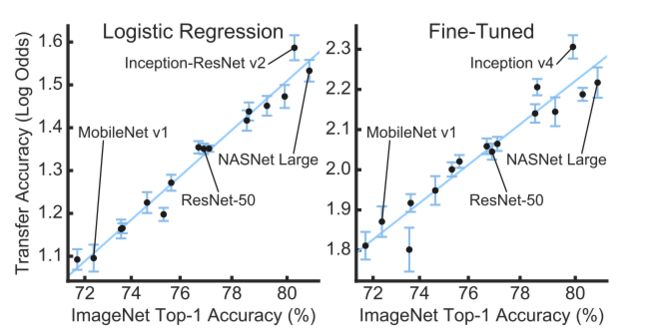
No.9 迁移学习
Do better imagenet models transfer better?
作者 | Simon Kornblith, Jonathon Shlens, Quoc V. Le
单位 | 谷歌大脑
论文 | https://arxiv.org/abs/1805.08974
代码 | https://github.com/lsh3163/Imagenet-Better
备注 | CVPR 2019 Oral
引用次数 | 232
No.10 FBNet 神经架构搜索
FBnet: Hardware-aware efficient convnet design via differentiable neural architecture search
通过可微的神经架构搜索实现硬件感知的高效convnet设计
作者 | Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, Kurt Keutzer
单位 | UC Berkeley;普林斯顿大学;Facebook
论文 | https://arxiv.org/abs/1812.03443
代码 | https://github.com/facebookresearch/
mobile-vision
引用次数 | 228

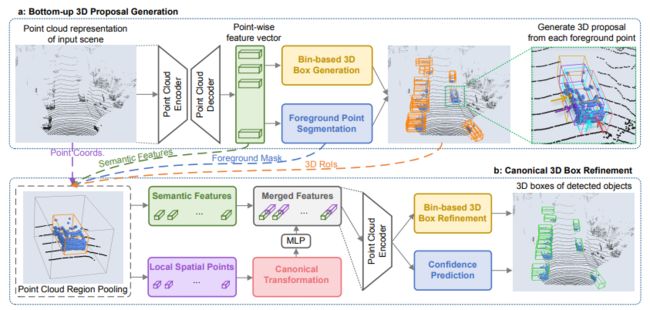
No.11 PointRCNN 3D目标检测
Pointrcnn: 3d object proposal generation and detection from point cloud
PointRCNN 第一个基于原始点云的3D目标检测
作者 | Shaoshuai Shi, Xiaogang Wang, Hongsheng Li
单位 | 香港中文大学
论文 | https://arxiv.org/abs/1812.04244
代码 | https://github.com/sshaoshuai/PointRCNN
解读 | https://zhuanlan.zhihu.com/p/71564244
引用次数 | 207
No.12 Pointpillars 3D目标检测
Pointpillars: Fast encoders for object detection from point clouds
从点云中进行目标检测的快速编码器
作者 | Alex H. Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, Oscar Beijbom
单位 | nuTonomy: an APTIV company
论文 | https://arxiv.org/abs/1812.05784
代码 | https://github.com/nutonomy/second.pytorch
引用次数 | 191

No.13 全景分割开山之作
Panoptic segmentation
作者 | Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, Piotr Dollár
单位 | FAIR;海德堡大学
论文 | https://arxiv.org/abs/1801.00868
代码 | https://github.com/facebookresearch/detectron2/
引用次数 | 186

No.14 Siamrpn++ 目标跟踪
Siamrpn++: Evolution of siamese visual tracking with very deep networks
作者 | Bo Li, Wei Wu, Qiang Wang, Fangyi Zhang, Junliang Xing, Junjie Yan
单位 | 商汤;中科院自动化所;中科院计算所
论文 | https://arxiv.org/abs/1812.11703
代码 | http://github.com/STVIR/pysot
主页 | http://bo-li.info/SiamRPN++/
解读 | https://zhuanlan.zhihu.com/p/56254712
引用次数 | 188

No.15 SiamMask 目标跟踪
Fast Online Object Tracking and Segmentation: A Unifying Approach
作者 | Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, Philip H.S. Torr
单位 | 中科院自动化所;牛津大学;FiveAI
论文 | https://arxiv.org/abs/1812.05050
代码 | https://github.com/foolwood/SiamMask
主页 | http://www.robots.ox.ac.uk/~qwang/SiamMask/
解读 | CVPR 2019 | 惊艳的SiamMask:开源快速同时进行目标跟踪与分割算法
引用次数 | 185
No.16 亚马逊图像分类大礼包
Bag of tricks for image classification with convolutional neural networks
作者 | Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li
单位 | 亚马逊
论文 | https://arxiv.org/abs/1812.01187
代码 | https://github.com/dmlc/gluon-cv
引用次数 | 183
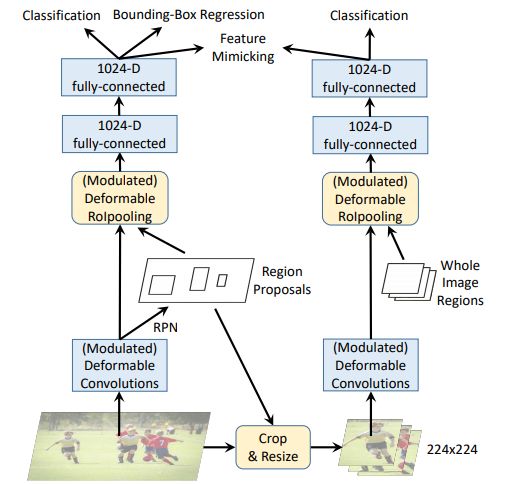
No.17 升级版可变形卷积
Deformable convnets v2: More deformable, better results
作者 | Xizhou Zhu, Han Hu, Stephen Lin, Jifeng Dai
单位 | 中国科学技术大学;微软亚洲研究院
论文 | https://arxiv.org/abs/1811.11168
代码 | https://github.com/msracver/Deformable-ConvNets
解读 | https://zhuanlan.zhihu.com/p/77644792
引用次数 | 182
No.18 对抗学习
Feature denoising for improving adversarial robustness
作者 | Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
单位 | 约翰斯霍普金斯大学;FAIR
论文 | https://arxiv.org/abs/1812.03411
代码 | https://github.com/facebookresearch/ImageNet-Adversarial-Training
引用次数 | 179
No. 19 DeepSDF 三维模型表示(三维重建)
Deepsdf: Learning continuous signed distance functions for shape representation
作者 | Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, Steven Lovegrove
单位 | 华盛顿大学;麻省理工学院;Facebook Reality Labs
论文 | https://arxiv.org/abs/1901.05103
代码 | https://github.com/facebookresearch/DeepSDF
引用次数 | 172

No. 20 Sophie 行人路径预测(自动驾驶领域)
Sophie: An attentive gan for predicting paths compliant to social and physical constraints
作者 | Amir Sadeghian, Vineet Kosaraju, Ali Sadeghian, Noriaki Hirose, S. Hamid Rezatofighi, Silvio Savarese
单位 | 斯坦福大学;佛罗里达大学;阿德莱德大学
论文 | https://arxiv.org/abs/1806.01482
代码 | https://github.com/StanfordVL/sophie
引用次数 | 157


备注如:CV

计算机视觉交流群
交流学习最新CV技术前沿,扫码备注拉入群。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 