yolo入门之二----yolo代码解析
you only look once 就能懂
voc_annotation.py
1. 转换标注文件:(xml----->txt)
in_file = open(‘VOCdevkit/VOC%s/Annotations/%s.xml’%(year, image_id)) 打开xml文件
tree=ET.parse(in_file) 解将xml文件析成ElementTree类的对象
root = tree.getroot() 获取xml文件的根节点
接下来是一个循环: for obj in root.iter(‘object’):
对于根节点中的条目 object的循环:

由于我这里只有一个目标,所以应该只是循环一次
difficult = obj.find(‘difficult’).text 应该指图像中是否有检测目标
cls = obj.find(‘name’).text 这里是people
cls_id = classes.index(cls) 之前定义过 classes = [“people”] 这里获取索引(第几类检测对象)
xmlbox = obj.find(‘bndbox’) 找到boundingbox的边界的父条目
b = (int(xmlbox.find(‘xmin’).text), int(xmlbox.find(‘ymin’).text), int(xmlbox.find(‘xmax’).text), int(xmlbox.find(‘ymax’).text)) 将父条目下的边界数值保存为元组b
list_file.write(" " + “,”.join([str(a) for a in b]) + ‘,’ + str(cls_id)) 说明了下面的五个数字都是什么
分别是四个边界值 + 检测对象类别
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
2. wd = getcwd()
获得此py文件所获得的目录
3. 下面进行一个循环
对于年份、什么集合(训练、验证、测试,因为~VOCdevkit\VOC2012\ImageSets\Main下分为训练、验证、测试集几个txt,txt里面写着哪些图片用来训练,那些用来验证,那些用来测试)进行循环:
.strip().split()
.strip() 删除字符串头尾的空白符(包括’\n’, ‘\r’, ‘\t’, ’ ')
.split() 以空字符进行字符串分割
list_file = open(’%s_%s.txt’%(year, image_set), ‘w’) 创建好txt文件准备写入需要的信息
convert_annotation(year, image_id, list_file) 将xml的信息提取出来写入项目文件夹下的txt文件,如2012_test.txt
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
train.py
下面是训练代码
导入必要的包
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
定义主函数
annotation_path为由voc_annotation.py生成的txt文件(再说一遍,因为xml并不是yolo所识别的数据格式,因此需要用这个文件将xml文件转换为txt信息。)
打开’2012_train.txt’,我们可以看到:
~/train1.jpg 189,171,233,299,0
后面有五个数字:189,171,233,299,0 分别表示 什么呢?
之前讲过,前四个数字约束了boundingbox的大小,0代表了第0类别
log_dir = ‘logs/000/’ 模型保存地址
classes_path = ‘model_data/voc_classes.txt’ 内容为people(这里我仅用了一类)
anchors_path = ‘model_data/yolo_anchors.txt’ yolo中的anchor到底是什么呢?
直接上吴恩达的教程
https://mooc.study.163.com/learn/2001281004?tid=2001392030#/learn/content?type=detail&id=2001729339
简而言之,anchor box是为了处理一个格子中有多个检测对象的情况,一般情况下anchorbox可以设置5-10个,涵盖想要检测的各种对象的形状。打开yolo_anchors文件就可以看到内容为:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
九个anchorbox
input_shape = (416, 416) 必须与输入一致(yolo算法不能改变输入图像的尺寸)
def _main():
annotation_path = '2012_train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
input_shape = (416, 416) # multiple of 32, hw
model = create_model(input_shape, anchors, len(class_names) )
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
下面分别看主函数中嵌套的几个函数:
- 获得类别函数get_class:
f.readlines()读取整个文件,然后把每一行放到一个列表里。所以你要是向voc_classes文件中添加类别时候一定要另起一行添加,如:

返回一个由各个类别名称组成的列表
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
- 获得anchorbox函数get_anchors
f.readline()读取一行,是在上一次读取的基础上读取。在这里只是读取一行用逗号分隔
所以在添加a时需要全部用逗号隔开。
最后需要reshape成为一个(9, 2 )的形式(9表示9个box,2表示一个box的长宽)
def get_anchors(anchors_path):
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
- create_model 建立模型函数
image_input = Input(shape=(None, None, 3))
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], num_anchors//3,num_classes+5)) for l in range(3)]
h = w = 416
num_anchors为anchorbox的个数
num_classes为类别个数
为什么y_true是这样呢?存疑
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss导入了yolobody,因此这里直接获取yolo结构
model_body = yolo_body(image_input, num_anchors//3, num_classes)
至于为什么要地板除3还是不明白
这个model_body到底是什么样子呢?
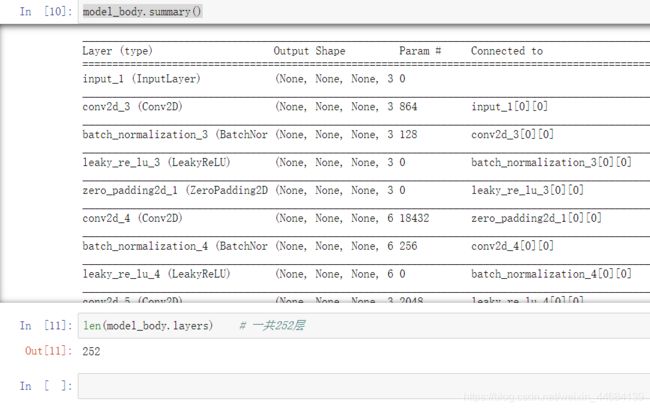
一共252层,最后7层可训练
model = Model([model_body.input, *y_true], model_loss)
指定输入是什么输出是什么,在跳远连接的代码示例中有用到
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False,
weights_path='model_data/yolo_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers)-7
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
- 训练函数
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
嵌套了
data_generator_wrap
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
np.random.shuffle(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
i %= n
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i += 1
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'):
model.compile(optimizer='adam', loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
batch_size = 3
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.shuffle(lines)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=100, # 500 有点多了
initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')
剩下的可以看这一篇博文