Apriori分析BreadBasket
数据集下载:https://www.kaggle.com/sulmansarwar/transactions-from-a-bakery?select=BreadBasket_DMS.csv
matplotlib设置绘图风格:https://blog.csdn.net/weixin_42968458/article/details/82889736
觉得比较好看的几款:
fivethirtyeight,seaborn-colorblind,seaborn-paper这三款差不多;seaborn-white是背景为白色的。
EDA
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('C:/Users/admin/Desktop/Apriori/BreadBasket_DMS.csv')
df['Item']=df['Item'].str.lower()
x=df['Item']== 'none'
print(x.value_counts())
False 20507
True 786
Name: Item, dtype: int64
df=df.drop(df[df.Item == 'none'].index) #这里不是null,所以不能用df.dropna(axis = 0)
去除没有买东西的记录,none相当于一个去超市逛了逛,但是最后没有买东西。
len(df['Item'].unique())
94
Item一共有94种不同的商品
分析最畅销的商品
df_for_top10_Items=df['Item'].value_counts().head(10)
Item_array= np.arange(len(df_for_top10_Items))
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
plt.figure(figsize=(12,5))
Items_name=['coffee','bread','tea','cake','pastry','sandwich','medialuna','hot chocolate','cookies','brownie']
plt.bar(Item_array,df_for_top10_Items.iloc[:])
plt.xticks(Item_array,Items_name) #设置横坐标
plt.title('Top 5 most selling items',fontsize=18)
#添加数据标签
for x, y in zip(Item_array,df_for_top10_Items.iloc[:]):
plt.text(x+0.05,y+0.15,'%.0f' %y,ha='center',va='bottom')
plt.show()
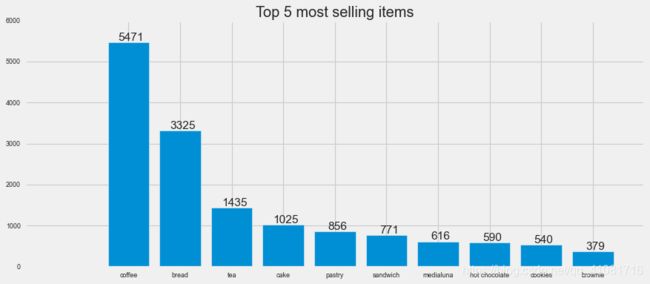
df_for_top10_Items.iloc[:]
coffee 5471
bread 3325
tea 1435
cake 1025
pastry 856
sandwich 771
medialuna 616
hot chocolate 590
cookies 540
brownie 379
Name: Item, dtype: int64
按星期分析的交易频次(售出商品数量)
df['Date'] = pd.to_datetime(df['Date']) #将数据转化为日期格式
df['Time'] = pd.to_datetime(df['Time'],format= '%H:%M:%S' ).dt.hour #获取小时这个数字
df['day_of_week'] = df['Date'].dt.weekday
#得出具体一天是星期几,0表示星期一,6表示星期天
d=df.loc[:,'Date']
df['day_of_week'].value_counts()
5 4605
4 3124
6 3095
3 2646
1 2392
0 2324
2 2321
Name: day_of_week, dtype: int64
weekday_names=[ 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
Weekday_number=[0,1,2,3,4,5,6]
week_df = d.groupby(d.dt.weekday).count().reindex(Weekday_number)
Item_array_week= np.arange(len(week_df))
plt.style.use("seaborn-paper")
plt.figure(figsize=(9,5))
plt.bar(Item_array_week,week_df)
plt.xticks(Item_array_week,weekday_names)
plt.title('Number of Transactions made based on Weekdays',fontsize=18)
#添加数据标签
for x, y in zip(Item_array_week,week_df):
plt.text(x+0.05,y+0.15,'%.0f' %y,ha='center',va='bottom')
plt.show()
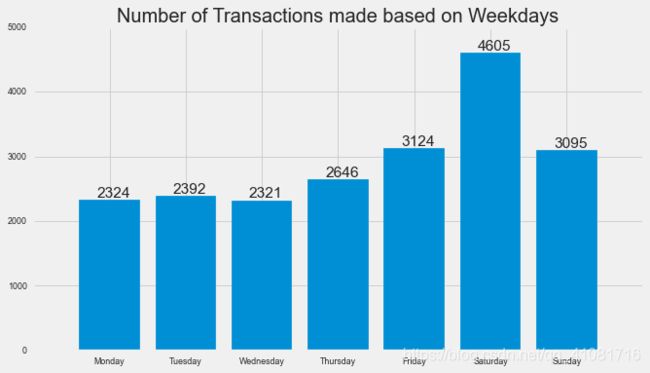
果然从周五开始放飞,一直持续到周日,并且周六购买的数量最多。
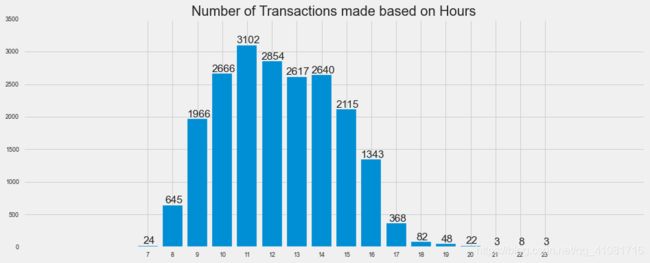
分析各个时段的购买商品数目(注意这里不是顾客数)
dt=df.loc[:,'Time']
Hour_names=[ 7, 8, 9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]
time_df=dt.groupby(dt).count().reindex(Hour_names)
Item_array_hour= np.arange(len(time_df))
plt.figure(figsize=(13,5))
plt.bar(Item_array_hour,time_df)
plt.xticks(Item_array_hour,Hour_names)
plt.title('Number of Transactions made based on Hours',fontsize=18)
#添加数据标签
for x, y in zip(Item_array_hour,time_df):
plt.text(x+0.05,y+0.15,'%.0f' %y,ha='center',va='bottom')
plt.show()
Apriori
同一时间的Transaction,我们认为是一个人的购物篮,所以需要将对应的Item按照Transaction分组,然后形成list,根据Apriori的要求,也可以形成tuple,但是这里最小不要形成tuple,因为对于tuple里只有一个元素的,末尾会添上一个问号,这个会影响到频繁项集的筛选。
处理参考网址:https://cloud.tencent.com/developer/ask/175315
df.groupby(['Transaction'])['Item'].apply(list).head()
Transaction
1 [bread]
2 [scandinavian, scandinavian]
3 [hot chocolate, jam, cookies]
4 [muffin]
5 [coffee, pastry, bread]
Name: Item, dtype: object
from efficient_apriori import apriori
data = list(df.groupby(['Transaction'])['Item'].apply(list))
itemsets, rules = apriori(data, min_support=0.05, min_confidence=0.2)
itemsets
{1: {('bread',): 3097,
('cake',): 983,
('coffee',): 4528,
('cookies',): 515,
('hot chocolate',): 552,
('medialuna',): 585,
('pastry',): 815,
('sandwich',): 680,
('tea',): 1350},
2: {('bread', 'coffee'): 852, ('cake', 'coffee'): 518}}
这里可以发现人们的一些购买习惯,如经常购买的物品,或者经常购买的物品组合,这些购买习惯中隐藏着一定强度的关联规则。
rules
[{bread} -> {coffee}, {cake} -> {coffee}]
min_support和min_confidence的初始值需要小一些,否则输出来是空的。经过不但尝试发现
{bread} -> {coffee}约0.2左右,{cake} -> {coffee}约0.52左右。即买面包后有20%的可能买咖啡,买蛋糕有50%的可能性买咖啡。