my面试
这里写自定义目录标题
- 1.集合
- 一.List和Set
- 1.常用的ArrayList,LinkedList,TreeSet,HashSet。
- 二.Map
- 2.线程
- 一.线程的创建3种方式
- 死锁
- 多线程三大特性
- volatile
- 3.线程池
- 1.线程池的作用及原理
- ==2.常见四种线程池==
- 4.JVM
- ==1.JVM组成==
- ==2.类加载器子系统执行过程==
- ==3.双亲委派机制==
- ==4.运行时数据区==
- ==5.堆区域是怎么划分的==
- ==6.元空间==
- ==7.执行引擎==
- ==8.JVM垃圾回收==
- ==9.常用垃圾回收算法==
- ==选择垃圾收集的时间==
- GC的基本原理
- ==10.常见垃圾收集器==
- 5.JVM的优化
- 1.JIT优化
- 2.JVM内存分区优化
- 调优工具:jvisualvm jconsole
- 3.JVM调优经验
- 4.常用JVM参数参考
- 5.设置jvm参数的几种方式
- 6.数据库优化Sql
- in和exists的区别
- 索引失效
- 1.单机优化--建表三范式
- *2.*单机优化--关系型数据库的优化技术
- ==1.定位慢查询(找出执行效率低Sql)==
- ==2.分析慢查询==
- ==4.索引==
- #1.经常作为查询或者排序条件的字段 建立索引 #2.唯一性太差的字段不适合创建索引 比如性别 #3.频繁更新修改的字段不适合创建索引 因为每次修改都需要重新维护索引结构 导致大量的io
- 单列 只在一个字段创建 多列(复合索引) 由多个字段共同组成索引
- create index dlindex on dept(dname,loc); show indexes from dept;
- 修改
- ==5.存储引擎==
- ==6.分表==:
- 7.分区
- 8. SQL优化小技巧
- 3.多机优化
- 主流方案
- 主从同步
- 测试环境
- Spring
- **什么是框架**
- 1.Spring是一个DI(注入)轻量级控制反转(IOC)和面向切面编程(AOP)的容器框架;
- SpringMVC(默认单利线程安全)
- 一.全注解
- 1.实例化bean的注解
- 2.请求注解
- 2.接收请求参数
- 3.的三种实现
- 4.执行流程
- 二.返回json
- SpringDataJpa
- 技术特点:
- 常用注解
- 1.SpringDataJpa查询Query的使用(重要)
- 2.@Query+@Modifying注解完成修改、删除操作(重要)
- Hibernate
- MyBatis
- 嵌套查询和嵌套结果
- 缓存
- 面试题:mybatis相较于jdbc的优点?
- MyBatis事务
- #和$区别
- 符号转义
- MyBatis的sql可以用xml和注解 的方式
- left join和join
- SpringBoot
- 1.启动流程分为两步
- 2.注解
- 配置文件2种
- SpringCloud
- 五大组件
- 服务熔断
- 服务降级
- 熔断VS降级
- Redis
- 集群:主从和哨兵的集合体
- 主从复制---主数据库(master)和从数据库(slave)
- 哨兵:是监控redis集群的运行状况
- 持久化:在于数据备份和故障恢复
- 缓存雪崩,穿透,击穿
- Elasticsearch
- 基本概念
- 为什么用?
- ES特点和优势
- 倒排索引
- Fastdfs
- fastDFS 是以C语言开发的一项开源轻量级分布式文件系统,他对文件进行管理,主要功能有:文件存储,文件同步,文件访问(文件上传/下载),特别适合以文件为载体的在线服务,如图片网站,视频网站等
- FastDFS由跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)构成。
- Tracker server 追踪服务器
- Storage server 储存服务器
- 客户端Client
- RabbitMq
- 1.1.基本概念
- 1.2.RabbitMQ使用场景
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wELez0pp-1585889807515)(../images/1570516911259-1573355508978.png)]
- 1.3.常见的消息队列
- 1.4.Exchange分类
- 12.如何避免消息丢失?
- 12.1 .手动签收
- 12.2 .持久化
- 7.常用的设计模式
- 1.工厂模式
- 2.抽象模式
- 3.单利模式
- 4.适配器模式
- 5.代理模式
- 6.装饰者模式(Decorator Pattern)
- 6. 观察者模式
- 8.RestFul风格
- RESTful架构
- 三次握手和四次挥手
- TCP和UDP
- 数据结构
- 栈
- 队列
- Ajax -- 异步的js和xml
- 1.获取ajax对象,ajax没有标准化,需要区分浏览器
- 2.发快递:
- 3.使用ajax发送get请求:
- 4.使用ajax发送post请求:
- 5.ie缓冲问题:
- 事务(本地-分布式)
- 事务ACID
- 四种-隔离级别设置
- 事务的-传播机制
- 注解方式:
- 分布式事务
- IO同步阻塞NIO异步阻塞
- 同步阻塞IO:用户线程在内核进行IO操作时被阻塞
- 同步非阻塞IO:是在同步阻塞IO的基础上,将socket设置为NIO(NONBLOCK)。
- 拦截器和过滤器
- 拦截器
- 过滤器
- 过滤器和拦截器的区别:
- 抽象类和接口
- Git和Svn
- 反射
- IO和NIO
- 1.讲讲你理解的 nio和 bio 的区别是啥,谈谈 reactor 模型。
- 同步和异步
- 同步
- 异步
- 深拷贝和浅拷贝
- 欢迎使用Markdown编辑器
- 新的改变
- 功能快捷键
- 合理的创建标题,有助于目录的生成
- 如何改变文本的样式
- 插入链接与图片
- 如何插入一段漂亮的代码片
- 生成一个适合你的列表
- 创建一个表格
- 设定内容居中、居左、居右
- SmartyPants
- 创建一个自定义列表
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
- 导出
- 导入
- 面试大全 https://blog.csdn.net/weixin_43495390/article/details/86533482
1.集合
- 一类是继承自Collection接口,这类集合包含List、Set和Queue等集合类。另一类是继承自Map接口,这主要包含了哈希表相关的集合类。
一.List和Set
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lQWd1yp4-1585889807453)(…/images/image-20191225161348971.png)]
图中的绿色的虚线代表实现,绿色实线代表接口之间的继承,蓝色实线代表类之间的继承。
list 元素 有序可重复 add
set 元素 无序不可重复
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
—Set 无序,唯一
HashSet---底层采用 HashMap 来保存元素
底层数据结构是哈希表。(无序,唯一)
--相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,我们应该为保存到 HashSet 中的对象覆盖 hashCode() 和 equals()。
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
————————————————
版权声明:本文为CSDN博主「游走的大千世界的烤腰子」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhangqunshuai/article/details/80660974
1.常用的ArrayList,LinkedList,TreeSet,HashSet。
- ArrayList,LinkedList的区别?
相同点 都是实现了List接口--都可以存储任意类型多个数据。
1.ArrayList 底层是基于数组实现的,具有查询快的特点。因为可以通过索引直接定位到数据,查询效率高。添加数据慢,数组长度确定后不能修改,如果扩容 会重新创建数组,复制数据,损耗性能。
2.LinkedList 底层基于链表实现的,具有添加快的特点。 因为添加的时候直接创建一个节点就行,不会涉及扩容,效率高。查询较慢,需遍历链表,效率低。
3.LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
- TreeSet,HashSet的区别?
相同点:都是set接口实现类 都可以存储任意类型任意多个数据。
1.TreeSet 此类保证排序后的 set 按照升序排列元素,根据使用的构造方法不同,可能会按照元素的自然顺序 进行排序,或按照在创建 set 时所提供的比较器进行排序。是一个有序集合,元素中按升序排序,缺省是按照自然顺序进行排序,意味着TreeSet中元素要实现Comparable接口;我们可以构造TreeSet对象时,传递实现了Comparator接口的比较器对象.
1.TreeSet 可以对Set集合中的元素进行排序,是线程不安全的。
唯一性(去重):根据比较方法的返回结果是否为0,如果是0,则是相同元素,不保存,如果不是0,则是不同元素,存储。
TreeSet对元素进行排序的方式(2种):
-----元素自身具备比较功能(自然排序),需要实现Comparable接口,并覆盖其compareTo方法。
-----元素自身不具备比较功能(定制排序),则需要实现Comparator接口,并覆盖其compare方法。
2.HashSet 内部的数据结构是哈希表,是线程不安全的。
唯一性(去重):通过对象的hashCode和equals方法来完成对象唯一性的判断。 添加时,用equals判断hashCode值是否相同,不同就保存。
注意:如果元素要存储到HashCode中,必须覆盖hashCode方法和equals方法。
- 总结:ComparaTo()方法和Comparator()方法的区别:
ComparaTo()方法只需要传递一个参数对象,与本类对象进行比较。它是元素的比较方法。
Comparator()方法是集合的比较方法。强行对某个对象 collection 进行整体排序 的比较函数
二.Map
那么哈希冲突如何解决呢? 计算哈希值时,得到了同一个地址
哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
1.常用的 HashMap-不安全,Hashtable-安全,ConcurrentHashMap-安全,Properties
- 三者之间的区别
相同点:都是map接口实现 都是以键值对形式存储值
HashMap 线程不安全 可以以null作为键或值 效率较高
Hashtable 线程安全 不可以以null作为键或值 效率较低
ConcurrentHashMap 线程安全 不可以以null作为键或值 效率相对较高
Properties它是继承了Hashtable 类,以Map 的形式进行放置值, put(key,value) get(key)。 key不能重复
load加载方法 store 保存方法
HashMap底层put方法
在jdk1.8之后,是采用数组+链表+红黑树的结构
长度:1.6之前初始化10 1.8之后长度为0
当调用put方法时,会创建一个数组,根据key的HashCode,计算出hash值(return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);),然后再根据该hash值得到这个元素在数组中的位置(得到该hash值所对应table中索引的方法:int i = indexFor(hash,table.length))(即下标)。
用equals判断key,如果该位置上没有元素,就直接将该元素放到此数组中的该位置上,判断当前链表长度是否>=7,满足就变成红黑树,不满足就直接添加。
如果有元素(hash冲突),判断key的hash值和要添加元素的hash值是否相等,相等就返回覆盖的值。判断当前链表长度是否>=7,满足就变成红黑树,不满足就直接添加。
最后判断是否需要扩容。16*0.75=12 超过12就自动扩容。没有就结束。
HashMap底层get方法
首先计算key的 hash值取得所定位的桶。 桶(entry)存储key-value
如果桶为空则直接返回 null 。
否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
如果第一个不匹配,则判断它的下一个是红黑树还是链表。
红黑树就按照树的查找方式返回值。
不然就按照链表的方式遍历匹配返回值。
从这两个核心方法(get/put)可以看出 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 O(logn)。
HashMap遍历
HashMap的遍历方式
主要通过获取keyset和entryset 然后使用迭代器和foreach
HashMap 是以键值对形式存储值 Entry
ConcurrentHashMap-线程安全
其实和 1.8 HashMap 结构类似,当链表节点数超过指定阈值的话,也是会转换成红黑树的,大体结构也是一样的。
那么它到底是如何实现线程安全的?
答案:其中抛弃了原有的Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
put过程:
1、判断Node[]数组是否初始化,没有则进行初始化操作
2、通过hash定位数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头节点),添加失败则进入下次循环。
3、检查到内部正在扩容,就帮助它一块扩容。
4、如果f!=null,则使用synchronized锁住f元素(链表/红黑树的头元素)。如果是Node(链表结构)则执行链表的添加操作;如果是TreeNode(树型结构)则执行树添加操作。
5、判断链表长度已经达到临界值8(默认值),当节点超过这个值就需要把链表转换为树结构。
6、如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
https://www.jianshu.com/p/5dbaa6707017
hashtable
HashTable是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的Hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
2.线程
一.线程的创建3种方式
(1)继承Thread类
需要实现 run() 方法,并且最后也是调用 start() 方法来启动线程
(2)实现Runnable接口
实现 run() 方法。通过 Thread 调用 start() 方法来启动线程。
(3)实现Callable接口----使用ExecutorService、Callable、Future实现有返回结果的多线程
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
- 实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以说任务是通过线程驱动从而执行的。
实现接口 VS 继承 Thread
单继承,多实现。
实现接口会更好一些,因为:
Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
类可能只要求可执行即可,继承整个 Thread 类开销会过大。
1.2 Thread和Runable的区别和联系
(1)联系:
1、Thread类实现了Runable接口。
2、都需要重写里面Run方法。
(2)不同:
1、实现Runnable的类更具有健壮性,避免了单继承的局限。
2、Runnable更容易实现资源共享,能多个线程同时处理一个资源
1.线程的状态有哪些(生命周期) 线程中的方法有哪些?
状态5种
1.新建状态:使用 new 关键字和 Thread 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 start() 这个线程。
2.就绪状态:当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待JVM里线程调度器的调度。
3.运行状态:如果就绪状态的线程获取 CPU 资源,就可以执行 run(),此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
4.死亡状态:一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。
5.阻塞状态:如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。可以分为三种:
等待阻塞:运行状态中的线程执行 wait() 方法,使线程进入到等待阻塞状态。
同步阻塞:线程在获取 synchronized 同步锁失败(因为同步锁被其他线程占用)。
其他阻塞:通过调用线程的 sleep() 或 join() 发出了 I/O 请求时,线程就会进入到阻塞状态。当sleep() 状态超时,join() 等待线程终止或超时,或者 I/O 处理完毕,线程重新转入就绪状态。
-------------------------------------------------------
方法
start() 启动线程并执行相应的run()方法
run() 子线程要执行的代码放入run()方法
yield方法:使当前线程从执行状态变为就绪状态。
sleep方法:强制当前正在执行的线程休眠,当睡眠时间到期,则返回到可运行状态。 不会放弃锁资源
join方法:通常用于在main()主线程内,等待其它线程完成再结束main()主线程,不会放弃锁资源
deamon:守护线程(deamon)是程序运行时在后台提供服务的线程,并不属于程序中不可或缺的部分。
当所有非后台线程结束时,程序也就终止,同时会杀死所有后台线程。
main() 属于非后台线程。
使用 setDaemon() 方法将一个线程设置为后台线程。
2.sleep和wait的区别?
Thread.sleep() --方法进入休眠状态,不会放弃锁资源
wait() ---Object中方法。 会放弃锁资源 ,使线程挂起,直到线程得到 notify() 或 notifyAll() 消息(或者 java.util.concurrent 类库中等价的 signal() 或 signalAll() 消息;
3.线程安全
- 当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象是线程安全的。
线程不安全----当多个线程访问同一个资源出现问题。
3.如何解决线程安全问题?
- 互斥同步 悲观锁 synchronized 关键字
同步是指在多个线程并发访问共享数据时,保证共享数据在同一个时刻只被一个(或者是一些,使用信号量的时候)线程使用。synchronized jvm管理的 可以锁代码块,方法,类。必须上一个线程执行完才能执行下一个线程。
特点:同步方法 1.效率会变低
2.没有线程安全问题了
特点:同步代码块
1. 把业务代码 放在 同步代码块中
2. 该代码块中的代码在一个时间点只能被一个线程访问,其他线程需要排队等待
- 非阻塞同步 乐观锁实现
* 使用Lock的步骤:
* 1.创建Lock实现类的对象
* 2.使用Lock对象的lock方法加锁
* 3.使用Lock对象的unlock方法解锁
* 注意:可把unlock方法的调用放在finally代码块中,保证一定能解锁
Lock 乐观锁 线程安全 效率高
CAS compare and swap 取出来先比较
出现:ABA 问题 加一个版本比较 version
①创建ReentrantLock对象
②调用lock方法:加锁
{代码....}
③调用unlock方法:解锁
注意:可把解锁的unlock方法的调用放在finally{}代码块中,保证一定能解锁
4.synchronize悲观锁与lock乐观锁的区别?
-
同步方法 一个方法只有一个线程执行,必须上一个线程执行完才能执行下一个线程。
-
同步代码块 : synchronized(被加锁的对象){ 代码 }
RandomAccess
Vector 线程安全
在相对于ArrayList来说,Vector线程是安全的,也就是说是同步的。创建了一个向量类的对象后,可以往其中随意地插入不同的类的对象,既不需顾及类型也不需预先选定向量的容量,并可方便地进行查找。对于预先不知或不愿预先定义数组大小,并需频繁进行查找、插入和删除工作的情况,可以考虑使用向量类。向量类提供了三种构造方法:
public Vector()
public Vector(int initialcapacity,int capacityIncrement)
public Vector(int initialcapacity)
死锁
-
同步中嵌套同步,锁没有来得及释放,一直等待,就导致死锁。
-
如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
下面这段代码,多运行几次就会出现死锁,思路是开启两个线程,让这两个线程执行的代码获取的锁的顺序不同,第一个线程需要先获得obj对象锁,然后再获得this锁,才可以执行代码,然后释放两把锁。线程2需要先获得this锁,再获取obj对象锁才可执行代码,然后释放两把锁。但是,当线程1获得了obj锁之后,线程2获得了this锁,这时候线程1需要获得this锁才可执行,但是线程2也无法获取到obj对象锁执行代码并释放,所以两个线程都拿着一把锁不释放,这就产生了死锁。
多线程三大特性
原子性
原子性就是在执行一个或者多个操作的过程中,要么全部执行完不被任何因素打断,要么不执行。比如银行转账,A账户减去100元,B账户必须增加100元,对这两个账户的操作必须保证原子性,才不会出现问题。还有比如:i=i+1的操作,需要先取出i,然后对i进行+1操作,然后再给i赋值,这个式子就不是原子性的,需要同步来实现数据的安全。
原子性就是为了保证数据一致,线程安全。
----------------------
可见性
当多个线程访问同一个变量时,一个线程修改了变量的值,其他的线程能立即看到,这就是可见性。
这里讲一下Java内存模型?简称JMM,决定了一个线程与另一个线程是否可见,包括主内存(存放共享的全局变量)和私有本地内存(存放本地线程私有变量)
本地私有内存存放的是共享变量的副本,线程操作共享变量,首先操作的是自己本地内存的副本,当同一时刻只有一个线程操作共享变量时,该线程操作完毕本地内存,然后会刷新到主内存,然后主内存会通知另一个线程,进而更新;但是如果同一时刻有多个线程操作共享变量,会来不及更新主内存进而通知其他线程更新变量,就会出现冲突问题。
---------------
有序性
就是程序的执行顺序会按照代码先后顺序进行执行,一般情况下,处理器由于要提高执行效率,对代码进行重排序,运行的顺序可能和代码先后顺序不同,但是结果一样。单线程下不会出现问题,多线程就会出现问题了。
volatile
保证可见性,但是不保证原子性。
3.线程池
- 定义:线程池就是首先创建一些线程,它们的集合称为线程池。使用线程池可以很好地提高性能,线程池在系统启动时即创建大量空闲的线程,程序将一个任务传给线程池,线程池就会启动一条线程来执行这个任务,执行结束以后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个任务。
1.线程池的作用及原理
1.创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处理效率。(线程复用)
2.线程并发数量过多,抢占系统资源从而导致阻塞。(控制并发数量)
3.对线程进行一些简单的管理。(管理线程的生命周期)
线程池原理
1.线程复用:实现线程复用的原理应该就是要保持线程处于存活状态(就绪,运行或阻塞)
2.控制并发数量:(核心线程和最大线程数控制)
3.管理线程(设置线程的状态)
线程池的返回值ExecutorService简介
ExecutorService是Java提供的用于管理线程池的类。该类的两个作用:控制线程数量和重用线程
2.常见四种线程池
1.CachedThreadPool() 可缓存线程池
/**
根据源码可以看出:
这种线程池内部没有核心线程,线程的数量是有限制的 最大是Integer最大值。
在创建任务时,若有空闲的线程时则复用空闲的线程,若没有则新建线程。
没有工作的线程(闲置状态)在超过了60S还不做事,就会销毁。
适用:执行很多短期异步的小程序或者负载较轻的服务器。
*/
public class Test1 {
public static ExecutorService newCachedThreadPool (){
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue());
}
}
2.FixedThreadPool(int nThreads) 定长线程池
/**
根据源码可以看出:
该线程池的最大线程数等于核心线程数,所以在默认情况下,该线程池的线程不会因为闲置状态超时而被销毁。
如果当前线程数小于核心线程数,并且也有闲置线程的时候提交了任务,这时也不会去复用之前的闲置线程,会创建新的线程去执行任务。如果当前执行任务数大于了核心线程数,大于的部分就会进入队列等待。等着有闲置的线程来执行这个任务。
适用:执行长期的任务,性能好很多。
*/L
public class Test1 {
//传入线程长度写死
public static ExecutorService newFixedThreadPool (int nThreads){
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
}
}
3.SingleThreadPool() 单线程池
/**
根据源码可以看出:
该线程池的最大线程数等于核心线程数,所以在默认情况下,该线程池的线程不会因为闲置状态超时而被销毁。
如果当前线程数小于核心线程数,并且也有闲置线程的时候提交了任务,这时也不会去复用之前的闲置线程,会创建新的线程去执行任务。如果当前执行任务数大于了核心线程数,大于的部分就会进入队列等待。等着有闲置的线程来执行这个任务。
适用:执行长期的任务,性能好很多。
*/
public class Test1 {
//传入线程长度写死
public static ExecutorService newFixedThreadPool (){
return new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
}
}
4.ScheduledThreadPool() 弹性缓存线程池
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5FdQLdVt-1585889807457)(…/images/image-20191226165626552.png)]
根据源码可以看出:
DEFAULT_KEEPALIVE_MILLIS就是默认10L,这里就是10秒。这个线程池有点像是CachedThreadPool和FixedThreadPool 结合了一下。
不仅设置了核心线程数,最大线程数也是Integer.MAX_VALUE。
这个线程池是上述4个中唯一一个有延迟执行和周期执行任务的线程池。
适用:周期性执行任务的场景(定期的同步数据)
总结:除了new ScheduledThreadPool 的内部实现特殊一点之外,其它线程池内部都是基于ThreadPoolExecutor类(Executor的子类)实现的。
5.自定义线程池 ThreadPoolExecutor 类构造器语法形式
ThreadPoolExecutor(corePoolSize,maxPoolSize,keepAliveTime,timeUnit,workQueue,threadFactory,handle);
方法参数:
corePoolSize:核心线程数(最小存活的工作线程数量)
maxPoolSize:最大线程数
keepAliveTime:线程存活时间(在corePoreSize6.ThreadPoolExecutor常见的方法
execute()方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
submit()方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,实际上它还是调用的execute()方法,只不过它利用了Future来获取任务执行结果。
shutdown()不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务。
shutdownNow()立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务。
isTerminated()方法
调用ExecutorService.shutdown方法的时候,线程池不再接收任何新任务,但此时线程池并不会立刻退出,直到添加到线程池中的任务都已经处理完成,才会退出。在调用shutdown方法后我们可以在一个死循环里面用isTerminated方法判断是否线程池中的所有线程已经执行完毕,如果子线程都结束了,我们就可以做关闭流等后续操作了。
7.线程池中的最大线程数
一般说来,线程池的大小经验值应该这样设置:(其中N为CPU的个数)
如果是CPU密集型应用,则线程池大小设置为N+1
如果是IO密集型应用,则线程池大小设置为2N+1
如果一台服务器上只部署这一个应用并且只有这一个线程池,那么这种估算或许合理,具体还需自行测试验证。
但是,IO优化中,这样的估算公式可能更适合:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
因为很显然,线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
创建线程的个数是还要考虑 内存资源是否足够装下相当的线程
下面举个例子:
比如平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到:((0.5+1.5)/0.5)*8=32。
8.四种线程池拒绝策略
-
https://www.jianshu.com/p/a55da1c8bb93
-
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize时,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略:
1.ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
这是线程池默认的拒绝策略,在任务不能再提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。
2.ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃。使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略(博客网站统计阅读量就是采用的这种拒绝策略)。
3.ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务
此拒绝策略,是一种喜新厌旧的拒绝策略。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。
4.ThreadPoolExecutor.CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务
如果任务被拒绝了,则由调用线程(提交任务的线程)直接执行此任务,我们可以通过代码来验证这一点
---通过结果可以看到,主线程main也执行了任务,这正说明了此拒绝策略由调用线程(提交任务的线程)直接执行被丢弃的任务的。
4.JVM
- JVM是java虚拟机,在不同操作系统安装不同版本的jvm,来运行编译过后的字节码文件(.class)来实现跨平台原理。
为什么要优化?
- 采用默认的配置不见得能起到最好的效果,甚至可能会导致运行效率更差,又或者面临高并发情况下,想让程序平稳顺畅的运行,所以我们需要针对实际的需要来进行优化.
插件 VisualVM
现在安装插件,插件的安装属于VisualVM的一个重要功能,凭借插件我们可以将这个工具的功能变得更强大。
打开工具->插件
选择“可用插件”页
我们在这里安装一个Visual GC,方便我们看到内存回收以及各个分代的情况
打上勾之后点击安装,就是常规的next以及同意协议等
网络不是很稳定,有时候可能需要多尝试几次。
安装完成后我们将当前监控页关掉,再次打开,就可以看到Profiler后面多了一个Visual GC页。
- 另外,如果开发工具使用的是Intellij IDEA的话,可以下载一个插件,VisualVM Launcher,通过插件启动可以直接到上述页面,不用在左边的条目中寻找自己的项目.
1.JVM组成
- 每一个Java虚拟机都由一个类加载器子系统(class loader subsystem),负责加载程序中的类型(类和接口),并赋予唯一的名字。每一个Java虚拟机都有一个执行引擎(execution engine)负责执行被加载类中包含的指令。JVM的两种类装载器包括:启动类装载器和用户自定义类装载器,启动类装载器是JVM实现的一部分,用户自定义类装载器则是Java程序的一部分,必须是ClassLoader类的子类。
1.类加载器子系统
2.运行时数据区
方法区 堆 虚拟机栈 本地方法栈 程序计数器
3.执行引擎
4.本地方法库
而本地库接口也就是用于调用本地方法的接口,在此我们不细说,主要关注的是上述的4个组件
2.类加载器子系统执行过程
加载,验证,准备,解析和初始化这5个步骤.
1.加载:找到字节码文件,读取到内存中.类的加载方式分为隐式加载和显示加载两种。隐式加载指的是程序在使用new关键词创建对象时,会调用类的加载器把对应的类加载到jvm中。显示加载指的是通过直接调用class.forName()方法来把所需的类加载到jvm中。(将字节码加载到内存中)
2.验证:验证此字节码文件是不是真的是一个字节码文件,毕竟后缀名可以随便改,而内在的身份标识是不会变的.在确认是一个字节码文件后,还会检查一系列的是否可运行验证,元数据验证,字节码验证,符号引用验证等.Java虚拟机规范对此要求很严格,在Java 7的规范中,已经有130页的描述验证过程的内容.
3.准备:为类中static修饰的变量分配内存空间并设置其初始值为0或null.可能会有人感觉奇怪,在类中定义一个static修饰的int,并赋值了123,为什么这里还是赋值0.因为这个int的123是在初始化阶段的时候才赋值的,这里只是先把内存分配好.但如果你的static修饰还加上了final,那么就会在准备阶段就会赋值.
4.解析:解析阶段会将java代码中的符号引用替换为直接引用.比如引用的是一个类,我们在代码中只有全限定名来标识它,在这个阶段会找到这个类加载到内存中的地址.
5.初始化:如刚才准备阶段所说的,这个阶段就是对变量的赋值的阶段.
原文链接:https://blog.csdn.net/qq_41701956/article/details/80020103
一、JVM将整个类加载过程划分为了三个步骤:
(1)装载(加载)
装载过程负责找到二进制字节码并加载至JVM中,JVM通过类名、类所在的包名通过ClassLoader来完成类的加载,同样,也采用以上三个元素来标识一个被加载了的类:类名+包名+ClassLoader实例ID,因此不同类加载器加载相同的类是不同的。有继承,将先在加载父类。
将类.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区中的数据结构
(2)链接
链接过程负责对二进制字节码的格式进行:校验、解析类中调用的接口、类。校验是防止不合法的.class文件,然后 对类中的所有属性、调用方法进行解析,以确保其需要调用的属性、方法存在,以及具备应的权限(例如public、private域权限等),会造成NoSuchMethodError、NoSuchFieldError等错误信息。
连接:
a、验证:确保被加载的类的正确性
b、准备:为类的静态变量分配内存,并将其初始化为默认值
c、解析: 把类中的符号引用转化为直接引用
(3)初始化
初始化过程即为执行类中的静态初始化代码、构造器代码以及静态属性的初始化。
在四种情况下初始化过程会被触发执行:
调用了new;
反射调用了类中的方法;
子类调用了初始化(先执行父类静态代码和静态成员,再执行子类静态代码和静态变量,然后调用父类构造器,最后调用自身构造器。);
JVM启动过程中指定的初始化类。
3.双亲委派机制
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gGFVXnmP-1585889807459)(…/images/image-20191226184500324.png)]
类加载器一般有4种,其中前3种是必然存在的
1.启动类加载器:加载\lib下的 C++实现的
2.扩展类加载器:加载\lib\ext下的 JVM用此classloader来加载扩展功能的一些jar包
3.应用程序类加载器: 加载Classpath下的
4.自定义类加载器
而双亲委派机制是如何运作的呢?
我们以应用程序类加载器举例,它在需要加载一个类的时候,不会直接去尝试加载,而是委托上级的扩展类加载器去加载,而扩展类加载器也是委托启动类加载器去加载.
启动类加载器在自己的搜索范围内没有找到这么一个类,表示自己无法加载,就再让扩展类加载器去加载,同样的,扩展类加载器在自己的搜索范围内找一遍,如果还是没有找到,就委托应用程序类加载器去加载.如果最终还是没找到,那就会直接抛出异常了.
而为什么要这么麻烦的从下到上,再从上到下呢?
这是为了安全着想,保证按照优先级加载.如果用户自己编写一个名为java.lang.Object的类,放到自己的Classpath中,没有这种优先级保证,应用程序类加载器就把这个当做Object加载到了内存中,从而会引发一片混乱.而凭借这种双亲委派机制,先一路向上委托,启动类加载器去找的时候,就把正确的Object加载到了内存中,后面再加载自行编写的Object的时候,是不会加载运行的.
-
注意:
1、所有的类加载器都继承与ClassLoader类。并且BootstrapClassLoader、ExtClassLoader、AppClassLoader继承于Java.net.URLClassLoader,可以从本地和网上下载字节码。URLClassLoader继承ClassLoader。;
2、BootstrapClassLoader是最先加载的,它然后依次加载出ExtClassLoader、AppClassLoader对象。
4.运行时数据区
- 运行时数据区分为 虚拟机栈, 本地方法栈, 堆区, 方法区 和 程序计数器.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FNgKMca2-1585889807460)(…/images/image-20191226185003740.png)]
- 1.方法区域(Method Area)
博客
在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代。
方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
------------------
方法区主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据。在jdk1.7及其之前,方法区是堆的一个“逻辑部分”(一片连续的堆空间),但为了与堆做区分,方法区还有个名字叫“非堆”,也有人用“永久代”(HotSpot对方法区的实现方法)来表示方法区。
从jdk1.7已经开始准备“去永久代”的规划,jdk1.7的HotSpot中,已经把原本放在方法区中的静态变量、字符串常量池等移到堆内存中,(常量池除字符串常量池还有class常量池等),这里只是把字符串常量池移到堆内存中;在jdk1.8中,方法区已经不存在,原方法区中存储的类信息、编译后的代码数据等已经移动到了元空间(MetaSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory)。
去永久代的原因:
(1)字符串存在永久代中,容易出现性能问题和内存溢出。
(2)类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
(3)永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
gc garbage collection
- 2.堆(Heap)
博客
它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中的对象的内存需要等待GC进行回收。
堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的。
Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer),其大小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配,在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配。
TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
--------------------------
堆和方法区一样(确切来说JVM规范中方法区就是堆的一个逻辑分区),就是一个所有线程共享的,存放对象的区域,也是GC的主要区域.其中的分区分为新生代,老年代.新生代中又可以细分为一个Eden,两个Survivor区(From,To).Eden中存放的是通过new 或者newInstance方法创建出来的对象,绝大多数都是很短命的.正常情况下经历一次gc之后,存活的对象会转入到其中一个Survivor区,然后再经历默认15次的gc,就转入到老年代.这是常规状态下,在Survivor区已经满了的情况下,JVM会依据担保机制将一些对象直接放入老年代。
堆内存主要用于存放对象和数组,它是JVM管理的内存中最大的一块区域,堆内存和方法区都被所有线程共享,在虚拟机启动时创建。在垃圾收集的层面上来看,由于现在收集器基本上都采用分代收集算法,因此堆还可以分为新生代(YoungGeneration)和老年代(OldGeneration),新生代还可以分为Eden、From Survivor、To Survivor
- 3.JavaStack(java的栈):虚拟机只会直接对Javastack执行两种操作:以帧为单位的压栈或出栈
博客
每个帧代表一个方法,Java方法有两种返回方式,return和抛出异常,两种方式都会导致该方法对应的帧出栈和释放内存。
帧的组成:局部变量区(包括方法参数和局部变量,对于instance方法,还要首先保存this类型,其中方法参数按照声明顺序严格放置,局部变量可以任意放置),操作数栈,帧数据区(用来帮助支持常量池的解析,正常方法返回和异常处理)。
-------------------------
本地方法栈与虚拟机栈的区别是,虚拟机栈执行的是Java方法,本地方法栈执行的是本地方法(Native Method),其他基本上一致,在HotSpot中直接把本地方法栈和虚拟机栈合二为一,这里暂时不做过多叙述。
https://xiaomogui.iteye.com/blog/857821
- 4.ProgramCounter(程序计数器)
博客
每一个线程都有它自己的PC寄存器,也是该线程启动时创建的。PC寄存器的内容总是指向下一条将被执行指令的饿地址,这里的地址可以是一个本地指针,也可以是在方法区中相对应于该方法起始指令的偏移量。
若thread执行Java方法,则PC保存下一条执行指令的地址。若thread执行native方法,则Pc的值为undefined
----------------------------
程序计数器是线程私有的,虽然名字叫计数器,但主要用途还是用来确定指令的执行顺序,比如循环,分支,跳转,异常捕获等.而JVM对于多线程的实现是通过轮流切换线程实现的,所以为了保证每个线程都能按正确顺序执行,将程序计数器作为线程私有.程序计数器是唯一一个JVM没有规定任何OOM的区块.
oom out of memory
程序计数器是一块非常小的内存空间,可以看做是当前线程执行字节码的行号指示器,每个线程都有一个独立的程序计数器,因此程序计数器是线程私有的一块空间,此外,程序计数器是Java虚拟机规定的唯一不会发生内存溢出的区域。
- 5.Nativemethodstack(本地方法栈):保存native方法进入区域的地址
博客
依赖于本地方法的实现,如某个JVM实现的本地方法借口使用C连接模型,则本地方法栈就是C栈,可以说某线程在调用本地方法时,就进入了一个不受JVM限制的领域,也就是JVM可以利用本地方法来动态扩展本身。
---------------
本地方法栈与虚拟机栈的区别是,虚拟机栈执行的是Java方法,本地方法栈执行的是本地方法(Native Method),其他基本上一致,在HotSpot中直接把本地方法栈和虚拟机栈合二为一,这里暂时不做过多叙述。
https://xiaomogui.iteye.com/blog/857821
5.堆区域是怎么划分的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BpiuRu5k-1585889807464)(…/images/image-20191226191137526.png)]
- Java虚拟机将堆内存划分为新生代、老年代和永久代。
- 永久代是HotSpot虚拟机特有的概念(JDK1.8之后为metaspace替代永久代),它采用永久代的方式来实现方法区,其他的虚拟机实现没有这一概念,而且HotSpot也有取消永久代的趋势.
- 在JDK 1.7中HotSpot已经开始了“去永久化”,把原本放在永久代的字符串常量池移出。永久代主要存放常量、类信息、静态变量等数据,与垃圾回收关系不大,新生代和老年代是垃圾回收的主要区域。
博客
1、堆结构分代的意义
Java虚拟机根据对象存活的周期不同,把堆内存划分为几块,一般分为新生代、老年代和永久代(对HotSpot虚拟机而言),这就是JVM的内存分代策略。
堆内存是虚拟机管理的内存中最大的一块,也是垃圾回收最频繁的一块区域,我们程序所有的对象实例都存放在堆内存中。给堆内存分代是为了提高对象内存分配和垃圾回收的效率。试想一下,如果堆内存没有区域划分,所有的新创建的对象和生命周期很长的对象放在一起,随着程序的执行,堆内存需要频繁进行垃圾收集,而每次回收都要遍历所有的对象,遍历这些对象所花费的时间代价是巨大的,会严重影响我们的GC效率。
有了内存分代,情况就不同了,新创建的对象会在新生代中分配内存,经过多次回收仍然存活下来的对象存放在老年代中,静态属性、类信息等存放在永久代中,新生代中的对象存活时间短,只需要在新生代区域中频繁进行GC,老年代中对象生命周期长,内存回收的频率相对较低,不需要频繁进行回收,永久代中回收效果太差,一般不进行垃圾回收,还可以根据不同年代的特点采用合适的垃圾收集算法。分代收集大大提升了收集效率,这些都是内存分代带来的好处。
2、堆结构分代
Java虚拟机将堆内存划分为新生代、老年代和永久代,永久代是HotSpot虚拟机特有的概念(JDK1.8之后为metaspace替代永久代),它采用永久代的方式来实现方法区,其他的虚拟机实现没有这一概念,而且HotSpot也有取消永久代的趋势,在JDK 1.7中HotSpot已经开始了“去永久化”,把原本放在永久代的字符串常量池移出。永久代主要存放常量、类信息、静态变量等数据,与垃圾回收关系不大,新生代和老年代是垃圾回收的主要区域。
3.新生代(Young Generation)
新生成的对象优先存放在新生代中,新生代对象朝生夕死,存活率很低,在新生代中,常规应用进行一次垃圾收集一般可以回收70% ~ 95% 的空间,回收效率很高。
HotSpot将新生代划分为三块,一块较大的Eden(伊甸)空间和两块较小的Survivor(幸存者)空间,默认比例为8:1:1。划分的目的是因为HotSpot采用复制算法来回收新生代,设置这个比例是为了充分利用内存空间,减少浪费。新生成的对象在Eden区分配(大对象除外,大对象直接进入老年代),当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC。
GC开始时,对象只会存在于Eden区和From Survivor区,To Survivor区是空的(作为保留区域)。GC进行时,Eden区中所有存活的对象都会被复制到To Survivor区,而在From Survivor区中,仍存活的对象会根据它们的年龄值决定去向,年龄值达到年龄阀值(默认为15,新生代中的对象每熬过一轮垃圾回收,年龄值就加1,GC分代年龄存储在对象的header中)的对象会被移到老年代中,没有达到阀值的对象会被复制到To Survivor区。接着清空Eden区和From Survivor区,新生代中存活的对象都在To Survivor区。接着, From Survivor区和To Survivor区会交换它们的角色,也就是新的To Survivor区就是上次GC清空的From Survivor区,新的From Survivor区就是上次GC的To Survivor区,总之,不管怎样都会保证To Survivor区在一轮GC后是空的。GC时当To Survivor区没有足够的空间存放上一次新生代收集下来的存活对象时,需要依赖老年代进行分配担保,将这些对象存放在老年代中。
4、老年代(Old Generationn)
在新生代中经历了多次(具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年代中。老年代中的对象生命周期较长,存活率比较高,在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢。
5、永久代(Permanent Generationn)
永久代存储类信息、常量、静态变量、即时编译器编译后的代码等数据,对这一区域而言,Java虚拟机规范指出可以不进行垃圾收集,一般而言不会进行垃圾回收。
三、永久代和方法区
1、方法区
方法区(Method Area)是jvm规范里面的运行时数据区的一个组成部分,jvm规范中的运行时数据区还包含了:pc寄存器、虚拟机栈、堆、方法区、运行时常量池、本地方法栈。主要用来存储class、运行时常量池、字段、方法、代码、JIT代码等。运行时数据区跟内存不是一个概念,方法区是运行时数据区的一部分。方法区是jvm规范中的一部分,并不是实际的实现,切忌将规范跟实现混为一谈。
2、永久代
永久带又叫Perm区,只存在于hotspot jvm中,并且只存在于jdk7和之前的版本中,jdk8中已经彻底移除了永久带,jdk8中引入了一个新的内存区域叫metaspace。并不是所有的jvm中都有永久带,ibm的j9,oracle的JRocket都没有永久带,永久带是实现层面的东西,永久带里面存的东西基本上就是方法区规定的那些东西。
3、区别
方法区是规范层面的东西,规定了这一个区域要存放哪些东西,永久带或者是metaspace是对方法区的不同实现,是实现层面的东西。
4、hotspot jdk8中移除了永久带以后的内存结构
6.元空间
上面说到,jdk1.8中,已经不存在永久代(方法区),替代它的一块空间叫做“元空间”,和永久代类似,都是JVM规范对方法区的实现,但是元空间并不在虚拟机中,而是使用本地内存,元空间的大小仅受本地内存限制,但可以通过-XX:MetaspaceSize和-XX:MaxMetaspaceSize来指定元空间的大小
7.执行引擎
- 执行引擎包含即时编译器(JIT)和垃圾回收器(GC),对即时编译器我们简单介绍一下,主要重点在于垃圾回收器.
8.JVM垃圾回收
垃圾回收,就是通过垃圾收集器把内存中没用的对象清理掉。
垃圾回收涉及到的内容有:
1、判断对象是否已死; 是否为垃圾
2、选择垃圾收集算法;
3、选择垃圾收集的时间;
4、选择适当的垃圾收集器清理垃圾(已死的对象)。
-
判断对象是否已死
-
- 判断对象是否已死有–引用计数算法和可达性分析算法
(1)引用计数算法
给每一个对象添加一个引用计数器,每当有一个地方引用它时,计数器值加1;每当有一个地方不再引用它时,计数器值减1,这样只要计数器的值不为0,就说明还有地方引用它,它就不是无用的对象。如下图,对象2有1个引用,它的引用计数器值为1,对象1有两个地方引用,它的引用计数器值为2 。
(2)可达性分析算法
了解可达性分析算法之前先了解一个概念——GC Roots,垃圾收集的起点,可以作为GC Roots的有虚拟机栈中本地变量表中引用的对象、方法区中静态属性引用的对象、方法区中常量引用的对象、本地方法栈中JNI(Native方法)引用的对象。
当一个对象到GC Roots没有任何引用链相连(GC Roots到这个对象不可达)时,就说明此对象是不可用的,是死对象。如下图:object1、object2、object3、object4和GC Roots之间有可达路径,这些对象不会被回收,但object5、object6、object7到GC Roots之间没有可达路径,这些对象就被判了死刑。
上面被判了死刑的对象(object5、object6、object7)并不是必死无疑,还有挽救的余地。进行可达性分析后对象和GC Roots之间没有引用链相连时,对象将会被进行一次标记,接着会判断如果对象没有覆盖Object的finalize()方法或者finalize()方法已经被虚拟机调用过,那么它们就会被行刑(清除);如果对象覆盖了finalize()方法且还没有被调用,则会执行finalize()方法中的内容,所以在finalize()方法中如果重新与GC Roots引用链上的对象关联就可以拯救自己,但是一般不建议这么做.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uGIH7Paa-1585889807469)(…/images/image-20191226194751598.png)]
(3)方法区回收
上面说的都是对堆内存中对象的判断,方法区中主要回收的是废弃的常量和无用的类。
判断常量是否废弃可以判断是否有地方引用这个常量,如果没有引用则为废弃的常量。
判断类是否废弃需要同时满足如下条件:
该类所有的实例已经被回收(堆中不存在任何该类的实例)
加载该类的ClassLoader已经被回收
该类对应的java.lang.Class对象在任何地方没有被引用(无法通过反射访问该类的方法)
9.常用垃圾回收算法
- 常用的垃圾回收算法有三种:标记-清除算法、复制算法、标记-整理算法。
(1)标记-清除算法:分为标记和清除两个阶段,首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。
缺点:标记和清除两个过程效率都不高;标记清除之后会产生大量不连续的内存碎片。
(2)复制算法:把内存分为大小相等的两块,每次存储只用其中一块,当这一块用完了,就把存活的对象全部复制到另一块上,同时把使用过的这块内存空间全部清理掉,往复循环。
缺点:实际可使用的内存空间缩小为原来的一半,比较适合
(3)标记-整理算法:先对可用的对象进行标记,然后所有被标记的对象向一段移动,最后清除可用对象边界以外的内存。
(4)分代收集算法:把堆内存分为新生代和老年代,新生代又分为Eden区、From Survivor和To Survivor。一般新生代中的对象基本上都是朝生夕灭的,每次只有少量对象存活,因此采用复制算法,只需要复制那些少量存活的对象就可以完成垃圾收集;老年代中的对象存活率较高,就采用标记-清除和标记-整理算法来进行回收。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aWoZf6l7-1585889807471)(…/images/image-20191226195521853.png)]
在这些区域的垃圾回收大概有如下几种情况:
新生代使用时minor gc 老年代使用的full gc 同时会触发一minor gc
大多数情况下,新的对象都分配在Eden区,当Eden区没有空间进行分配时,将进行一次Minor GC,清理Eden区中的无用对象。清理后,Eden和From Survivor中的存活对象如果小于To Survivor的可用空间则进入To Survivor,否则直接进入老年代);Eden和From Survivor中还存活且能够进入To Survivor的对象年龄增加1岁(虚拟机为每个对象定义了一个年龄计数器,每执行一次Minor GC年龄加1),当存活对象的年龄到达一定程度(默认15岁)后进入老年代,可以通过-XX:MaxTenuringThreshold来设置年龄的值。
当进行了Minor GC后,Eden还不足以为新对象分配空间(那这个新对象肯定很大),新对象直接进入老年代。
占To Survivor空间一半以上且年龄相等的对象,大于等于该年龄的对象直接进入老年代,比如Survivor空间是10M,有几个年龄为4的对象占用总空间已经超过5M,则年龄大于等于4的对象都直接进入老年代,不需要等到MaxTenuringThreshold指定的岁数。
在进行Minor GC之前,会判断老年代最大连续可用空间是否大于新生代所有对象总空间,如果大于,说明Minor GC是安全的,否则会判断是否允许担保失败,如果允许,判断老年代最大连续可用空间是否大于历次晋升到老年代的对象的平均大小,如果大于,则执行Minor GC,否则执行Full GC。
当在java代码里直接调用System.gc()时,会建议JVM进行Full GC,但一般情况下都会触发Full GC,一般不建议使用,尽量让虚拟机自己管理GC的策略。
永久代(方法区)中用于存放类信息,jdk1.6及之前的版本永久代中还存储常量、静态变量等,当永久代的空间不足时,也会触发Full GC,如果经过Full GC还无法满足永久代存放新数据的需求,就会抛出永久代的内存溢出异常。
大对象(需要大量连续内存的对象)例如很长的数组,会直接进入老年代,如果老年代没有足够的连续大空间来存放,则会进行Full GC。
Minor GC和Full GC
在说这两种回收的区别之前,我们先来说一个概念,“Stop-The-World”。
如字面意思,每次垃圾回收的时候,都会将整个JVM暂停,回收完成后再继续。如果一边增加废弃对象,一边进行垃圾回收,完成工作似乎就变得遥遥无期了。
而一般来说,我们把新生代的回收称为Minor GC,Minor意思是次要的,新生代的回收一般回收很快,采用复制算法,造成的暂停时间很短。而Full GC一般是老年代的回收,并伴随至少一次的Minor GC,新生代和老年代都回收,而老年代采用标记-整理算法,这种GC每次都比较慢,造成的暂停时间比较长,通常是Minor GC时间的10倍以上。
所以很明显,我们需要尽量通过Minor GC来回收内存,而尽量少的触发Full GC。毕竟系统运行一会儿就要因为GC卡住一段时间,再加上其他的同步阻塞,整个系统给人的感觉就是又卡又慢。
选择垃圾收集的时间
当程序运行时,各种数据、对象、线程、内存等都时刻在发生变化,当下达垃圾收集命令后就立刻进行收集吗?肯定不是。这里来了解两个概念:安全点(safepoint)和安全区(safe region)。
安全点:从线程角度看,安全点可以理解为是在代码执行过程中的一些特殊位置,当线程执行到安全点的时候,说明虚拟机当前的状态是安全的,如果有需要,可以在这里暂停用户线程。当垃圾收集时,如果需要暂停当前的用户线程,但用户线程当时没在安全点上,则应该等待这些线程执行到安全点再暂停。举个例子,妈妈在扫地,儿子在吃西瓜(瓜皮会扔到地上),妈妈扫到儿子跟前时,儿子说:“妈妈等一下,让我吃完这块再扫。”儿子吃完这块西瓜把瓜皮扔到地上后就是一个安全点,妈妈可以继续扫地(垃圾收集器可以继续收集垃圾)。理论上,解释器的每条字节码的边界上都可以放一个安全点,实际上,安全点基本上以“是否具有让程序长时间执行的特征”为标准进行选定。
安全区:安全点是相对于运行中的线程来说的,对于如sleep或blocked等状态的线程,收集器不会等待这些线程被分配CPU时间,这时候只要线程处于安全区中,就可以算是安全的。安全区就是在一段代码片段中,引用关系不会发生变化,可以看作是被扩展、拉长了的安全点。还以上面的例子说明,妈妈在扫地,儿子在吃西瓜(瓜皮会扔到地上),妈妈扫到儿子跟前时,儿子说:“妈妈你继续扫地吧,我还得吃10分钟呢!”儿子吃瓜的这段时间就是安全区,妈妈可以继续扫地(垃圾收集器可以继续收集垃圾)。
GC的基本原理
GC的基本原理:将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停
(1)对新生代的对象的收集称为minor GC;
(2)对旧生代的对象的收集称为Full GC;
(3)程序中主动调用System.gc()强制执行的GC为Full GC。
不同的对象引用类型, GC会采用不同的方法进行回收,JVM对象的引用分为了四种类型:
(1)强引用:默认情况下,对象采用的均为强引用(这个对象的实例没有其他对象引用,GC时才会被回收)
(2)软引用:软引用是Java中提供的一种比较适合于缓存场景的应用(只有在内存不够用的情况下才会被GC)
(3)弱引用:在GC时一定会被GC回收
(4)虚引用:由于虚引用只是用来得知对象是否被GC
Young(年轻代)
年轻代分三个区。一个Eden区,两个Survivor区。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制年老区(Tenured。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。
Tenured(年老代)
年老代存放从年轻代存活的对象。一般来说年老代存放的都是生命期较长的对象。
Perm(持久代)
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=进行设置。
————————————————
版权声明:本文为CSDN博主「Java程序员-张凯」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41701956/article/details/80020103
10.常见垃圾收集器
现在常见的垃圾收集器有如下几种
新生代收集器:Serial、ParNew、Parallel Scavenge
老年代收集器:Serial Old、CMS、Parallel Old
堆内存垃圾收集器:G1
每种垃圾收集器之间有连线,表示他们可以搭配使用。
(1) Serial 收集器
Serial是一款用于新生代的单线程收集器,采用复制算法进行垃圾收集。Serial进行垃圾收集时,不仅只用一条线程执行垃圾收集工作,它在收集的同时,所有的用户线程必须暂停(Stop The World)。就比如妈妈在家打扫卫生的时候,肯定不会边打扫边让儿子往地上乱扔纸屑,否则一边制造垃圾,一遍清理垃圾,这活啥时候也干不完。
如下是Serial收集器和Serial Old收集器结合进行垃圾收集的示意图,当用户线程都执行到安全点时,所有线程暂停执行,Serial收集器以单线程,采用复制算法进行垃圾收集工作,收集完之后,用户线程继续开始执行。
适用场景:Client模式(桌面应用);单核服务器。可以用-XX:+UserSerialGC来选择Serial作为新生代收集器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bne119TX-1585889807473)(…/images/image-20191226220108376.png)]
(2) ParNew 收集器
ParNew就是一个Serial的多线程版本,其它与Serial并无区别。ParNew在单核CPU环境并不会比Serial收集器达到更好的效果,它默认开启的收集线程数和CPU数量一致,可以通过-XX:ParallelGCThreads来设置垃圾收集的线程数。
如下是ParNew收集器和Serial Old收集器结合进行垃圾收集的示意图,当用户线程都执行到安全点时,所有线程暂停执行,ParNew收集器以多线程,采用复制算法进行垃圾收集工作,收集完之后,用户线程继续开始执行。
适用场景:多核服务器;与CMS收集器搭配使用。当使用-XX:+UserConcMarkSweepGC来选择CMS作为老年代收集器时,新生代收集器默认就是ParNew,也可以用-XX:+UseParNewGC来指定使用ParNew作为新生代收集器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NhF1dSNc-1585889807475)(…/images/image-20191226220020011.png)]
(3) Parallel Scavenge 收集器
Parallel Scavenge也是一款用于新生代的多线程收集器,与ParNew的不同之处是,ParNew的目标是尽可能缩短垃圾收集时用户线程的停顿时间,Parallel Scavenge的目标是达到一个可控制的吞吐量。吞吐量就是CPU执行用户线程的的时间与CPU执行总时间的比值【吞吐量=运行用户代代码时间/(运行用户代码时间+垃圾收集时间)】,比如虚拟机一共运行了100分钟,其中垃圾收集花费了1分钟,那吞吐量就是99% 。比如下面两个场景,垃圾收集器每100秒收集一次,每次停顿10秒,和垃圾收集器每50秒收集一次,每次停顿时间7秒,虽然后者每次停顿时间变短了,但是总体吞吐量变低了,CPU总体利用率变低了。
可以通过-XX:MaxGCPauseMillis来设置收集器尽可能在多长时间内完成内存回收,可以通过-XX:GCTimeRatio来精确控制吞吐量。
如下是Parallel收集器和Parallel Old收集器结合进行垃圾收集的示意图,在新生代,当用户线程都执行到安全点时,所有线程暂停执行,ParNew收集器以多线程,采用复制算法进行垃圾收集工作,收集完之后,用户线程继续开始执行;在老年代,当用户线程都执行到安全点时,所有线程暂停执行,Parallel Old收集器以多线程,采用标记整理算法进行垃圾收集工作。
适用场景:注重吞吐量,高效利用CPU,需要高效运算且不需要太多交互。可以使用-XX:+UseParallelGC来选择Parallel Scavenge作为新生代收集器,jdk7、jdk8默认使用Parallel Scavenge作为新生代收集器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fUBTdDZ6-1585889807480)(…/images/image-20191226220947472.png)]
(4) Serial Old收集器
- Serial Old收集器是Serial的老年代版本,同样是一个单线程收集器,采用标记-整理算法。
如下图是Serial收集器和Serial Old收集器结合进行垃圾收集的示意图:
适用场景:Client模式(桌面应用);单核服务器;与Parallel Scavenge收集器搭配;作为CMS收集器的后备预案。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n3jKQNe6-1585889807482)(…/images/wps1.jpg)]
(5) CMS(Concurrent Mark Sweep) 收集器
CMS收集器是一种以最短回收停顿时间为目标的收集器,以“最短用户线程停顿时间”著称。整个垃圾收集过程分为4个步骤
① 初始标记:标记一下GC Roots能直接关联到的对象,速度较快
② 并发标记:进行GC Roots Tracing,标记出全部的垃圾对象,耗时较长
③ 重新标记:修正并发标记阶段引用户程序继续运行而导致变化的对象的标记记录,耗时较短
④ 并发清除:用标记-清除算法清除垃圾对象,耗时较长
整个过程耗时最长的并发标记和并发清除都是和用户线程一起工作,所以从总体上来说,CMS收集器垃圾收集可以看做是和用户线程并发执行的。
CMS收集器也存在一些缺点:
对CPU资源敏感:默认分配的垃圾收集线程数为(CPU数+3)/4,随着CPU数量下降,占用CPU资源越多,吞吐量越小
无法处理浮动垃圾:在并发清理阶段,由于用户线程还在运行,还会不断产生新的垃圾,CMS收集器无法在当次收集中清除这部分垃圾。同时由于在垃圾收集阶段用户线程也在并发执行,CMS收集器不能像其他收集器那样等老年代被填满时再进行收集,需要预留一部分空间提供用户线程运行使用。当CMS运行时,预留的内存空间无法满足用户线程的需要,就会出现“Concurrent Mode Failure”的错误,这时将会启动后备预案,临时用Serial Old来重新进行老年代的垃圾收集。
因为CMS是基于标记-清除算法,所以垃圾回收后会产生空间碎片,可以通过-XX:UserCMSCompactAtFullCollection开启碎片整理(默认开启),在CMS进行Full GC之前,会进行内存碎片的整理。还可以用-XX:CMSFullGCsBeforeCompaction设置执行多少次不压缩(不进行碎片整理)的Full GC之后,跟着来一次带压缩(碎片整理)的Full GC。
适用场景:重视服务器响应速度,要求系统停顿时间最短。可以使用-XX:+UserConMarkSweepGC来选择CMS作为老年代收集器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1egCi95O-1585889807486)(…/images/image-20191226221155056.png)]
(1) Parallel Old 收集器
Parallel Old收集器是Parallel Scavenge的老年代版本,是一个多线程收集器,采用标记-整理算法。可以与Parallel Scavenge收集器搭配,可以充分利用多核CPU的计算能力。
适用场景:与Parallel Scavenge收集器搭配使用;注重吞吐量。jdk7、jdk8默认使用该收集器作为老年代收集器,使用 -XX:+UseParallelOldGC来指定使用Paralle Old收集器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6PlP5Z6-1585889807488)(…/images/image-20191226221242279.png)]
(7) G1 收集器
G1 收集器是jdk1.7才正式引用的商用收集器,现在已经成为jdk1.9默认的收集器。前面几款收集器收集的范围都是新生代或者老年代,G1进行垃圾收集的范围是整个堆内存,它采用“化整为零”的思路,把整个堆内存划分为多个大小相等的独立区域(Region),在G1收集器中还保留着新生代和老年代的概念,它们分别都是一部分Region,如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kbZ5ETMA-1585889807491)(…/images/image-20191226221339905.png)]
每一个方块就是一个区域,每个区域可能是Eden、Survivor、老年代,每种区域的数量也不一定。JVM启动时会自动设置每个区域的大小(1M~32M,必须是2的次幂),最多可以设置2048个区域(即支持的最大堆内存为32M*2048=64G),假如设置-Xmx8g -Xms8g,则每个区域大小为8g/2048=4M。
为了在GC Roots Tracing的时候避免扫描全堆,在每个Region中,都有一个Remembered Set来实时记录该区域内的引用类型数据与其他区域数据的引用关系(在前面的几款分代收集中,新生代、老年代中也有一个Remembered Set来实时记录与其他区域的引用关系),在标记时直接参考这些引用关系就可以知道这些对象是否应该被清除,而不用扫描全堆的数据。
G1收集器可以“建立可预测的停顿时间模型”,它维护了一个列表用于记录每个Region回收的价值大小(回收后获得的空间大小以及回收所需时间的经验值),这样可以保证G1收集器在有限的时间内可以获得最大的回收效率。
如下图所示,G1收集器收集器收集过程有初始标记、并发标记、最终标记、筛选回收,和CMS收集器前几步的收集过程很相似:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NpYG6a3b-1585889807492)(…/images/image-20191226221347747.png)]
① 初始标记:标记出GC Roots直接关联的对象,这个阶段速度较快,需要停止用户线程,单线程执行
② 并发标记:从GC Root开始对堆中的对象进行可达新分析,找出存活对象,这个阶段耗时较长,但可以和用户线程并发执行
③ 最终标记:修正在并发标记阶段引用户程序执行而产生变动的标记记录
④ 筛选回收:筛选回收阶段会对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来指定回收计划(用最少的时间来回收包含垃圾最多的区域,这就是Garbage First的由来——第一时间清理垃圾最多的区块),这里为了提高回收效率,并没有采用和用户线程并发执行的方式,而是停顿用户线程。
适用场景:要求尽可能可控GC停顿时间;内存占用较大的应用。可以用-XX:+UseG1GC使用G1收集器,jdk9默认使用G1收集器。
5.JVM的优化
https://www.cnblogs.com/zzuli/p/9403928.html
JVM调优目标:使用较小的内存占用来获得较高的吞吐量或者较低的延迟。
程序在上线前的测试或运行中有时会出现一些大大小小的JVM问题,比如cpu load过高、请求延迟、tps降低等,甚至出现内存泄漏(每次垃圾收集使用的时间越来越长,垃圾收集频率越来越高,每次垃圾收集清理掉的垃圾数据越来越少)、内存溢出导致系统崩溃,因此需要对JVM进行调优,使得程序在正常运行的前提下,获得更高的用户体验和运行效率。
这里有几个比较重要的指标:
内存占用:程序正常运行需要的内存大小。
延迟:由于垃圾收集而引起的程序停顿时间。
吞吐量:用户程序运行时间占用户程序和垃圾收集占用总时间的比值。
当然,和CAP原则一样,同时满足一个程序内存占用小、延迟低、高吞吐量是不可能的,程序的目标不同,调优时所考虑的方向也不同,在调优之前,必须要结合实际场景,有明确的的优化目标,找到性能瓶颈,对瓶颈有针对性的优化,最后进行测试,通过各种监控工具确认调优后的结果是否符合目标。
(1)调优可以依赖、参考的数据有系统运行日志、堆栈错误信息、gc日志、线程快照、堆转储快照等。
① 系统运行日志:系统运行日志就是在程序代码中打印出的日志,描述了代码级别的系统运行轨迹(执行的方法、入参、返回值等),一般系统出现问题,系统运行日志是首先要查看的日志。
② 堆栈错误信息:当系统出现异常后,可以根据堆栈信息初步定位问题所在,比如根据“java.lang.OutOfMemoryError: Java heap space”可以判断是堆内存溢出;根据“java.lang.StackOverflowError”可以判断是栈溢出;根据“java.lang.OutOfMemoryError: PermGen space”可以判断是方法区溢出等。
③ GC日志:程序启动时用 -XX:+PrintGCDetails 和 -Xloggc:/data/jvm/gc.log 可以在程序运行时把gc的详细过程记录下来,或者直接配置“-verbose:gc”参数把gc日志打印到控制台,通过记录的gc日志可以分析每块内存区域gc的频率、时间等,从而发现问题,进行有针对性的优化。
④ 线程快照:顾名思义,根据线程快照可以看到线程在某一时刻的状态,当系统中可能存在请求超时、死循环、死锁等情况是,可以根据线程快照来进一步确定问题。通过执行虚拟机自带的“jstack pid”命令,可以dump出当前进程中线程的快照信息,更详细的使用和分析网上有很多例,这篇文章写到这里已经很长了就不过多叙述了,贴一篇博客供参考:http://www.cnblogs.com/kongzhongqijing/articles/3630264.html
⑤ 堆转储快照:程序启动时可以使用 “-XX:+HeapDumpOnOutOfMemory” 和 “-XX:HeapDumpPath=/data/jvm/dumpfile.hprof”,当程序发生内存溢出时,把当时的内存快照以文件形式进行转储(也可以直接用jmap命令转储程序运行时任意时刻的内存快照),事后对当时的内存使用情况进行分析。
JVM的优化我们可以从JIT优化,内存分区设置优化以及GC选择优化三个方面入手。
1.JIT优化
在系统启动的时候,首先Java代码是解释执行的,当方法调用次数到达一定的阈值的时候(client:1500,server:10000),会采用JIT优化编译。而直接将JVM的启动设置为-Xcomp并不会有想象中那么好。没有足够的profile(侧写,可以大致理解为分析结果),优化出来的代码质量很差,甚至于执行效率还要低于解释器执行,并且机器码的大小很容易就超出字节码大小的10倍以上。
那么我们能做的,就是通过附加启动命令适当的调整这个阈值或者调整热度衰减行为,在恰当的时候触发对代码进行即时编译。
方法计数器阈值:-XX:CompileThreshold
回边计数器阈值:-XX:OnStackReplacePercentage(这并不是直接调整阈值,回边计数器的调整在此仅作简单介绍,此计数器会根据是Client模式还是Server模式有不同的计算公式)
关闭热度衰减:-XX:UseCounterDecay
设置半衰周期:-XX:CounterHalfLifeTime
而JIT也是一片广阔的知识海洋,有兴趣可以根据以下的优化技术名称搜索了解详情,在此就不赘述了。
2.JVM内存分区优化
-
调优工具:jvisualvm jconsole
① 用 jps(JVM process Status)可以查看虚拟机启动的所有进程、执行主类的全名、JVM启动参数,比如当执行了JPSTest类中的main方法后(main方法持续执行),执行 jps -l可看到下面的OOMTest类的pid为7480,加上-v参数还可以看到JVM启动参数。
② 用jstat(JVM Statistics Monitoring Tool)监视虚拟机信息
jstat -gc pid 500 10 :每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印10次jstat还可以以其他角度监视各区内存大小、监视类装载信息等,具体可以google jstat的详细用法。
③ 用jmap(Memory Map for Java)查看堆内存信息
执行jmap -histo pid可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name是每个类的类名([B是byte类型,[C是char类型,[I是int类型),bytes是这个类的所有示例占用内存大小,instances是这个类的实例数量:
...
执行jmap -dump 可以转储堆内存快照到指定文件,比如执行 jmap -dump:format=b,file=/data/jvm/dumpfile_jmap.hprof 3361 可以把当前堆内存的快照转储到dumpfile_jmap.hprof文件中,然后可以对内存快照进行分析。
④ 利用jvisualvm分析内存信息(各个区如Eden、Survivor、Old等内存变化情况),如果查看的是远程服务器的JVM,程序启动需要加上如下参数:
"-Dcom.sun.management.jmxremote=true"
"-Djava.rmi.server.hostname=12.34.56.78"
"-Dcom.sun.management.jmxremote.port=18181"
"-Dcom.sun.management.jmxremote.authenticate=false"
"-Dcom.sun.management.jmxremote.ssl=false"
⑤ 分析堆转储快照
前面说到配置了 “-XX:+HeapDumpOnOutOfMemory” 参数可以在程序发生内存溢出时dump出当前的内存快照,也可以用jmap命令随时dump出当时内存状态的快照信息,dump的内存快照一般是以.hprof为后缀的二进制格式文件。
可以直接用 jhat(JVM Heap Analysis Tool) 命令来分析内存快照,它的本质实际上内嵌了一个微型的服务器,可以通过浏览器来分析对应的内存快照,比如执行 jhat -port 9810 -J-Xmx4G /data/jvm/dumpfile_jmap.hprof 表示以9810端口启动 jhat 内嵌的服务器:
Reading from /Users/dannyhoo/data/jvm/dumpfile_jmap.hprof...
Dump file created Fri Aug 03 15:48:27 CST 2018
Snapshot read, resolving...
Resolving 276472 objects...
Chasing references, expect 55 dots.......................................................
Eliminating duplicate references.......................................................
Snapshot resolved.
Started HTTP server on port 9810
Server is ready.
在控制台可以看到服务器启动了,访问 http://127.0.0.1:9810/ 可以看到对快照中的每个类进行分析的结果。
jvisualvm也可以分析内存快照,在jvisualvm菜单的“文件”-“装入”,选择堆内存快照,快照中的信息就以图形界面展示出来了,如下,主要可以查看每个类占用的空间、实例的数量和实例的详情等:
3.JVM调优经验
我们依据Java Performance这本书的建议的设置原则进行设置,
Java整个堆大小设置,Xmx 和 Xms设置为老年代存活对象的3-4倍,即FullGC之后的老年代内存占用的3-4倍,Xmx和Xms的大小设置为一样,避免GC后对内存的重新分配。而Full GC之后的老年代内存大小,我们可以通过前面在Visual VM中添加的插件Visual GC查看。先手动进行一次GC,然后查看老年代的内存占用。
新生代Xmn的设置为老年代存活对象的1-1.5倍。
老年代的内存大小设置为老年代存活对象的2-3倍。
JVM配置方面,一般情况可以先用默认配置(基本的一些初始参数可以保证一般的应用跑的比较稳定了),在测试中根据系统运行状况(会话并发情况、会话时间等),结合gc日志、内存监控、使用的垃圾收集器等进行合理的调整,当老年代内存过小时可能引起频繁Full GC,当内存过大时Full GC时间会特别长。
那么JVM的配置比如新生代、老年代应该配置多大最合适呢?答案是不一定,调优就是找答案的过程,物理内存一定的情况下,新生代设置越大,老年代就越小,Full GC频率就越高,但Full GC时间越短;相反新生代设置越小,老年代就越大,Full GC频率就越低,但每次Full GC消耗的时间越大。建议如下:
-Xms和-Xmx的值设置成相等,堆大小默认为-Xms指定的大小,默认空闲堆内存小于40%时,JVM会扩大堆到-Xmx指定的大小;空闲堆内存大于70%时,JVM会减小堆到-Xms指定的大小。如果在Full GC后满足不了内存需求会动态调整,这个阶段比较耗费资源。
新生代尽量设置大一些,让对象在新生代多存活一段时间,每次Minor GC 都要尽可能多的收集垃圾对象,防止或延迟对象进入老年代的机会,以减少应用程序发生Full GC的频率。
老年代如果使用CMS收集器,新生代可以不用太大,因为CMS的并行收集速度也很快,收集过程比较耗时的并发标记和并发清除阶段都可以与用户线程并发执行。
方法区大小的设置,1.6之前的需要考虑系统运行时动态增加的常量、静态变量等,1.7只要差不多能装下启动时和后期动态加载的类信息就行。
代码实现方面,性能出现问题比如程序等待、内存泄漏除了JVM配置可能存在问题,代码实现上也有很大关系:
避免创建过大的对象及数组:过大的对象或数组在新生代没有足够空间容纳时会直接进入老年代,如果是短命的大对象,会提前出发Full GC。
避免同时加载大量数据,如一次从数据库中取出大量数据,或者一次从Excel中读取大量记录,可以分批读取,用完尽快清空引用。
当集合中有对象的引用,这些对象使用完之后要尽快把集合中的引用清空,这些无用对象尽快回收避免进入老年代。
可以在合适的场景(如实现缓存)采用软引用、弱引用,比如用软引用来为ObjectA分配实例:SoftReference objectA=new SoftReference(); 在发生内存溢出前,会将objectA列入回收范围进行二次回收,如果这次回收还没有足够内存,才会抛出内存溢出的异常。
避免产生死循环,产生死循环后,循环体内可能重复产生大量实例,导致内存空间被迅速占满。
尽量避免长时间等待外部资源(数据库、网络、设备资源等)的情况,缩小对象的生命周期,避免进入老年代,如果不能及时返回结果可以适当采用异步处理的方式等。
4.常用JVM参数参考
参数 说明 实例
-Xms 初始堆大小,默认物理内存的1/64 -Xms512M
-Xmx 最大堆大小,默认物理内存的1/4 -Xms2G
-Xmn 新生代内存大小,官方推荐为整个堆的3/8 -Xmn512M
-Xss 线程堆栈大小,jdk1.5及之后默认1M,之前默认256k -Xss512k
-XX:NewRatio=n 设置新生代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:NewRatio=3
-XX:SurvivorRatio=n 年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:8,表示Eden:Survivor=8:1:1,一个Survivor区占整个年轻代的1/8 -XX:SurvivorRatio=8
-XX:PermSize=n 永久代初始值,默认为物理内存的1/64 -XX:PermSize=128M
-XX:MaxPermSize=n 永久代最大值,默认为物理内存的1/4 -XX:MaxPermSize=256M
-verbose:class 在控制台打印类加载信息
-verbose:gc 在控制台打印垃圾回收日志
-XX:+PrintGC 打印GC日志,内容简单
-XX:+PrintGCDetails 打印GC日志,内容详细
-XX:+PrintGCDateStamps 在GC日志中添加时间戳
-Xloggc:filename 指定gc日志路径 -Xloggc:/data/jvm/gc.log
-XX:+UseSerialGC 年轻代设置串行收集器Serial
-XX:+UseParallelGC 年轻代设置并行收集器Parallel Scavenge
-XX:ParallelGCThreads=n设置Parallel Scavenge收集时使用的CPU数。并行收集线程数。 -XX:ParallelGCThreads=4
-XX:MaxGCPauseMillis=n 设置Parallel Scavenge回收的最大时间(毫秒) -XX:MaxGCPauseMillis=100
-XX:GCTimeRatio=n设置Parallel Scavenge垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) -XX:GCTimeRatio=19
-XX:+UseParallelOldGC 设置老年代为并行收集器ParallelOld收集器
-XX:+UseConcMarkSweepGC 设置老年代并发收集器CMS
-XX:+CMSIncrementalMode 设置CMS收集器为增量模式,适用于单CPU情况。
5.设置jvm参数的几种方式
1、集成开发环境下启动并使用JVM,如eclipse需要修改根目录文件eclipse.ini;
2、Windows服务器下安装版Tomcat,可使用Tomcat7w.exe工具(tomcat目录下)和直接修改注册表两种方式修改Jvm参数;
3、Windows服务器解压版Tomcat注册Windows服务,方法同上;
4、解压版本的Tomcat, 通过startup.bat启动tomcat加载配置的,在tomcat 的bin 下catalina.bat 文件内添加;
5、Linux服务器Tomcat设置JVM,修改TOMCAT_HOME/bin/catalina.sh;
6、windows环境下配置JAVA_OPTS
full GC是man GC 的10倍
6.数据库优化Sql
一、什么是分区、分表、分库
分区:
将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介子中,实际上还是一张表。提高查询效率。
就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的
分表:
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
分库:
一旦分表,一个库中的表会越来越多
关系型数据库:
- 关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。常见的关系型数据库有Mysql,Oracle,Db2,Sysbase。
非关系型数据库(NoSQL):
- 大量的NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计
in和exists的区别
- *外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”*
索引失效
1. 索引字段进行判空查询时。也就是对索引字段判断是否为NULL时。语句为is null 或is not null。
2. 对索引字段进行like查询时。 like后面跟%
3. 判断索引列是否不等于某个值时。‘!=’操作符。比如:select * from S where User != 0
4. 对索引列进行运算。这里运算包括+-*/等运算。也包括使用函数。
5. or会导致索引失效
1.单机优化–建表三范式
三范式:
1.列不可分割
2.表中的记录具有唯一标识 通常通过主键来实现
3.表中尽量不要有冗余的字段 能够通过其他表推导出来的数据不要单独设置字段 通常通过外键来实现
-
1.每一列属性都是不可再分的属性值,确保每一列的原子性。
-
2.每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。表中记录是唯一标识,通过主键来实现。二范式就是要有主键,要求其他字段都依赖于主键。
-
3.数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。是要消除传递依赖,方便理解,可以看做是“消除冗余”。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
关系型数据库瓶颈
- 高并发读写需求
- 网站高并发高(双十一购物),硬盘I/O是一个很大的问题。
- 解决:集群和分布式
- 海量数据的高效率读写
- 解决:分表、分库。(表的数据量太大)
- 高扩展性和可用性
*2.*单机优化–关系型数据库的优化技术
1.定位慢查询(找出执行效率低Sql)
定位的时候先关闭mysql服务(cmd),在bin目录下cmd----执行----mysqld.exe --safe-mode --slow-query-log
- 查看和修改慢查询时间阈值
#查询慢查询的次数 系统默认的慢查询时间为10s
show status like 'slow_queries'
#查询表中所有的数据
select count(*) from emp
#设置慢查询时间 默认设置是当前会话的慢查询时间 如果需要设置全局的global
set global long_query_time = 0.5
- 常用命令
#查看数据库运行了多久 单位是秒
show status like 'uptime'
#查看crud的次数
show status like '%com_%'
#只看查询的次数 新增和查询的比例是二八
show status like '%com_select'
show status like '%com_insert'
#查询所有连接数
show status like 'connections'
#查询最大连接数 可以作为配置数据库最大连接数依据
show status like 'Max_used_connections'
#查询慢查询的次数 系统默认的慢查询时间为10s
show status like 'slow_queries'
#查看数据库慢查询时间
show variables like 'long_query_time'
#表中总条数
select count(*) from emp
select * from emp where empno=2800000
#设置慢查询时间 默认设置是当前会话的慢查询时间 如果需要设置全局的global
set global long_query_time = 0.5
步骤总结:
1)关闭原有mysql服务
2)以支持记录慢sql的方式来启动
3)设置慢查询时间阀值
4)构造慢sql
5)到日志文件中找慢sql(data.dir)
什么时候开启慢查询?
系统中所有sql都执行一遍,才能判断是否有慢sql。什么时候开启能覆盖所有sql执行?
开发者自验:
开发完成后,需要统一打包,统一部署,统一验证。
测试人员测试:
测试人员需要测试所有功能。
项目上线:
用户用了所有功能。
2.分析慢查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kwhtWPVi-1585889807495)(…/images/image-20191228194525787.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-buf39LqJ-1585889807499)(…/images/image-20191228195213374.png)]
-
explain+慢查询的sql语句
type 如果all表示全表扫描 possible_keys 可能用到的索引 key 实际用到的索引 rows 扫描多少行 -
explain select * from dept where dname like “OUhcNKkXfL%” 分析慢查询
-
索引失效的问题 like 百分号不能在前面 like “%OUhcNKkXfL%”
3.优化
-
单机 的优化(表结构,索引,Sql,选择数据库引擎)
-
表机构
遵循3范式 (3NF)
反三范式 (3NF)添加字段。课程封面能看到浏览量或购买量。点进去就加1,给课程添加一个字段。
变长:根据存储数据的大小 用多少就分配多少
定长:会立即分配相应的空间来存储数据
4.索引
-
索引(Index)是帮助数据库管理系统(DBMS)高效获取数据的数据结构。
组织数据方式,及访问数据的api的封装。-list,set,map,数组
-
索引算法
- myisam(不支持事务,外键,查询较多可用,表锁)----innodb(支持事务,外键,读写都可以,行锁) 只支持 B-tree算法
- 以空间换时间 (添加索引查询效率高,增删改的效率低----增加 I/O-索引存在磁盘上面)
总结:使用索引把全表查找变为索引查找,减少查询次数,增加查询效率。而索引查找效率的取决于索引算法。也就是索引(Index)是帮助DBMS高效获取数据的数据结构
-
索引的分类:
-
根据索引列的多少分为复合索引(多列)和普通索引(单列)
-
普通索引 唯一索引 主键索引 全文索引
-
普通索引:允许重复的值出现
一般来说,普通索引的创建,是先创建表,然后在创建普通索引 create index 索引名 on 表 (列1,列名2,...); alter table 表名add index 索引名(列1,列名2,..); 比如: create table aaa(id int unsigned,name varchar(32)); create index nameIndex on aaa(name); alter table aaa add index index1(name);- 唯一索引:除了不能有重复的记录外,其它和普通索引一样
1、当表的某列被指定为unique约束时,这列就是一个唯一索引 例如:create table bbb(id int primary key auto_increment , name varchar(32) unique); 这时, name 列就是一个唯一索引. 2、在创建表后,再去创建唯一索引 create unique index 索引名 on 表名 (列1,列2,..); alter table 表名add unique index 索引名 (列1,列2,..); 例如: create table ccc(id int primary key auto_increment, name varchar(32)); 注意:unique字段可以为NULL,并可以有多NULL, 但是如果是具体内容,则不能重复. 主键字段,不能为NULL,也不能重复.- 主键索引:是随着设定主键而创建的,也就是把某个列设为主键的时候,数据库就会給改列创建索引。这就是主键索引.唯一且没有null值
1、创建表时指定主键 例如:create table ddd(id int unsigned primary key auto_increment ,name varchar(32) not null defaul ‘’); 这时id 列就是主键索引. 2、如果你创建表时,没有指定主键,也可以在创建表后,再添加主键。 指令:alter table 表名 add primary key (列名); 举例: create table eee(id int , name varchar(32) not null default ‘’); alter table eee add primary key (id);- 全文索引:用来对表中的文本域(char,varchar,text)进行索引, 全文索引针对MyISAM有用
- 添加主键:alter table 表名 add primary key (列名);
-
-
创建索引的原则
#1.经常作为查询或者排序条件的字段 建立索引
#2.唯一性太差的字段不适合创建索引 比如性别
#3.频繁更新修改的字段不适合创建索引 因为每次修改都需要重新维护索引结构 导致大量的io单列 只在一个字段创建 多列(复合索引) 由多个字段共同组成索引
create index dlindex on dept(dname,loc);
show indexes from dept;#删除索引
alter table 表名 drop index 索引名;
alter table dept drop index name_index;
#删除主键修改
先删除后添加=修改
-
索引的代价:
1.占用磁盘空间。
2.对dml操作有影响,因为要维护索引,变慢。
#对于创建的多列索引(复合索引),不是使用的第一部分就不会使用索引。
explain select * from dept where dname like 'OUhcNKkXfL' #会使用索引
explain select * from dept where loc like 'mbvaQcPS'#不会使用索引
explain select * from dept where dname like 'OUhcNKkXfL' and loc like 'mbvaQcPS'#会使用索引
explain select * from dept where loc like 'mbvaQcPS' and dname like 'OUhcNKkXfL' #会使用索引
explain select * from dept where dname like 'OUhcNKkXfL' or loc like 'mbvaQcPS' #不会索引 or会导致索引失效
explain select * from dept where dname like '%OUhcNKkXfL%'#不会使用索引
explain select * from dept where dname like '%OUhcNKkXfL'#不会使用索引
explain select * from dept where dname like 'OUhcNKkXfL%'#会使用索引 like模糊查询前置匹配导致索引失效
explain select * from dept where dname is null #isnull判断会导致索引失效
- 索引失效
对于创建的多列索引(复合索引),不是使用的第一部分索引会失效。
用 or会导致索引失效。
like模糊查询前置匹配导致索引失效。
is null #isnull判断会导致索引失效
如果mysql估计使用全表扫描要比使用索引快,则不使用索引。----表中一条数据
5.存储引擎
- 分类:mysql:myisam,innodb,memory
MyISAM 和 INNODB的区别(主要)******
1. 事务安全 MyISAM不支持事务,INNODB支持
2. 查询和添加速度 MyISAM速度快,INNODB速度慢
3. 支持全文索引 MyIsam支持,innodb不支持
4. 锁机制 MyIsam表锁 innodb行锁
5. 外键 MyISAM 不支持外键, INNODB支持外键. (通常不设置外键,通常是在程序中保证数据的一致)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6bp5H698-1585889807501)(…/images/image-20191228195421160.png)]
- 引擎的使用场景
MyISAM存储引擎:
如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. 比如 bbs 中的 发帖表,回复表.
INNODB存储引擎:
对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
Memory 存储:
比如我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快.
- 修改数据库引擎
#指定存储引擎的时机
#建表的时候指定 没有指定的时候使用的是my.ini默认的
create table test (id int(20),name varchar(20))
# 指定数据库引擎 Create table 表名(字段列表) engine 存储引擎名称;
create table test1 (id int(20),name varchar(20)) ENGINE myisam
#修改存储引擎
alter table test1 engine = innodb
DQL 查询 Qquery select
DML 数据管理 manage insert update delete
DDL 定义 define create alter。。。。
delete trancate drop 删除
6.分表:
水平(行):业务 id区间 时间 hash分表
垂直(列):将一些不经常查询的大的字段分一张表 用外键连接
-
水平分割(行)和垂直分割(列)
-
所以一个好的拆分依据是最重要的。UNION,UNION ALL
- 分表策略
-
水平分表(数据百w一张表)-----经常组合(union)查询
如果一张表中数据量巨大时,我们要经常查询。则可以按照合适的策略拆分为多张小表。尽量在单张表中查询,减少扫描次数,增加查询效率。如果拆分不好,经常组合(union)查询,还不如不拆分.
分表策略
1.按时间分表
这种分表方式有一定的局限性,当数据有较强的实效性,如微博发送记录、微信消息记录等,这种数据很少有用户会查询几个月前的数据,如就可以按月分表。
按业务类型
2.按区间范围分表
一般在有严格的自增id需求上,如按照user_id水平分表:
table_1 user_id从1~100w
table_2 user_id从100W+1~200w
table_3 user_id从200W+1~300w
3.hash分表
通过一个原始目标的ID或者名称通过一定的hash算法计算出数据存储表的表名,然后访问相应的表。
Teacher1
Teacher2
生成id的方式:主键自增 uuid 雪花算法
最简单hash算法: T_user + Id%2+1 复杂hash算法: 分2张表 余0,1. 加1 可以得到最大2张
- 垂直分表
- 字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系(外键)。 (JOIN)
如果一张表某个字段,信息量大,但是我们很少查询,则可以考虑把这些字段,单独的放入到一张表中,用外键关联。如果硬是要查询,就是用跨表查询(join)
7.分区
-
分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器。分区后,表面上还是一张表,但数据散列到多个位置了。app读写的时候操作的还是大表名字,db自动去组织分区的数据。
-
查看数据库是否支持 5.1以后支持(MySql)
SHOW VARIABLES LIKE ‘%partition%’;
8. SQL优化小技巧
- DDL优化:变多次索引维护为一次索引维护,变多次唯一校验为一次唯一校验,变多次事务提交为一次事务提交
- DML优化:变多次事务提交为一次事务提交
30种sql语句优化
https://www.cnblogs.com/Little-Li/p/8031295.html
ddl dml 变多次维护为一次维护
dql优化 :注意索引失效的情况 对于limit分页 当偏移量大的时候 使用一个带有索引的字段进行排序或者过滤 就不再是全表扫描
3.多机优化
主流方案
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
1.sharding-jdbc(读写分离 分表分库);
-
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。(当当网开源框架,文档丰富,使用成本低。)
-
sharding-jdbc 是一个开源的适用于微服务的分布式数据访问基础类库,它始终以云原生的基础开发套件为目标。只支持java语言。
https://www.cnblogs.com/warehouse/p/10787601.html
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
2.Sharding-Proxy
- 定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL使用。
- 适用于任何兼容MySQL协议的客户端。
3.Sharding-Sidecar
- 定位为Kubernetes(k8s)或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
4.三者的区别特点
| Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
主从同步
准备环境
1.分别构造主、从数据库并输出日志(方便定位问题)
拷贝 数据库安装目录的文件夹,进入my.ini 进行修改配置
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3307
log=
#Path to installation directory. All paths are usually resolved relative to this.
basedir="G:/Program Files/MySQL5.5/master"
#Path to the database root
datadir="C:/ProgramData/MySQL/MySQL Server 5.5/Data/"
# The default character set that will be used when a new schema or table is
# created and no character set is defined
character-set-server=utf8
# The default storage engine that will be used when create new tables when
default-storage-engine=INNODB
2.修改master中的my.ini 路径改为master的路径
mysqld --install MySQLXY --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini"
(install/remove of the service denied 权限不足 以管理身份运行)
net start MySQLXY 重启服务
Sc delete master/slave 弄错了可以删除服务重新操作
开启日志(非必须)
(非必须)开启sql语句的日志,生产环境不建议开启:
查看日志目录,并开启sql语句的日志:
mysql>show variables like ‘%general_log%’;
mysql>set global general_log=on;
开启后,重启Mysql ,上述开启日志配置将失效。
测试环境
使用Spring Boot +MyBatis+dbcp+Sharding-JDBC+MySQL进行读写分离。
- pom导包
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.0.1
mysql
mysql-connector-java
5.1.46
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-devtools
true
org.projectlombok
lombok
commons-dbcp
commons-dbcp
1.4
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.0.0.M1
Spring
什么是框架
程序中的框架(framework)其实是一系列jar包的组合;
- 程序中的框架(framework)其实是一系列jar包的组合;
- 一个半成品,不需要从零起步,提高开发效率;
- 为了解决某一个领域的问题而产生;
- 适用于团队开发,统一规范,方便维护;
- 代码重用;
spring用到的设计模式:
代理模式—在AOP和remoting中被用的比较多。
单例模式—在spring配置文件中定义的bean默认为单例模式。
模板方法—用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
工厂模式—BeanFactory用来创建对象的实例。
适配器--spring aop
装饰器--spring data hashmapper
观察者-- spring 时间驱动模型
回调--Spring ResourceLoaderAware回调接口
https://blog.csdn.net/asdfsadfasdfsa/article/details/76690107
1.Spring是一个DI(注入)轻量级控制反转(IOC)和面向切面编程(AOP)的容器框架;
- 1.1.轻量级:
- (1)相对于重量级(框架设计比较繁琐,配置较多,例如EJB(tomcat不支持),现在基本不用了)而言,开发使用比较简单,功能强大;
- (2)IOC(Inverse of control):控制反转,将创建对象的权利交给Spring容器去管理,就不用了我们之前new对象的方式了,我们直接用,@Autowide注入就可以了;通过引入IOC容器,利用依赖关系注入的方式,实现对象之间的解耦。
- BeanFactory是懒加载
IOC容器的基本实现。它是工厂设计模式的实现,允许通过名称创建和检索对象。BeanFactory 也可以管理对象之间的关系。
- ApplicationContext是BeanFactory的子类,功能更加强大是迫切加载(主要的2个实现)。
ClassPathXmlApplicationContext:从类路径下加载配置文件;
FileSystemXmlApplicationContext:从文件系统中加载配置文件。
-----------------------------
- FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。
- (3)AOP(Aspect Oriented Programming)–代理模式:注解@Tranlcation 将相同的逻辑抽取出来,即将业务逻辑从应用服务中分离出来。然后以拦截的方式作用在一个方法的不同位置。例如日志,事务的处理(过滤,隔离);注解-XML
不同的类有相同的方法,可以把方法抽出来形成一个单独的类,谁要这个方法就直接调。
如果多个类出现了相同的代码,就应该抽取一个父类,然后把这些公共的代码都写在父类中。
AOP(AspectOrientedProgramming):将日志记录,性能统计,安全控制,事务处理,异常处理等代码从业务逻辑代码中划分出来,通过对这些行为的分离,我们希望可以将它们独立到非指导业务逻辑的方法中,进而改变这些行为的时候不影响业务逻辑的代码---解耦。
- (4)DI 一个对象的创建可能涉及到另一个对象的创建,比如A对象的成员变量持有B对象的引用,这就是依赖,A依赖于B,那么spring容器在创建对象A的时候,也会创建对象B,并把对象B注入到对象A中。
2.Spring致力于J2EE应用的各层的解决方案,而不是仅仅专注于某一层的方案。在企业级开发中,通常用于整合其他层次的框架;
3.Spring相当于是一个大的工厂,程序员需要将对象的创建交给Spring去执行;
4.Spring的一个最大的目的就是使JavaEE开发更加容易。Spring提供了对开源社区中很多框架及JavaEE中很多技术的支持,让程序员很轻松能整合及使用这些框架技术;
5.Spring在一定程度行降低了代码之间的耦合度,使得维护难度降低了;
6.容器框架:装对象(Bean是Spring中的对象)
7.测试
@Runwith
@ApplicationContext 配置文件
SpringMVC(默认单利线程安全)
- SpringMvc是spring中的一个模块,它可以和Spring无缝连接
- 是一个web层/表现层的框架,也叫MVC框架
核心控制器:用于Web层核心功能的处理以及在所有控制器执行之前,所有的WebMvc框架都采用了这种方式,在SpringMVC中使用的是DispatcherServlet为核心控制器. DispatcherServlet核心控制器会拦截匹配的请求,把拦截下来的请求,依据相应的规则分发到目标Controller来处理;
ModelAndView:是SpringMVC控制器中特有一个对象,描述一次请求响应的数据(Model)和 视图(View);
一.全注解
1.实例化bean的注解
- @controller :控制层注解
- @Service :业务层
- @Componet :通用的
- @Repository :持久化
- 前提是扫描包路径:
2.请求注解
- @RequestMapping("/")
- 前提是开启mvc注解:mvc:annotation-driven
3.注入注解 - @Autowired (创建对象)
- 可以使用在字段和setter方法上
2.接收请求参数
- req参数
- 形参:名字必须与表单中name属性值相同
- 通过对象获取:bean属性要与表单中的name属性值相同
- 通过@PathVariable获取
3.的三种实现
实现Controller接口;
实现HttpRequestHandler接口;
普通类(pojo)和注解 @RequestMapping;
注意事项:
1.要使用@Controller注解(创建对象的注解),就需要配置:
4.执行流程
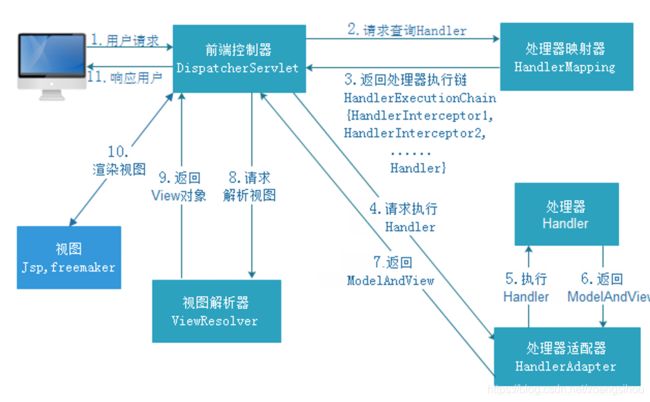
二.返回json
- @RequestBody注解
@RequestBody注解用于读取http请求的内容(字符串),通过SpringMVC提供的HttpMessageConverter接口将读到的内容转换为json、xml等格式的数据并绑定到Controller类方法的参数上。
本例子应用:@RequestBody注解实现接收http请求的json数据,将json数据转换为java对象。
- @ResponseBody注解
@ResponseBody注解用于将Controller类的方法返回的对象,通过HttpMessageConverter接口转换为指定格式的数据如:json、xml等,通过Response响应给客户端。

SpringDataJpa
技术特点:
我们只需要定义接口并集成 Spring Data JPA 中所提供的接口就可以了。不需要编写接口实现类。
-
SpringData JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。
-
Spring Data JPA的独特之处就是简单查询根本不用写实现类,直接写接口就好,它能根据你的接口去生成sql,很酷炫吧
常用注解
@Entity 这是一张表
@Table(name = "自定义的表名")
自定义设置这个实体类在数据库所对应的表名!
@Id
把这个类里面所在的变量设置为主键Id。
@GeneratedValue
设置主键的生成策略,这种方式依赖于具体的数据库,如果数据库不支持自增主键,那么这个类型是没法用的。
@Basic
表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的getXxxx()方法,默认 即为 @Basic fetch: 表示该属性的读取策略,有EAGER和LAZY两种,分别表示主支抓取和延迟加载,默认为EAGER.
@Column(name = "自定义字段名",length = "自定义长度",nullable = "是否可以空",unique = "是否唯一",columnDefinition = "自定义该字段的类型和长度")
表示对这个变量所对应的字段名进行一些个性化的设置,例如字段的名字,字段的长度,是否为空和是否唯一等等设置。
@Transient
表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性. 如果一个属性并非数据库表的字段映射,就务必将其标示为 @Transient ,否则,ORM框架默认其注 解为 @Basic对于昨天实践的注解已经解析完了啦!那么今天为了接着对JPA表之间的各种关系的映射继续实践,我们再新建几个实体类!接下来我们分别新建了
@Entity //表
@Table(name = "employee") //表名
public class Employee extends BaseDomain {
---------------
/**
* 泛化:继承关系
* 在我们JPA,如果要抽取一个父类,就必需加上 @MappedSuperclass
* 非常明确定的告诉JPA,这是一个用于映射的父类
*/
@MappedSuperclass
public class BaseDomain {
@Id
@GeneratedValue
protected Long id;
---------------
//自动从当前上下文中获取这个对象
@PersistenceContext
1.SpringDataJpa查询Query的使用(重要)
1)基于方法名称命名规则查询 ...findBy(关键字)+属性名称(属性名称的首字母大写)+查询条件(首字母大写)
2)基于@Query 注解查询
https://www.cnblogs.com/chenglc/p/11226693.html
| 关键字 | 方法命名 | sql where 字句 |
|---|---|---|
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equal | findById, | findByIdEquals |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEqual | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEqual | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,Not Null | findByNameNotNull | where name is not |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?’ |
| Containing | findByNameContaining | where name like ‘%?%’ |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection c) | where id in (?) |
| NotIn | findByIdNotIn(Collection c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
- 第一种:根据方法命名规则自动生成 findBy
1)基于一列等值查询 findBy列名 例如:findByName(String name)
// 根据收派标准名称查询
public List findByName(String name);
2)基于一列模糊查询findBy列名Like 例如:findByNameLike(String name)
3)基于两列等值查询findBy列名And列名 例如:findByUsernameAndPassword(String username,String password)
- 第二种:不按命名规则写的查询方法,可以配置@Query绑定JPQL语句或者SQL语句
@Query(value="from Standard where name = ?" ,nativeQuery=false)
// nativeQuery 为 false 配置JPQL,为true 配置SQL
public List queryName(String name);
- 第三种:不按命名规则写的查询方法,配置@Query,没写语句,实体类@NamedQuery定义(不常用)
@Query
public List queryName2(String name);
@NamedQueries({
@NamedQuery(name="Standard.queryName2",query="from Standard where name=?")
})
2.@Query+@Modifying注解完成修改、删除操作(重要)
1、修改
@Query(value="update Standard set minLength=?2 where id =?1")
@Modifying
public void updateMinLength(Integer id , Integer minLength);
2、测试
Junit单元测试,要添加事务,设置事务不回滚
@Test
@Transactional
@Rollback(false)
public void testUpdate(){
standardRepository.updateMinLength(1, 3);
}
————————————————
版权声明:本文为CSDN博主「匿名攻城狮」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sunguodong_/article/details/79083496
Hibernate
- 是一个ORM框架,性能一般(SQL不可控),不用自己写Sql(一般的都处理了)
hibernate:是整orm映射规范的一种实现.
MyBatis
- MyBatis 是一款优秀的持久层框架,它支持定制化 (动态)SQL、存储过程以及高级映射。
- 核心对象 ---- SqlSessionFactory 通过xml配置 拿到 SqlSession
- https://www.jianshu.com/p/5b0e0a584cd9
- https://mybatis.org/mybatis-3/zh/sqlmap-xml.html 多对多

查询男性用户,如果输入了姓名则按照姓名模糊查找,否则如果输入了年龄则按照年龄查找,否则查找姓名为“鹏程”的用户
List queryUserListByNameOrAge(@Param("name") String name,@Param("age") Integer age);
---------------
————————————————
查询所有用户,如果输入了姓名按照姓名进行模糊查询,如果输入年龄,按照年龄进行查询,如果两者都输入,两个条件都要成立
List queryUserListByNameAndAge(@Param("name") String name,@Param("age") Integer age);
————————————————
foreach
————————————————
原文链接:https://blog.csdn.net/hellozpc/article/details/80878563
嵌套查询和嵌套结果
- 嵌套结果
发一条关联sql解决问题,映射文件Mapper结果的手动封装ResultMap
- 嵌套结果
缓存
-
在mybatis中,一级缓存默认是开启的,并且一直无法关闭
-
一级原理
mybatis的一级缓存作用域在 session中 ,默认开启且无法关闭。当执行相同的SQL时,mybatis不执行SQL,而是从缓存命中返回。
Mybatis查询时,先去缓冲区命中,如果命中直接返回,没有就执行SQL,查数据库。
---------------------------
一级缓存: SqlSession级别缓存,缓存对象存储周期为第一次获取,到sqlsession被销毁掉,或是sqlSession().clearCache();
一级缓存满足条件:
1、同一个session中
2、相同的SQL和参数
- 二级缓存
二级缓存: SqlSessionFactory级别缓存,缓存对象存储周期为第一次获取,到SqlSessionFactory被销毁掉(应用停止了);
mybatis 的二级缓存的作用域是一个mapper的namespace ,同一个namespace中查询sql可以从缓存中命中。
面试题:mybatis相较于jdbc的优点?
1. jdbc重复性代码比较多 ,mybatis 没有jdbc贾琏欲执事
2. jdbc在封装数据那块比较麻烦,比如查询一条数据 select * from user where id=1,返回值需要在结果集里面进行封装,使用mybatis 自动会封装
3. jdbc没有缓存支持,mybatis也是有缓存支持
4. jdbc写sql写到代码里面,sql和代码融合在一起,修改起来不是很方便,mybatis统一维护sql,专门有mapper.xml文件配置
5. mybatis比较灵活,支持批量操作...
MyBatis事务
Mybatis提供了一个事务接口Transaction,以及两个实现类jdbcTransaction和ManagedTransaction,当spring与Mybatis一起使用时,spring提供了一个实现类SpringManagedTransaction
Transaction接口:提供的抽象方法有获取数据库连接getConnection,提交事务commit,回滚事务rollback和关闭连接close,源码如下:
#和$区别
#:传进来的参数会加“” 引号当成字符串解析,#{}能够很大程度上防止sql注入;
$:传入的数据直接显示生成在sql中。
- 注意:Mybaties排序时使用order by 动态参数时需要注意,使用${}而不用#{}。
符号转义
1.转义

cdata(未解析)字符数据
MyBatis的sql可以用xml和注解 的方式
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}
left join和join
-
select * from a inner join b on a.id=b.id 只会查出相等的id
-
select * from a left/right join b on a.id=b.id 全部查出来所有字段
SpringBoot
-
简化开发,使用Spring Boot很容易创建一个独立运行(运行jar,内嵌Servlet容器)、准生产级别的基于Spring框架的项目,使用Spring Boot你可以不用或者只需要很少的Spring配置。
-
特点
独立运行的Spring项目:Spring Boot可以以jar包的形式独立运行,运行一个Spring Boot项目只需通过java -jar xx.jar来运行
内嵌的Servlet容器:Spring Boot可选择内嵌Tomcat、Jetty,无需以war包形式部署项目
提供starter简化Maven的配置,如使用spring-boot-starter-web时,会自动加入tomcat,webMvc,jackson,hibernate-validate的jar
自动配置Spring:Spring Boot 会根据在类路径中的jar包,类为jar包里的类自动配置Bean
准生产级别的应用监控:Spring Boot提供了基于http,ssh,telnet对运行时的项目进行监控
无代码生产和xml配置(spring 4.x中通过条件注解实现)
————————————————
原文链接:https://blog.csdn.net/weixin_37598682/article/details/81912871
1.启动流程分为两步
启动流程分为两步: https://www.jianshu.com/p/b1b195f21dd4 详情
1.创建SpringApplication实例
1)判断是否为web环境
2) 设置初始化器
从META-INF/spring.factories处读取配置文件中Key为:org.springframework.context.ApplicationContextInitializer的value,进行实例化操作
3) 设置监听器
4) 推断应用入口类
2.执行SpringApplication.run()
1) 获取SpringApplicationRunListeners,启动监听
2) 根据SpringApplicationRunListeners以及参数来准备环境
3) 创建ApplicationContext(spring上下文)
4) 创建FailureAnalyzer, 用于触发从spring.factories加载的FailureAnalyzer和FailureAnalysisReporter实例
5) spring上下文前置处理
6) spring上下文刷新
7) spring上下文后置处理
2.注解
- @SpringBootApplication包括三个注解:
@EnableAutoConfiguration:SpringBoot根据应用所声明的依赖来对Spring框架进行自动配置。简单概括一下就是,是借助@Import的帮助,将所有符合自动配置条件的bean定义加载到IoC容器。
@Configuration:它就是JavaConfig形式的Spring Ioc容器的配置类。被标注的类等于在spring的XML配置文件中(applicationContext.xml),装配所有bean事务,提供了一个spring的上下文环境。
@ComponentScan:组件扫描,可自动发现和装配Bean,功能其实就是自动扫描并加载符合条件的组件或者bean定义,最终将这些bean定义加载到IoC容器中。可以通过basePackages等属性来细粒度的定制@ComponentScan自动扫描的范围,如果不指定,则默认Spring框架实现会从声明@ComponentScan所在类的package进行扫描。默认扫描SpringApplication的run方法里的Booter.class所在的包路径下文件,所以最好将该启动类放到根包路径下。
- @EnableAutoConfiguration自动装配
这里我们可以看到@EnableAutoConfiguration使用@Import添加了一个AutoConfigurationImportSelector类,Spring自动注入配置的核心功能就依赖于这个对象。
在这个类中,提供了一个getCandidateConfigurations()方法用来加载配置文件。借助Spring提供的工具类SpringFactories的loadFactoryNames()方法加载配置文件。扫描的默认路径位于META-INF/spring.factories中。
配置文件2种
1.bootstrap.yml(bootstrap.properties)先加载 bootstrap 是应用程序的父上下文,系统级别配置
2.application.yml(application.properties)后加载
配置文件名是固定的 application.properties 或application.yml
-
application.properties 像键值对那样 K-V结构
-
application.yml
1. 使用缩进表示层级关系
2. 缩进时不允许使用Tab键,只允许使用空格
3. 缩进的空格的数目不重要,只要相同层级的元素左对齐即可
4. 大小写敏感
-
bootstrap 配置文件有以下几个应用场景。
使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
一些固定的不能被覆盖的属性
一些加密/解密的场景;
SpringCloud
五大组件
注册中心:Eureka(服务的注册和管理服务)
负载均衡:Ribbon Feign 接口调用组件
断路器:Hystrix(豪猪) 解决雪崩
路由网关:zuul(为后台服务提供统一访问的接口)
配置中心:config(对多个服务里面的配置文件进行统一管理)
- Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
-
Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
-
Feign:请求调用——基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求(底层是ribbon)
-
Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
-
Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
————————————————原文链接:https://blog.csdn.net/xunjiushi9717/article/details/91988479
服务熔断
- 服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
- 服务出现不可调用时,暂时停止对该服务的调用。比如说(评论服务当前不可用,其他模块业务不影响)
服务降级
-
服务间调用时,有服务挂了,而直接返回一个提前准备好的fallback(托底)错误处理信息。
-
服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
熔断VS降级
相同点:
目标一致 都是从可用性和可靠性出发,为了防止系统崩溃;
用户体验类似 最终都让用户体验到的是某些功能暂时不可用;
不同点:
触发原因不同 服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
原文链接:https://blog.csdn.net/pengjunlee/article/details/86688858
- 每一层用到的注解
Redis
https://blog.csdn.net/the_programlife/article/details/80863268
使用Redis有什么缺点?
缓存和数据库双写一致性问题
缓存雪崩问题
缓存击穿问题
缓存的并发竞争问题
3、单线程的Redis为什么这么快?
你知道Redis是单线程工作模型吗?
纯内存操作
单线程操作,避免了频繁的上下文切换
采用了非阻塞I/O多路复用机制
4、Redis的数据类型及使用场景
(这5种类型你用到过几个?)
String:一般做一些复杂的计数功能的缓存;
Hash:单点登录;
List:做简单的消息队列的功能;
Set:做全局去重的功能;
SortedSet:做排行榜应用,取TOPN操作;延时任务;做范围查找。
5、Redis过期策略和内存淘汰机制?
正解:Redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?定期删除+惰性删除是如何工作的呢?采用定期删除+惰性删除就没其他问题了么?
6、Redis和数据库双写一致性问题
(最终一致性和强一致性)
如果对数据有强一致性要求,不能放缓存。
7、如何应对缓存穿透和缓存雪崩问题
缓存穿透:即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
缓存雪崩:即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
中小型的公司一般遇不到这些问题,但是大并发的项目,流量有几百万左右,这两个问题一定要深刻考虑。
8、如何解决Redis并发竞争Key问题?
这个问题大致就是,同时有多个子系统去set一个key。不太推荐使用redis的事务机制。
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
默认端口:6379 ----- k-value非关系性数据库
数据结构
String: 字符串 一个String类型的value最大可以存储512M。一般做一些复杂的计数功能的缓存;
Hash: 散列 单点登录
List: 列表 做简单的消息队列的功能;
Set: 集合 做全局去重的功能;
Sorted Set: 有序集合 做排行榜应用,取TOPN操作;延时任务;做范围查找。
(这5种类型你用到过几个?)
存储 set key xxx
取值 get key
集群:主从和哨兵的集合体
为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
使用集群,只需要将redis配置文件中的cluster-enable配置打开即可。每个集群中至少需要三个主数据库才能正常运行,新增节点非常方便。
1.多个redis节点网络互联,数据共享
2.所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用
3.客户端可以连接任何一个主节点进行读写
不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上, 并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为
支持在线增加、删除节点
主从复制—主数据库(master)和从数据库(slave)
特点
主可以读写,从只读
主挂了之后不会有从升为主
一个主可以有多个从,从唯一对应一个主
-------------------------------
主挂了就不提供写服务,服务就真的挂了
哨兵:是监控redis集群的运行状况
特点
是建立在主从模式的基础上,如果只有一个Redis节点,哨兵就没意义了
主挂了会有选举机制选择一个从提升为主,修改配置文件
持久化:在于数据备份和故障恢复
Redis所有的数据都保存在内存中,对数据的更新将异步地保存在磁盘上
- AOF 记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集
https://blog.csdn.net/qq_34190023/article/details/82715705
优点
1.AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
2.AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
缺点
1.对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大。
2.做数据恢复AOF比RDB差 AOF先把命令读出来在执行 RDB直接导进去数据
- RDB 快照 可以将存在于某一时刻的所有数据都写入磁盘
优点:速度快,适合于用做备份,主从复制也是基于RDB持久化功能实现的。
缺点:会有数据丢失
优点
1.RDB可以做冷备,生成多个文件,每个文件都代表了某一个时刻的完整的数据快照
2.相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis的数据会更加快速。
3.当进行RDB持久化时,对redis服务处理读写请求的影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。生成一次RDB文件的过程就是把当前时刻内存中的数据一次性写入文件中,而AOF则需要先把当前内存中的小量数据转换为操作指令,然后把指令写到内存缓存中,然后再刷写入磁盘。
缺点
1.一般不要让生成RDB文件的间隔太长,否则每次生成的RDB文件太大了,对redis本身的性能会有影响。
# RDB文件的文件名称,默认dump.rdb
dbfilename dump.rdb
# 生成RDB文件的策略,默认为以下3种,意思是:
# 每隔60s(1min),如果有超过10000个key发生了变化,就写一份新的RDB文件
# 每隔300s(5min),如果有超过10个key发生了变化,就写一份新的RDB文件
# 每隔900s(15min),如果有超过1个key发生了变化,就写一份新的RDB文件
# 配置多种策略可以同时生效,无论满足哪一种条件都会写一份新的RDB文件
save 900 1
save 300 10
save 60 10000
# 是否开启RDB文件压缩,该功能可以节约磁盘空间,默认为yes
rdbcompression yes
# 在写入文件和读取文件时是否开启rdb文件检查,检查是否有无损坏
# 如果在启动时检查发现文件损坏,则停止启动,默认yes
rdbchecksum yes
######################### AOF #########################
# 是否开启AOF机制,默认为no
appendonly yes
# AOF文件的名称,默认为appendonly.aof
appendfilename "appendonly.aof"
# fsync的策略,默认为everysec
# everysec:每秒fsync一次
# no:redis不主动fsync,完全交由操作系统决定
# always:1条指令fsync一次
appendfsync everysec
缓存雪崩,穿透,击穿
缓存穿透
访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
解决方案
采用布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤;
访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间。
缓存击穿
一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。
解决方案
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key
缓存雪崩
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
解决方案
可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
原文链接:https://blog.csdn.net/qq_42737056/article/details/86531310
Elasticsearch
基本概念
| ElasticSearch | RDBMS |
|---|---|
| 索引(index) | 数据库(database) |
| 类型(type) | 表(table) |
| 文档(document) | 行(row) |
| 字段(field) | 列(column) |
| 映射(mapping) | 表结构(schema) |
| 全文索引 | 索引 |
| 查询DSL | SQL |
| GET | select |
| PUT/POST | update |
| DELETE | delete |
索引
索引(index)是ElasticSearch存放具体数据的地方,是一类具有相似特征的文档的集合。ElasticSearch中索引的概念具有不同意思,这里的索引相当于关系数据库中的一个数据库实例。在ElasticSearch中索引还可以作为动词,表示对数据进行索引操作。
类型
在6.0之前的版本,一个ElasticSearch索引中,可以有多个类型;从6.0版本开始,一个ElasticSearch索引中,只有1个类型。一个类型是索引的一个逻辑上的分类,通常具有一组相同字段的文档组成。ElasticSearch的类型概念相当于关系数据库的数据表。
文档
文档是ElasticSearch可被索引的基础逻辑单元,相当于关系数据库中数据表的一行数据。ElasticSearch的文档具有JSON格式,由多个字段组成,字段相当于关系数据库中列的概念。
链接:https://www.jianshu.com/p/bcffe33f55ab
为什么用?
查询东西太多,效率高,通过分词器将关键字进行拆分。提高查询效率。把需要查询的字段添加到es索引库,我们在里面搜索,然后es给我们返回。
上线:es创建索引,从es查 成功之后更改数据库状态
Kibanan
- ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
倒排索引
- 倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
- 把需要查询的数据分词 拆分添加索引 k-V结构 索引-数据
Fastdfs
-
fastDFS 是以C语言开发的一项开源轻量级分布式文件系统,他对文件进行管理,主要功能有:文件存储,文件同步,文件访问(文件上传/下载),特别适合以文件为载体的在线服务,如图片网站,视频网站等
-
分布式文件系统:
基于客户端/服务器的文件存储系统
对等特性允许一些系统扮演客户端和服务器的双重角色,可供多个用户访问的服务器,比如,用户可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样
FastDFS由跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)构成。
-
Tracker server 追踪服务器
追踪服务器负责接收客户端的请求,选择合适的组合storage server ,tracker server 与 storage server之间也会用心跳机制来检测对方是否活着。
Tracker需要管理的信息也都放在内存中,并且里面所有的Tracker都是对等的(每个节点地位相等),很容易扩展
客户端访问集群的时候会随机分配一个Tracker来和客户端交互。
-
Storage server 储存服务器
实际存储数据,分成若干个组(group),实际traker就是管理的storage中的组,而组内机器中则存储数据,group可以隔离不同应用的数据,不同的应用的数据放在不同group里面,
-
优点:
海量的存储:主从型分布式存储,存储空间方便拓展,
fastDFS对文件内容做hash处理,避免出现重复文件
然后fastDFS结合Nginx集成, 提供网站效率 -
客户端Client
-
主要是上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。每个客户端服务器都需要安装Nginx

链接:https://www.jianshu.com/p/b7c330a87855
RabbitMq
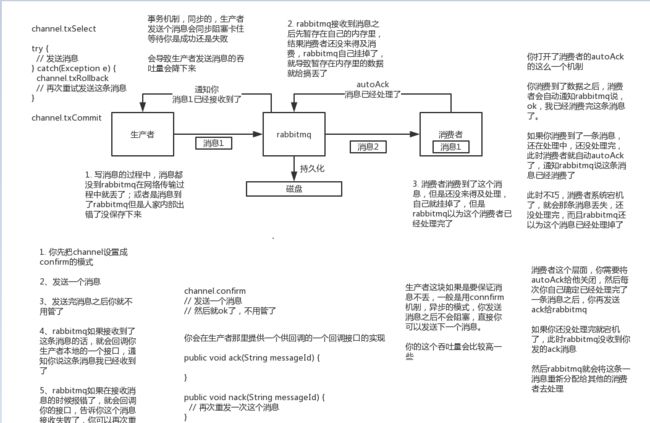
1、保证消息不丢失
1.1、开启事务(不推荐)
1.2、开启confirm(推荐)
可以开启confirm模式。在生产者那里设置开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如何写入了rabbitmq之中,rabbitmq会给你回传一个ack消息,告诉你这个消息发送OK了;如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
1.3、开启RabbitMQ的持久化(交换机、队列、消息)
1.4、关闭RabbitMQ的自动ack(改成手动)
2、保证消息不重复消费
2.1、幂等性(每个消息用一个唯一标识来区分,消费前先判断此标识有没有被消费过,若已消费过,则直接ACK)
rabbitmq如何保证消息的顺序性
将消息放入同一个交换机,交给同一个队列,这个队列只有一个消费者,这个消费者只允许同时开启一个线程
rabbitMQ保证消息不丢失的具体方案
前提:
(1)开启confirm
(2)开启RabbitMQ的持久化(交换机、队列、消息)
(3)关闭RabbitMQ的自动ack(改成手动)
(4)配置消费重试次数,消费重试间隔时间等
1、保证投放消息不丢失
(1)先将消息放入生产者Redis(此时消息的状态为未投放),再放入队列
(2)根据conform(ReturnCallback和ConfirmCallback)的结果来确定消息是否投递成功,
投递成功的,修改生产者redis中此消息的投递状态为已投递
投递失败的将会放入失败的Redis,并从生产者Redis中删除,由定时任务定期扫描并重新投递
(3)需要一个专门的定时任务扫描生产者Redis中存放了一定时间,但是状态还是未投放的消息
此消息会被认为已经投递,但是没有任何反馈结果(由于不可知因素,导致没有ReturnCallback,也没有ConfirmCallback),
此类消息被扫描到后,会放入失败的Redis,并从生产者Redis中删除,由定时任务定期扫描并重新投递
(4)还需要一个专门的定时任务扫描生产者Redis中存放了很久,仍然未消费的数据(状态为已投递),此类消息被扫描到后,会放入失败的Redis,并从生产者Redis中删除,由定时任务定期扫描并重新投递
(5)扫描失败的Redis的定时任务都遵循一条原则,一条消息最多被重新投递三次,若投递了三次仍然失败,则记录日志,记录到数据库,不会再投递,需要人工干预处理
2、保证消费消息不丢失
(1)消费者取到消息后,从消息中取出唯一标识,先判断此消息有没有被消费过,若已消费过,则直接ACK(避免重复消费)
(2)正常处理成功后,将生产者Redis中的此消息删除,并ACK(告诉server端此消息已成功消费)
(3)遇到异常时,捕获异常,验证自己在消息中设定的重试次数是否超过阀值,若超过,则放入死信队列,若未超过,则向将消息中的重试次数加1,抛出自定义异常,进入重试机制
(4)有专门的消费者用于处理死信队列中消费多次仍未消费成功的数据,可以记录日志,入库,人工干预处理
集群部署方案
rabbitmq有两种集群部署方案
1、普通模式
rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构
消息实体只存在于其中一个节点rabbit01(或者rabbit02)
当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer
2、镜像模式
把需要的队列做成镜像队列,存在与多个节点,消息实体会主动在镜像节点间同步,属于RabbitMQ的HA方案。
副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
1.1.基本概念
MQ全称为Message Queue,即消息队列. 它也是一个队列,遵循FIFO原则.
RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue Protocol高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开 发中应用非常广泛。
1.2.RabbitMQ使用场景
-
消峰&限流
-
应用解耦
-
异步处理
-
数据分发
-
消息通讯
-
分布式事务
-
排序保证&先进先出
场景原理图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xl9pfrVA-1585889807509)(…/images/image-20191210102102118.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wELez0pp-1585889807515)(…/images/1570516911259-1573355508978.png)]
1.3.常见的消息队列
ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ、Redis。
1.4.Exchange分类
-
Fanout:广播
将消息交给所有绑定到交换机的队列 all
-
Direct:定向
把消息交给符合指定routing key 的队列 一堆或一个
-
Topic:通配符
把消息交给符合routing pattern(路由模式)的队列 一堆或者一个
12.如何避免消息丢失?
12.1 .手动签收
消费者的ACK机制。可以防止消费者丢失消息。
12.2 .持久化
持久化可以防止消费者丢失消息。
7.常用的设计模式
创建型模式,共五种:工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
1.工厂模式
https://blog.csdn.net/fanrenxiang/article/details/81939357
-
工厂模式适用于生产大量相似对象、 抽象工厂模式:生产家族(全套的各类对象)
静态工厂模式:将多方法工厂模式里的方法置为静态的,不需要创建实例,直接调用即可,较为常用。
public class SendFactory {
public static Sender produceMail(){ // 多方法工厂+static静态
return new MailSender();
}
public static Sender produceSms(){
return new SmsSender();
}
}
public class FactoryTest {
public static void main(String[] args) {
Sender sender = SendFactory.produceMail(); // 不需要创建实例,直接调用即可
sender.Send();
}
}
2.抽象模式
抽象工厂模式(Abstract Factory):增加多个工厂类
public class SendMailFactory implements Provider {
public Sender produce(){
return new MailSender();
}
}
public class SendSmsFactory implements Provider{
public Sender produce() {
return new SmsSender();
}
}
3.单利模式
-
https://my.oschina.net/dyyweb/blog/609021
-
由于某种需要,要保证一个类在程序的生命周期当中只有一个实例,并且提供该实例的全局访问方法。
-
单例模式在程序设计中非常的常见,一般来说,某些类,我们希望在程序运行期间有且只有一个实例,原因可能是该类的创建需要消耗系统过多的资源、花费很多的时间,要保证一个类在程序的生命周期当中只有一个实例,并且提供该实例的全局访问方法。
package cn.itsource.test;
public class Test5 {
/*5.写出至少两种不同方式的单例模式的类,并说说他们的区别单利模式的意义
* 懒汉模式 具有线程安全问题
* 饿汉模式
* */
public static void main(String[] args) {
}
}
/*
懒汉式:顾名思义懒汉式就是应用刚启动的时候,并不创建实例,当外部调用该类的实例或者该类实例方法的时候,才创建该类的实例。是以时间换空间。
懒汉式的优点:实例在被使用的时候才被创建,可以节省系统资源,体现了延迟加载的思想。
延迟加载:通俗上将就是:一开始的时候不加载资源,一直等到马上就要使用这个资源的时候,躲不过去了才加载,这样可以尽可能的节省系统资源。
懒汉式的缺点:由于系统刚启动时且未被外部调用时,实例没有创建;如果一时间有多个线程同时调用LazySingleton.getLazyInstance()方法很有可能会产生多个实例。
也就是说下面的懒汉式在多线程下,是不能保持单例实例的唯一性的,要想保证多线程下的单例实例的唯一性得用同步,同步会导致多线程下由于争夺锁资源,运行效率不高。
*/
class LazyMode{
//私有化构造方法
private LazyMode(){}
//准备一个私有化字段
private static LazyMode instance = null;
//提供一个共有的可访问的方法 返回该类对象
public static LazyMode getInstance(){
if(instance==null){
instance = new LazyMode();
}
return instance;
}
}
/*
饥汉式:顾名思义懒汉式就是应用刚启动的时候,不管外部有没有调用该类的实例方法,该类的实例就已经创建好了。以空间换时间。
饥汉式的优点:写法简单,在多线程下也能保证单例实例的唯一性,不用同步,运行效率高。
饥汉式的缺点:在外部没有使用到该类的时候,该类的实例就创建了,若该类实例的创建比较消耗系统资源,并且外部一直没有调用该实例,那么这部分的系统资源的消耗是没有意义的。
*/
//饿汉模式
class Hungry{
//私有化构造方法
private Hungry(){}
//准备一个私有化字段
private static Hungry instance = new Hungry();
//提供一个方法 返回该类对象
public static Hungry getInstance(){
return instance;
}
}
4.适配器模式
- 定义: 作为两个不兼容的接口之间的桥梁,将一个类的接口(Adaptee),通过适配器(Adapter)转换成客户期望的另一个目标接口(Target)
5.代理模式
引用:https://www.imooc.com/video/4999
CSDN https://blog.csdn.net/fanrenxiang/article/details/81939357
1)静态代理:
静态代理的代理对象和被代理对象在代理之前就已经确定,它们都实现相同的接口或继承相同的抽象类。
聚合优于继承,可以适应代理执行顺序变换的场景
2)动态代理:jdk动态代理()——接口、cglib动态代理 --不要接口
AOP底层实现就是动态代理
JDK动态代理
jdk动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用业务方法前调用InvocationHandler处理。代理类必须实现InvocationHandler接口,并且,JDK动态代理只能代理实现了接口的类,没有实现接口的类是不能实现JDK动态代理。结合下面代码来看就比较清晰了
使用JDK动态代理类基本步骤:
1、编写需要被代理的类和接口(我这里就是OrderServiceImpl、OrderService);
2、编写代理类(例如我这里的DynamicLogProxy),需要实现InvocationHandler接口,重写invoke方法;
3、使用Proxy.newProxyInstance(ClassLoader loader,Class[] interfaces,InvocationHandler h)动态创建代理类对象,通过代理类对象调用业务方法。
Cglib动态代理
cglib是针对类来实现代理的,它会对目标类产生一个代理子类,通过方法拦截技术对过滤父类的方法调用。代理子类需要实现MethodInterceptor接口。另外,如果你是基于Spring配置文件形式开发,那你需要显示声明:
org.springframework
spring-core
4.1.0.RELEASE
6.装饰者模式(Decorator Pattern)
-
装饰器(Decorator) 装饰 组件(Component), 通过装饰,在原有对象的基础上得到了一个新的具有更多属性和行为的对象,
动态地将行为附加到对象上 提供了比继承更具有弹性的替代方案。 -
在装饰者模式中,存在两个角色:组件(Component) 和 装饰器(Decorator),并且两者要实现相同的接口或抽象类(实现接口或继承抽象类都行),这样就可以使用装饰器来装饰组件了。现实生活中有很多这样的例子,比如购买手机时,一个裸机就算是一个组件,如果想要装饰下手机,加个手机套,贴个膜,送支手写笔等,这些就是装饰器.
原文链接:https://blog.csdn.net/TTCCAAA/article/details/50458633
三个装饰器(新属性、行为),可以分别装饰安卓手机和苹果手机
public abstract class Phones {
String description="nothing";
public String getDescription(){
return description;
}
}
-----------
public class AndroidPhone extends Phones {
public AndroidPhone(){
description="Android 手机";
}
}
----------
public class iOSPhone extends Phones {
public iOSPhone(){
description="iOS 手机";
}
}
------------
public abstract class PhoneAccessory extends Phones {
//装饰者基类
public abstract String getDescription();
}
-----------------
public class PhoneCover extends PhoneAccessory{
private Phones phone;
//手机壳装饰
public PhoneCover(Phones p){
this.phone=p;
}
@Override
public String getDescription() {
return this.phone.getDescription()+" 加了个保护套";
}
}
--------------
public class PhoneMembrane extends PhoneAccessory {
private Phones phones;
//手机膜装饰
public PhoneMembrane(Phones p){
this.phones=p;
}
@Override
public String getDescription() {
return this.phones.getDescription()+" 贴了个膜";
}
}
————————————————
public class PhonePen extends PhoneAccessory{
private Phones phone;
//手写笔装饰
public PhonePen(Phones p){
this.phone=p;
}
@Override
public String getDescription() {
return this.phone.getDescription()+" 送了支手写笔";
}
}
————————————————
public class MainTest {
public static void main(String[] args) {
Phones phone = new AndroidPhone();
System.out.println(phone.getDescription());
PhoneCover coverPhone = new PhoneCover(phone);
System.out.println(coverPhone.getDescription());
PhoneMembrane membranePhone = new PhoneMembrane(coverPhone);
System.out.println(membranePhone.getDescription());
PhonePen penPhone = new PhonePen(membranePhone);
System.out.println(penPhone.getDescription());
}
}
————输出。。。

6. 观察者模式
- 引用:https://blog.csdn.net/TTCCAAA/article/details/50429901
观察者模式:(观察-监听模式、发布订阅模式)(行为型模式:主要关注对象间的通讯)
主要关注的是对象的一对多关系,也就是多个对象都依赖一个对象,当该对象的状态发生改变时,其他对象都能收到相应的通知。
观察者:Tom 和 Jerry (用户)
被观察者:报社 DailyNews
- 模拟 当被观察者改变状态时,它的所有观察者都会收到通知并更新,取消订阅不再接受消息。
报刊订阅实例,报社DailyNews ,Tom 和 Jerry 都订阅服务,每当有最新消息到来,报社就会通知他们,接着 Tom 取消了这个服务,则报社的最新消息不会通知 Tom 而只通知 Jerry。在这个过程中,DailyNews 报社扮演被观察者角色,Tom 和 Jerry 两个用户扮演观察者角色。
用户抽象接口,实现两个用户实体类
报社观察方法接口:NewsPaper, 注册观察者,删除观察者,通知观察者的功能
报社实体类:DailyNews implements NewsPaper
抽象主题(Subject):也就是抽象被观察者接口,提供增加删除和通知观察者的方法
抽象观察者(Observer):观察者接口,提供更新的方法
具体主题(ConcreteSubject):实现抽象主题接口,因此具有增加删除通知观察者的方法,
具体观察者(COncreteObserver):实现抽象观察者接口,注册具体主题后就可以接收到通知更新
————————————————
原文链接:https://blog.csdn.net/TTCCAAA/article/details/50429901
8.RestFul风格
- REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
RESTFUL特点包括:
1、每一个URI代表1种资源;
2、客户端使用GET、POST、PUT、DELETE4个表示操作方式的动词对服务端资源进行操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源;
3、通过操作资源的表现形式来操作资源;
4、资源的表现形式是XML或者HTML;
5、客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息。
RESTful架构
-
RESTful架构是对MVC架构改进后所形成的一种架构,通过使用事先定义好的接口与不同的服务联系起来。在RESTful架构中,浏览器使用POST,DELETE,PUT和GET四种请求方式分别对指定的URL资源进行增删改查操作。因此,RESTful是通过URI实现对资源的管理及访问,具有扩展性强、结构清晰的特点。
-
RESTful架构将服务器分成前端服务器和后端服务器两部分,前端服务器为用户提供无模型的视图;后端服务器为前端服务器提供接口。浏览器向前端服务器请求视图,通过视图中包含的AJAX函数发起接口请求获取模型。
-
项目开发引入RESTful架构,利于团队并行开发。在RESTful架构中,将多数HTTP请求转移到前端服务器上,降低服务器的负荷,使视图获取后端模型失败也能呈现。但RESTful架构却不适用于所有的项目,当项目比较小时无需使用RESTful架构,项目变得更加复杂。 [4
三次握手和四次挥手
--------3
第一次握手:
客户端向服务器发出连接请求报文,这个是三次握手中的开始。表示客户端想要和服务端建立连接;
第二次握手:
TCP服务器收到请求报文后,如果同意连接,则发出确认报文。询问客户端是否准备好;
第三次握手:
TCP客户进程收到确认后,还要向服务器给出确认。这里客户端表示我已经准备好;
--------4
第一次挥手:TCP发送一个FIN(结束),用来关闭客户到服务端的连接; 客户端向服务器发结束消息
第二次挥手:服务端收到这个FIN,他发回一个ACK(确认); 服务器收到这个消息,回来个确认收到
第三次挥手:服务端发送一个FIN(结束)到客户端,服务端关闭客户端的连接; 服务器向客户端发生结束消息
第四次挥手:客户端发送ACK(确认)报文确认,并将确认的序号+1,这样关闭完成; 客户端收到消息
TCP和UDP
- TCP,UDP区别
1. 首先它们都是传输层的协议;
2. TCP是可靠传输协议,是面向连接(双向连接)的,基于流的传输控制协议;
3. UDP是不可靠的协议,是无连接的,基于数据包的 用户数据报协议;
4. TCP传输数据都需要先建立连接,所以传输效率比较低,但是安全;
5. UDP虽然是不可靠传输协议,但是传输数据效率高;
- TCP/IP如何保证可靠性,数据包有哪些数据组成
1. 当客户和服务器彼此交互数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据,TCP 协议使用超时重传(断点续传)、数据确认等方式来确保数据包被正确地发送至目的端;
2. 数据包由起始行、消息头、实体内容组成,又分为请求数据包和响应数据包;
https://blog.csdn.net/Shawei_/article/details/81741817
数据结构
- 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成 。
常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表等,如图所示:
栈
-
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出,或者说是后进先出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。
-
栈的结构就像一个集装箱,越先放进去的东西越晚才能拿出来(放碗),所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列。
-
使用场景:因为队列先进先出的特点,在多线程阻塞队列管理中非常适用。
队列
队列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。从一端放入元素的操作称为入队,取出元素为出队
Ajax – 异步的js和xml
作用:1.提高用户体验,效率高 2.较少服务器与浏览器之间的数据传输
实质:通过浏览器的ajax对象发送异步请求
3.学习ajax其实是学习使用浏览器的ajax(XMLHttpRequest对象)对象发异步请求,将响应的数据局部更新到页面;
- 同步:你先做完我再做,后一步的操作必须要等待前一步操作的结果
- 异步:各做各的相互不干扰(效率高)
1.获取ajax对象,ajax没有标准化,需要区分浏览器
XMLHttpRequest ActiveX
2.发快递:
发送快递的单位(申通,韵达,顺丰) – ajax
准备快递(地址,电话) – open(“get”,“url?id=1”)
发送快递 – send(null)
给一个回执单 – xhr.onreadystate = function(){
//接收服务器响应的数据
3.使用ajax发送get请求:
4.使用ajax发送post请求:
function getRandomData(){
var name = “tom”;
var xhr =getXhr(); //1.获取ajax对象
xhr.open(“post”,“ajaxPost”); //2.准备发送请求
xhr.setRequestHeader(“content-type”,“application/x-www-form-urlencoded”);//如果要提交数据才设置
xhr.send(“username=”+name); //3.发送请求
xhr.onreadystatechange = function(){ //4.设置回调函数
if(xhr.readyState==4 && xhr.status == 200){
alert(xhr.responseText);//接收服务器响应的数据
}
}
}
5.ie缓冲问题:
- 在ie浏览器中发送get请求的时候,如果你发送的请求地址是一样的话,它会将之前你访问过的页面直接返回给你,就不会请求服务器了
解决:1.发送post 2.欺骗浏览器
事务(本地-分布式)
事务ACID
原子性(Atomicity) : 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency): 针对一个事务操作前与操作后的状态一致。
隔离性(Isolation) : 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability) : 表示事务结束后的数据不随着外界原因导致数据丢失。(事务结束数据保存到库)
- 脏读:指一个事务读取了另外一个事务未提交的数据。
- 幻读:是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
(一般是行影响,多了一行) - 不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
四种-隔离级别设置
-
数据库
set transaction isolation level 设置事务隔离级别
select @@tx_isolation 查询当前事务隔离级别
设置 描述
Serializable 可避免脏读、不可重复读、虚读情况的发生。(串行化)
Repeatable read 可避免脏读、不可重复读情况的发生。(可重复读)
Read committed 可避免脏读情况发生(读已提交)。
Read uncommitted 最低级别,以上情况均无法保证。(读未提交)
————————————————
原文链接:https://blog.csdn.net/dengjili/article/details/82468576
- java
适当的 Connection 方法,比如 setAutoCommit 或 setTransactionIsolation
设置 描述
TRANSACTION_SERIALIZABLE 指示不可以发生脏读、不可重复读和虚读的常量。
TRANSACTION_REPEATABLE_READ 指示不可以发生脏读和不可重复读的常量;虚读可以发生。
TRANSACTION_READ_UNCOMMITTED 指示可以发生脏读 (dirty read)、不可重复读和虚读 (phantom read) 的常量。
TRANSACTION_READ_COMMITTED 指示不可以发生脏读的常量;不可重复读和虚读可以发生。
事务的-传播机制
REQUIRED(默认):支持使用当前事务,如果当前事务不存在,创建一个新事务。 required
SUPPORTS:支持使用当前事务,如果当前事务不存在,则不使用事务。 supports
MANDATORY:中文翻译为强制,支持使用当前事务,如果当前事务不存在,则抛出Exception。 mandatory
REQUIRES_NEW:创建一个新事务,如果当前事务存在,把当前事务挂起。 requires_new
NOT_SUPPORTED:无事务执行,如果当前事务存在,把当前事务挂起。 not_supported
NEVER:无事务执行,如果当前有事务则抛出Exception。 nested
NESTED:嵌套事务,如果当前事务存在,那么在嵌套的事务中执行。如果当前事务不存在,则表现跟REQUIRED一样。
————————————————
原文链接:https://blog.csdn.net/u011305680/article/details/79206408
注解方式:
- @Transactional只能被应用到public方法上,对于其它非public的方法,如果标记了@Transactional也不会报错,但方法没有事务功能.
默认情况下,一个有事务方法, 遇到RuntimeException 时会回滚 . 遇到 受检查的异常 是不会回滚 的. 要想所有异常都回滚,要加上 @Transactional( rollbackFor={Exception.class,其它异常})
————————————————
原文链接:https://blog.csdn.net/weixin_37934748/article/details/82774230
————————————————
版权声明:本文为CSDN博主「share_happy_life」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_37934748/article/details/82774230
分布式事务
事务保持一致。
可用性:对数据修改后立马响应不能延迟。
IO同步阻塞NIO异步阻塞
I/0 操作 主要分成两部分
① 数据准备,将数据加载到内核缓存(数据加载到操作系统)
② 将内核缓存中的数据加载到用户缓存(从操作系统复制到应用中)
同步和异步的概念描述的是用户线程与内核的交互方式
阻塞和非阻塞的概念描述的是用户线程调用内核IO操作的方式
同步阻塞IO:用户线程在内核进行IO操作时被阻塞
同步非阻塞IO:是在同步阻塞IO的基础上,将socket设置为NIO(NONBLOCK)。
拦截器和过滤器
拦截器
一个拦截器对象可以多次调用,拦截Controller请求,对直接访问静态请求的资源不做拦截
- 登录验证,没有登录就返回登录页面
过滤器
- 使用过滤器的目的是用来做一些过滤操作,获取我们想要获取的数据,比如:在过滤器中修改字符编码;在过滤器中修改HttpServletRequest的一些参数,包括:过滤低俗文字、危险字符等
过滤器和拦截器的区别:
①拦截器是基于java的反射机制的,过滤器是基于函数回调。
②拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
③拦截器只能对action请求起作用,过滤器则可以对几乎所有的请求起作用。
④拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
⑤在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。
⑥拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。
抽象类和接口
- 抽象
当父类的某些方法不确定时,可以用 abstract 关键字来修饰该方法[抽象方法],用 abstract 来修饰该类[抽象类]。
抽象类
- 抽象类:含有抽象方法的类叫做抽象类,用 abstract 关键字修饰。
抽象类不能被实例化(但是类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样),只有被继承时才可以被使用。
- 抽象方法
抽象方法:在类中没有方法体的方法,就是抽象方法,用 abstract 关键字修饰。
抽象方法只需要声明,不能有方法体,不需要实现某些功能,但是必须被重写。
从形态上看
抽象类可以给出一些成员的实现,接口却不包含成员的实现;
抽象类的抽象成员可被子类部分实现,接口的成员需要实现类完全实现,一个类只能继承一个抽象类,但可实现多个接口等等。
如何区分
类是对对象的抽象,抽象类是对类的抽象;
接口是对行为的抽象。
若行为跨越不同类的对象,可使用接口;
对于一些相似的类对象,用继承抽象类。
抽象类是从子类中发现了公共的东西,泛化出父类,然后子类继承父类;
接口是根本不知子类的存在,方法如何实现还不确认,预先定义。
Git和Svn
一般使用:https://blog.csdn.net/weixin_33739627/article/details/88726460
-
Git分布式版本控制
-
Svn集中式版本控制
Git优点
1.适合分布式开发,强调个体
2.公共服务器压力不会太大
3.速度快,灵活,能离线工作(添加代码能add,commit到本地仓库,有网在推到中央仓库)
Svn优点
1.代码一致性高
2.集中式服务器更安全,权限分配
3.适合开发人数不多的项目
----------------------------
缺点 要网
反射
- https://blog.csdn.net/liujiahan629629/article/details/18013523?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
IO和NIO
1.讲讲你理解的 nio和 bio 的区别是啥,谈谈 reactor 模型。
- IO(BIO)是面向流的,NIO是面向缓冲区的
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
原文链接:https://blog.csdn.net/weixin_43495390/article/details/86533482
同步和异步
-
同步
方法执行后需要等待(在店铺买手机,没货,叫等待一会去仓库拿)
就是调用某个东西是,调用方得等待这个调用返回结果才能继续往后执行
-
异步
方法执行后不需要等待,可以处理其他事情。(在网上买手机,下单后就不管了,快递到了再取。中间可以做其他事情)
和同步相反 调用方不会理解得到结果,而是在调用发出后调用者可用继续执行后续操作,被调用者通过状体来通知调用者,或者通过回掉函数来处理这个调用
同步方法调用一旦开始,调用者必须等到方法调用返回后,才能继续后续的行为。
异步方法调用更像一个消息传递,一旦开始,方法调用就会立即返回,调用者就可以继续后续的操作。而,异步方法通常会在另外一个线程中,“真实”地执行着。整个过程,不会阻碍调用者的工作
阻塞和非阻塞 强调的是程序在等待调用结果(消息,返回值)时的状态. 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。 对于同步调用来说,很多时候当前线程还是激活的状态,只是从逻辑上当前函数没有返回而已,即同步等待时什么都不干,白白占用着资源。
同步和异步强调的是消息通信机制 (synchronous communication/ asynchronous communication)。所谓同步,就是在发出一个"调用"时,在没有得到结果之前,该“调用”就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由“调用者”主动等待这个“调用”的结果。而异步则是相反,"调用"在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在"调用"发出后,"被调用者"通过状态、通知来通知调用者,或通过回调函数处理这个调用
参考博客:https://blog.csdn.net/huangqiang1363/article/details/79508852
深拷贝和浅拷贝
- 假设B复制了A,当修改A时,看B是否会发生变化,如果B也跟着变了,说明这是浅拷贝,拿人手短,如果B没变,那就是深拷贝,自食其力。
https://www.jianshu.com/p/55d3e1b3afab
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WcqonIL1-1585889807519)(…/images/2302117437.bmp)]
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
- Markdown
- Text-to- HTML conversion tool
- Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
mermaid语法说明 ↩︎
注脚的解释 ↩︎