MNN - 端侧推理引擎面临的挑战与应对
![]()
MNN(Mobile Neural Network)已于今年5月7日在 Github 上正式开源。淘宝无线开发专家——陈以鎏(离青)在 GMTC 全球大前端技术大会为大家分享了 MNN 开发、开源中的思考与总结,通过淘宝在移动AI 上的实践经验,你将会了解移动 AI 的发展状况和应用场景,以及通过端侧推理引擎了解移动/IoT深度优化策略。
![]()

淘宝无线开发专家——离青
开源与背景
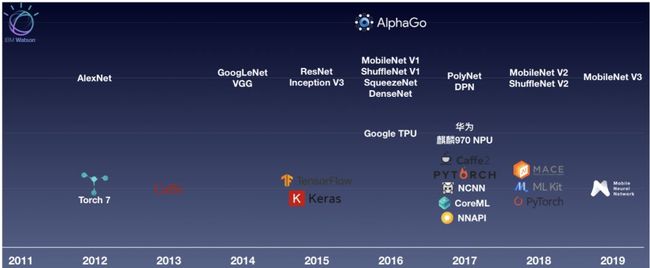
人工智能从 2006 年开始,迎来了第三次浪潮。随着 AlphaGo 在 2016 年、 2017 年先后战胜李世石和柯洁,人工智能彻底进入了公众的视野。人工智能大热的背后,是大数据的积累,是深度学习的发展,也是设备算力的提升。与此同时,深度学习的框架也在不断演进 —— 从 Torch、Caffe 到 TensorFlow、PyTorch ,再到更面向移动端的 CoreML、NNAPI、NCNN、MACE 等。淘宝的深度学习推理引擎 MNN 也于 2019 年 5 月宣布开源。

MNN 项目从 2017 年开始启动,在经历一年多的开发迭代并通过了淘宝双十一的考验后,于 2018 年底启动开源计划,在历时小半年的开源改造后,今年 5 月份正式在 Github 开源。
开源首先还是因为经历过双十一之后,我们觉得自己做好了准备,开源有助于我们鞭策自己,把 MNN 做的更好;另一方面,业界的开源方案,不论是 TensorFlow Lite 、 NCNN 还是 Mace ,都给了我们很好的输入和借鉴,我们也希望借着开源,将我们的思考和创新回馈社区。
下文将主要围绕着 MNN ,来介绍淘宝在移动 AI 上的一些实践经验。
挑战与应对

端侧推理引擎面临的挑战中,碎片化是最为显著的,这种碎片化是多层次、多维度的 。
训练框架上, Caffe 、 TensorFlow 、 PyTorch 、 MXNet 在训练模型时都很常用;
计算设备上, CPU 、 GPU 已是主流, NPU 、 TPU 渐渐成为标配, DSP 、 FPGA 在 Io T上也很常见;
算子层面上,众多参数会形成不同的组合,从而对应出不同的优化方式,轻量化和通用化需要取舍;

一款优秀的端侧推理引擎,就需要在这样碎片化的环境下,利用设备有限的资源,尽可能发挥出设备的性能。为此,也需要在转换、调度、执行上加入相应的优化策略。下文,会就其中的部分展开说明。
转换工具
模型优化

在模型优化中,MNN 引入了前端的概念来统一训练框架。不同的前端负责加载不同训练框架的模型,统一转换为 MNN 的模型格式。对于最常用的训练框架 TensorFlow 和 Caffe ,我们提供了独立的前端;其他训练框架,比如 MXNet ,则需要先将模型转换为 ONNX ,再通过 ONNX 前端加载。这里,由于 TensorFlow 的算子颗粒度相比 Caffe 和 ONNX 要更小,我们引入了图优化的模块来对齐算子之间的颗粒度。模型转换之后,会经过优化器优化,包含算子融合、算子替换、布局调整等等。之后,可以选择对浮点模型执行量化压缩。目前模型压缩的模块还没有开源,我们会在完善之后,将相关代码开源。这些步骤都完成之后,会使用 flatbuffer 来保存部署模型。
图优化

这里以 RNN-GRU cell 为例,说明一下图优化。
左图是 RNN-GRU cell 在 TensorBoard 中的可视化描述。它足足包含了 3584 个节点,而每一个节点都代表了一定的数据读写或运算,累积起来的总量非常大。然而,所有这些节点可以打包使用一个大颗粒的算子来替代。这不仅大幅降低了部署模型的大小,还可以在大颗粒算子的实现中聚合大量的计算,避免不必要的数据读写。
右图展示的是一个实际业务模型在图优化前后的性能对比。在华为 P10 、红米 3x 、小米 6 上都有 1 倍左右的性能提升。而如果是双向 GRU ,效果还会更明显。
算子融合

再以 Convolution、Batchnorm、Scale、ReLU 为例说明优化器中的算子融合。
首先融合 Convolution 和 Batchnorm,Convolution 的 weight 等于 weight 乘 alpha ,而 bias 等于 bias 乘 alpha 再加 beta ;而后融合 Convolution 和 Scale ,融合过程和 Batchnorm 类似;最后融合 Convolution 和 ReLU ,在输出结果前,计算激活函数 ReLU 即可。
这样,四个算子就可以合并成一个算子。融合的过程避免了三次 tensor 读写、两次 tensor 乘加。优化效果见右图, MobileNet V1 在小米 5 和华为 P10 上有 20 ~ 40% 的性能提升,效果还是比较明显的。
智能调度
整体设计

在调度上, MNN 将每一类计算设备抽象为一个后端,将算子在特定后端上的实现抽象为执行器。后端负责特定设备上的资源分配和计算调度,执行器负责具体的实现。后端和算子的添加都通过注册表来实现,这是一个双层注册表结构,拓展起来就相对灵活。
调度时,可以为子图选择相应的后端,再由后端创建出相应的执行器,组成管线;也可以为子图选择后端组,实现混合调度。比如,在 GPU 上不宜实现排序算子时,可以回退到 CPU 来执行。
目前, MNN 在 CPU 上实现了 76 个算子, Metal 上有 55 个, OpenGL 覆盖了基础的 CNN 网络, OpenCL 和 Vulkan 分别有 29 和 31 个。
缓存管理

在创建完执行器之后,子图和管线已经就绪。下来,需要计算出所有tensor的形状,在相应的后端上完成内存的分配。而后,在准备执行器时,再为所有的执行器预先在后端上申请好必要的buffer。运行结束后,返回tensor即可。
由于推理所需的所有内存在准备期就已经申请完毕,在后续推理时,如果输入的形状不变,就可以复用tensor和buffer,从而避免频繁地申请、释放内存;只有输入形状改变的时候,才需要从形状计算开始,调整一次内存分配。同时,由于使用后端统一管理缓存,后端内的执行器之间,缓存就可以充分复用的,这就大大减少了内存的需求量。此外,MNN分配内存时,默认按照32位对齐,内存对齐有利于数据读写。
执行优化
数据布局与滑窗卷积

数据布局对性能影响巨大。
先来看一看在 NCHW 的布局下,怎么利用 SIMD 加速 3x3 的 depth-wise 卷积。
首先,读取数据时,需要一次性读取四个 float 作为第一行的数据,后两行的读取也是相似的;此时,读取出的三行数据已经足够计算两列输出,即,可以复用部分数据;而后,为了提高数据复用,会再读取出第四行数据,一次计算两行两列,即,可以引入循环展开;然而,残留的 5~25 和 21~25 亮度眼边界无法利用 SIMD 计算,只能逐一循环读写完成计算;按照这样的方式,就可以相应完成后几个通道的计算。
但是, NCHW 布局下,无法充分利用 SIMD 进行加速,同时,实现优化分支越多,占用包大小也就越多。

再来看一看 NC/4HW4 布局下,利用 SIMD 加速的情况又是怎样的。
这里的 "C/4" 指的是按照 4 个通道对齐的方式重排数据。重排所有输入和权重数据后,每次 SIMD 读写都天然是 4 个通道的输入数据和 4 个通道的权重数据。这样,不论 kernel、stride、dilation 怎么变化,我们都可以简单地使用 for 循环和 SIMD 的一套通用优化完成卷积计算。既不会有边缘数据无法加速的问题,也不会对包大小造成影响。
Winograd

对于对于 KxK 卷积,可以使用 Winograd 算法进一步加速。 MNN 中支持 2x2 到 7x7 的 Winograd 实现。 Winograd 计算时,需要把输出拆分成 NxN 的小块,把输入拆分成 (N+K-1)x(N+K-1) 的小块。这样,问题就可以简化为两个小矩阵的卷积。

再套用 Winograd 的公式,将矩阵间的卷积运算转换为矩阵点乘运算。在这个过程中,除了矩阵点乘外,还引入三个矩阵转换,分别是输入矩阵 d 、权重矩阵 g 和结果矩阵 Y’ 的转换。其中,权重转换时, G 矩阵可以利用中国剩余数定理计算, GgGT 就可以在准备执行器时提前计算;输入转换和输出转换时用到的 A 和 B 矩阵需要根据 N 和 K 计算,我们在代码中内置了几种优化后的组合,所以实际计算时,这两个转换并不需要经过复杂的矩阵乘法。
这样,原来矩阵卷积所需要的 9x4 次乘法计算就可以用矩阵点乘的 4x4 次乘法计算代替。只考虑乘法耗时的话,加速了 2.25 倍。示例中, K=3,N=2 ,但实际使用时,可以选择更大的 N 值,获取高的加速倍数,但也要相应消耗更多的内存。
Strassen

MNN 可能是端侧推理引擎中,第一个应用 Strassen 算法优化矩阵乘法的。
Strassen 在计算矩阵乘法时,首先需要将矩阵平均拆分成四个小矩阵。这里使用 a11 ~ a22、b11 ~ b22、c11 ~ c22 代表四个小矩阵,计算过程一共需要8次小矩阵乘法运算。
这里可以引入中间小矩阵, s1 ~ s4、t1 ~ t4、m1 ~ m7、u1 ~ u7 。其中,只有 m1 ~ m7 包含小矩阵乘法,一共 7 次小矩阵乘法运算。而其他的,只包含小矩阵的加减法。也就是说,通过 4 + 4 + 7 次小矩阵加减法,替代了一次小矩阵乘法。
与原来的矩阵乘法相比, Strassen 的时间复杂度从 n 的 3 次方,降低到 n 的 2.81 次方。在矩阵较大时,矩阵乘法远远慢于矩阵加减法,收益就更明显。

在 MNN 中,我们会递归使用 Strassen 。也就是说,递归拆分矩阵。在矩阵足够大时,继续拆分;在矩阵不够大时,使用普通的矩阵算法。这里使用减免的矩阵乘法开销作为收益,使用小矩阵 s 、小矩阵 t 、小矩阵 u 矩阵的加减法开销之和作为代价,收益大于代价时,就可以考虑使用 Strassen 算法。
链路优化

链路优化可以举一个 19 年春节淘宝扫年货的例子。在获得手机相机输入后,每一帧的图像首先需要经过一次预处理,将图片缩放到年货检测模型的输入大小上,然而再经过推理,判定图像有没有年货,如果有,就发放相关权益。这个过程中,图片预处理的耗时也不容忽视。降低这个耗时,就可以帮助我们提升帧率,从而改进用户体验。为此,我们引入了一个轻量级的 2D 图片处理库,可以高效地完成色值变化、色彩空间的转换或者仿射变换等。这样, MNN 的用户就不再需要为图片处理引入 libyuv 或者 opencv 了。
性能比较

经过种种优化后,这是我们在性能上交出的答卷。
MobileNet V2 ,在 OPPO r17 和 iPhone 7Plus 上做了一系列的性能对比。
如图, MNN 的性能在 CPU 和 GPU 上都有一定的优势。
小结

总的来说, MNN 吸纳了前人的经验,也结合自己对端侧推理引擎的认知,做了许多创新。综合考虑性能、模型和后端的拓展性、缓存、 CPU 和 GPU 的算子实现,以及 CV 库等方面的表现,在端侧推理引擎中, MNN 是值得移动 AI 用户尝试的选择。
后续规划

在后续计划上,转换部分,我们计划追加更多算子和更多图优化匹配模板,也计划将模型量化工具开源;调度部分,我们计划分步实现端侧训练和边缘学习,计算设备自动选择也在筹划中;执行部分,还是会持续优化现有各端算子的实现,也计划优化量化卷积、矩阵乘算法,计划在 CV 库上直接支持 GPU ,我们也考虑将现有 NC/4HW4 实现的算法,整理为独立的高性能计算库,算法自动选择同样在筹划中;其他部分,我们会持续建设项目的可用性,持续加入更多的文档和示例。

MNN 开源项目地址
https://github.com/alibaba/mnn
(可点击下方阅读原文)
欢迎大家参与 MNN 开源共建。
One More Thing
淘宝基础平台部-端智能团队欢迎推理引擎研发工程师、AR技术研发工程师、高性能计算研发工程师的加入。对新技术感兴趣,善于创新突破,渴望用新技术给用户带来创新体验的同学请联系我们,简历投递至[email protected]。
相关文章推荐

重磅| 淘宝轻量级的深度学习端侧推理引擎 MNN 开源

点击这里阅读原文