Yolo系列(1)--Yolov1
1. 背景
## Yolov1能够实现端到端的目标
Yolov1用于检测和识别,其最大的优势就是速Yolov是一个实现回归功能的卷积神经网络,其没有过于复杂的结构设计过Yolov1在区分目标和背景区域的效果上要有优与基于区域建议的 RCNN系列算的,它是直接通过整张图片进行训练模型,而没有采用滑动窗口、选择性搜索等方式进行候选框的选择。
2.基本概念
1.BoundingBox(边界框)
边界框的大小和位置用4个值来表示:(x,y,w,h),其中(x, y)是边界框的中心坐标,w和h是边界框的宽与高。具体来说,(x, y)是相对于每个单元格左上角坐标点偏移值,并且单位是相对于单元格大小的,而w和h预测值是相对于整个图片的宽和高的比例,这样理论上4个元素的大小在[0, 1]范围内,而且每个边界框的预测值实际上包含5个元素:(x, y, w, h, c)。前四个元素表征边界框的大小和位置,最后一个值是置信度。
2.Confidence(置信度)
置信度评分S:
S=Pr(O)*Iou
Pr(O)表示当前网格目标边框中存在物体的可能性, O表示目标对象。Iou(IntersectionoverUnion, 交并比)展示了当前模型预测到的目标边框位置的准确性。
3.NMS (非极大值抑制)
def non_max_suppression(prediction, num_classes, conf_thres=0.5, nms_thres=0.4):
# 求左上角和右下角
box_corner = prediction.new(prediction.shape)
box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2
box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2
box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2
box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2
prediction[:, :, :4] = box_corner[:, :, :4]
output = [None for _ in range(len(prediction))]
for image_i, image_pred in enumerate(prediction):
# 利用置信度进行第一轮筛选
conf_mask = (image_pred[:, 4] >= conf_thres).squeeze()
image_pred = image_pred[conf_mask]
if not image_pred.size(0):
continue
# 获得种类及其置信度
class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True)
# 获得的内容为(x1, y1, x2, y2, obj_conf, class_conf, class_pred)
detections = torch.cat((image_pred[:, :5], class_conf.float(), class_pred.float()), 1)
# 获得种类
unique_labels = detections[:, -1].cpu().unique()
if prediction.is_cuda:
unique_labels = unique_labels.cuda()
for c in unique_labels:
# 获得某一类初步筛选后全部的预测结果
detections_class = detections[detections[:, -1] == c]
# 按照存在物体的置信度排序
_, conf_sort_index = torch.sort(detections_class[:, 4], descending=True)
detections_class = detections_class[conf_sort_index]
# 进行非极大抑制
max_detections = []
while detections_class.size(0):
# 取出这一类置信度最高的,一步一步往下判断,判断重合程度是否大于nms_thres,如果是则去除掉
max_detections.append(detections_class[0].unsqueeze(0))
if len(detections_class) == 1:
break
ious = bbox_iou(max_detections[-1], detections_class[1:])
detections_class = detections_class[1:][ious < nms_thres]
# 堆叠
max_detections = torch.cat(max_detections).data
# Add max detections to outputs
output[image_i] = max_detections if output[image_i] is None else torch.cat(
(output[image_i], max_detections))
return output
3.网络结构
Yolov1的网络结构有24个卷积层,其次是2个全连接层。网络架构借Google Net的思想,交替使用 1*1卷积层之后再接一个 3*3的卷积层的结构Inception 结构。 Yolov1网络的结构如图 1.1 所示:
图1.1 Yolov1网络结构图
YOLO的输入层, 是由输入图像经过裁剪、归一化或数据增强等方式处理得到数据。CNN中将样本图像的数据经过某种处理后得到的几何特征称为特征图。输入层可以认为是初始的特征图, 由于目标检测需要更加精细的信息, YOLO统一将处理后的特征图的大小固定为448*448*3。其中448*448为单一维度的图片像素值,由于图片是彩色的, 需要红、绿、蓝三个颜色通道互相叠加而得到。
紧接着的是24个卷积层,主要操作是对输入层处理的特征图进行卷积操作运算, 其实质是提取输入层的特征信息以便后续的分类与定位处理。由图1.1可知, YOLO的卷积核有3*3和1*1两种。其中使用1*1大小的卷积核, 主要考虑到降低卷积核通道数量的需要, 以减少网络产生的参数。存在于卷积层之间的是池化层, 其主要操作是在特征空间内对输入的数据样本进行下采样处理。即根据特征矩阵所处的空间位置,根据设置的粒度块分割特征, 并在小块中计算新的特征值,替换原先块中的信息。依据替换新特征值的规贝!J,下采样操作常见的有均值池化和最大值池化。YOLO算法采用最大值池化法,即使用块中的最大值替换原特征块。
YOLO在最后一个池化层到输出层之间有两个全连接层, 其主要作用是将特征提取出来的二维矩阵转换为一维矩阵。采用将所有输入与网络参数连接运算的方式,是网络中参数最多,运算量最大的一层。网络的最后一层是输出层,相当于一个分类器,将全连接层输出的一维向量进行分类输出,输出的特征图个数就是目标的分类数。该网络最后输出的是一个7*7*30的一维向量, 包含了图片中物体的分类结果以及其位置信息的编码, 最后通过统一约定的方式对该向量进行解码就可以在原图片中绘制出检测结果。
4.损失函数
-
预测框中心损失
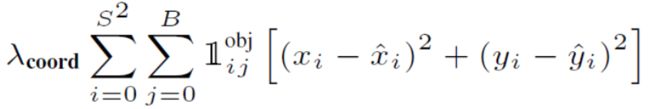
-
预测框宽高损失
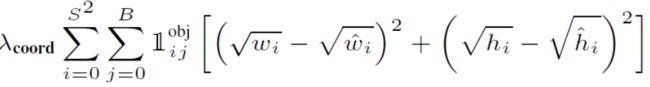
-
预测框判断有物体损失
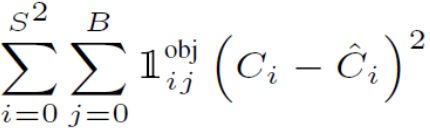
-
预测框判断无物体损失
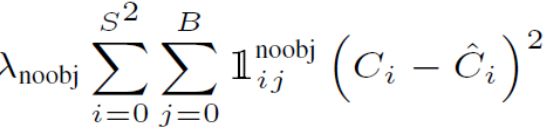
-
预测框置信度损失

总损失为:

5.不足
- Yolov1采用了卷积层、池化层和全连接层的网络设计, 参数数量较为庞大, 训练神经网络的效率相对较低。需要大量标注的图像数据进行训练, 给在特定领域方向的应用带来了一定的困难。
- Yolov1算法对于小物体及密集场景下的检测效果不佳, 整体的检测精度要低于最先进的基于候选区域的深度神经网络算法。