哨兵的状态监测及故障切换代码梳理
redis哨兵代码流程如下图所示
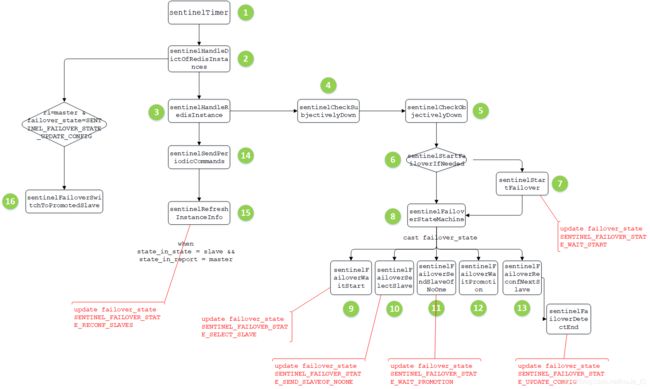
1. sentinelTimer定时任务
sentinelCheckTiltCondition();
sentinelHandleDictOfRedisInstances(sentinel.masters);
sentinelRunPendingScripts();
sentinelCollectTerminatedScripts();
sentinelKillTimedoutScripts();
2. sentinelHandleDictOfRedisInstances
启动对所有监听的master节点的状态判断等任务
void sentinelHandleDictOfRedisInstances(dict *instances) {
dictIterator *di;
dictEntry *de;
sentinelRedisInstance *switch_to_promoted = NULL;
/* There are a number of things we need to perform against every master. */
di = dictGetIterator(instances);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
sentinelHandleRedisInstance(ri);
if (ri->flags & SRI_MASTER) {
sentinelHandleDictOfRedisInstances(ri->slaves);
sentinelHandleDictOfRedisInstances(ri->sentinels);
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
}
}
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
dictReleaseIterator(di);
}
重点
1、 启动对所有redis节点的sentinelHandleRedisInstance任务,详情见3
2、 如果redis节点是主节点 && 发现任务状态是failover-state== SENTINEL_FAILOVER_STATE_UPDATE_CONFIG,表示进行了failover并已经完成,然后进入sentinelFailoverSwitchToPromotedSlave发送switch-master事件,并reset哨兵内的数据记录,详情见16
3. sentinelHandleRedisInstance 开始监听工作
/* ======================== SENTINEL timer handler ==========================
* This is the "main" our Sentinel, being sentinel completely non blocking
* in design. The function is called every second.
* -------------------------------------------------------------------------- */
/* Perform scheduled operations for the specified Redis instance. */
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
/* ========== MONITORING HALF ============ */
/* Every kind of instance */
sentinelReconnectInstance(ri);
sentinelSendPeriodicCommands(ri);
/* ============== ACTING HALF ============= */
/* We don't proceed with the acting half if we are in TILT mode.
* TILT happens when we find something odd with the time, like a
* sudden change in the clock. */
if (sentinel.tilt) {
if (mstime()-sentinel.tilt_start_time < SENTINEL_TILT_PERIOD) return;
sentinel.tilt = 0;
sentinelEvent(LL_WARNING,"-tilt",NULL,"#tilt mode exited");
}
/* Every kind of instance */
sentinelCheckSubjectivelyDown(ri);
/* Masters and slaves */
if (ri->flags & (SRI_MASTER|SRI_SLAVE)) {
/* Nothing so far. */
}
/* Only masters */
if (ri->flags & SRI_MASTER) {
sentinelCheckObjectivelyDown(ri);
if (sentinelStartFailoverIfNeeded(ri))
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
sentinelFailoverStateMachine(ri);
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}
重点
1、 每秒执行一次
2、 启动sentinelSendPeriodicCommands任务,启动对节点的定时任务,详情见14
3、 节点状态监听及可能的故障切换,详情见4
4. sentinelCheckSubjectivelyDown判断sdown
对心跳进行监听,如果sdown,进入odown判断,详情见5
5. 判断odown状态sentinelCheckObjectivelyDown
1、确认odown后,发布odown时间日志
标记master两个属性
master->flags |= SRI_O_DOWN;
master->o_down_since_time = mstime();
确认odown后启动是否failover,详情见6
2、否则-odown,取消标记
6. 判断是否需要failover,sentinelStartFailoverIfNeeded
重点对三个方面进行判断
1、 再次确认是否为odown状态
2、 确认是否已经启动failover_in_progresschulizhong
3、 确认是否和上次的failover时间超过2failover_time_out
mstime() - master->failover_start_time < master->failover_timeout2
如果成立,就会加锁,在上次时间的基础上增加failover_timeout*2的时间
if (mstime() - master->failover_start_time <
master->failover_timeout*2)
{
if (master->failover_delay_logged != master->failover_start_time) {
time_t clock = (master->failover_start_time +
master->failover_timeout*2) / 1000;
char ctimebuf[26];
ctime_r(&clock,ctimebuf);
ctimebuf[24] = '\0'; /* Remove newline. */
master->failover_delay_logged = master->failover_start_time;
serverLog(LL_WARNING,
"Next failover delay: I will not start a failover before %s",
ctimebuf);
}
return 0;
}
如果需要startfailover,进入sentinelStartFailover编辑更新状态,详情见7
7. 标记启动failover sentinelStartFailover
标记failover_state、flags、failover_epoch、failover_start_time
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->flags |= SRI_FAILOVER_IN_PROGRESS;
master->failover_epoch = ++sentinel.current_epoch;
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",
(unsigned long long) sentinel.current_epoch);
sentinelEvent(LL_WARNING,"+try-failover",master,"%@");
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
master->failover_state_change_time = mstime();
重点
1、 标记failover_state= SENTINEL_FAILOVER_STATE_WAIT_START,表示failover的开始
2、 将master-> failover_start_time更新为当前时间
3、 启动新纪元epoch,开始failover
8. 标记完成后进入处理sentinelFailoverStateMachine
首先再次判断是否进入了SRI_FAILOVER_IN_PROGRESS状态
然后开始依次执行任务(当前任务状态“SENTINEL_FAILOVER_STATE_WAIT_START”)
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
重点:
1、 根据failover_state进入不同的处理阶段
2、 每个state处理完成不会进入下一个,而是等待从第一步开始的定时任务在进行下一个
9. sentinelFailoverWaitStart进行sentinel的leader选举
当前任务状态为SENTINEL_FAILOVER_STATE_WAIT_START
char *leader;
int isleader;
/* Check if we are the leader for the failover epoch. */
leader = sentinelGetLeader(ri, ri->failover_epoch);
isleader = leader && strcasecmp(leader,sentinel.myid) == 0;
sdsfree(leader);
/* If I'm not the leader, and it is not a forced failover via
* SENTINEL FAILOVER, then I can't continue with the failover. */
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
int election_timeout = SENTINEL_ELECTION_TIMEOUT;
/* The election timeout is the MIN between SENTINEL_ELECTION_TIMEOUT
* and the configured failover timeout. */
if (election_timeout > ri->failover_timeout)
election_timeout = ri->failover_timeout;
/* Abort the failover if I'm not the leader after some time. */
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
sentinelEvent(LL_WARNING,"+elected-leader",ri,"%@");
if (sentinel.simfailure_flags & SENTINEL_SIMFAILURE_CRASH_AFTER_ELECTION)
sentinelSimFailureCrash();
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_WARNING,"+failover-state-select-slave",ri,"%@");
重点
1、 election_timeout:默认10s,在10s和failover_timeout时间取最小,选举超时放弃
2、 结束后任务状态设置为SENTINEL_FAILOVER_STATE_SELECT_SLAVE
3、 选举leader在方法sentinelGetLeader
4、 更新master->failover_start_time为当前时间
10. sentinelFailoverSelectSlave
当任务状态设置为SENTINEL_FAILOVER_STATE_SELECT_SLAVE,就会开始启动选举新主节点
void sentinelFailoverSelectSlave(sentinelRedisInstance *ri) {
// 选出slave
sentinelRedisInstance *slave = sentinelSelectSlave(ri);
/* We don't handle the timeout in this state as the function aborts
* the failover or go forward in the next state. */
if (slave == NULL) {
sentinelEvent(REDIS_WARNING,"-failover-abort-no-good-slave",ri,"%@");
sentinelAbortFailover(ri);
} else {
// 修改状态为SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE
sentinelEvent(REDIS_WARNING,"+selected-slave",slave,"%@");
slave->flags |= SRI_PROMOTED;
ri->promoted_slave = slave;
ri->failover_state = SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE;
ri->failover_state_change_time = mstime();
sentinelEvent(REDIS_NOTICE,"+failover-state-send-slaveof-noone",
slave, "%@");
}
}
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
sentinelRedisInstance **instance =
zmalloc(sizeof(instance[0])*dictSize(master->slaves));
sentinelRedisInstance *selected = NULL;
int instances = 0;
dictIterator *di;
dictEntry *de;
mstime_t max_master_down_time = 0;
// 计算最长同步延迟
if (master->flags & SRI_S_DOWN)
max_master_down_time += mstime() - master->s_down_since_time;
max_master_down_time += master->down_after_period * 10;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
// 已经断开的slave,直接忽略
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN|SRI_DISCONNECTED)) continue;
// 超过5倍ping间隔的slave也忽略
if (mstime() - slave->last_avail_time > SENTINEL_PING_PERIOD*5) continue;
if (slave->slave_priority == 0) continue;
/* If the master is in SDOWN state we get INFO for slaves every second.
* Otherwise we get it with the usual period so we need to account for
* a larger delay. */
if (master->flags & SRI_S_DOWN)
info_validity_time = SENTINEL_PING_PERIOD*5;
else
info_validity_time = SENTINEL_INFO_PERIOD*3;
// INFO响应超过有效时间,忽略
if (mstime() - slave->info_refresh > info_validity_time) continue;
// 和master断开的时间太长,忽略
if (slave->master_link_down_time > max_master_down_time) continue;
instance[instances++] = slave;
}
dictReleaseIterator(di);
if (instances) {
// 快速排序
qsort(instance,instances,sizeof(sentinelRedisInstance*),
compareSlavesForPromotion);
selected = instance[0];
}
zfree(instance);
return selected;
}
int compareSlavesForPromotion(const void *a, const void *b) {
sentinelRedisInstance **sa = (sentinelRedisInstance **)a,
**sb = (sentinelRedisInstance **)b;
char *sa_runid, *sb_runid;
// 先根据slave优先级排序
if ((*sa)->slave_priority != (*sb)->slave_priority)
return (*sa)->slave_priority - (*sb)->slave_priority;
/* If priority is the same, select the slave with greater replication
* offset (processed more data frmo the master). */
// 优先级相同,根据复制偏移量
if ((*sa)->slave_repl_offset > (*sb)->slave_repl_offset) {
return -1; /* a < b */
} else if ((*sa)->slave_repl_offset < (*sb)->slave_repl_offset) {
return 1; /* b > a */
}
/* If the replication offset is the same select the slave with that has
* the lexicographically smaller runid. Note that we try to handle runid
* == NULL as there are old Redis versions that don't publish runid in
* INFO. A NULL runid is considered bigger than any other runid. */
// 到这里选哪个都无所谓了,按照runid来选择
sa_runid = (*sa)->runid;
sb_runid = (*sb)->runid;
if (sa_runid == NULL && sb_runid == NULL) return 0;
else if (sa_runid == NULL) return 1; /* a > b */
else if (sb_runid == NULL) return -1; /* a < b */
return strcasecmp(sa_runid, sb_runid);
}
重点
1、 删除列表中所有处于下线或者断线状态的slave
2、 删除列表中所有最近五秒内没有回复过领头sentinel的INFO命令的slave
3、 删除所有与已下线主服务器连接断开超过down-after-milliseconds * 10毫秒的slave(确保slave没有过早与master断开,副本比较新)
4、 根据slave优先级选择
5、 如果优先级相同,选择复制偏移量最大的slave
6、 如果都相同,按照run_id排序,选出run_id最小的slave
7、 任务执行完成标记failover_state= SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE
11. sentinelFailoverSendSlaveOfNoOne
对上一步选举的slave执行slaveof no one操作,执行升级为主节点的操作
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
/* We can't send the command to the promoted slave if it is now
* disconnected. Retry again and again with this state until the timeout
* is reached, then abort the failover. */
if (ri->promoted_slave->link->disconnected) {
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
/* Send SLAVEOF NO ONE command to turn the slave into a master.
* We actually register a generic callback for this command as we don't
* really care about the reply. We check if it worked indirectly observing
* if INFO returns a different role (master instead of slave). */
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL,0);
if (retval != C_OK) return;
sentinelEvent(LL_NOTICE, "+failover-state-wait-promotion",
ri->promoted_slave,"%@");
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
ri->failover_state_change_time = mstime();
}
判断是否超时
然后发送命令给从节点,命令slaveof no one
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
/* We can't send the command to the promoted slave if it is now
* disconnected. Retry again and again with this state until the timeout
* is reached, then abort the failover. */
if (ri->promoted_slave->flags & SRI_DISCONNECTED) {
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(REDIS_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
/* Send SLAVEOF NO ONE command to turn the slave into a master.
* We actually register a generic callback for this command as we don't
* really care about the reply. We check if it worked indirectly observing
* if INFO returns a different role (master instead of slave). */
// 发送slaveof no one命令,告知slave成为master
// 由于是否成功通过info命令观察,所以这里发送的时候不关注slaveof的结果
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL,0);
if (retval != REDIS_OK) return;
sentinelEvent(REDIS_NOTICE, "+failover-state-wait-promotion",
ri->promoted_slave,"%@");
// 状态变成SENTINEL_FAILOVER_STATE_WAIT_PROMOTION
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
ri->failover_state_change_time = mstime();
}
int sentinelSendSlaveOf(sentinelRedisInstance *ri, char *host, int port) {
char portstr[32];
int retval;
ll2string(portstr,sizeof(portstr),port);
/* If host is NULL we send SLAVEOF NO ONE that will turn the instance
* into a master. */
if (host == NULL) {
host = "NO";
memcpy(portstr,"ONE",4);
}
/* In order to send SLAVEOF in a safe way, we send a transaction performing
* the following tasks:
* 1) Reconfigure the instance according to the specified host/port params.
* 2) Rewrite the configuration.
* 3) Disconnect all clients (but this one sending the commnad) in order
* to trigger the ask-master-on-reconnection protocol for connected
* clients.
*
* Note that we don't check the replies returned by commands, since we
* will observe instead the effects in the next INFO output. */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"MULTI"));
if (retval == C_ERR) return retval;
ri->link->pending_commands++;
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s %s %s",
sentinelInstanceMapCommand(ri,"SLAVEOF"),
host, portstr);
if (retval == C_ERR) return retval;
ri->link->pending_commands++;
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s REWRITE",
sentinelInstanceMapCommand(ri,"CONFIG"));
if (retval == C_ERR) return retval;
ri->link->pending_commands++;
/* CLIENT KILL TYPE is only supported starting from Redis 2.8.12,
* however sending it to an instance not understanding this command is not
* an issue because CLIENT is variadic command, so Redis will not
* recognized as a syntax error, and the transaction will not fail (but
* only the unsupported command will fail). */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s KILL TYPE normal",
sentinelInstanceMapCommand(ri,"CLIENT"));
if (retval == C_ERR) return retval;
ri->link->pending_commands++;
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"EXEC"));
if (retval == C_ERR) return retval;
ri->link->pending_commands++;
return C_OK;
}
会启动五个异步任务,发送命令通过事务去做
1、 提交事务
2、 执行slaveof no one
3、 执行rewrite将当前配置信息写入配置文件
4、 停止客户端连接
5、 执行2-4的事务操作
标记failover_state= SENTINEL_FAILOVER_STATE_WAIT_PROMOTION,等待查询成功升级为master
在异步任务的同时,会启动sentinelDiscardReplyCallback
12. sentinelFailoverWaitPromotion
重点
1、 仅仅判断一下是否超时判断
2、 当前failover_state= SENTINEL_FAILOVER_STATE_WAIT_PROMOTION
3、 对slave no one的执行结果以及修改failover_state,是根据环节3启动的sentinelSendPeriodicCommands中的定时任务判断,详情见14
13. sentinelFailoverReconfNextSlave
在failover_state= SENTINEL_FAILOVER_STATE_RECONF_SLAVES时,对其余的从节点进行slaveof new_redis_ip new_redis_port操作,建立主从关系
void sentinelFailoverReconfNextSlave(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
int in_progress = 0;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG))
in_progress++;
}
dictReleaseIterator(di);
di = dictGetIterator(master->slaves);
while(in_progress < master->parallel_syncs &&
(de = dictNext(di)) != NULL)
{
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
/* Skip the promoted slave, and already configured slaves. */
if (slave->flags & (SRI_PROMOTED|SRI_RECONF_DONE)) continue;
/* If too much time elapsed without the slave moving forward to
* the next state, consider it reconfigured even if it is not.
* Sentinels will detect the slave as misconfigured and fix its
* configuration later. */
if ((slave->flags & SRI_RECONF_SENT) &&
(mstime() - slave->slave_reconf_sent_time) >
SENTINEL_SLAVE_RECONF_TIMEOUT)
{
sentinelEvent(LL_NOTICE,"-slave-reconf-sent-timeout",slave,"%@");
slave->flags &= ~SRI_RECONF_SENT;
slave->flags |= SRI_RECONF_DONE;
}
/* Nothing to do for instances that are disconnected or already
* in RECONF_SENT state. */
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)) continue;
if (slave->link->disconnected) continue;
/* Send SLAVEOF . */
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == C_OK) {
slave->flags |= SRI_RECONF_SENT;
slave->slave_reconf_sent_time = mstime();
sentinelEvent(LL_NOTICE,"+slave-reconf-sent",slave,"%@");
in_progress++;
}
}
dictReleaseIterator(di);
/* Check if all the slaves are reconfigured and handle timeout. */
sentinelFailoverDetectEnd(master);
}
并核查是否完成配置
void sentinelFailoverDetectEnd(sentinelRedisInstance *master) {
int not_reconfigured = 0, timeout = 0;
dictIterator *di;
dictEntry *de;
mstime_t elapsed = mstime() - master->failover_state_change_time;
/* We can't consider failover finished if the promoted slave is
* not reachable. */
if (master->promoted_slave == NULL ||
master->promoted_slave->flags & SRI_S_DOWN) return;
/* The failover terminates once all the reachable slaves are properly
* configured. */
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_PROMOTED|SRI_RECONF_DONE)) continue;
if (slave->flags & SRI_S_DOWN) continue;
not_reconfigured++;
}
dictReleaseIterator(di);
/* Force end of failover on timeout. */
if (elapsed > master->failover_timeout) {
not_reconfigured = 0;
timeout = 1;
sentinelEvent(LL_WARNING,"+failover-end-for-timeout",master,"%@");
}
if (not_reconfigured == 0) {
sentinelEvent(LL_WARNING,"+failover-end",master,"%@");
master->failover_state = SENTINEL_FAILOVER_STATE_UPDATE_CONFIG;
master->failover_state_change_time = mstime();
}
/* If I'm the leader it is a good idea to send a best effort SLAVEOF
* command to all the slaves still not reconfigured to replicate with
* the new master. */
if (timeout) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
if (slave->flags & (SRI_RECONF_DONE|SRI_RECONF_SENT)) continue;
if (slave->link->disconnected) continue;
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == C_OK) {
sentinelEvent(LL_NOTICE,"+slave-reconf-sent-be",slave,"%@");
slave->flags |= SRI_RECONF_SENT;
}
}
dictReleaseIterator(di);
}
}
重点
1、 异步完成对所有其他的从节点执行slaveof命令建立主从关系
2、 完成后通过sentinelFailoverDetectEnd对执行结果进行判断
3、 如果配置更新成功,这里就会将任务状态设置为SENTINEL_FAILOVER_STATE_UPDATE_CONFIG,等待定时任务更新,当failover_state为该状态时表示failover完成,等待环节2判断后进行环节16,详情见16
4、
14. sentinelSendPeriodicCommands(ri)
此由环节3触发,启动对对应节点的ping、info等定时任务(ping,info)
ainelSendPeriodicCommands(sentinelRedisInstance *ri) {
/* Send INFO to masters and slaves, not sentinels. */
if ((ri->flags & SRI_SENTINEL) == 0 &&
(ri->info_refresh == 0 ||
(now - ri->info_refresh) > info_period))
{
retval = redisAsyncCommand(ri->link->cc,
sentinelInfoReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"INFO"));
if (retval == C_OK) ri->link->pending_commands++;
}
/* Send PING to all the three kinds of instances. */
if ((now - ri->link->last_pong_time) > ping_period &&
(now - ri->link->last_ping_time) > ping_period/2) {
sentinelSendPing(ri);
}
/* PUBLISH hello messages to all the three kinds of instances. */
if ((now - ri->last_pub_time) > SENTINEL_PUBLISH_PERIOD) {
sentinelSendHello(ri);
}
在执行info获取对应节点的信息时会启动redisAsyncCommand,在执行异步任务时,将返回信息进入到sentinelInfoReplyCallback进行处理
void sentinelInfoReplyCallback(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *ri = privdata;
instanceLink *link = c->data;
redisReply *r;
if (!reply || !link) return;
link->pending_commands--;
r = reply;
if (r->type == REDIS_REPLY_STRING)
sentinelRefreshInstanceInfo(ri,r->str);
}
sentinelInfoReplyCallback在判断reply有效后会refresh哨兵节点记录的该节点的状态信息,详情见环节15
15. sentinelRefreshInstanceInfo
/* Process the INFO output from masters. */
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
sds *lines;
int numlines, j;
int role = 0;
/* cache full INFO output for instance */
sdsfree(ri->info);
ri->info = sdsnew(info);
/* The following fields must be reset to a given value in the case they
* are not found at all in the INFO output. */
ri->master_link_down_time = 0;
/* Process line by line. */
lines = sdssplitlen(info,strlen(info),"\r\n",2,&numlines);
for (j = 0; j < numlines; j++) {
sentinelRedisInstance *slave;
sds l = lines[j];
/* run_id:<40 hex chars>*/
if (sdslen(l) >= 47 && !memcmp(l,"run_id:",7)) {
if (ri->runid == NULL) {
ri->runid = sdsnewlen(l+7,40);
} else {
if (strncmp(ri->runid,l+7,40) != 0) {
sentinelEvent(LL_NOTICE,"+reboot",ri,"%@");
sdsfree(ri->runid);
ri->runid = sdsnewlen(l+7,40);
}
}
}
/* old versions: slave0:,,
* new versions: slave0:ip=127.0.0.1,port=9999,... */
if ((ri->flags & SRI_MASTER) &&
sdslen(l) >= 7 &&
!memcmp(l,"slave",5) && isdigit(l[5]))
{
char *ip, *port, *end;
if (strstr(l,"ip=") == NULL) {
/* Old format. */
ip = strchr(l,':'); if (!ip) continue;
ip++; /* Now ip points to start of ip address. */
port = strchr(ip,','); if (!port) continue;
*port = '\0'; /* nul term for easy access. */
port++; /* Now port points to start of port number. */
end = strchr(port,','); if (!end) continue;
*end = '\0'; /* nul term for easy access. */
} else {
/* New format. */
ip = strstr(l,"ip="); if (!ip) continue;
ip += 3; /* Now ip points to start of ip address. */
port = strstr(l,"port="); if (!port) continue;
port += 5; /* Now port points to start of port number. */
/* Nul term both fields for easy access. */
end = strchr(ip,','); if (end) *end = '\0';
end = strchr(port,','); if (end) *end = '\0';
}
/* Check if we already have this slave into our table,
* otherwise add it. */
if (sentinelRedisInstanceLookupSlave(ri,ip,atoi(port)) == NULL) {
if ((slave = createSentinelRedisInstance(NULL,SRI_SLAVE,ip,
atoi(port), ri->quorum, ri)) != NULL)
{
sentinelEvent(LL_NOTICE,"+slave",slave,"%@");
sentinelFlushConfig();
}
}
}
/* master_link_down_since_seconds: */
if (sdslen(l) >= 32 &&
!memcmp(l,"master_link_down_since_seconds",30))
{
ri->master_link_down_time = strtoll(l+31,NULL,10)*1000;
}
/* role: */
if (!memcmp(l,"role:master",11)) role = SRI_MASTER;
else if (!memcmp(l,"role:slave",10)) role = SRI_SLAVE;
if (role == SRI_SLAVE) {
/* master_host: */
if (sdslen(l) >= 12 && !memcmp(l,"master_host:",12)) {
if (ri->slave_master_host == NULL ||
strcasecmp(l+12,ri->slave_master_host))
{
sdsfree(ri->slave_master_host);
ri->slave_master_host = sdsnew(l+12);
ri->slave_conf_change_time = mstime();
}
}
/* master_port: */
if (sdslen(l) >= 12 && !memcmp(l,"master_port:",12)) {
int slave_master_port = atoi(l+12);
if (ri->slave_master_port != slave_master_port) {
ri->slave_master_port = slave_master_port;
ri->slave_conf_change_time = mstime();
}
}
/* master_link_status: */
if (sdslen(l) >= 19 && !memcmp(l,"master_link_status:",19)) {
ri->slave_master_link_status =
(strcasecmp(l+19,"up") == 0) ?
SENTINEL_MASTER_LINK_STATUS_UP :
SENTINEL_MASTER_LINK_STATUS_DOWN;
}
/* slave_priority: */
if (sdslen(l) >= 15 && !memcmp(l,"slave_priority:",15))
ri->slave_priority = atoi(l+15);
/* slave_repl_offset: */
if (sdslen(l) >= 18 && !memcmp(l,"slave_repl_offset:",18))
ri->slave_repl_offset = strtoull(l+18,NULL,10);
}
}
ri->info_refresh = mstime();
sdsfreesplitres(lines,numlines);
/* ---------------------------- Acting half -----------------------------
* Some things will not happen if sentinel.tilt is true, but some will
* still be processed. */
/* Remember when the role changed. */
if (role != ri->role_reported) {
ri->role_reported_time = mstime();
ri->role_reported = role;
if (role == SRI_SLAVE) ri->slave_conf_change_time = mstime();
/* Log the event with +role-change if the new role is coherent or
* with -role-change if there is a mismatch with the current config. */
sentinelEvent(LL_VERBOSE,
((ri->flags & (SRI_MASTER|SRI_SLAVE)) == role) ?
"+role-change" : "-role-change",
ri, "%@ new reported role is %s",
role == SRI_MASTER ? "master" : "slave",
ri->flags & SRI_MASTER ? "master" : "slave");
}
/* None of the following conditions are processed when in tilt mode, so
* return asap. */
if (sentinel.tilt) return;
/* Handle master -> slave role switch. */
if ((ri->flags & SRI_MASTER) && role == SRI_SLAVE) {
/* Nothing to do, but masters claiming to be slaves are
* considered to be unreachable by Sentinel, so eventually
* a failover will be triggered. */
}
/* Handle slave -> master role switch. */
if ((ri->flags & SRI_SLAVE) && role == SRI_MASTER) {
/* If this is a promoted slave we can change state to the
* failover state machine. */
if ((ri->flags & SRI_PROMOTED) &&
(ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state ==
SENTINEL_FAILOVER_STATE_WAIT_PROMOTION))
{
/* Now that we are sure the slave was reconfigured as a master
* set the master configuration epoch to the epoch we won the
* election to perform this failover. This will force the other
* Sentinels to update their config (assuming there is not
* a newer one already available). */
ri->master->config_epoch = ri->master->failover_epoch;
ri->master->failover_state = SENTINEL_FAILOVER_STATE_RECONF_SLAVES;
ri->master->failover_state_change_time = mstime();
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+promoted-slave",ri,"%@");
if (sentinel.simfailure_flags &
SENTINEL_SIMFAILURE_CRASH_AFTER_PROMOTION)
sentinelSimFailureCrash();
sentinelEvent(LL_WARNING,"+failover-state-reconf-slaves",
ri->master,"%@");
sentinelCallClientReconfScript(ri->master,SENTINEL_LEADER,
"start",ri->master->addr,ri->addr);
sentinelForceHelloUpdateForMaster(ri->master);
} else {
/* A slave turned into a master. We want to force our view and
* reconfigure as slave. Wait some time after the change before
* going forward, to receive new configs if any. */
mstime_t wait_time = SENTINEL_PUBLISH_PERIOD*4;
if (!(ri->flags & SRI_PROMOTED) &&
sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri,wait_time) &&
mstime() - ri->role_reported_time > wait_time)
{
int retval = sentinelSendSlaveOf(ri,
ri->master->addr->ip,
ri->master->addr->port);
if (retval == C_OK)
sentinelEvent(LL_NOTICE,"+convert-to-slave",ri,"%@");
}
}
}
/* Handle slaves replicating to a different master address. */
if ((ri->flags & SRI_SLAVE) &&
role == SRI_SLAVE &&
(ri->slave_master_port != ri->master->addr->port ||
strcasecmp(ri->slave_master_host,ri->master->addr->ip)))
{
mstime_t wait_time = ri->master->failover_timeout;
/* Make sure the master is sane before reconfiguring this instance
* into a slave. */
if (sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri,wait_time) &&
mstime() - ri->slave_conf_change_time > wait_time)
{
int retval = sentinelSendSlaveOf(ri,
ri->master->addr->ip,
ri->master->addr->port);
if (retval == C_OK)
sentinelEvent(LL_NOTICE,"+fix-slave-config",ri,"%@");
}
}
/* Detect if the slave that is in the process of being reconfigured
* changed state. */
if ((ri->flags & SRI_SLAVE) && role == SRI_SLAVE &&
(ri->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)))
{
/* SRI_RECONF_SENT -> SRI_RECONF_INPROG. */
if ((ri->flags & SRI_RECONF_SENT) &&
ri->slave_master_host &&
strcmp(ri->slave_master_host,
ri->master->promoted_slave->addr->ip) == 0 &&
ri->slave_master_port == ri->master->promoted_slave->addr->port)
{
ri->flags &= ~SRI_RECONF_SENT;
ri->flags |= SRI_RECONF_INPROG;
sentinelEvent(LL_NOTICE,"+slave-reconf-inprog",ri,"%@");
}
/* SRI_RECONF_INPROG -> SRI_RECONF_DONE */
if ((ri->flags & SRI_RECONF_INPROG) &&
ri->slave_master_link_status == SENTINEL_MASTER_LINK_STATUS_UP)
{
ri->flags &= ~SRI_RECONF_INPROG;
ri->flags |= SRI_RECONF_DONE;
sentinelEvent(LL_NOTICE,"+slave-reconf-done",ri,"%@");
}
}
}
重点
1、在更新节点info时,发现role是从slave变更为master并且failover_state= SENTINEL_FAILOVER_STATE_WAIT_PROMOTION,表示是由哨兵启动的从升主,则标记failover_state= SENTINEL_FAILOVER_STATE_RECONF_SLAVES,由环节13进行reconf-slave操作,详情见13
16. sentinelFailoverSwitchToPromotedSlave
发布switch-master事件,并更新本地哨兵中的记录
/* This function is called when the slave is in
* SENTINEL_FAILOVER_STATE_UPDATE_CONFIG state. In this state we need
* to remove it from the master table and add the promoted slave instead. */
void sentinelFailoverSwitchToPromotedSlave(sentinelRedisInstance *master) {
sentinelRedisInstance *ref = master->promoted_slave ?
master->promoted_slave : master;
sentinelEvent(LL_WARNING,"+switch-master",master,"%s %s %d %s %d",
master->name, master->addr->ip, master->addr->port,
ref->addr->ip, ref->addr->port);
sentinelResetMasterAndChangeAddress(master,ref->addr->ip,ref->addr->port);
}
17. 细节
17.1. failover_state
表示在确认odown状态后的各个执行阶段的状态,主要由七种
| 任务码 | 任务名称 | 任务描述 |
|---|---|---|
| 0 | SENTINEL_FAILOVER_STATE_NONE | No failover in progress |
| 1 | SENTINEL_FAILOVER_STATE_WAIT_START | Wait for failover_start_time |
| 2 | SENTINEL_FAILOVER_STATE_SELECT_SLAVE | Select slave to promote |
| 3 | SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE | Slave -> Master |
| 4 | SENTINEL_FAILOVER_STATE_WAIT_PROMOTION | Wait slave to change role |
| 5 | SENTINEL_FAILOVER_STATE_RECONF_SLAVES | SLAVEOF newmaster |
| 6 | SENTINEL_FAILOVER_STATE_UPDATE_CONFIG | Monitor promoted slave |
17.2. 时间管理
17.2.1. 节点时间
1、 Master->failover_start_time
默认为0,分别有两次赋值,第一次是在环节7确认可以failover后更新master信息是更新,第二次是选举sentinel leader成功后更新为当前时间
2、 Master->failover_timeout
默认3min
3、 election_timeout
选举超时,默认10s
4、
17.2.2. 两次failover时间约束
在执行环节6,查询是否需要执行failover时(已经odown),哨兵都会判断上次failover和此次的时间是否满足要求
mstime() - master->failover_start_time < master->failover_timeout*2
如果没有超过,则会加锁,在加锁时间内不允许进行failover
time_t clock = (master->failover_start_time +
master->failover_timeout*2) / 1000;
char ctimebuf[26];
ctime_r(&clock,ctimebuf);
ctimebuf[24] = '\0'; /* Remove newline. */
master->failover_delay_logged = master->failover_start_time;
serverLog(LL_WARNING,
"Next failover delay: I will not start a failover before %s",
ctimebuf);
17.3. 选举超时
环节9中,每次确认是否选举超时,如果选举超时都会放弃此次选举,
election_timeout默认为10s,系统在election_timeout和failover_timeout两者选择最小
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
int election_timeout = SENTINEL_ELECTION_TIMEOUT;
/* The election timeout is the MIN between SENTINEL_ELECTION_TIMEOUT
* and the configured failover timeout. */
if (election_timeout > ri->failover_timeout)
election_timeout = ri->failover_timeout;
/* Abort the failover if I'm not the leader after some time. */
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}